#aws (2019-11)
 Discussion related to Amazon Web Services (AWS)
Discussion related to Amazon Web Services (AWS)
Discussion related to Amazon Web Services (AWS)
Archive: https://archive.sweetops.com/aws/
2019-11-02
terraform is replacing the instance while enabling ebs encryption after creation of the instance. Any way to avoid this?
you can avoid this by not enabling ebs encryption for existing instances ? There is no such thing as live-encryption of existing ebs volumes hence it will try to recreate one.
Thanks, I have encrypted the ebs root volume manually , how to refresh the terraform remote state?
Should we use kms_key_id (arn) or the kms_alias as a value for the kms_key_id while encrypting root volume? If I use the alias, terraform is recreating the instance saying the kms key id is different from the last time.
you should use the key id, you can use a datasource to lookup the id with an alias. https://www.terraform.io/docs/providers/aws/d/kms_alias.html
Get information on a AWS Key Management Service (KMS) Alias
2019-11-03
A fully functional local AWS cloud stack. Develop and test your cloud & Serverless apps offline! - localstack/localstack
it’s not perfect, and some boilerplate code is required to make it usable.
A fully functional local AWS cloud stack. Develop and test your cloud & Serverless apps offline! - localstack/localstack
2019-11-04
Anyone here runs R5 AWS instance type for kubernetes ? Our fleet runs pretty high on memory and low on CPU, and I wonder if switching to R5 would be a good cost effective move. Is R5 cpu usually good enough to support a kubernetes with multiple web services (with low to mid CPU consumption) ?
make sure the ami supports enhanced networking
I use EKS optimized-ami
https://docs.aws.amazon.com/eks/latest/userguide/eks-optimized-ami.html
It doesn’t say but I guess it supports enhanced networking
The Amazon EKS-optimized Linux AMI is built on top of Amazon Linux 2, and is configured to serve as the base image for Amazon EKS worker nodes. The AMI is configured to work with Amazon EKS out of the box, and it includes Docker, kubelet , and the AWS IAM Authenticator.
I think it’s hard to answer generally speaking
Also, you can look into spotinst for managing efficient pools of autoscaling spot, OnDemand and reserved instances
Depending on your workloads it might give you even more bang for the buck
They have a Kubernetes autoscaler called ocean that takes care of all the heavy lifting
Learn about the Quick Start architecture and details for deploying Spotinst Ocean for Amazon EKS Nodes in the AWS Cloud.
Cool
I’m running the fleet on T3 medium instances at the moment, with nothing reserved yet, until I figure out what we really need
9 nodes per cluster, 3 environments
It’s getting expensive lol
We use the t3 series too
Medium for playing around
I see in grafana our nodes CPU is pretty much idle, around 5%, but memory is high
SO that’s why I was asking about R5 instances
xlarge or above for anything serious
I have the K8s Cluster autoscaler, and hpa for each pods, so for now it “does the job”
But yeah, I plan to upgrade node eventually as we grow
T3 are more expensive but you trade that for the ability to burst which is may be cheaper depending on your usage
Also, #kubecost is nice to see where your money is going if you’re running a lot of micro services and namespaces
t3.medium = 0.0416 per Hour (2vcpu 4gb ram) let’s say I need a cluster of at least 8gb so 2 nodes for 0.83$
Compare to a m5.large (2vcpu 8gb) : 0.096$ per hour.
It seems to me t3 are cheaper, can burst, and gives me 2 additionnal vCPU
Correct ?
R5 seems less expensive, (if you can run on very low cpu consumption)
With r5.large (2vcpu 16gb) $0.126 per Hour
So I would need 4 t3.medium to match the 16gb of ram. Resulting in 0.1666$ per hour, or a single t3.xlarge (4vcpu 16gb) at $0.1664 per Hour.
But you need to max out the ram on the servers to be cost effectivive, or have a large fleet
Well, that’s how I see it. But I might be missing something
2019-11-05
Hey team, looking at the autoscale-group module as called from eks-workers module.
