#announcements (2018-07)
 Cloud Posse Open Source Community #geodesic #terraform #release-engineering #random #releases #docs
Cloud Posse Open Source Community #geodesic #terraform #release-engineering #random #releases #docs
This channel is for workspace-wide communication and announcements. All members are in this channel.
Archive: https://archive.sweetops.com
2018-07-01
Second training repo. No step by step instruction yet. If you have ideas, or suggestions please submit issues. https://github.com/firmstep-public/trainingdaytwo
trainingdaytwo - Day Two: Creating Terraform modules
The example module in demo_one is a working module for a web server in an asg. Which I figured was a common desire for the first thing to template for a company.
2018-07-02
@rohit.verma I was able to reproduce that s3 path issue you were experiencing when mounting the s3 bucket: https://github.com/cloudposse/geodesic/pull/167 - once we have it CR’ed and tested will have a new release with this fix in it. Will keep you posted.
what Add the absolute path to the s3fs script for mounting s3 bucket via goofys. why Fix a bug where pathing issue causes any mount -a invocation to throw an error: /bin/sh: s3fs: not found
@mcrowe (and possibly @tamsky) also ran into it
just wondering why the mount command is not honoring the PATH
Hi Erik, we had a quick chat on Friday regarding ECS! I would love to know how you do it. The end-goal for me is to be able to use 3rd party deployment software which most likely pushes a docker image based on a GIT-SHA, meanwhile Terraform should be able to run and take the last active task definition ( this part is simple ). Harder part is when I want Terraform to be able to modify the environment variables while keeping the image of the last task definition.
The idea I now have is by taking the image variable length to decide if it’s bootstrapping or keep_image:
# Initial bootstrapping with ecr/repo:tag module “ecs_app” { image = “ecr/repo:tag” }
# after that, a change to keep_image module “ecs_app” { image = “” ( default) }
when image==””, i create datasources to get the current image definition, use that as input for the updated task definition resource.
Not sure if that would all work, and happy to hear your input on that.
roughly it breaks down like this:
1) deploy ecs service task with container definition. default the container to our default-backend (~ a 404 page).
2) use codebuild/pipeline to CI/CD all image deployments.
3) define one public ALB per cluster
4) use ingress rules (targets) to route traffic based on host/paths to backend services
the inspiration for the architecture comes from our experience with kubernetes and trying to make it feel more like it.
what I describe above is captured in this module:
terraform-aws-ecs-web-app - Terraform module that implements a web app on ECS and supporting AWS resources.
the CI/CD is here: https://github.com/cloudposse/terraform-aws-ecs-codepipeline (which swaps out the image & tag)
terraform-aws-ecs-codepipeline - Terraform Module for CI/CD with AWS Code Pipeline and Code Build for ECS https://cloudposse.com/
we programmatically generate the container definition JSON in this module: https://github.com/cloudposse/terraform-aws-ecs-container-definition
terraform-aws-ecs-container-definition - A Terraform module to generate well-formed JSON documents (container definitions) that are passed to the aws_ecs_task_definition Terraform resource
and our ALB modules are in: https://github.com/cloudposse/terraform-aws-alb https://github.com/cloudposse/terraform-aws-alb-ingress
terraform-aws-alb - Terraform module to provision a standard ALB for HTTP/HTTP traffic
terraform-aws-alb-ingress - Terraform module to provision an HTTP style ingress rule based on hostname and path for an ALB using target groups
oh, and our “default-backend”
default-backend - Default Backend for ECS that serves a pretty 404 page
Does Codebuild allow cross account ECR repos by now ?
we have 1:1 codebuild/codepipeline/ecr/web app
so a different build image for your staging , as for prod ?
aha, for now, we have not orchestrated that.
in our case, we would promote an image to the prod repo
but we have not done that yet
(we’re pretty early in our ECS journey as most of what we use is k8s)
let me correct that
we currently would rebuild it
but the way I would want to solve it eventually is to promote the image between ECR repos
still reading through it..
I see this working when having an imagename like repo:latest , but not for repo:unique_id or am I missing something
@sarkis where is an example of our build spec?
we do set a tag
so for example, it’s possible to only deploy tagged releases
then it would be repo:tag
Contribute to docker-php-poc development by creating an account on GitHub.
We should add this example to the web app repo docs
Contribute to docker-php-poc development by creating an account on GitHub.
- ill get to this by EOD … added to my tasks for the day
(we never pin to latest)
printf '[{"name":"%s","imageUri":"%s"}]' $CONTAINER_NAME $REPO_URI:$IMAGE_TAG > imagedefinitions.json
@maarten I thought you were doing something similar to this
so it all comes down to how IMAGE_TAG is computed
yes, but after the building, how is terraform aware of the new IMAGE_TAG, I’m not seeing that.
oh, the lifecycle of the image:tag is not the job of terraform
this is our concession
terraform is strictly responsible for deploying the infrastructure that powers the service
monitoring
autoscaling
iam permissions, etc
so i think we ignore changes, right @sarkis?
I agree there, but for me ENV VARS are a sort of grey area
SSM
+chamber
Yeah at Blinkist we’re using SSM
(it doesn’t resolve how to “rollback” envs, but we’ve also conceded that we won’t solve for that)
But another customer doesn’t want SSM or doesn’t want a wrapper inside his Docker for that..
So I thought, maybe I can find a way to deal with that using container def. datasources
i agree that I don’t like the wrapper inside the container as the entrypoint, but it’s become the necessary evil to reduce complexity with terraform.
wrapper = chamber
would be nice to have have ENV VARS defined for the ecs service instead, problem solved
something else, which is beautiful, happens if you use SSM though…
call out to @jamie for introducing us to this pattern
terraform-aws-ssm-parameter-store - Terraform module to populate AWS Systems Manager (SSM) Parameter Store with values from Terraform. Works great with Chamber.
you can provision those SSM parameters from outputs of your other modules
users, passwords, hosts, etc
yeah I’ve seen that, super cool and will use it
what’s the customer’s counter argument?
…we’ve even started using chamber with kubernetes in place of configmaps and secrets. it makes it much, much easier to manage ACLS+IAM using IAM roles
Another thing in the chain they don’t know.. I was probably not convincing enough.. first customer after my current employer ..
haha, yea, understood - in the end, if you overwhelm them with all the pros, I think the cons are very minimal.
the ECS envs are also not encrypted
ok, outside environment variables you still have CPU and MEMORY definitions
that is an actual terraform argument I think
maybe not for Fargate
that is an actual terraform argument I think
can you elaborate
inside the task definition you define the cpu and memory for a task
Of course you can set these vars during deployment
but is this something any developer should do in some conditions, or rather have memory/cpu centrally orchestrated
aha, yes, but i don’t think this solution precludes that
we set some defaults
but the buildspec.yaml can also override them
printf '[{"name":"%s","imageUri":"%s"}]' $CONTAINER_NAME $REPO_URI:$IMAGE_TAG > imagedefinitions.json
just add memory to that
no?
you’re right. I’m thinking from a perspective where the CI is circleci and not managed by terraform..
aha
yes, i can see that some stuff gets more complicated that way
But still, circleci can invoke codebuild
i guess
or a lambda which does nothing but deployment, and terraform manages the parameters for the lambda.
yea, lambda is the ultimate escape hatch. can probably accomplish it that way.
That also saves me distributing access keys which can stop services.
Do you a tool for remote command execution, fixing a failed migration etc ?
Thanks anyway, I didn’t find the answer to my solution, but it made it clear that when I control the deployment of ecs I can still control the container definition, be it codebuild or not.
yep! no problem. i think we went down a similar path until we resovled that it wasn’t feasible at this point in time with terraform.
hrmm… the only migrations we’ve done so far happen in k8s and then we’re able to exec into the container to perform manual remediations.
@jamie might have some tips
ok because the new guy replacing me is working on my old tool which does this:
- Takes current running task, properties, security groups
- Creates keypair
- Starts EC2 ECS Instance with keypair
- Starts task [same iam etc]
- SSH into EC2 instance , creates a socket forward for /var/run/docker.sock ( this is so cool)
- docker exec into task
that sounds pretty cool
on-demand ssh
i know this is a pattern promoted by Teleport SSH (gravitational)
but haven’t seen it in practice yet with ECS
https://github.com/blinkist/skipper it’s dormant now, also because my golang skills are .. but I’m sure he’ll be able to make something nice of it
skipper - Maintenance tool for moving docker containers on ECS.
Anyway, I’ll keep you updated on it, for now it’s focus is on regular EC2, with already SSH access.
For conditions without VPN we can maybe also add a network load balancer to allow outside access to internal ssh
yea, what I think could be neat is to have something like this:
bastion - Secure Bastion implemented as Docker Container running Alpine Linux with Google Authenticator & DUO MFA support
that is deployed on demand into the cluster for triaging
e.g. fixing failed migrations
Well it would be nice to be able to completely log it to an S3 bucket, with the private key EC2 generation for the ec2 instance for the specific user (for which it needs MFA ) the extra MFA is probably overkill.
but is ec2 instance access necessary?
what i like about using containers is that it’s still isolated
I like that too, but when things brake someone wants to have access I suppose..
One question, how quick is codebuild now w/r booting up ?
It’s pretty quick now, but as you can see from the code for the “test app” we are using - it’s really basic.
@sarkis can maybe answer this
The idea I have now is this
- Have CircleCI test & build , a lot of startups here are using Circleci
- After build and push to ECR, push textfile to S3 in dev/uat/prod environment with image:tag
- Codebuild just pushes to ECS
- CircleCI loops&polls codebuild result, finishes
Yep, that sounds like a good solution to a common use case
@Erik Osterman (Cloud Posse) https://github.com/cloudposse/geodesic/pull/168
What it is Previously this used an old spec that caused newer installations of the this chart to fail. storageSpec has since been updated to just storage See: coreos/prometheus-operator#860 (commen…
One question regarding terraform-aws-ecs-web-app Have you ever had issues with the ecs_service being created before the listener_rule was added to the target_group ? I don’t see this dependency being forced in terraform-aws-ecs-web-app and I had this quite a lot and caused me to trick around.
@sarkis
@maarten we do have that issue - since it’s a one time problem (cold boot) - we are just running terraform apply twice for the time being. I’d like to at some point dig into the provider and see if there is something to be done there, before trying to hack this with depends_on statements
Clarify what you mean by twice
I think what you mean is two phases
Not twice as retrying after failure :)
well it fails then
depends on definition of fail.
But the hack to mitigate it is .. kind of ugly..
