#aws (2019-06)
 Discussion related to Amazon Web Services (AWS)
Discussion related to Amazon Web Services (AWS)
Discussion related to Amazon Web Services (AWS)
Archive: https://archive.sweetops.com/aws/
2019-06-02
2019-06-03
Easy switch between AWS Profiles and Regions. Contribute to claranet/aps development by creating an account on GitHub.
2019-06-04
new tool I released :
A tool to list all S3 Buckets of an AWS account with their main statistics. Buckets are sorted by size. - claranet/go-s3-describe
@Issif I mean if I use a classic AWS key/secret key, they workflow in your tool will use AWS CLI profile? I would rather use aws-vault
I understand you using federation/STS. Merci pour le retour
If I get it, you don’t add you keys in .credentials/.config but you use aws-vault to store them and get them on the fly?
but after getting them, when you create a session, AWS provides you a token and this token is used by CLI or anything else to auth your requests
I guess you can keep this pattern, as you could do with AWS cli or else
yep I don’t store my keys in aws cli config as they are stored in plain text
A vault for securely storing and accessing AWS credentials in development environments - 99designs/aws-vault
have you had any problems using this in assume_role setting with MFA with ruby gems ?
A vault for securely storing and accessing AWS credentials in development environments - 99designs/aws-vault
I was trying terraforming to do a backup and with aws-vault it does not seems to work
although any other cli command works
does your script use the credentials from ENV or try to grab a profile in AWS CLI
is not my script, I’m using terraforming project
Export existing AWS resources to Terraform style (tf, tfstate) - dtan4/terraforming
it uses the ruby aws sdk
so it should use the session env , region etc
aws-vault exec home -- env | grep AWS
perfect, my tool ca use env vars
it should work as well

I’m curious about a test if you can
I will do it later once I get my backlog cleared . Will keep you updated
thank, I let you comment and close your issue if you can
it populates them as env variables in temp context
by the way there is no licence in your released code.
oh shit, thanks, I thought it was
fixed yesterday
Easy switch between AWS Profiles and Regions. Contribute to claranet/aps development by creating an account on GitHub.
2019-06-05

If you have ever written code that accesses a relational database, you know the drill. You open a connection, use it to process one or more SQL queries or other statements, and then close the connection. You probably used a client library that was specific to your operating system, programming language, and your database. At […]
Amazon Aurora: design considerations for high throughput cloud-native relational databases Verbitski et al., SIGMOD’17 Werner Vogels recently published a blog post describing Amazon Aurora as their fastest growing service ever. That post provides a high level overview of Aurora and then links to two SIGMOD papers for further details. Also of note is the recent announcement of Aurora serverless. So the plan for this week on The Morning Paper is to cover both of these Aurora papers and then look at Calvin, which underpins FaunaDB. Say you’re AWS, and the task in hand is to take an existing relational database (MySQL) and retrofit it to work well in a cloud-native environment. Where do you start? What are the key design considerations and how can you accommodate them? These are the questions our first paper digs into. (Note that Aurora supports PostgreSQL as well these days). Here’s the starting point: In modern distributed cloud services, resilience and scalability are increasingly achieved by decoupling compute from storage and by replicating storage across multiple nodes. Doing so lets us handle operations such as replacing misbehaving or unreachable hosts, adding replicas, failing over from a writer to a replica, scaling the size of a database instance up or down, etc. So we’re somehow going to take the backend of MySQL (InnoDB) and introduce a variant that sits on top of a distributed storage subsystem. Once we’ve done that, network I/O becomes the bottleneck, so we also need to rethink how chatty network communications are. Then there are a few additional requirements for cloud databases: SaaS vendors using cloud databases may have numerous customers of their own. Many of these vendors use a schema/database as the unit of tenancy (vs a single schema with tenancy defined on a per-row basis). “As a result, we see many customers with consolidated databases containing a large number of tables. Production instances of over 150,000 tables for small databases are quite common. This puts pressure on components that manage metadata like the dictionary cache.” Customer traffic spikes can cause sudden demand, so the database must be able to handle many concurrent connections. “We have several customers that run at over 8000 connections per second.” Frequent schema migrations for applications need to be supported (e.g. Rails DB migrations), so Aurora has an efficient online DDL implementation. Updates to the database need to be made with zero downtime The big picture for Aurora looks like this:
The database engine as a fork of “community” MySQL/InnoDB and diverges primarily in how InnoDB reads and writes data to disk. There’s a new storage substrate (we’ll look at that next), which you can see in the bottom of the figure, isolated in its own storage VPC network. This is deployed on a cluster of EC2 VMs provisioned across at least 3 AZs in each region. The storage control plane uses Amazon DynamoDB for persistent storage of cluster and storage volume configuration, volume metadata, and S3 backup metadata. S3 itslef is used to store backups. Amazon RDS is used for the control plane, including the RDS Host Manager (HM) for monitoring cluster health and determining when failover is required. It’s nice to see Aurora built on many of the same foundational components that are available to us as end users of AWS too. Durability at scale The new durable, scalable storage layer is at the heart of Aurora. If a database system does nothing else, it must satisfy the contract that data, once written, can be read. Not all systems do. Storage nodes and disks can fail, and at large scale there’s a continuous low level background noise of node, disk, and network path failures. Quorum-based voting protocols can help with fault tolerance. With copies of a replicated data item, a read must obtain votes, and a write must obtain votes. Each write must be aware of the most recent write, which can be achieved by configuring . Reads must also be aware of the most recent write, which can be achieved by ensuring . A common approach is to set and . We believe 2/3 quorums are inadequate [even when the three replicas are each in a different AZ]… in a large storage fleet, the background noise of failures implies that, at any given moment in time, some subset of disks or nodes may have failed and are being repaired. These failures may be spread independently across nodes in each of AZ A, B, and C. However, the failure of AZ C, due to a fire, roof failure, flood, etc., will break quorum for any of the replicas that concurrently have failures in AZ A or AZ B. Aurora is designed to tolerate the loss of an entire AZ plus one additional node without losing data, and an entire AZ without losing the ability to write data. To achieve this data is replicated six ways across 3 AZs, with 2 copies in each AZ. Thus ; is set to 4, and is set to 3. Given this foundation, we want to ensure that the probability of double faults is low. Past a certain point, reducing MTTF is hard. But if we can reduce MTTR then we can narrow the ‘unlucky’ window in which an additional fault will trigger a double fault scenario. To reduce MTTR, the database volume is partitioned into small (10GB) fixed size segments. Each segment is replicated 6-ways, and the replica set is called a Protection Group (PG). A storage volume is a concatenated set of PGs, physically implemented using a large fleet of storage nodes that are provisioned as virtual hosts with attached SSDs using Amazon EC2… Segments are now our unit of independent background noise failure and repair. Since a 10GB segment can be repaired in 10 seconds on a 10Gbps network link, it takes two such failures in the same 10 second window, plus a failure of an entire AZ not containing either of those two independent failures to lose a quorum. “At our observed failure rates, that’s sufficiently unlikely…” This ability to tolerate failures leads to operational simplicity: hotspot management can be addressed by marking one or more segments on a hot disk or node as bad, and the quorum will quickly be repaired by migrating it to some other (colder) node OS and security patching can be handled like a brief unavailability event Software upgrades to the storage fleet can be managed in a rolling fashion in the same way. Combating write amplification A six-way replicating storage subsystem is great for reliability, availability, and durability, but not so great for performance with MySQL as-is: Unfortunately, this model results in untenable performance for a traditional database like MySQL that generates many different actual I/Os for each application write. The high I/O volume is amplified by replication. With regular MySQL, there are lots of writes going on as shown in the figure below (see §3.1 in the paper for a description of all the individual parts).