I see in Console that launch_template_version default isn’t being set to the latest. I have v1 (default) and v2.
$Latest is the default in the autoscale-group module though: https://github.com/cloudposse/terraform-aws-ec2-autoscale-group/blob/master/variables.tf#L78
eks-workers module doesn’t supply launch_template_version value to autoscale-group so figure it should use default (of $Latest)
I’m trying to work out how nodes will rotate with an update to launch template and validating blue/green worker pools.
$Latest seems to be correct per terraform provider docs: https://www.terraform.io/docs/providers/aws/r/autoscaling_group.html#with-latest-version-of-launch-template
Terraform module to provision Auto Scaling Group and Launch Template on AWS - cloudposse/terraform-aws-ec2-autoscale-group
@kskewes how do you do version change and how do you test it?
Terraform module to provision Auto Scaling Group and Launch Template on AWS - cloudposse/terraform-aws-ec2-autoscale-group
We have extended the 2 worker groups example in eks-workers to use some locals as an easy way to update image and toggle which/both worker pools.
locals {
# Fetch image AMI using Makefile
# worker pool variable map shared across AZ's
workers_01_blue = {
enabled = false
image_id = "ami-082bdeda2726e4fff" # 1.14
instance_type = "t2.small"
}
workers_01_green = {
enabled = true
image_id = "ami-0f4f8678ca910061a" # 1.13
instance_type = "t2.small"
}
When we toggle or update image_id/etc it does update the launch_template, as can see new version (eg: v2) in AWS Console. However the default version is not changed to v2 (for example).
There are also no change to the ec2 instances (rollout or otherwise), which could be my misunderstanding of how ASG’s work.
In any case, we can blue/green worker pools for now.
I saw in a medium post that the ASG rolling upgrade API wasn’t exposed for use by Terraform/API directly, only CloudFormation can use it.
This makes the launch template stuff above moot.
Have attached snippet of what we have working right now, albeit with a nasty local hack.
Don’t worry we’ll move to git based module location too.
did you try to add new instance and sea if it gets new AMI?
sorry, yes I tried to delete an instance but it didn’t create replacement with new k8s node AMI
i mean a completely new one (it’s calls launch template for a reason)
no sorry
people using multi account and ecr + eks: how are you distributing images between accounts? i.e. are you a) allowing accounts to pull from a central repository or b) pushing images to multiple accounts — follow up question: what hurts about the option you’ve gone with?
Good question. On a recent engagement, we went with option (a), but considered both. It was just so much easier to have a centralized repo rather than worry about promotion.
@Igor Rodionov can answer technical questions.
how painful was management of cross account repo policies?
are you doing multiregion ?
single region
so multi aws account one ECR ?
yeah - that’s option a
basically ecr hosted within a shared ‘infra’ account and different clusters pull from that
option b is that images are pushed to different accounts based on  processes
processes
@Chris Fowles we use A
We are in multi region but we use the “regional account ecr” as a central repo
Yeah, we think the same because sometime images do not “arrive” to the second and/or third registry for some reasons So, our way is one registry for all regions
so same as having option A
yeh cool
cheers
I was leaning towards A for that reason
thanks folks
2019-11-06
Hello there, how are you? Could you please tell me if u have any experience using cloudwatch anomaly detection? I couldn’t find this resource in terraform docs.
I kept my images in gitlab

I first wrote about EC2 Reserved Instances a decade ago! Since I wrote that post, our customers have saved billions of dollars by using Reserved Instances to commit to usage of a specific instance type and operating system within an AWS region. Over the years we have enhanced the Reserved Instance model to make it […]
Cool!!!