How did you get it working?
terraform-aws-airship-ecs-service - Terraform module which creates an ECS Service, IAM roles, Scaling, ALB listener rules.. Fargate & AWSVPC compatible
so the listener rules of the alb handling are outputted
inputted after into the ecs service module
then a null resource .. doing nothing
and aws_ecs_service with a depends_on
clever
but maybe the null_resource could be removed, create a local, and add the local to the count = inside the ecs_service I think now
might be a computed count issue
well, we don’t have to count it, just evaluate it in someway
hm
so @maarten looking over your ecs_service/ in more depth - it looks like you need 2 tf runs as well right?
nope
where ?
i guess i’m not seeing where lb_attached gets changed
oh nvm i see how you make it wait with null_resource
lb_attached is just input for if it is a worker or a web service
The ugliest hack you will find here : https://github.com/blinkist/terraform-aws-airship-ecs-service/blob/master/modules/ecs_task_definition/main.tf search for my_random Module has as input key-value pairs which afterwards are turned into Name: Value: pairs for the environment variables of the task definition.. I found out that when “true” runs through a null_resource it will be casted to a 1 ..
terraform-aws-airship-ecs-service - Terraform module which creates an ECS Service, IAM roles, Scaling, ALB listener rules.. Fargate & AWSVPC compatible
I have no idea how I could fix this otherwise, input very much welcome
yea typecast hell is real in TF
we did something similar for converting TF -> json
i mean not similar but a similar typecast issue
let me find it - it might make you feel better about your hack
I think the ecs_service can be done without null_resource, add another empty item to the list, grab that item from the list, call it empty_string , and use that empty_string somewhere in ecs_service
terraform-aws-ecs-container-definition - A Terraform module to generate well-formed JSON documents (container definitions) that are passed to the aws_ecs_task_definition Terraform resource
lol
i call that “cost of doing business with terraform”
price we have to pay
sadly - i was reading through HCL2 didn’t see anything specifically about the typecasting
there was a vague mention that types work better or something
Do you know if your modules will break yes/no ?
that’s also very vague rigth now - i think they are waiting for the community to do the dirty work
Wonder what is smart then, just create a new one calling it module-hc2 and go from there
i was thinking a new branch to start out
for example in the ecs_service part i now have 4 x ecs_service with conditionals.. with hcl2 this can be compacted to just one
but that might be too optimistic
ah yea i hear you though - it’s going to assume you can use the new tf version everywhere too
can prob fix this with tags though… go to a new major release for HCL2 (in your modules)
and then a note in the readme
sounds like they are going to support both languages initially, no?
so that provides an upgrade path
so modules can lay claim to the legacy provider until upgraded
hmm how would that work? oh just depends on what provider version you lock?
but i’m definitely nervously biting my nails right now hoping that it won’t be too painful
we have something like 70 modules
yea and i’m certain we do some interesting workarounds / hacks that are going to be fixed/deprecated in the future
Night ttyl
goodnight!
2018-07-03
Good morning… new to the channel and not sure where I should / if I should be asking questions here… A while back I saw you guys do a presentation along side Codefresh…I remember being very impressed with the deployment pipeline you guys had set up and I am trying to get something of my own set up. I am curious how you guys connect git tags and pull them through to your dockerhub registry
I just found this page …. seems like I am on the right track https://docs.cloudposse.com/release-engineering/cicd-process/semantic-versioning/
@cbravo I can share more details a little later today
Currently afk
Yes that’s a good place to start
@Erik Osterman (Cloud Posse) Thank you very much…. I am also scoping out this repo (https://github.com/cloudposse-demo/demo-catalogue) and the build harness repo
Contribute to demo-catalogue development by creating an account on GitHub.
we’ve also iterated a lot since that demo
would love to get you to try out the new stuff
all of our new stuff uses helmfile
are you familiar with that?
I am not
it simplifies a lot of stuff around working with helm
we are just getting our feet wet with helm but the particular project I am currently focused on is just a deployment image (it has aws cli in it and some other tools we use…) and I am trying to come up with a way to keep the git tag inline with the tags in docker hub without having to do a bunch of automated steps
codefresh gives you the git hub short revision but no access to the git tags
aha, ok - that is a simpler use-case
we are slowly ramping up our knowledge of help and kubernetes but we aren’t there yet
terraform-root-modules - Collection of Terraform root module invocations for provisioning reference architectures
here’s a more simple codefresh pipeline
this builds a docker image and tags it with the semantic version generated in a previous step
it’s also an example of pushing the image to multiple registries
Any Datadog users here ?
i think we all have a bit of experience (cloudposse org)
I’ve not seen a good timeboard module yet, and with locals the population of multiple graphs can be fixed .. at least it looks like it
i personally have less than others here with datadog - my use case was limited to monitoring kafka
@Erik Osterman (Cloud Posse) so is the build harness something that the public should be using? like should I consider using your build harness? or is it something that could change without warning
or really something I should just consider taking pieces of and rolling my own solution based off it
we recommend to all of our customers to use the build-harness
it’s well maintained and we tag all releases. so if it suits your needs, by all means, leverage it.
especially with codefresh, the build-harness makes a lot of sense since every step runs in a container
@cbravo let me know if it would be helpful to take a look at what you have
and if we are not currently customers?
only share what’s not subject to an NDA
you can DM me
I am 200 messages behind this chat. Sorry I’ve been afk guys.
you snooze you lose
Totally!
If anyone wants to take a look at the basic structure of a datadog timeboard module, feel free to comment.
https://github.com/maartenvanderhoef/terraform-datadog-timeboard/blob/master/examples/main.tf
https://www.terraform.io/docs/providers/datadog/r/timeboard.html
Problem of the datadog_timeboard was that it’s set-up like the cloudfront resource.. many blocks after another inside one resource.. but now with locals it can be modularized a bit. I wanted to be able to create graphs seperatedly from creating the actualy timeboard by creating 2 modules and this seems to be working.
Contribute to terraform-datadog-timeboard development by creating an account on GitHub.
Provides a Datadog timeboard resource. This can be used to create and manage timeboards.
@dave.yu @Daren maybe something interesting for you guys
cool will take a look
anyone know how to get the version of a terraform module programmatically? e.g. ${module.version}
use-case: I want to download artifacts from github release corresponding to the version of the terraform module
(e.g. a lambda zip file)
this appears to work:
variable "git_ref" {
default = "tag"
}
data "external" "example" {
count = "${var.git_ref == "tag" ? 1 : 0}"
program = ["git", "-C", "${path.module}", "tag", "--points-at", "HEAD", "--format={\"ref\": \"%(refname:lstrip=2)\"}"]
query = {
}
}
output "ref" {
value = "${join("", data.external.example.*.result.ref)}"
}
minor nit:
even with a data.external.example input or output, we can’t use either to instantiate the module:
Terraform does not support interpolations in the source parameter of a module
outputs:
ref = test-0.1.1
2018-07-04
Hey @Erik Osterman (Cloud Posse) – been looking at aws-cloudfront-s3-cdn. Do you guys have a strategy for a javascript bundled webapp deployed to dev/test/prod via codepipeline?
I’m wondering: 1) Github -> hook -> CodePipeline (builds app via webpack) and pushes to dev 2) Q/A approves, time to move to test/uat 3) (?????) push dev artifacts to uat 4) Customer approves live 5) (?????) pushes uat artifacts to prod
we usually use tags for gate control
so branches = dev
merge to master = pre-production
tags like release- go to prod
we have implemented this with codefresh
not yet with codepipeline
Maybe I’m over-thinking it. Maybe each one is a codepipeline task off a branch
There’s a seriously small cap on the number of pipelines you can make. But because you can pass a lot of data to them you can do a lot. So I suggest making your pipeline as generic per task as you can and making it work for you.
So what you describe is a pretty common pattern. A few of our customers do exactly that. We haven’t packaged that up as a terraform module. Most of them use Codefresh for CI/CD, and then use
terraform-aws-cloudfront-cdn - Terraform Module that implements a CloudFront Distribution (CDN) for a custom origin.
terraform-aws-s3-website - Terraform Module for Creating S3 backed Websites and Route53 DNS
Here’s a reference implementation https://github.com/cloudposse/terraform-root-modules/tree/master/aws/docs
terraform-root-modules - Collection of Terraform root module invocations for provisioning reference architectures
2018-07-05
hey folks, quick question on the prometheus-cloudwatch exporter. When i try to follow the kubernetes instructions (https://github.com/cloudposse/prometheus-to-cloudwatch) the prometheus-to-cloudwatch pod fails to deploy, saying the image is unavailable. I’m running helm install . from within the charts subdirectory so I’m not sure what to do next.
prometheus-to-cloudwatch - Utility for scraping Prometheus metrics from a Prometheus client endpoint and publishing them to CloudWatch
@tom thanks for the report. I will check into this a bit later today.
Hello @tom - do you have some more info you can share, namely helm/tiller version while we look into reproducing the issue?
@Andriy Knysh (Cloud Posse) are you are around to take a look?
@sarkis probably just wrong image tag
It should correspond to the latest release in the repo
ah yea
i see an old version here: https://github.com/cloudposse/prometheus-to-cloudwatch/blob/master/chart/values.yaml#L21
prometheus-to-cloudwatch - Utility for scraping Prometheus metrics from a Prometheus client endpoint and publishing them to CloudWatch
i’ll check in after i push through the few tasks i have today - if you haven’t looked yet I can dig into it..
@tom
Ah yeah that was it. Thanks for your help
great!
For our use case, it’s so we can download a zip artifact for a lambda function from the module GitHub release page.
what Do not set Name and Namespace why When we try to set the tags "Name" and "Namespace" the second deployement fails (the first one is ok). example * module.front-elastic-…
@jamie any idea how we can change this to only apply Name and Namespace on first apply?
apparently, all applys after the first one fail if these are set
Yo
just a moment ill look
thx
well, yeah
lifecycle { ignore_changes = [“tags”]}
might do it
ah, yea, I think that’s a better fix
I’m not set up to test that it will fix it though
are you able to?
i’ll ask that they try it out
if not… then its possible to do their fix… or strip “Name” and “Namespace” tags back out
but i think their solution is .. tidier then removing two map items from a map
by having a data lookup the existing tags on the elb
and only apply the extra tags
ok, my response: https://github.com/cloudposse/terraform-aws-elastic-beanstalk-environment/pull/37#pullrequestreview-134777928
what Do not set Name and Namespace on Elastic Beanstalk Environment why When we try to set the tags "Name" and "Namespace" the second deployement fails (the first one is ok)….
since you can reference resources directly
so you could do { if lookup(this.resource.tags, “Name”, “NAME_NOT_EXISTS”) != “NAME_NOT_EXISTS”} add full list of tags { else } add subset of tags {end}
^psudocode
Thanks for thinking of me
yea, that will simplify so many things in complex terraform modules
thanks!
As part of the lead up to the release of Terraform 0.12 later this summer, we are publishing a blog post each week highlighting a new feature. The post this week is on first-class …
i should start constructing a sed expression to replace “${var…}” to var…. and post to the cloudposse blog
no need i think
they will have a conversion method
oh like a HCL 1->2?
so all the standard stuff will convert as easily as something like terraform fmt .
yea
nice
thats true this should be a fmt change
(also, I’m not sure if fmt is the action they will use, but I read that they will provide a means of automatically upgrading code)
2018-07-06
https://github.com/kubernetes/kops/issues/2537 (via @Daren)
I noticed a few instances where if a pod is hung in ContainerCreating state, or some other state and won’t go into Evicted state Kops hangs forever waiting for it during a rolling-update.
@Max Moon @dave.yu heads up
there’s an issue with kops 1.9 where it has trouble detecting failed pod evictions
Good looking out, thank you!
We hit it on every node with nginx-ingress-controller
Dang, I upgraded worker node size yesterday and fortunately it went smoothly
2018-07-09
@dave.yu @Max Moon heads up: https://github.com/cloudposse/geodesic/pull/172/
what Replace sets with inline values Rewrite values files with inline values (except files with comments that used to override values) why #169
we’re planning on merging this soon.
it uses inline values.yaml to make it easier to maintain
Thanks @Erik Osterman (Cloud Posse)
2018-07-10
Hey i have a tip for you guys when dealing with ecs
in many cases the service, the containers, and the metrics all want the cluster name, not the arn
but the resource doesn’t provide a name, just the arn
but you can do this:locals { cluster_name = "${basename(aws_ecs_cluster.default.arn)}"}
to get the name
that’s a good one! like the use of basename(...) for this
I was doing
locals { cluster_name = "${element(split("/",(aws_ecs_cluster.default.arn), 1)}"}
Before.
really nice tip - thanks @jamie i was trying to figure out last week how to get the name with just the ARN (was looking at data source, but some sources don’t have name available :()
I thought it would be up your alley
I have grown to dislike “terraform_remote_state” data provider
hmmm - not good in practice?
how come?
It requires a lot of details to collect details from a remote state
It has meant that when writing code that depends on other modules
you have to pass in “workspace”, “s3 bucket name”, “state path”, and use shit like:
### For looking up info from the other Terraform States
variable "state_bucket" {
description = "The bucket name where the chared Terraform state is kept"
}
variable "state_region" {
description = "The region for the Terraform state bucket"
}
variable "env" {
description = "The terraform workspace name."