Aurora takes a different approach: In Aurora, the only writes that cross the network are redo log records. No pages are ever written from the database tier, not for background writes, not for checkpointing, and not for cache eviction. Instead, the log applicator is pushed to the storage tier where it can be used to generate database pages in background or on demand.
Using this approach, a benchmark with a 100GB data set showed that Aurora could complete 35x more transactions than a mirrored vanilla MySQL in a 30 minute test.
Using redo logs as the unit of replication means that crash recovery comes almost for free! In Aurora, durable redo record application happens at the storage tier, continuously, asynchronously, and distributed across the fleet. Any read request for a data page may require some redo records to be applied if the page is not current. As a result, the process of crash recovery is spread across all normal foreground processing. Nothing is required at database s…
Interesting articles ^
2019-06-10
Anyone doing this? https://www.reddit.com/r/aws/comments/7rkwx0/earn_5_amazon_rewards_for_your_aws_bill/
48 votes and 20 comments so far on Reddit
2019-06-11
….presumably anyone paying aws bills (who isn’t at the PO level) is using a a credit card with rewards… for non-SP businesses, though, as mentioned that card is a personal card, so probably not the best idea to use for business expenses.
I keep on getting cache missed from CloudFront in front of Api Gateway for Serverless Image Handler
Do I need to enable API cache on the API Gateway Stage for CloudFront to cache the images?
2019-06-12
@Igor - yes
Although API Gateway does use Cloudfront - it’s not fully featured
2019-06-13
- join #aws-reinvent
It is soon time to know who is going to be at AWS re:invent and want to meet there this year I go
@me1249 The Serverless Image Handler page states “The solution generates a Amazon CloudFront domain name that provides cached access to the image handler API.” Is that misleading then?
Another overview page says “modified images are cached in CloudFront”
CC @Andriy Knysh (Cloud Posse)
Unless the intent is to generate the images that are needed and then save them in the S3 bucket
Actually, I may be wrong
Are you using and edge or regional endpoint?
2019-06-14
The solution generates cloudfront distribution and caches images there. At least it’s supposed to do so, but before I also noticed that in some cases the images were not cached with Miss from CloudFront response header
I didn’t go into the details, but guess the cache request cache headers are generated incorrectly on the origin
I would check the cloudfront distribution and see what and how it uses the cache headers
And maybe try to override the origin headers
I can’t even see the CloudFront distribution in front of the API Gateway
I see the one in front of the S3 bucket that stores the utility that generates the images and original images
The API Gateway one presumably is under an AWS-owned account
Question: Can somebody share which AWS Namespace option I should choose?
The Cold Start Prerequisite sections states that you need to have a domain and a namespace setup (I assume the meaning “within AWS”). However, when I choose to create a namespace within AWS I am presented with three options, of which I must choose one… but the Cold Start instructions do not indicate which one I should choose:
1) API calls - the application discovers service instances by specifying the namespace name and service name in a DiscoverInstances request.
2) API calls and DNS queries in VPCs - AWS Cloud Map automatically creates an Amazon Route 53 private hosted zone that has this name.
3) API calls and public DNS queries - AWS Cloud Map automatically creates an Amazon Route 53 public hosted zone that has the same name.
2019-06-19
Funny issue we had where I work the other day which I’d like to share. One instance could not retrieve from ECR, but another one in another VPC with the same credentials could . The VPC had a S3 endpoint configured with a restrictive policy..
aha! tricky
2019-06-24
A question regarding certificate management: I need to set up a bunch of very lightweight HTTP webservers (only a single endpoint) through ECS in different regions (and within each region within 2-3 AZs for HA). The web server Docker images will be built from scratch with a single self-contained binary (with Go). I don’t want to use an ALB, but just leverage Route53’s latency based routing. I know that in case of an outage I will loose some payloads before DNS re-routing kicks in due to DNS caching (3min), but that’s not a problem. This means I need to do TLS termination on the web servers using Let’s Encrypt certificates. Certificate creation can be easily automated with certbot which can cache the certificates. However, those caches are on the specific machines and CSRs are limited to 20 a week, which doesn’t scale. Does anybody have a good solution for centrally managing Let’s Encrypt certificates and keeping them up to date on specific servers?