I first wrote about EC2 Reserved Instances a decade ago! Since I wrote that post, our customers have saved billions of dollars by using Reserved Instances to commit to usage of a specific instance type and operating system within an AWS region. Over the years we have enhanced the Reserved Instance model to make it […]
yuuuuuge!
that is running inside one my ECS instances in AWS
I did not have to do anything access wise, it is done trough a tunnel to github
no user input needed just the command to run the installer ( it is in beta)
but the fact I can run this means I could start a container with the software needed, spin it up upon action in git wait until the hosted runner service is up and then run terraform apply that will be using the credentials given by IAM profile to specific resources, limiting what the runner can do. This is a pretty cool new feature of githug actions self hosted runners
Awesom
btw, see this https://github.com/hashicorp/terraform-github-actions?
GitHub Actions For Terraform. Contribute to hashicorp/terraform-github-actions development by creating an account on GitHub.
awesome
just created #github-actions channel
@jose.amengual I guess it can be run in Fargate as well ?
as long as you run the executable ( compiled from source) then yes
as the entrypoint
my guess is they will have a docker image soon
aha! i was just looking for that today
do they have one ?
I’ve been stuck on calls. Haven’t gotten back to it.
Basically, I’m curious about recreating the atlantis workflows
…jusing github actions
exactly my point too
we are about to buy TF Cloud
but so I think we will go that route
are you 100% terraform?
but this open the idea of having real test on instances etc
no we are not
we have TF, CF, CDK
and people clicking in the console
2019-11-07
so you need GH actions to compile GH actions
lol
Question : is Cloudposse going to be at re:Invent ?
Haven’t yet booked it. A lot going on - not sure if can make it
no booth or anything like that?
2019-11-08
Anybody knows a tool, shell or GitHub (python) project which helps me working within AWS organizations to rollout a bunch of settings across all accounts and regions? Especially for those services which aren’t integrated into AWS orgs. I’d like to use assume-role into the target account.
That is good question and I am looking for such tool for our project. If you find it, please let me know
First of all Cloudformation StackSets can be applied to accounts, OUs and regions. The preparation could be done based on a python script while utilizing the code from https://github.com/awslabs/aws-securityhub-multiaccount-scripts/blob/master/enablesecurityhub.py. This should help creating a new OSS repo.
This script automates the process of running the Security Hub multi-account workflow across a group of accounts that are in your control - awslabs/aws-securityhub-multiaccount-scripts
Have you looked at organisation group policies? SCP
SCPs don’t configure services.
well, only a few
Anyone do this yet? https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/UsingWithRDS.SSL-certificate-rotation.html
Rotate your SSL/TLS certificate as a security best practice.
I did on a test DB – Aurora MySQL 5.7 RDS instance, no issues
Rotate your SSL/TLS certificate as a security best practice.
@Darren Cunningham did you do have to do step #2 where you update your application? I don’t feel like most applications need to?
nope
will give it a shot on my test db — RDS Postgres
my case may not be yours –
"The methods for updating applications for new SSL/TLS certificates depend on your specific applications. Work with your application developers to update the SSL/TLS certificates for your applications."
Did it last week with a PHP app. We download the RDS CA bundle on every deploy so all I had to do was change the setting in the RDS instance.
If anybody has recommendations as to how to best implement DLQs w/Lambdas I’d appreciate input – trying to figure out if I should have a single target by Lambda, by region, by account or have a single target for my org. I’m thinking that I want to “default” to a SNS topic by region.
2019-11-10
2019-11-11
2019-11-13

Practice infrastructure-as-code in your organization and learn how to detect when engineers make manual changes in your AWS Console
 1
1Amazing! Thanks for sharing. This is a must have.
yeah, would be a cool project around the idea, tracking/matching the event patterns and managing the cloudwatch event rule
Would also like to see more meta data
In the slack alert
Looking for a solution to automatically tag AWS resources that were created with the creator and time . I came across this project https://github.com/GorillaStack/auto-tag .
Anyone else have recommendations?
Automatically tag AWS resources on creation, for cost assignment - GorillaStack/auto-tag
2019-11-14
This can be used for instances only http://answersforaws.com/code/graffiti-monkey/
@zeid.derhally
That looks like it only transfers existing tags from the instance to volumes/snapshots?