}
locals {
state_path = "${var.env == "default" ? "" : "env:/${var.env}/" }"
}
### Look up remote state info
data "terraform_remote_state" "vpc" {
backend = "s3"
config {
bucket = "${var.state_bucket}"
key = "${local.state_path}vpc/state.tfstate"
region = "${var.state_region}"
}
}
That locals hack to get around the non-conformance that it has with workspaces
hrmm… yes… fwiw, here’s what we’ve recently done
data "terraform_remote_state" "backing_services" {
backend = "s3"
config {
bucket = "${module.identity.namespace}-${module.identity.stage}-terraform-state"
key = "backing-services/terraform.tfstate"
}
}
we have a module that keep track of a lot of constants
that can be reused
i think just stay clear of workspaces
we don’t love it
Workspaces were so good when I discovered them
yea because you’d think it would help DRY
With one command I could switch from the ecs container task that has jenkins deploying, to the nginx container, to the node container
all the same code, but dif vars
Yeah, but when it comes to state management and workspaces
there is a lot to be desired
If only terraform_remote_state wasn’t the only data source with a default
I’d be using parameter_store, or an api call.
\/whinge
One last gripe….!
I would prefer that blocks that only have one entry in them were put all in one line when you formatted.
haha devops therapy sessions
how does that make you feel?
resource "aws_thing" "default" {
tags = { managedby = "Terraform"}
}
output "thing" { value = "the thing i mentioned" }
IMO, I don’t like that. I agree it’s concise, but in most language frameworks I’ve dealt with, they are strict about how braces are used. Typically, they enforce one of:
if (...) {
....
}
or
if (...)
{
...
}
but never
if (...) { ... }
Where’s the Terraform yaml option!
Okay… gripe done ;-D
heh, would be interesting to see what TF would look like in YAML
data:
template_file:
example:
template: '${hello} ${world}!'
vars:
hello: goodnight
world: moon
output:
rendered:
value: '${data.template_file.example.rendered}'
variable:
count:
default: 2
hostnames:
default:
'0': example1.org
'1': example2.net
data:
template_file:
web_init:
count: '${var.count}'
template: '${file("templates/web_init.tpl")}'
vars:
hostname: '${lookup(var.hostnames, count.index)}'
resource:
aws_instance:
web:
count: '${var.count}'
user_data: '${element(data.template_file.web_init.*.rendered, count.index)}'
AKA
data "template_file" "example" {
template = "${hello} ${world}!"
vars {
hello = "goodnight"
world = "moon"
}
}
output "rendered" {
value = "${data.template_file.example.rendered}"
}
and
variable "count" {
default = 2
}
variable "hostnames" {
default = {
"0" = "example1.org"
"1" = "example2.net"
}
}
data "template_file" "web_init" {
// here we expand multiple template_files - the same number as we have instances
count = "${var.count}"
template = "${file("templates/web_init.tpl")}"
vars {
// that gives us access to use count.index to do the lookup
hostname = "${lookup(var.hostnames, count.index)}"
}
}
resource "aws_instance" "web" {
// ...
count = "${var.count}"
// here we link each web instance to the proper template_file
user_data = "${element(data.template_file.web_init.*.rendered, count.index)}"
}
can’t help but feel like it’s “cloudformation” when seeing it in YAML format
it feels like they just “borrowed” the golang approach to { }
now thats a nice positive rant
i’ve noticed he does these multiple tweets a lot lol
that’s cool
2018-07-11
I’m mid module writing for handling ecs instance draining for spot instances, but I want it to handle ASG standard istances as well…
so now it looks like im making another module for my module
how are you implementing the draining?
Modifies the status of an Amazon ECS container instance.
Good question
boto3
on asg instance termination sns alert
i get the instance id
And currently i grab the list of all ecs clusters, then in each cluster, i list all container_instances, and then i compare my instance id to the container instance id.
Once I have that i change state to draining
I don’t know how heavy those requests are when there are 100 clusters with 10000 instances on each
but it works for mine
I expect a faster lookup would be: tag each instance on creation with its cluster name
then, use the tags to get the cluster name from the id.
But then it involves an extra step on creation.
Whereas this way, i don’t need access to the ASG resource, just the asg name
I am still in POC stage with it really
I can see many ways to smooth it out, break it in to smaller reusable chunks and so on
but … maybe once I get the functions and permission sets all working
I can split the modulerisation of it with Sarkis or something
Well, it works
terraform-aws-ecs-launch-template - Terraform module for generating an AWS Launch Template for ECS that handles draining on Spot Termination Requests
It now also handles draining on scale in
Next it likely needs the lambda function rewritten to trim all of the junk off it, and set up a step function, so that a 5 or 10 second delay can be added between checking if the tasks have drained.
at the moment it just loops with no delay, between sns -> lambda -> sns ->lambda etc
until it finishes draining the tasks
@jamie the upstream tf PR was merged to support the launch templates?
2018-07-12
Not for spot fleets.
So while waiting for that, I made the template module handle both spot fleets, asg on demand, and asg spot.
That’s just the launch template module
The other module which I’m making with you in mind is the auto scaling spot fleet one.
And that requires the merge first

Your typical cloud monitoring service integrates with dozens of service and provides you a pretty dashboard and some automation to help you keep tabs on how your applications are doing. Datadog has long done that but today, it is adding a new service called Watchdog, which uses machine learning to …
I like writing modules because it makes me do less work in the long term.
Question for the ones who worked with K8S before, I have not really. How does it compare to ECS for you. I see small startups offering jobs to devops for their to-be-configured k8s cluster ( on AWS) and I really think, why not just ecs ? It’s so much hype.
feature velocity of k8s is insane. huge ecosystem of tools, much lager than for ECS. IMO, it’s easier to deploy complex apps on kubernetes than on ECS. ECS needs something like Helm. Not sure if “terraform” is the answer for that. ECS has evolved leaps and bounds from when I first looked at it (e.g. DNS service discovery), but it still feels rather primitive coming from an kubernetes background. I think one big thing ECS has going for it is that it is simpler, but in being simpler lacks a lot of the cool features of kubernetes.
charts - Curated applications for Kubernetes
There’s no signficant library of apps for ECS like there is for kubernetes. That to me is a little bit of a redflag.
(that I’m aware of)
True, but tbh, how many of the cool features do you really need. And will some cool features like persistent storage let people make decisions which are contrary to the reason for moving to AWS, like, having AWS taking care of your stateful services.
The idea is to represent as much of the infrastructure as possible so that i can be easily deployed without involving ops
with ECS, that’s not really possible.
with k8s, you can almost do everything but IAM roles/policies
volumes, load balancers, ingress, namespaces, secrets, configmaps, replicasets, deployments, pods, etc.
automatic TLS
automatic DNS
so basically a single helm chart is capable of provisioning a web app with a dynamic TLS certificate, automatic public DNS registration, pulling secrets and exposing them as envs, mounting configmaps as files on the filesystem, provisioning EBS volumes for scratch storage, and more…
we use these features all the time.
CI/CD of this is very easy with Kubernetes
few orgs actually do CI/CD of terraform
ok, but when connected to AWS in ways of networking, iam, .. then you do get terraform after all
persistent storage doesn’t have to be “persistent”
but you need it for big data applications like cassandara or HDFS
and for staging environments, we run apps like postgres
so having attached storage is necessary since the host machine is limited
so kubernetes cannot exist without terraform
that’s why it’s so central still to everything we do visible in our github
but kubernetes is headed in the right direction
I’d love to see a kind: Terraform in kubernetes
then it would truly allow everything
for what resources then ?
IAM roles, policies
RDS databases
elasicache instances
EFS filesystems
etc.
…so fully managed services
Here’s a POC presented at HashiConf: https://github.com/kris-nova/terraformctl
terraformctl - Running Terraform in Kubernetes as a controller
The other thing about k8s, is it’s more like like a framework (like “rails”) for how to do cloud automation. It provides the interfaces, scheduling, state, service discovery. Then makes it extensible to add anything else on top of it. So for more complex applications, e.g. “postgres”, in order to run it in a containerized environment, you need an “application aware” controller. Something that knows instinctively how to manage postgres. How to do updates, upgrades, rollbacks, etc.
So people are developing operators like this: https://github.com/CrunchyData/postgres-operator
postgres-operator - PostgreSQL Operator Creates/Configures/Manages PostgreSQL Clusters on Kubernetes
etcd-operator - etcd operator creates/configures/manages etcd clusters atop Kubernetes
for running complex applications that aren’t just stateless webapps
Sure, but having seen a few meetups with pains of guys running stateful inside k8s..
Didn’t we move to AWS to not have state anymore
i agree that not dealing with state is the “ideal” situation
and we encourage our customers to push that off as long as possible
but I would rather have a platform capable of handling that in addition to all the stateless apps
at somepoint, someone needs to manage the state.
aws doesn’t provide state management for every application
thus some apps do need to handle that.
true, although, there are so many providers who offer services through vpc peering now
mongo atlas for example
yea, i would love to see more of that
i think that’s a cool direction
also, we’re still in the wee early days of k8s, but look how far & fast it’s come?
totally, in the end this is about not having 24/7 shifts, and not needing a 100% devops
With ECS I think this is possible, with self managed k8s, maybe less
yea, so back to perhaps your original question
but I don’t know k8s enough
to really judge there
companies who don’t have any dedicated devops, i would recommend considering ECS
smaller shops, with 1-4 people, ECS is probably better/simpler.
also with fargate then.. just great
i came from 80, but also only devops .. so ECS is perfect then
i think we’re coming at this from 2 differnet backgrounds. i spent the last 3 years working with k8s and 2 months with ECS.
so I don’t yet fully appreciate perhaps ECS.
you will, let’s just wait for that one k8s update hehe
haha
i really want to start working on our TF modules for EKS.
having deployed both - i do prefer k8s - something about it just appeals to me - i think it’s mostly the fact that i can do everything out of the box via command line - i.e. kubectl
def possible for ecs i bet but aws-cli is meh
for example - so easy to cat out the logs for ingress and describe a pod etc… for ECS i still find myself in the AWS web console - i know I am doing it wrong - but aws doesn’t make it a no brainer task like k8s for cli equivalents
so in a 20 developer situation how many people have kubectl and can do damage ?
RBAC addresses that concern
also, you can give those developers carte blanche for a namespace, so they can triage their own stuff.
speeds up itertations, removes bottlenecks
yea good point - not ideal in production
and imo kubectl is the emergency hatch - so whoever is dealt the devops card in the 20 dev group
large companies definitely are dealing with it though and as far as I know, love the RBAC support within kubernetes.
ok
i.e. knows what they are doing
hehe
As part of the lead up to the release of Terraform 0.12 (https://www.hashicorp.com/blog/terraform-0-1-2-preview), we are publishing a series of feature preview blog posts. The post…
@Erik Osterman (Cloud Posse) uploaded a file: Pasted image at 2018-07-12, 6:49 PM
This is awesome, but I find the formatting awkward without additional indention
Kubernetes and related technologies, such as Red Hat OpenShift and Istio, provide the non-functional requirements that used to be part of an application server and the additional capabilities described in this article. Does that mean application servers are dead?