There’s tools that can do this - traefik for example has the ability to store/maintain LE certs; cert-manager in kuberenetes, etc. I just went through needing to automate 1000s of these. Every thing I researched was basically “build your own service to manage it.” We ended up settling on using traefik enterprise because it fit our use case (we needed the reverse proxy anyways), but it doesn’t fit your design parameters.
I didn’t find anything that is basically an off the shelf certificate management service with like an api you could use while building your containers or what not.
@squidfunk for the simplicity I would store generated files in S3 protected with KMS or in SSM encrypted parameter store. then download/get objects from either in entrypoint.sh. This setup works for us pretty well but we don’t have anything critical. for more critical setups we use elb with acm.
@Maciek Strömich that’s a great idea, thanks! How do you make sure that certificates are re-generated and web servers are restarted? Cloud Watch Events + S3 Lambda triggers?
as I said it’s nothing critical and if a cert expires nothing bad happens. someone (one of 3 people) on internal network will get a cert warning. we regenerate the certs in a semi automatic fashion based on tasks from our GRC calendar (someone has to run a make command) and last step in that target is to kill the containers that are currently running using aws command line tools.
Just as an FYI: I solved it by using the Terraform ACME provider which will automatically generate certificates via route53 DNS challenge and save them in SSM. Terraform will also perform automatic renewal on the next apply when necessary (i.e. expiration date is x days away).
Question regarding integrating AWS with Azure AD SSO - more specifically using ’aws-azure-login (<https://github.com/dtjohnson/aws-azure-login>) on top of that. I did everything according to this tutorial - <https://docs.microsoft.com/en-us/azure/active-directory/saas-apps/amazon-web-service-tutorial> - and I’m able to login via web browser, but when I configure aws-azure-login` and try to login, I receive following error message. Any clues how to solve it?
Has someone seen something like this? Or have an idea what could be wrong?
I’m banging my head against the wall for a week already
I managed to solve the issue myself. Turns out there I needed to change SAML link in settings from AWS one to MS one.
2019-06-25

Today we are introducing Service Quotas, a new AWS feature which enables you to view and manage your quotas, also known as limits, from a central location via the AWS console, API or the CLI. Service Quotas is a central way to find and manage service quotas, an easier way to request and track quota increases, […]
Does this mean we don’t need to open support tickets any more to raise our limits for EC2 instances?
looks like it’s just wrapping the existing way of requesting increases
it adds a few nice features though, like service quota templating
@Erik Osterman (Cloud Posse) And here I thought it was just us that do the weekly “ask AWS for more of X” dance.
maybe I’m being mean….
looks to see if it has an API to programmatically create requests 
Quite nice to see everything in one place though, even incl. non-adjustable limits
Seems to be missing quite a few things (e.g. CloudFront + Lambda@Edge), but it’s a good start
It’d also be nice to see what the current usage value a limit is, which they must know to actually apply a limit (you’d assume)
ya, I would love to see that as well
@keen You joke, and yet I think this is the main reason we pay for the Business support (at a painful percentage of our monthly AWS cost), to get quick limit increase turnarounds. I’d drop it in a heartbeat if this turns out to be quick, easy and painless.
Last thing I’d love to see is an articulation of the hard limits (since these are soft limits only, for those that are increasable) - I get why AWS doesn’t want to publish them, but it’s nice to know exactly where the headroom extends to for some of the limits. I couldn’t get a sufficient answer from them for the absolute maximum number of CloudFront distributions.
@Lee Skillen i think they aren’t able to provide you with a hardlimit because it changes over time depending on new hardware installation/hardware upgrades/technology evolving/any other reason
Yup
aws is constantly evolving and tries to squeeze as much as possible from their setup
I agree! That’s what I meant by “I get why AWS doesn’t want to publish them”. They might not even always know for certain.
business support is nice to have. especially when your cf stack goes rogue and hangs in e.g. UPDATE_FAILED_ROLLBACK_IN_PROGRESS
also save us from few other headaches in the past when we put too much trust in developer hands
Has anyone ever run into CodeDeploy failing at AllowTraffic step?