2019-11-15
Hem, does AWS network load balancing works between instances? I have insance A (part of asgA) and instance B(part of asgB). I need to connect from A to non http endpoint in B. I am trying to do it with NLB but it does not work. I am starting to wonder if i am missing something - maybe it cannot be done that way? (Security groups on both A and B allows whole 10/8 network and all servers are in it.)
This looks really strange - when i try to telnet from A to B it stays around 3-5 minutes in Trying.. and then it connects. Till that time i can see only Syn packages being sent from source host and no packages on target host. Once connection is established i can see first packages reaching target
You can use vpc flow logging to have a better look what is going on, sounds very weird indeed.
To me it sounds like the NLB Target Group is actually not marked healthy or some strange routing thing. Also make sure EGRESS Security Group rules, DNS resolving and Network ACL can’t be a cause.
I’m hoping the NLB is marked as internal to rule out strange routing problems.
it is not a case - i checked flow logs already everything is accepted. I am using dns name of NLB and it seems that it does not work if dns responds with ip of NLB from subnet where there is no healthy target. I have 3 subnets and 1 instance - to allow it to migrate to another one etc. But then only one of the NLB ip addresses is working
Do you have cross zone balancing enabled ?
enabling/disabling doesn’t change this behavior
AWS Support
2019-11-16
2019-11-17
has anyone been able to terraform out inspector in an automated fashion?
inspector ?
aws inspector
im having issues finding good examples
I have not used, just guard duty and config
I have those both working well, was wondering about inspector. its cool
Hi
I’m looking for a solution to monitor changes in AWS
Anyone knows a solution? preferable open source one
2019-11-18
AWS Config ?
Terraform plan?
Config would be your best bet - it will inform you of changes from your BASELINE report created at the start, any changes from that such as s3 bucket permissions changed it will notify you so that you can resolve.
AWS Config provides an inventory of your AWS resources and a history of configuration changes to these resources. You can use AWS Config to define rules that evaluate these configurations for compliance.

By Raghav Tripathi, Michael Hausenblas, and Nathan Taber From our first conversations with customers, our vision has always been that Amazon Elastic Kubernetes Service (EKS) should provide the best managed Kubernetes experience in the cloud. When we launched EKS, our first step was to provide a managed Kubernetes control plane, but we never intended to stop […]
We’ve just about ready to migrate to EKS and this comes out. hah. Always the way. We don’t think we’ll move to managed node groups just yet. Maybe next year.
By Raghav Tripathi, Michael Hausenblas, and Nathan Taber From our first conversations with customers, our vision has always been that Amazon Elastic Kubernetes Service (EKS) should provide the best managed Kubernetes experience in the cloud. When we launched EKS, our first step was to provide a managed Kubernetes control plane, but we never intended to stop […]
It feels like we are always as fast as we can but AWS is moving so fast it’s hard to keep up
yeah, and to be fair the other clouds have had this for a while so it was inevitable. We’re super happy so far and starting to do more PR’s that we hope are useful.
What he said; GCE has had this stuff for years; and they dont charge for the control plain (grumble 150 a month eks) Good stuff though I like having the option to fob off uninteresting details
“our vision has always been that Amazon Elastic Kubernetes Service (EKS) should provide the best managed Kubernetes experience in the cloud”
lol they’re not even the second best K8 in the cloud
https://github.com/aws/containers-roadmap/issues/530 “coming soon” in the roadmap
Kubernetes supports the ability to enable envelope encryption of Kubernetes secrets using a customer managed key (CMK). To support a defense-in-depth strategy, we plan to enable the AWS Encryption …
To clarify, my point is that AWS in aggregate moves so fast. Yes, managed node pools were late to the party, but that neglects to account for the 100x other services/features AWS has released since EKS first came on the scene.
It’s more to lament that as a company trying to codify their services and best practices in the form of terraform modules, it’s hard to keep up.
2019-11-19
Hi all, first time poster here so be gentle :smile:,
I have a question about a problem we have regarding AWS accounts, IAM policies, and S3 permissions in general.