2018-07-13
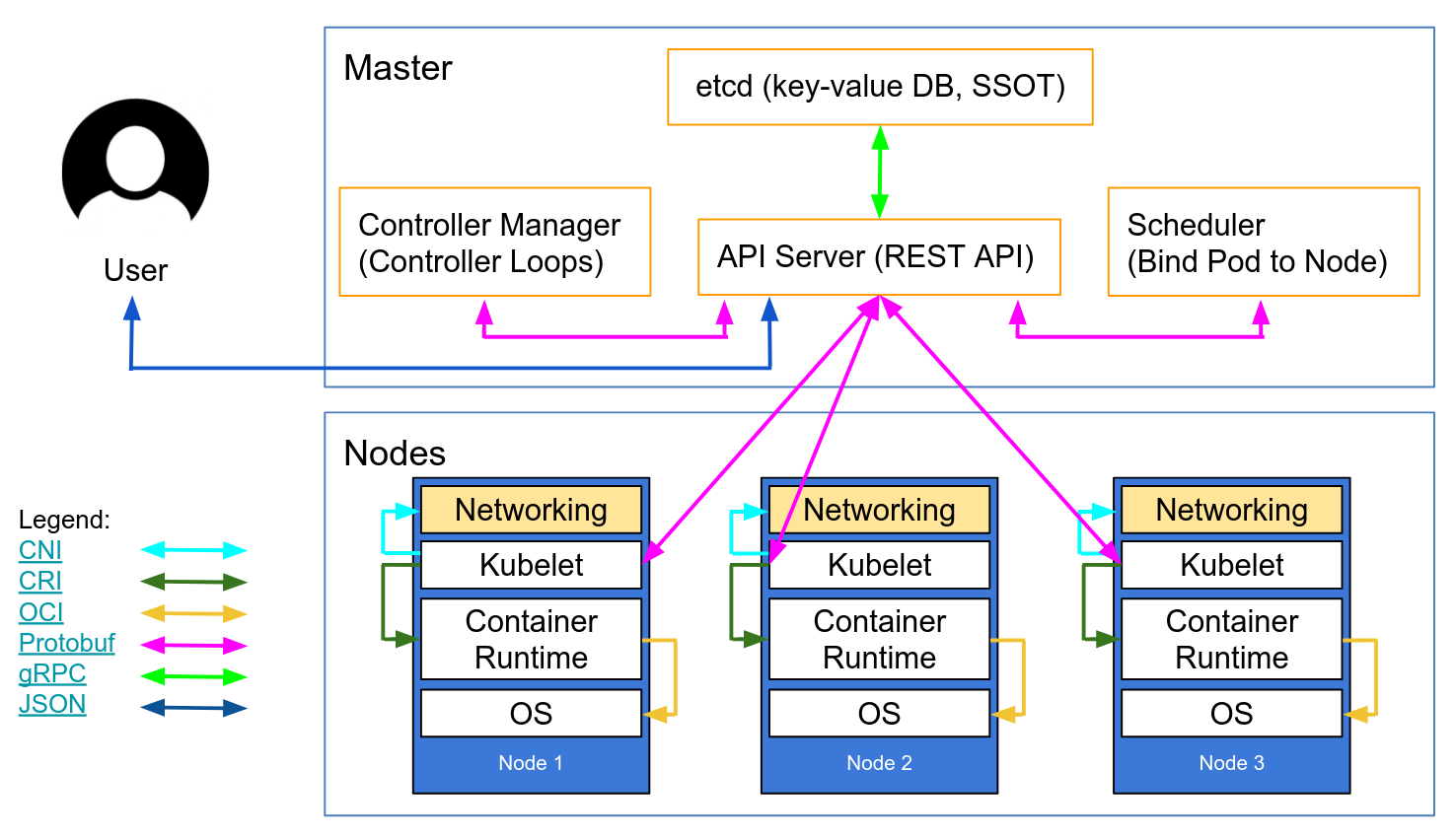
@Erik Osterman (Cloud Posse) /@sarkis Within geodesic wrapper we are publishing geodesic port and binding kubernetes_api_port to it, can you tell why we are doing this
also how can I proxy something out of container to host
say for example kubernetes-dashboard
Yep! This is for kubectl proxy
So you can do exactly what you want to do
Also, for dashboard you can do something else
But I am on my way to bed. Can demo our portal for you tomorrow or next week
It uses bitly oauth2 proxy
kubectl proxy –port=0.0.0.0:8080
its seems not working as expected, so if I do kubectl proxy –port=$GEODESIC_PORT
From inside geodesic
No
yes thats what i am doing
okay
You are not binding to 0.0.0.0
By default it is 127.0.0.1
Docker port forwarding does not work to local host
Actually, arg is diff
kubectl proxy --port=0.0.0.0:8080 gives invalid port syntax exception
—addresss=0.0.0.0
okay
sorry, on phone so hard to type
thats working
thanks
I have Kubernetes running on a VM on my dev box. I want to view the Kubernetes dashboard from the VM host. When I run the following command: kubectl proxy –address 0.0.0.0 –accept-hosts ^/.* …
Might need to add this too
I will document this too
It’s a good question
Anyways thanks a lot, it was an instant resolution, cheers
Haha welcome! :)
Hi, someone with spare time and wants to help me out with something. I’m passing a list with maps to a resource. This works as long as there is no interpolation happening with a variable from an external source. When I do it fails and the resource complains certain keys are missing from the map.
But when I output that structure, the structure is the same, just in a different order, I can’t figure out what is wrong with it.
https://gist.github.com/maartenvanderhoef/83047f578486dce8f5995d3c728b99d3
Can you share the precise error
Error: datadog_timeboard.this: “graph.0.request”: required field is not set
Error: datadog_timeboard.this: “graph.0.title”: required field is not set
Error: datadog_timeboard.this: “graph.0.viz”: required field is not set
This sounds familiar. @Andriy Knysh (Cloud Posse) I think ran into this in one of our other modules, but I don’t remember which one
Have you tried not using a local?
For the data structure
Have you tried removing the brackets here:
Then it does work, but that wouldn’t work for my module ..
graph = [”${local.not_working_graph}”]
let me try
the thing is, i’m passing a list of maps there normally, not just one, so it’s an actual list..
but let me try just a single one.
Actually, I misread your local
Thought it was already in a list
What if you put the local in a list
I don’t have any ideas other than to try all kinds of permutations of what you are attempting to do
(On my phone)
first attempt “datadog_timeboard.not_working: graph: should be a list”
the datadog_timeboard can have multiple graph { } blocks, so it must be a list.
haha, thanks , i’ll try the other option
2nd option, same problem as initial error. When outputted I have this:
not_working = {
request = [map[style:map[type:solid width:normal palette:dog_classic] q:avg:aws.applicationelb.target_response_time.p95{targetgroup:targetgroup/qa-web-backend-web/123} aggregator:avg type:line]]
title = not_working
viz = timeseries
}
working = {
request = [map[q:avg:aws.applicationelb.target_response_time.p95{targetgroup:targetgroup/qa-web-backend-web/123} aggregator:avg type:line style:map[palette:dog_classic type:solid width:normal]]]
title = working
viz = timeseries
}
I’ll wait for the new terraform I think.
2018-07-14
@Erik Osterman (Cloud Posse) I think there is some issue with git::<https://github.com/cloudposse/terraform-aws-rds-cluster.git?ref=master>
What’s the problem?
I have create
module "rds_mysql" {
source = "git::<https://github.com/cloudposse/terraform-aws-rds-cluster.git?ref=master>"
engine = "aurora-mysql"
cluster_size = "${var.MYSQL_CLUSTER_SIZE}"
cluster_family = "aurora-mysql5.7"
namespace = "${var.namespace}"
stage = "${var.stage}"
name = "${var.MYSQL_DB_NAME}"
admin_user = "${var.MYSQL_ADMIN_NAME}"
admin_password = "${var.MYSQL_ADMIN_PASSWORD}"
db_name = "${var.MYSQL_DB_NAME}"
instance_type = "${var.MYSQL_INSTANCE_TYPE}"
vpc_id = "${module.vpc.vpc_id}"
availability_zones = ["us-west-2b", "us-west-2c"]
security_groups = ["${aws_security_group.store_pv.id}"]
subnets = ["${module.subnets.private_subnet_ids}"]
zone_id = "${var.zone_id}"
cluster_parameters = [
{
name = "character_set_client"
value = "utf8"
},
{
name = "character_set_connection"
value = "utf8"
},
{
name = "character_set_database"
value = "utf8"
},
{
name = "character_set_results"
value = "utf8"
},
{
name = "character_set_server"
value = "utf8"
},
{
name = "lower_case_table_names"
value = "1"
apply_method = "pending-reboot"
},
{
name = "skip-character-set-client-handshake"
value = "1"
apply_method = "pending-reboot"
},
]
}
but if I run terraform apply , 2 nd time it recreates the instance
-/+ module.rds_mysql.aws_rds_cluster.default (new resource required)
id: "niki-dev-commerce" => <computed> (forces new resource)
apply_immediately: "true" => "true"
availability_zones.#: "3" => "2" (forces new resource)
availability_zones.2050015877: "us-west-2c" => "us-west-2c"
availability_zones.221770259: "us-west-2b" => "us-west-2b"
availability_zones.2487133097: "us-west-2a" => "" (forces new resource)
backup_retention_period: "5" => "5"
cluster_identifier: "niki-dev-commerce" => "niki-dev-commerce"
cluster_identifier_prefix: "" => <computed>
cluster_members.#: "1" => <computed>
cluster_resource_id: "cluster-PA4BVKHSGWXDI7RT72RN2JGEZQ" => <computed>
database_name: "commerce" => "commerce"
db_cluster_parameter_group_name: "niki-dev-commerce" => "niki-dev-commerce"
db_subnet_group_name: "niki-dev-commerce" => "niki-dev-commerce"
endpoint: "niki-dev-commerce.cluster-cgxpu4rhgni7.us-west-2.rds.amazonaws.com" => <computed>
engine: "aurora-mysql" => "aurora-mysql"
engine_version: "5.7.12" => <computed>
final_snapshot_identifier: "niki-dev-commerce" => "niki-dev-commerce"
hosted_zone_id: "Z1PVIF0B656C1W" => <computed>
iam_database_authentication_enabled: "false" => "false"
kms_key_id: "" => <computed>
master_password: <sensitive> => <sensitive> (attribute changed)
master_username: "root" => "root"
port: "3306" => <computed>
preferred_backup_window: "07:00-09:00" => "07:00-09:00"
preferred_maintenance_window: "wed:03:00-wed:04:00" => "wed:03:00-wed:04:00"
reader_endpoint: "niki-dev-commerce.cluster-ro-cgxpu4rhgni7.us-west-2.rds.amazonaws.com" => <computed>
skip_final_snapshot: "true" => "true"
storage_encrypted: "false" => "false"
tags.%: "3" => "3"
tags.Name: "niki-dev-commerce" => "niki-dev-commerce"
tags.Namespace: "niki" => "niki"
tags.Stage: "dev" => "dev"
vpc_security_group_ids.#: "1" => "1"
vpc_security_group_ids.1052271664: "sg-0774db77" => "sg-0774db77"
Probably something making it not idempotent
I cannot look at it now though - on my way out
The problem looks like your AZ map is not static
no problem, initially i though it can be due to either you are calculation azs or subnets counts somewhere
Consider hardcodifnit
Hard coding it
Or at the very least sorting it
Already did that ` availability_zones = [“us-west-2b”, “us-west-2c”]`
Hrmm I see
That is the line of investigation I would pursue
We used this module for multiple enagagemebrs
Probably a regression caused by a newer version of terraform
Show me your subnet invocation
module "subnets" {
source = "git::<https://github.com/cloudposse/terraform-aws-dynamic-subnets.git?ref=master>"
availability_zones = ["us-west-2b", "us-west-2c"]
namespace = "${var.namespace}"
stage = "${var.stage}"
name = "${local.name}"
region = "${var.kops_region}"
vpc_id = "${module.vpc.vpc_id}"
igw_id = "${module.vpc.igw_id}"
cidr_block = "${module.vpc.vpc_cidr_block}"
nat_gateway_enabled = "true"
}
hardcoded here as well
Hrmmm yea was going to be my other suggestion
You can try upgrading / downgrading the AWS provider
Hrmmm can you check the status of your 2a az?
AWS takes zones out of commission
Though unlikely in us-west
Also, not all services are available in all zones
Try a different az selection and see if it makes a difference
Also try reducing to just 2, for example
And don’t include the 2a
okay
But their weird thing is it’s saying you are going from 3 => 2
As an outsider, it looks like you previously provisioned the cluster in 3 az and now want to shrink it
That will destroy the cluster
Terraform is not a good tool for that kind of automation
it never actually happened and i verified that
Hrm odd indeed
i have actually destroy the module and recreated also
and the aws console shows 2 azs only
this looks more of an issue on terraform
Ya…
@mcrowe are you using the RDS cluster module?