My instance is showing up in the targets as Healthy.. but CodeDeploy just times out after 5min on AllowTraffic
2019-06-26
that’s one of the best aws news I got today
the other one is the ability to use secrets property in aws::taskdefinition pointing directly to ssm in cloudformation
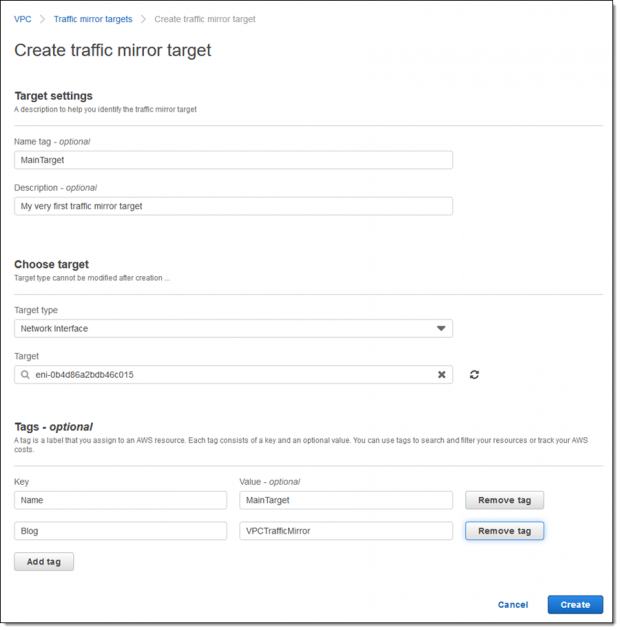
Running a complex network is not an easy job. In addition to simply keeping it up and running, you need to keep an ever-watchful eye out for unusual traffic patterns or content that could signify a network intrusion, a compromised instance, or some other anomaly. VPC Traffic Mirroring Today we are launching VPC Traffic Mirroring. […]
seems like aws is more and more showing it’s “be nice to law enforcement” face
We’re still waiting on cross-region support for Aurora Postgres - That would really make my day.
we are waiting for it too.
2019-06-27
Anyone here using aws-azure-login and has found an alternative ?
What’s the objective/end goal?
aws-azure-login is currently used company wide to login employees to AWS who are in the AD of Azure. This itself works great for engineers.
Installation is an npm install of a package and it needs a bit of configuration for ~/.aws/config
However, currently, other non-engineers, for example content people, update images on S3 have their own created iam users with specific s3 bucket access and login with a tool like Cyberduck. Currently IAM Users+keys are created for them and it would be much better and safer to provide them access through AD as well.
But supporting the installation of aws-azure-login for the regular users would be too much work for IT and it would be great to have a simpler tool which would be easier to install / maintain.
ok, that’s great context. agree that you might not want to have them get all that other stuff setup.
perhaps a better solution would be a self-hosted S3 browser sitting behind a web/oidc proxy?
can Sumone help me out with this “The role “arniam:role/Admin” cannot be assumed. There are a number of possible causes of this - the most common are: * The credentials used in order to assume the role are invalid * The credentials do not have appropriate permission to assume the role * The role ARN is not valid”
@Sharanya this is unfortunately quite open ended. There are too many possibilities of what could be wrong.
My Terraform is on 0.12.3 , Is there any changelog with Providers ?
@Erik Osterman (Cloud Posse)
do you mean that everything was working and it stopped after upgrading?
yea
it was working perfect locally without providers
i don’t understand what “locally” means in this context and what “without providers” means since terraform cannot function without providers.
you mean you are able to assume the role not using terraform? e.g. with the aws cli?
by Locally I mean terraform was able to do “init” and plan ,
without provider
nice stuff.
very