So, as an example: • we have a single AWS account • multiple EKS clusters, one per environment, under the same AWS account • each EKS cluster has a role attached for the worker nodes • a kubernetes workload will upload files from any public S3 bucket and save it in to the clusters own private S3 bucket
The challenge: • the workload should be able to read from the public buckets from another environment under the same account. • the workload should not be able to read from the private buckets from another environment under the same account.
Is there an IAM policy to achieve this? I have looked at https://docs.aws.amazon.com/AmazonS3/latest/dev/walkthrough1.html but this would entail explicitly Denying access to other specific buckets.
Or are all buckets, by the nature of things, always visible under a single AWS account with the s3:ListAllMyBuckets permission.
Is there another way to achieve this? Are there any best practices? Using an account per environment would enable us to restrict by account number.
Hey @Steve Boardwell while I haven’t personally tried this out.. what you are trying to achieve may soon become one of my use cases too. I was hoping to solve this via IAM Permissions to K8s service accounts in EKS : https://aws.amazon.com/about-aws/whats-new/2019/09/amazon-eks-adds-support-to-assign-iam-permissions-to-kubernetes-service-accounts/. Basically I would setup my pod’s SA’s role to be restricted to specific private buckets. Would that work in your case ?
Hey, thanks for the link. I’m not sure if it completely covers my use case.
For example, what about public buckets in the same account? If access is restricted to specific buckets in that account, would the ‘public’ buckets still be accessible?
We actually have a separate role for each eks clusters set of worker nodes, meaning each cluster has their own permissions pointing to a specific bucket.
However, these roles can still see the other private buckets (which do not belong to the cluster) in the same account.
Maybe https://aws.amazon.com/blogs/security/how-to-restrict-amazon-s3-bucket-access-to-a-specific-iam-role/ would solve it ? Basically allow the eks cluster node role to be able to access all buckets (IAM role Policy for nodes) but use resource -based policy on their respective private buckets to only allow the respective nodes access (hence restricting other roles automatically)?
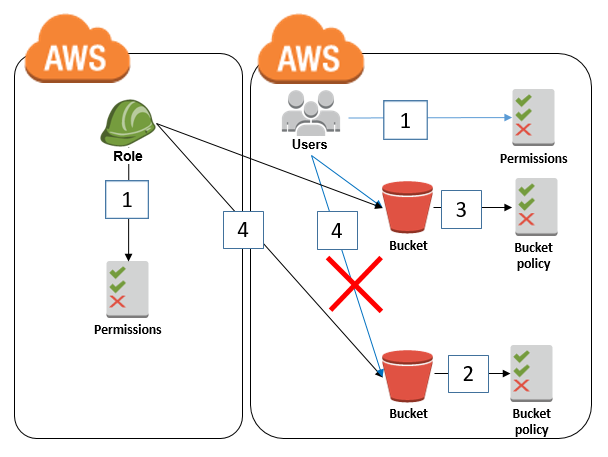
I am a cloud support engineer here at AWS, and customers often ask me how they can limit Amazon S3 bucket access to a specific AWS Identity and Access Management (IAM) role. In general, they attempt to do this the same way that they would with an IAM user: use a bucket policy to explicitly […]
That might work, thanks. I’ll give it a shot
great ! .. let me know how it goes
2019-11-20
2019-11-21
Tell us about your request Right now we can use on-demand instances in a managed node worker group. However I see no reference in the documentation to using spot instances or a spot fleet. Ideally,…
The one we talked yesterday
Eks node groups with SPOT
Thanks!!

CloudFormation was launched in 2011 (AWS CloudFormation – Create Your AWS Stack From a Recipe) and has become an indispensable tool for many AWS customers. They love the fact that they can define a template once and then use it to reliably provision their AWS resources. They also make frequent use of Change Sets, and […]
Registry + Resource Providers + Third-Party support… starting to be more competitive with Terraform
Hey all - I am looking for a way to debug and develop an api gateway lambda - I’m using Sam local with mock data, but I feel there is a better way - is anybody using something different? Any way to capture the request data sent to api gateway for easier access?