2018-07-15
For my info, what is the reason to both specify vpc subnets and ec2 availability zones ?
If you leave out availability zones it will work out most likely. The subnet group defines the azs.
availability_zones - (Optional) A list of EC2 Availability Zones that instances in the DB cluster can be created in
Yea that’s a good suggestion @maarten
@rohit.verma
Has there been a discussion about whether having security groups defined inside modules along the resource of purpose is OK or not, like with the rds module ? I personally dislike it a lot as I used ot create modules which did exactly that. It makes migrations extremely complex in some cases. Next to that the AWS/Terraform security group implementation is poor enough on itself, so it’s something I’m extremely careful with. Having vpc_security_group_ids as list variable for a module is a lot simpler and safer I think.
@rohit.verma Can you show us the output of terraform plan?
@maarten yes/no, but to your point, this module does not do it correctly
@Erik Osterman (Cloud Posse) uploaded a file: image.png
is bad practice. We should use security group rules for stability/interoperability with other modules
i think it’s ok, so long as the module returns the security group, so that other modules or consumers can add rules.
@Erik Osterman (Cloud Posse) If you define a SG with inline rules, it is very problematic to add additional rules using security group rules. We ran into this and removed all inline rules to support the intra-module flexibility
From https://www.terraform.io/docs/providers/aws/r/security_group.html
At this time you cannot use a Security Group with in-line rules in conjunction with any Security Group Rule resources. Doing so will cause a conflict of rule settings and will overwrite rules.
Provides a security group resource.
yes, 100%
we need to remove these inline rules
but also to @maarten point, i think we need to add the option of moving the SG outside of the module too
we had this problem at gladly too and it complicated migrations.
added issues
what consider removing security group from the resource in the module, or making it an optional parameter why complicates interoperability with other modules reported by @maartenvanderhoef
i am open to discussion around this. @Igor Rodionov @jamie @mcrowe and @Andriy Knysh (Cloud Posse) probably have more thoughts
let’s decide on something.
@Erik Osterman (Cloud Posse) what module is that?
terraform-aws-rds-cluster - Terraform module to provision an RDS Aurora cluster for MySQL or Postgres
@maarten @Erik Osterman (Cloud Posse) and @mcrowe, thanks for your suggestions. For the time being i have actually added all 3 availability zones, anyways as mentioned the instances are created in provided subnets only, so it don’t impact anything
2018-07-17
hi team, did any one tried kube2iam with eks and got it working?
Use Kiam
kiam has master agent configuration
Crap
i don’t understood how to schedule master
eks have no master nodes
You might need to have a pseudo master tier
On phone
Kube2iam has a lot of serious issues
this is a bit concerning, is there something else we should be using?
yes, kiam will work out-of-the-box for you guys using our helmfile
i can show @Max Moon
This still needs to be discussed, I’ll gladly take a look at it on Monday when I’m back in the country
If you could put together a list of these serious issues I can take a look at before then, that would be great.
Geodesic is the fastest way to get up and running with a rock solid, production grade cloud platform built on strictly Open Source tools. https://docs.cloudposse.com/geodesic/
Thanks, I will take a look at that. Do you have a list of github issues about kube2iam?
Sec
Kiam bridges Kubernetes’ Pods with Amazon’s Identity and Access Management (IAM). It makes it easy to assign short-lived AWS security…
FWIW, gladly and PeerStreet have both had issues
And Joany
Gladly is evaluating Kiam
It has its own set of issues :-)
But has a dedicated following and a channel now in the official kube Slack team
sorry didn’t got that, what is pseudo master tier on phone ?
Any interest to collaborate on our EKS modules?
sure i will
I am on my phone - hard to type :-)
okay, no problem
Bagel in other hand
ah ha
take your time
also to support eks, you have to make changes to your subnet module
i will send pr, small change
Ok many thanks
just when you got time, tell me about psuedo master,
if i promote any worker to act as master, i can’t run anything on it which need role assumption
Yes, want to review the EKS modules I am working on with you
2018-07-18
@rohit.verma are you around?
i can share now
(or later today - ping me)
Just dropped a PR for elasticache-redis, need to be able to pass the encrypt at rest / enable TLS flags. Should be backwards compatible with previous releases (e.g. defaults to false on both). No idea if this is how you prefer I contribute, but let me know: https://github.com/cloudposse/terraform-aws-elasticache-redis/pull/15
thanks @jonathan.olson
@evan @Max Moon @Daren @chris might be interested in this enhancement for encryption at rest and TLS
@dave.yu also a heads up, we might need to do this: https://github.com/cloudposse/geodesic/issues/180
what Set memory and CPU limits for Kiam why Kiam may have a memory leak references uswitch/kiam#72 uswitch/kiam#125
(reported by @Daren)
they are seeing memory leaks in kiam
(and possibly some excess network traffic)
2018-07-19
We just released Cloud Posse reference architectures:
https://github.com/cloudposse/terraform-root-modules - Collection of Terraform root module invocations for provisioning reference architectures https://github.com/cloudposse/root.cloudposse.co - Terraform Reference Architecture of a Geodesic Module for a Parent (“Root”) Organization in AWS https://github.com/cloudposse/prod.cloudposse.co - Terraform Reference Architecture of a Geodesic Module for a Production Organization in AWS https://github.com/cloudposse/staging.cloudposse.co - Terraform Reference Architecture of a Geodesic Module for a Staging Organization in AWS https://github.com/cloudposse/dev.cloudposse.co - Terraform Reference Architecture of a Geodesic Module for a Development Sandbox Organization in AWS https://github.com/cloudposse/audit.cloudposse.co - Terraform Reference Architecture of a Geodesic Module for an Audit Logs Organization in AWS https://github.com/cloudposse/testing.cloudposse.co - Terraform Reference Architecture that implements a Geodesic Module for an Automated Testing Organization in AWS
They show how we provision AWS accounts and what Terraform modules we use. Complete description is here https://docs.cloudposse.com/reference-architectures
Thanks everybody for your contributions. We will be improving the repos and the docs. Your input and PRs are very welcome.
Awesome team, thanks for open sourcing
Hi Team, I’m writing a naming/tagging strategy document. I would love another set of eyes on it and suggestions. As far as I can I’m using the cloudposse terraform naming convention, but I needed to extend it to cover a larger number of scenarios.
Sorry, just fixed the access
try and click again now
Permission to comment in the doc is enabled.
wow, great document
very detailed
I think you have everything covered there
Hah, well, thats kind of you. But critical feedback will help me improve it
nice doc @jamie
here is some feedback
1) we usually use namespace as a company name or abbreviation so we can distinguish the company’s resources from other companies resources (but it’s your choice to expand its usage as you described in the doc)
2) the third part in our naming (label) pattern is name, not role. The difference is what it does vs. what it is. Those could be just small differences, but we usually try not to use the resource types in resource names, e.g. we don’t use cp-prod-subnet-xxx-yyy-zzz but instead cp-prod-app1-xxx-yyy-zzz to name a subnet. But I think your doc has described both cases
1) As it is a single company, but with 6 different divisions i was wanting to have them use it for that instead
2) Role is a suggested tag from AWS for categorisation, and i wanted to have them group resources as needed by the role.
As in role: frontend or cmsstack
the only issue with that (and why we use a company name as the namespace) is to name global AWS resources like S3 buckets. Could be naming collisions if not used properly
I wanted to disambiguate the Name input from the Name output (id) that the label module does, but as a convention document.
Which is why i changed from name to role.
Well, I can tell you from years of field experience that most people don’t even have the document for the tags, but plenty of tags they want to use
So you end up with a giant cluster f*$! of mismatched tags with very little direction, and plenty of weird dependancies and gotchas baked into the system.
So, touch somethign and watch the dumpster start burning
Having a document like that to start with is a solid way of moving, good footing from the start is a powerful position for sure
what it is vs what it does is a very valid point.
Haha, well thats good news @krogebry - its for a transformation project one of my clients have. They have a monolith of aws EC2 instances, and are moving to serverless and docker microservices. And they have hired new teams and such, so before the big work starts on the transform i’m wanting to get a a few standards in place for consistancy
nice
yeah, that’s solid, I’ve done that work to transform, doing that work now
if you use role as a name, it should be role from the business point of view, not resource types point of view. Although in some cases it’s difficult to assign names (yes, naming is hard)
i'm wanting to get a a few standards in place for consistency - very valid point @jamie
Whats that saying you have about naming?
There are only two hard things in Computer Science: cache invalidation and naming things – Phil Karlton (bonus variations on the page)
Love that
I may put that as a footnote.
Jamie this is awesome. I will take a closer look later today. At first glance love the selection of tags.
Access controls via tags is only sometimes supported
Ha, thanks Erik. Yeah, I have the list
Maybe add a note in regards to that. It should be used as a last resort IMO
For stage segregation, tags are not well suited since there are resources which do not even support tags
I’m gonna do a policy that means that anyone in the ‘developer’ group that wants to create new resources from that list, must apply tags at creation. As well as to ‘start’ a resource.
That way the greenfields stuff has to have tags, even if they are not awesome.
That is cool. Enforcing tags at some level would be a nice account level module!
Maybe i can see if I can just make a cloudtrail metric alert that looks for missing tags on creation, and notifys slack, or a dashboard via sns
Btw love the font in your doc
Oh thanks
More of a ‘soft’ way to enforce it
and implement the hard enforcement if required.
Can I offer an idea on that front?
I just did something with the tags on this client wrt missing tags
It’s an idea that Intuit implemented, but geared for tags.
Sure!
Alright, so Intuit started this with an “up and to the right” progress over perfection initiative with regards to the overall security of any given account that ran a service ( mobile stuff, mint, etc… ). I’ve implemented the same idea with various different things including pager duty noise levels.
Start with a simple code base ( lambda could work, or ruby+docker+jenkins, whatever ), analyze tags, then create a grading metric. So, A for >90% compliance, B for compliance of >80% >90%, C,D,F etc.
Or just go with the numeric, but i think there’s almost a cognitive hook on the grades.
I usually end up representing these as graphs in Jira
I was thinking I would use https://www.terraform.io/docs/providers/aws/r/config_config_rule.html
Provides an AWS Config Rule.
A config rule, to do the checks
@krogebry So this is in terms of bringing an account into compliance?
@krogebry uploaded a file: Screen Shot 2018-07-19 at 11.13.49 AM.png
Yeah, so forcing compliance from resource creation can work, but does get in the way.
However, a stance of “progress over perfection” usually works better in the transformation world of things.
Like, the reality is that you’re probably not going to get people to conform to tags right away, and in some cases you can’t enforce things because enforcing the standard might actually break things.
So the idea is the Riot sort of mindset where we’re just trying to move things up and to the right, or progress over time.
Usually more effictive when dealing with people who are maybe a little timid around big changes.
</rant cents=”2”>
@krogebry agree. But how do you do it from the automation point of view? E.g. we create and provision TF resources without tags (or with some tags), and then use the process to validate the tags and then update all the resources from TF?
@Andriy Knysh (Cloud Posse) with aws config rules you can have it provide a compliance report based on your terraform resources https://docs.aws.amazon.com/config/latest/developerguide/evaluate-config_manage-rules.html
Use the AWS Config console, AWS CLI, and AWS Config API to view, update, and delete your AWS Config rules.
nice
So instead of hard enforicing it, it can just be dashboard
Okay, I can tell you a tale of woe as to how not to do it
and its something that could be a TF module easily
Yeah, so you’re on the right track, basically you have two good options: either enforce it from the creation of things, or enforce it later with some kind of dashboard/report’y thingie
If you enforce at creation the only real risk is the timing with things, so in many cases the tag creation is a secondary action after the resource is created
So you just have to be aware of that, if you do something like “kill instance if tags are missing” with an ASG, you’re going to have a bad time because of the timing stuff.
yea, that’s why naming is hard
It would be neat to have some kind of way to have TF actually enforce the naming conventions with if conditionals
Might be an option in 0.12?
Its an option now
using my nifty hack
ohh, with config rules?
so I think it’s good to combine the two strategies: 1) enforce some rules at creation; 2) check it after creation and alert/dashboard
yeah, okay, I can see how that would be pretty awesome with config rules
variable "failure_text" {
default = "The values didn't have the values needed"
}
variable "conditional" { default = true }
resource "null_resource" "ASSERTION_TEST_FAILED" {
count = "${var.conditional ? 1 : 0}"
"${var.failure_text}" = true
}
im curious, is this pseudo code or you actually have this working?
It’s working
It’s works great. I wrote an article on it :)
And it gets referenced here https://github.com/hashicorp/terraform/issues/2847
It would be nice to assert conditions on values, extending the schema validation idea to the actual config language. This could probably be limited to variables, but even standalone assertion state…
Thats the entire assert module I have
you would use it like
module "assert_name_length" {
source = "thatmodulepath"
failure_text = "Your name is too long"
conditional = "${length(var.name) < 63}"
}
nice hack @jamie
Although @Andriy Knysh (Cloud Posse) actually won’t touch it, because he hates hacks
So its just for my own compliance checks for now
for a few reasons :
understandable
breaking changes and all
- As a user of the module, you instantiate the module in TF and you add/change the assertion code - looks like you just control yourself
- Little bit difficult to read
But that module has worked since at least version 0.9
I added it because I had a client just filling in tf vars files
So they wouldn;t have tf access, and it would go through a pipeline
but i agree something like that is needed
so, i was using it to cause a TF error and message when their vars were flakey
for 0.12
Error: Error running plan: 2 error(s) occurred:
* module.elasticache_redis.module.dns.var.records: Resource 'aws_elasticache_replication_group.default' does not have attribute 'primary_endpoint_address' for variable 'aws_elasticache_replication_group.default.*.primary_endpoint_address'
* module.elasticache_redis.output.id: Resource 'aws_elasticache_replication_group.default' does not have attribute 'id' for variable 'aws_elasticache_replication_group.default.*.id'
@Daren have you seen this with yours/our TF module for redis
Yes
We are using auth_tokens and if the token is not valid for AWS this happens
ok, i think that could be related to our issue
We used:
resource "random_string" "redis_auth_token" {
length = 16
override_special = "!&#$^<>-"
}
@jamie
I have grown to dislike “terraform_remote_state” data provider
I love the data provider.
In directories (origin) where another directory (client) is expected to read the state, I create a lib/remote_state.tf in the origin directory.
The (client) directory has a symlink to the lib/remote_directory.tf file, and leaves all the implementation details up to the (origin).
example: https://github.com/tamsky/terrabase/blob/master/aws-blueprints/core/lib/remote-state.tf
Contribute to terrabase development by creating an account on GitHub.
Its all we have but my list of gripes are:
- It hard binds one tf template to another: I.e. even using variables to choose a state to use at first run, you can’t search for a state to use, or select states by relative paths. Because the s3 bucket has to be unique.
- You have to have an agreed naming structure to use a state, and there are no standards, so each setup will be different.
- It does have default values, but no way to provide a wildcard default, so that you can query for a value that doesn’t exist. I.e. If you are using version 1.0.1 of a tf template that has an output string “alb_frontend_sg” but in version 1.0.2 you have changed it to a list “alb_frontend_sgs”. And your remote state is changed to query for “alb_frontend_sgs”, if you need to roll back to version 1.0.1. You would get an error looking for “alb_frontend_sgs”. While it is good practice to error, it doesn’t allow you to create terraform level exception handling. Such as querying for both variables, and outputting the value that isn’t an empty string.
Contribute to terrabase development by creating an account on GitHub.
if you could get the outputs of terraform_remote_state as a map, and do a lookup, it would help that last part on unknown outputs at the code level. And you can workaround that last part if you have easy access to the terraform_remote_state data provider, as you could add both alb_frontend_sgs and alb_frontend_sg as default values.
that’s nice @tamsky
2018-07-20
Hey everybody! Proud to join the SweetOps crowd… this is a great initiative, seems like a real missing piece.
I have a quick q regarding the reference architectures, which operate under root.company.com, staging.company.com and prod.company.com etc. Where/how, in this setup, would I set up top-level DNS mappings, e.g. CNAME record referencing company.com -> prod.company.com, app.company.com -> app.prod.company.com etc? Would this be in the root module?
@Sebastian Nemeth I can help answer in a few hours.
Great! Thanks very much. I’m trying to get rolling with geodesic and some basic stuff as we speak.
also, let’s move the conversation to #geodesic so it’s not lost in the noise
btw, let’s start using #geodesic so we can concentrate knowledge
@Andriy Knysh (Cloud Posse) might be around to answer some questions related to this.
Have you seen this? https://docs.cloudposse.com/reference-architectures/cold-start/
Sorry for the messed up css
We are still refining that doc to make it more clear
I’m following it now, but it’s taking some cross-referencing. e.g. it tells me to install aws-vault, but then I read that it’s included in geodesic, so trying to figure out best way to use geodesic and where to keep the credentials store.
Great of feedback. Agree. Credentials will be stored in an encrypted key chain file
Inevitably you will want to use AWS vault natively as well. E.g. docker compose
But you don’t need to install to get started, so we should not make that a step so early on
Actually, @Andriy Knysh (Cloud Posse) and I were talking about just this yesterday.
I don’t mind installing aws-vault, but if its already installed in geodesic maybe it’s better to just run geodesic while mounting a local volume to store credentials for our developers.
@tamsky thanks for the bug report on https://github.com/cloudposse/terraform-aws-alb-target-group-cloudwatch-sns-alarms! Just addressed the arn_suffix issue with a PR - just waiting on an approval and should be merged in…
Also just a heads up that I found and fixed an edge case here, would love a quick review and any comments/suggestions on the solution: https://github.com/cloudposse/terraform-aws-alb-target-group-cloudwatch-sns-alarms/issues/8
terraform-aws-alb-target-group-cloudwatch-sns-alarms - Terraform module to create CloudWatch Alarms on ALB Target level metrics.
what AWS CloudWatch Alarm Thresholds should be assumed to contain floats when used in conditionals. why Fix the following case: CloudWatch thresholds are specified in seconds, which results in spec…
whoops sorry Jamie - just committed this too: https://github.com/cloudposse/terraform-aws-alb-target-group-cloudwatch-sns-alarms/pull/9/commits/dfdb45d0a293cb745a6d40e153e2b3a0cf991578
what Wrap thresholds with a floor to convert to int before comparing to 0. why Fixes #8 and #6
didn’t think it was worth it’s own PR for that since it is just cosmetic
maybe target_response_time_alarm_enabled = "${floor(var.target_response_time_threshold) < 0 ? 0 : 1 * local.enabled}"
should be the one without a floor
ah yea its confusing
Hi there! I am evaluating using geodesic for my organization and curious to discuss some kubernetes cluster related patterns.
Sure thing! You can direct message me or shoot me an email ([email protected])
Our current kubernetes architecture is captured in this kops manifest:
https://github.com/cloudposse/geodesic/blob/master/rootfs/templates/kops/default.yaml
Geodesic is the fastest way to get up and running with a rock solid, production grade cloud platform built on strictly Open Source tools. https://docs.cloudposse.com/geodesic/
also, let’s move the conversation to #geodesic so it’s not lost in the noise
since it is actually float
@Yoann hi, welcome
i think you mean the other way around right @jamie since reponse time is the one that is a float?
so only wrap floor() for var.target_response_time_threshold so it converts that to an int and can compare to 0 safely
Lets try it in terraform console
where var.target_response_time_threshold is 0.5
> floor(0.5) < 0
false
> 0.5 < 0
false
>
So it evaluates fine
hmm
ah right
string
try “0.5” < 0
> floor(0.5)
0
> floor("0.5") < 0
false
> "0.5" < 0
__builtin_StringToInt: strconv.ParseInt: parsing "0.5": invalid syntax in:
${"0.5" < 0}
> floor("1") < 0
false
> floor("-1") < 0
true
but when you do the extrapolation
it shouldn’t be a string
thats the exact error you get currenly in latest stable when trying to set response time to 0.X: __builtin_StringToInt: strconv.ParseInt: parsing “0.5”: invalid syntax in:
ah
well then…. floor it is!
haha
Although this should change in 0.12
i wrapped the others to be safe - but obviously we should not expect a count to be a float
What if you took the quotes off the variable?
defaults
nah.. don;t worry about that
just floor it
i agree with erik there too - < 0.12 this is the most sane way to work with terraform i.e. strings, maps, lists
Yeah
I have a really large stack of metric alarm notes
For things like, containers per instance alarm
and ‘lambda max concurrent execution alarms’
and ‘rds database level custom metrics -> alarms’
Which im looking forward to adding to our arsenal
Oh and billing alerts
i copied some already for the module we were talking about
def good stuff - thanks for sharing it!
haha
I hope you plastered my face across the footer
of course
@jamie if you got a sec: https://github.com/cloudposse/terraform-aws-alb-target-group-cloudwatch-sns-alarms/pull/7 - CR please and I’ll owe you a
what Fix the dimensions by removing unnecessary join in interpolation why Fixes #4 Terraform will perform the following actions: ~ module.data_model_web_app.module.ecs_codepipeline.aws_codepipe…
or a CR whichever
Checked
Verified
lgtm
ty ty
Just a heads up - released 0.4.0 for https://github.com/cloudposse/terraform-aws-alb-target-group-cloudwatch-sns-alarms. This fixes a few reported issues: https://github.com/cloudposse/terraform-aws-alb-target-group-cloudwatch-sns-alarms/issues/8 https://github.com/cloudposse/terraform-aws-alb-target-group-cloudwatch-sns-alarms/issues/4 https://github.com/cloudposse/terraform-aws-alb-target-group-cloudwatch-sns-alarms/issues/6
Thanks to @tamsky, @Erik Osterman (Cloud Posse), @jamie!
terraform-aws-alb-target-group-cloudwatch-sns-alarms - Terraform module to create CloudWatch Alarms on ALB Target level metrics.
what AWS CloudWatch Alarm Thresholds should be assumed to contain floats when used in conditionals. why Fix the following case: CloudWatch thresholds are specified in seconds, which results in spec…
currently at https://github.com/cloudposse/terraform-aws-alb-target-group-cloudwatch-sns-alarms/blob/master/alarms.tf#L10-L11 we have: "TargetGroup" = "${join("/", list(&qu…
what what we’re mixing snake case with camel case why bad convention
thanks for the quick fix! like the use of floor().
terraform-aws-alb-target-group-cloudwatch-sns-alarms - Terraform module to create CloudWatch Alarms on ALB Target level metrics.
what AWS CloudWatch Alarm Thresholds should be assumed to contain floats when used in conditionals. why Fix the following case: CloudWatch thresholds are specified in seconds, which results in spec…
currently at https://github.com/cloudposse/terraform-aws-alb-target-group-cloudwatch-sns-alarms/blob/master/alarms.tf#L10-L11 we have: "TargetGroup" = "${join("/", list(&qu…
what what we’re mixing snake case with camel case why bad convention
Issue 6 was mixing case because the cloudwatch metric names are in
So that there was a 1:1 for name recognition
Originally
Since we have to use modules with terraform and really don’t have a desire to buy TF Enterprise just to get a “registry”, I was thinking of writing a little utility that will:
• parse through your TF project
• find any modules, then grab the source repo
• compare what version you have to the latest available in the source repo and then output if there is a new revision/tag compared the one being used
I think @mcrowe did wrote something similar
would like something like this though
hmm nice i’d love to see it - i might just write one on my free time anyway so i have an excuse to write a go utility with cobra
yea, go would be my pref!
this example is a bash script
ah cool!
i also think it would be a popular utility for the community
yea i feel like can benefit from concurrency here - but of course already thinking about github api limits
there’s some way also to convert HCL to json
also, what’s nice with mike’s script is it can generate the composite outputs from all module deps
@Erik Osterman (Cloud Posse) uploaded a file: image.png
@sarkis you can start with something like this https://github.com/kvz/json2hcl. It shows what terraform packages to use for parsing, or you can convert hcl to json which is easier to analyze
json2hcl - Convert JSON to HCL, and vice versa
hey all, just want to invite those interested to #geodesic and #terraform
it might help organize information and get questions better answered if we distribute the traffic
set the channel topic: Cloud Posse Open Source Community #geodesic #terraform #random #releases #docs
2018-07-23
Hey guys, can you give me some idea why the term ‘stage’ was chosen over ‘environment’? In the label module?