2019-11-22
Hey guys,
I am trying to create an AWS config custom rule which checks that a certain setting is always on (EBS default encryption)
When submitting my evaluation using the put_evaluations API call, I am required to submit a resourcetype and resourceid
Now, I’m monitoring a setting and not a resource… I’m at a loss as to what resource I ought to specify here. Anyone able to help?
Hi @Saichovsky, are you trying to put-config-rule instead ? https://docs.aws.amazon.com/cli/latest/reference/configservice/put-config-rule.html
Haven’t tried that yet. My calls ebs-get-encryption-by-default to get status and if disabled, calls enable-ebs-encryption-by-default ; I’d then like to call AWS Config’s put-evaluations which takes in resource params. This is where I get stuck.
Let me check out the link you shared for more info
sure..let me know how it goes.
2019-11-25
Hello there! I’m trying to run aws-nuke solution, I could delete one account but I had some issues trying to connect with another account using cross account role. somebody have any experience with this tool? Maybe a config file example?
2019-11-26
Hi, I’m planning on setting up Vault for our credential management. Anyone here with experience doing that? Would love to hear if you like it, common pitfalls you ran into or other things I might have to take into consideration for this project.
For me in was a long journey, did at least 3 refactor on the job
In the end, ended up with applications policy,roles,tokens generation etc in terraform instead of packer, and kept packer image script only for the vault base image not bounded to any environment and re-usable.
Going all in with packer in the beginning was a mistake I did
Also, if you run Vault with multiple instance, when you launch them with terraform, you’ll eventually have to wait for every nodes to get correctly into the cluster.
I had trouble “configuring” the vault too soon, because some vault slave was still in “Could not find elected master” state or something like that.
So make sure you wait properly for the cluster to be fully up and running before you start configuring it
I remember setting up the certificate correctly for SSL was a bit of a pain too lol
But in the end I think it was worth
Thanks!

Shortly after we launched EC2, customers started asking for ways to identify, classify, or categorize their instances. We launched tagging for EC2 instances and other EC2 resources way back in 2010, and have added support for many other resource types over the years. We added the ability to tag instances and EBS volumes at creation […]
i both loath and love the lead-up to re-invent
I’ve never been, I’m kinda excited.
i’m not heading there this year - i’m more talking about the amount of stuff that changes in aws in a very short time that you need to get your head around
it was worse when i was consulting - at least now i don’t have to worry about being ambushed by questions about a 2 hour old service when walking into a pre-sales meeting
Haha this I can relate to!
Hahaha oh man yeah
I am looking on some guidance using secrets with EKS. I could use K8s secrets and mount them on a volume (EFS ? ). I would prefer use of Parameter Store/Secrets Manager.
i’ve not found anything perfect for my use case in deal with secrets pulled from paramstore so i’m using a small bootstrapper that i wrote to pull secrets from paramstore and inject them into env vars in process
similar to a chamber exec https://github.com/segmentio/chamber#exec
CLI for managing secrets. Contribute to segmentio/chamber development by creating an account on GitHub.
didn’t need all of chamber though so wrote our own
it feels as though this should be a solved problem, but i wasn’t able to find a tool that did exactly what i needed
if you’re ok with secrets being written to etcd then you can use something like https://github.com/godaddy/kubernetes-external-secrets
Integrate external secret management systems with Kubernetes - godaddy/kubernetes-external-secrets
2019-11-27
Thank you for sharing ..I’ll take a look .. I do see this as an item on the EKS roadmap, it’s still being researched though
A Vault swiss-army knife: a K8s operator, Go client with automatic token renewal, automatic configuration, multiple unseal options and more. A CLI tool to init, unseal and configure Vault (auth met…
2019-11-28
quick question, can I add a new tag using terraform module with the volume-id I get from Data source ?