@Erik Osterman (Cloud Posse) uploaded a file: Image from iOS
See #2
There are multiple stages
It’s where software performs
The term environment is also overloaded and often abbreviated as env
Which from my subjective experience more confusing. Stage imo is misused inside many organizations and I guess I made it our personal mission to correct its usage
However I could maybe consider adding environment after stage as another (optional) dimension of disambiguation
I have used environment in all other projects as the term to encapsulate the resources for development vs production.
And I think it is quite a common use, but I do understand the ambiguity issue.
How the term environment means, environment variables, it the old word for terraform workspaces as well.
My issue with the term stage is the implicit temporal nature it has. Like a stage in a pipeline or rocket is something that gets used and is destroyed.
But environment describes what surrounds something, and doesn’t imply any permanency, or lack of.
So for describing a split between production and preproduction, where the application is exactly the same build asset, but the configuration and attached resources are different. I align more with environment.
It feels like environment is something that should be encapsulated in a module
Thus the environment is baptized with name
Then resources with in that are disambiguated with attributes to that environment name
Couldn’t it be argued that the root level module invocation is the environment?
I align more with environment for the same reasons Jamie has mentioned. I’m also not a fan of envas an abbreviation.
What about adding more optional fields to the label module
Perhaps along the lines of Jamie’s document on canonical tag names
If not passed, they are not concatenated
Stage and environment can be adjacent, that way the caller can use what it’s most natural to their organization
I think this would satisfy both requirements. Thinking environment would be concatenated after stage.
It’s a non breaking change so I think it’s good idea
Stage can then be specific to things like. Source. Build. Test. Tag. Release. As well.
In any case it will add flexibility to the module that allows me to use it in different clients
agreed - and we want to support other use-cases too so lets do it
Terraform Module to define a consistent naming convention by (namespace, stage, name, [attributes])
see that?
what Support passing a label's context between label modules why DRY demo module "label1" { source = "../../" namespace = "Namespace" stage = &…
I’ll update it
So what’s the name for the env between dev and prod?
that might be staging. note, that staging is not the same word as stage.
@Erik Osterman (Cloud Posse) uploaded a file: image.png
could be QA, UAT, preproduction
so “dev” is a stage
production is a stage
it’s a stage in a lifecycle

A multistage rocket, or step rocket is a launch vehicle that uses two or more rocket stages, each of which contains its own engines and propellant. A tandem or serial stage is mounted on top of another stage; a parallel stage is attached alongside another stage. The result is effectively two or more rockets stacked on top of or attached next to each other. Taken together these are sometimes called a launch vehicle. Two-stage rockets are quite common, but rockets with as many as five separate stages have been successfully launched. By jettisoning stages when they run out of propellant, the mass of the remaining rocket is decreased. This staging allows the thrust of the remaining stages to more easily accelerate the rocket to its final speed and height. In serial or tandem staging schemes, the first stage is at the bottom and is usually the largest, the second stage and subsequent upper stages are above it, usually decreasing in size. In parallel staging schemes solid or liquid rocket boosters are used to assist with lift-off. These are sometimes referred to as “stage 0”. In the typical case, the first-stage and booster engines fire to propel the entire rocket upwards. When the boosters run out of fuel, they are detached from the rest of the rocket (usually with some kind of small explosive charge) and fall away. The first stage then burns to completion and falls off. This leaves a smaller rocket, with the second stage on the bottom, which then fires. Known in rocketry circles as staging, this process is repeated until the desired final velocity is achieved. In some cases with serial staging, the upper stage ignites before the separation—the interstage ring is designed with this in mind, and the thrust is used to help positively separate the two vehicles. A multistage rocket is required to reach the escape velocity of 11.186 km/s (25,020 mph) from Earth’s gravity.
stage 1, stage 2, …. stage n.
A file, which can’t be shown because your team is past the free storage limit, was commented on.
I think I like UAT
It’s descriptive as to what it actually does
“Stage” is like you say, it’s a part of the rocket, but it doesn’t actually define what it’s doing
I like y’all in this group, really makes me think about the important questions
2018-07-24

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Suggestions on additional sections, or technologies to cover, or core concepts are very welcomed!
Can i just paste questions I’ve asked recently beneath it and don’t care about formatting ?
Yes! You can also use the comment feature
Less Meta , hard to keep an interview < 1h and to also ask a few easy questions to make the candidate feel at ease.
Thank you very much!
I was also providing question answer formats because I am not the one hiring them
@jamie as always, very nice doc, thanks for initiating these conversations
Met with @tamsky yesterday. He has also lots of nice things to say about your docs.
I had to move the document for the client. If you want to access the document still, whoch you are welcome to. Here https://docs.google.com/document/d/1yO7qgVyfKwPpK6EzBv0w64TzDOAUfCnE_nCEYX4maJg/edit?usp=sharing
It will need you to request access though guys. @Erik Osterman (Cloud Posse) @Andriy Knysh (Cloud Posse) @tamsky
Curious @jamie– is there a LICENSE for your https://github.com/firmstep-public/trainingdayone ?
trainingdayone - Day One: Using the Terraform command, creating a resource, and managing Terraform state.
@tamsky in regards to trainingdayone’s license. Thanks for asking. Do you want to use some of it? Or add to it?
It would be the MPL 2.0 license. So that I would be notified of any improvements if there were any.
I may want to use it - just checking in – I like the order and how you introduce the concepts.
Firstly if I post it in here. Take it if you want. It’s the cost I pay for the quality feedback.
Secondly, if I can help you improve it let me know. If you’re interested let’s do a slack video or something to rough out improvements
It’s a good investment in time for me and anyone else. As it’s very reusable
Thank you @Andriy Knysh (Cloud Posse) :-)
@pmuller hi and welcome
i have exposed kubernetes dashboard with bitly oauth proxy as we do with cloudposse portal
can we pass the dashboard token
somewhere within bitly redirect etc..
or for that kind of login we have to use dex
thanks!
funny how nice slack channel mostly live… during the night
(UTC+8 here)
i discovered your github a few days ago, and i love it
i am learning so much thanks to you guys !
(Cloud Posse is based in Los Angeles, CA)
Awesome! Glad to hear your getting some mileage out of it.
since when all of this is on GH ?
We’ve been publishing our modules for the past 2 years , but we only really started promoting them this year when we doubled down on our documentation, readme’s and community.
i thought i had a lot of not-that-nice patterns in my code base.. now i know for sure
thanks! would be happy to give you a tour of the complete open source ecosystem. we have A LOT so it can be hard to see the trees through the forest.
set the channel topic: Cloud Posse Open Source Community #geodesic #terraform #release-engineering #random #releases #docs
2018-07-25
Hey guys, pretty sweet collection of blocks. I’ve been swaying between the aws community modules on Terraform and yours. I have a quick question - terraform-aws-cicd <— I believe this module does not support multi-container beanstalk, is that correct? (using beanstalk for first time with new org.)
@tpagden welcome
correct, the module does not support multi-container beanstalk
you can open an issue for that and we’ll review
or use ECS instead
Expert Cloud Architects DevOps Professional Services
@Andriy Knysh (Cloud Posse) Cool, no problem at all. I was just confirming what I saw and that I didn’t miss anything. I’ll mull over some of the options
@Andriy Knysh (Cloud Posse) One more question - I know you all have avoided doing a wrapper approach (such as Terragrunt), which I’m inclined to avoid as well, however, do you all have a recommended directory structure approach that you recommend? Like live/non-prod/{region}/application ? If so, do you separate the application directories from infrastructure (like VPC) ?
We use containers instead
So we package all of our terraform invocations in one repo. Then we use docker Multi Stage builds to copy them. Have a look a look at our reference architectures
The Dockerfile shows our strategy
You could say we deploy infrastructure as code the same way we deploy applications.
So we don’t have our apps broken out into production and staging folders. We have then containerized. Then we deploy those containers. We think infrastructure code should be treated the same way.
@Cristin we still recommend to separate all resources into at lest two stages (dev and prod) and don’t mix anything b/w/ them
terraform-root-modules - Collection of Terraform root module invocations for provisioning reference architectures
staging.cloudposse.co - Example Terraform Reference Architecture for Geodesic Module Staging Organization in AWS.
This is how we deploy those modules for a staging account.
it’s wrapper approach (such as Terragrunt) vs. container + ENV vars approach. We use the second one
Yea that’s a succinct way of putting it. @Andriy Knysh (Cloud Posse) I should probably add that to the geodesic readme.
yep, naming is important, not only for TF resources
but also for patterns and approaches
next time somebody asks what approach we use, we can say container + ENV vars (or something like that maybe with a better name)
I added a #jobs channel where people can post if they are looking for work or are hiring (FTE or contractors).
2018-07-26

Today we’re launching new ways to simplify your CI process, so you can use the tools you need to focus on the work that matters to your team.
Finally getting some of those awesome GitLab features.
Today we’re launching new ways to simplify your CI process, so you can use the tools you need to focus on the work that matters to your team.
2018-07-27
@Erik Osterman (Cloud Posse) I am working on updating the aws cloud front module to allow me to disable alias creation. https://github.com/cloudposse/terraform-aws-cloudfront-cdn/issues/14. I want to add a boolean dns_aliases_enabled. If the value is false no alias will be create. I see that DNS records are created using module “dns”. If DNS was created with resource I can set the count = “${var.dns_aliases_enabled}”. False is 0 so no record will be created. As far as I know I cannot pass in “count” to a module. Only option I see is to modify the module that creates DNS to take in count parameter. I am wondering if you have any suggestion for me.
We are hosting 5 different sites in AWS. All of them are behind the same ALB. We want to put CDN in front of all these sites. When I was creating CDN using your module I specified aliases for all t…
Correct, first we need to update the dns module to add that flag
Then we can do this module.
It is great to be here. Thanks for creating these modules. I have a consulting company and one of our clients is using terraform. They told me that cloudposse writes excellent modules.
I will also add web_acl_id parameter to the cloud front module.
Thanks @rajcheval !!
Can we add the web acl id as a separate PR? Just so we can be more pedantic about how we introduce changes.
yes this makes sense. adding web acl id is an easier change and I will keep it separate.
I am looking at the https://github.com/cloudposse/terraform-aws-route53-alias/blob/master/main.tf. It currently calculates the count based on number of elements in the aliases array. I am wondering how I will pass in a count parameter and still keep the current module usable. Current users are not setting count and relying on count being calculated by number of elements in array. Is there a way to not invoke the module that creates dns at all. There is a new beta for terraform and they are making a bunch of enhancements. Perhaps I need to see the language enhancements that may help us.
terraform-aws-route53-alias - Terraform Module to Define Vanity Host/Domain (e.g. [brand.com](http://brand.com)) as an ALIAS record
@rajcheval hi, give me 1 min I’ll show you how to do it
first, it will work now w/o any modifications if you provide var.aliases as an empty list, count will be 0 and nothing will be created
resource "aws_route53_record" "default" {
count = "${length(compact(var.aliases))}"
if we want to introduce var.enabled to be more specific (as we have in other modules), we do this:
count = "${var.enabled == "true" ? length(compact(var.aliases)) : 0}"
variable "enabled" {
type = "string"
default = "true"
description = "Set to false to prevent the module from creating any resources"
}
For <https://github.com/cloudposse/terraform-aws-cloudfront-cdn>, it will work now w/o any modifications if you specify an empty var.aliases
module "dns" {
source = "git::<https://github.com/cloudposse/terraform-aws-route53-alias.git?ref=tags/0.2.2>"
aliases = []
if we add var.enabled to route53-alias, then we can add var.dns_aliases_enabled to cloudfront-cdn and use it like this:
module "dns" {
source = "git::<https://github.com/cloudposse/terraform-aws-route53-alias.git?ref=tags/0.2.2>"
enabled = "${var.dns_aliases_enabled}"
aliases = "${var.aliases}"
parent_zone_id = "${var.parent_zone_id}"
parent_zone_name = "${var.parent_zone_name}"
target_dns_name = "${aws_cloudfront_distribution.default.domain_name}"
target_zone_id = "${aws_cloudfront_distribution.default.hosted_zone_id}"
}
@rajcheval does it answer your questions?
@Andriy Knysh (Cloud Posse) passing in empty aliases is not an option because cloudfront distribution still needs aliases. However your other suggestion will work. Thank you so much for taking the time to help me. I am going to learn a lot from you.
(sorry, yes var.aliases is needed in any case, so we need to modify the modules to add enabled and dns_aliases_enabled)
@rajcheval after you make modifications and before opening a PR, run these three commands to regenerate README:
make init
make readme/deps
make readme
(not terraform-aws-cloudfront-cdn yet, this was not converted to the new README format yet. Just update README.md)
what Add README.yaml why Standardize README
@Andriy Knysh (Cloud Posse) please merge for me
Afk
100% have been updated
working on it now (it needs terraform fmt)
Just not all yet merged
@rajcheval we merged readme changes to master for https://github.com/cloudposse/terraform-aws-cloudfront-cdn
terraform-aws-cloudfront-cdn - Terraform Module that implements a CloudFront Distribution (CDN) for a custom origin.
if you open a PR, please run the three commands above to update README
@Andriy Knysh (Cloud Posse) I did run make commands to update readme. I have submitted PR’s for route53 and cloudfront. Once these are approved I will be making my final change on cloudfront resource to allow me to disable DNS record creation.
@rajcheval thanks, will review

Interviewing for a DevOps job? Here are some questions you’ll likely have to answer.
@jamie want to review ^ and maybe add to your doc?
sure do!
@rajcheval reviewed the PRs, look good, just a few comments
2018-07-30
I’ve been thinking lately that we should be training the interview skills like we train anything else
“How do you adapt when things don’t go as planned?” This question has nothing to do with devops per se, but is probably 90% of the actual job.
my buddy Ian has a great series of Tech Interview Prep emails => https://www.facebook.com/technicalinterviewprep/
Technical Interview Prep by Email. 66 likes. Improve your technical interview chances by learning to think like an interviewer. Get new insight every day for 30+ days via Email.
Nice
I have a friend that I’m going to try to convince to start up a consulting company that would specialize in training for the interview process
@Andriy Knysh (Cloud Posse) Thanks for merging my changes. I have one more PR for cloudfront resource ready for review.
@rajcheval thanks for the PR, looks good, merged to master
@Erik Osterman (Cloud Posse) if you want we can go over the specs you guys want for https://github.com/cloudposse/terraform-aws-ec2-autoscale-group and i can try to jam it out this week in my spare time
terraform-aws-ec2-autoscale-group - Terraform module provision an EC2 autoscale group
that would be awesome.
When’s good for you?
my general thoughts are that it should include:
- launch config
- autoscaling group
- basic security group (ingress + egress)
- min/max size vars
- enabled var
- volume size var
- vpc id
- user data script var (this would need to be a path using ${path.module} syntax in local module)
- elb enabled/disabled
- eip enabled/disabled
- dns record pointing to elb/eip?
- dns_zone_id var
maybe some basic security group ingress/egress rules for things like ssh/http/https
really any morning works for me
above is a broad stroke, but that’d be the general idea
Cool, tomorrow I’ll be busy until ~11:30. But free after that.
cool, just DM me
Yea, let’s move this to an issue under that repo
I know @maarten and @jamie will probably have some valuable input.
My general thoughts are that it should include the following resources: launch config autoscaling group security group dns record iam instance profile iam role Variables: min/max size enabled volum…
Ok, I’ve commented on it with some additional resources
A lot of the work has already been done by @jamie - we just need to modularize it
I link to it in the GH issue
This is massively appreciated. We need this module as one of the building-blocks for us to rollout EKS support later, as well
Nice! Okay cool, I’ll take a look at it in a bit
Also, we can roll it out in phases, if you don’t want to bite off too much at once.
That is a good idea haha
2018-07-31
hi
I am in the process of migrating terraform modules to codecommit. However, as i already use codecommit on other AWS accounts, I cannot rely on ~/.ssh/config to define a default username; but I want to keep my terraform code generic. I do not want to put my IAM user ssh key id in all module statements, otherwise my coworkers and the CI won’t be able to use them. So I tried to use interpolation in the module source to optionally define a SSH username. I ended up reading a bunch of GH wont-fix issues, then found https://github.com/hashicorp/terraform/issues/15614 which tracks precisely what I would need. So, how can I handle my use case? Any suggestion?
(This was split out of #1439, to capture one of the use-cases discussed there.) Currently all of the information for requesting a module gets packed into the source string, which cannot be paramete…
i’ve had good luck using an iam role with codecommit, and the codecommit helper for aws cli
(This was split out of #1439, to capture one of the use-cases discussed there.) Currently all of the information for requesting a module gets packed into the source string, which cannot be paramete…
i just configure my aws config file with a profile that has perms to the codecommit repo, and then add the credential helper to my .gitconfig
the module source then looks like this:
source = "git::<https://git-codecommit.REGION.amazonaws.com/v1/repos/REPO//PATH?ref=REF>"
Provides detailed steps for setting up to connect to AWS CodeCommit repositories over HTTPS on Linux, macOS, or Unix, including setting up a credential helper.
I went the https way and it works fine. Thanks.
Awesome! If you use a mac, be aware that the system gitconfig uses keychain as a credential helper and will catch and store the temporary credential… Causes problems cuz keychain doesn’t know it’s temporary… I have our team remove the credential helper from their system config
Something like this, update for whatever region(s) and aws profiles you use:
git config --system --remove-section credential
git config --global --remove-section credential
git config --global --remove-section 'credential.<https://git-codecommit.us-east-1.amazonaws.com>'
git config --global credential.'<https://git-codecommit.us-east-1.amazonaws.com>'.helper '!aws --profile default codecommit credential-helper $@'
git config --global credential.'<https://git-codecommit.us-east-1.amazonaws.com>'.UseHttpPath true
(and yeah, I would also like to avoid relying on a wrapper which would rewrite all module sources)
As far as I can tell, @loren’s suggestion is not a wrapper to git. It adds an auth mechanism to the git config
You still interact directly with the git command
Moving from one git repo such as GitHub to CodeCommit will necessarily require updating your module sources, no?
Also, using AWS services for open source implementations will often require some hacks. Just like ECR which requires also using the AWS cli to first generate credentials to docker login.
if you really want to use ssh auth to codecommit, another option is to use [override.tf](http://override.tf) and define just the source field for the module
add [override.tf](http://override.tf) to .gitignore to avoid committing it
Terraform loads all configuration files within a directory and appends them together. Terraform also has a concept of overrides, a way to create files that are loaded last and merged into your configuration, rather than appended.
Wow, didn’t know about that feature :-)
very handy if you need to move the modules around between git remotes
i need to test it with nested modules though… not too sure off the top of my head exactly how i’d specify the module name
Yea don’t see how it could work recursively
maybe nest things inside the override?
module "foo" {
module "bar" {
source = "..."
}
}
perhaps terragrunt has something to help write sources on-the-fly
i use terragrunt pretty extensively…. i think you can interpolate the top level source in the terragrunt block, but the source in any nested modules would not be interpolated… you’d have to get creative i think, with a terragrunt hook to edit the .tf file in place, after retrieving the modules…
no, that’s too late, the modules have already been cloned… hmm…
I think it’s an interesting use-case
Currently, our customers rely entirely on our git repo hosted modules
but I could see a case where they’d want to replicate them in-house, and then rewrite the base URL and pull locally
One way would be to use a HTTP proxy with url rewriting
(would only work with HTTP sources)
since we run terraform in a container (geodesic), it would be pretty easy to introduce a proxy in the mix
oh, good point, nice
oh, I did not know about tf overrides, that’s great, thank you @loren
(i’m looking into using them right now to help us solve our coldstart problem in a nicer way)
terraform-root-modules - Collection of Terraform root module invocations for provisioning reference architectures
you want to use overrides to disable the s3 remote state temporarily ?
yea, exactly!
our hack right now is to use sed
terraform-root-modules - Collection of Terraform root module invocations for provisioning reference architectures
yes i read that
so instead echo 'terraform { }' > [overrides.tf](http://overrides.tf)
i have the same issue on my side, so overrides are promising to solve a few ugly stuff (i really want to AVOID writing another tf wrapper… ;))
in the meantime, i did another attempt to solve my issue: using https to access codecommit ; now i need to prefix some terraform and git commands with aws-vault, which is not that nice… but it works well
(or aws-vault exec ... -- bash)
hehe yeah
and just operate in a session
i discovered aws-vault a few weeks ago, thanks to you guys
before i used a dumb python script i wrote to do the same
but with much less features
yea, we did that too in the beginning
do you use the aws-vault login action? love that!
https://github.com/pmuller/awsudo maybe i should archive this too now
awsudo - sudo for AWS roles
yep, love it too :))
and rotate !
yea, I should use rotate. haven’t yet.
the only thing i don’t like is that aws-vault rotate doesn’t handle MFA yet, and i don’t like the idea of allowing key rotation without MFA
yea, it’s more strict
though i think we ended up allowing self-service key changes because developers would loose their IAM keys
…so they can login to the console and generate a new key pair
guess it depends on your constraints
(but still require MFA to use keys)
so you only allow MFA device management when authenticated with the MFA ?
terraform-aws-iam-assumed-roles - Terraform Module for Assumed Roles on AWS with IAM Groups Requiring MFA
But I am definitely open to feedback
we wanted to allow new users to be able to setup their own MFA device without admin assistance
so you allow MFA management without MFA but require it to deactivate it
i have a similar policy in place
but i do not like it
but i do not require MFA to deactive MFA…yet
it means that a leaked API key or user password is enough to create a new MFA device, then use the new one to access all roles of the compromised user
Yea, looking at this again, seems like we should require MFA for that
yep !
unsure about "iam:ResyncMFADevice",
resync = allowing the user to pass 2 consecutive tokens to AWS ?
not sure I get how this could be dangerous
ok
when digging about my terraform modules / codecommit issue, i stumbled upon some “Terrafile” projects ; any thoughts about these ?
I’m not familiar with terrafile
Looks very interesting. Ultimately, what I want though is something more like this: https://github.com/dependabot/feedback/issues/118
what Open PRs against terraform repos when terraform modules have new releases Open PRs against terraform repos when terraform providers have new releases why It's an extremely diverse ecosyste…
To help us manage and keep deps up to date.
oh that’s a nice service !
i’d like the same for in house code
they support many languages and private repos
Automated dependency updates. Dependabot creates pull requests to keep your Ruby, Python, JavaScript, PHP, .NET, Go, Elixir, Rust and Java dependencies up-to-date.
we’re currently using them for Docker and Submodules.
in my current company, all repositories are in VPCs, and I cannot imagine opening this up to the internet (very sensitive code)
I think the project core is open source, you could run it in house
but for other businesses, i’ll definitely try this
heh, yea - understandable