#aws (2020-03)
 Discussion related to Amazon Web Services (AWS)
Discussion related to Amazon Web Services (AWS)
Discussion related to Amazon Web Services (AWS)
Archive: https://archive.sweetops.com/aws/
2020-03-01
2020-03-02
Hi, I would like to know if someone have an EKS cluster in any environment with only fargate implemented with the terraform-aws-eks-fargate-profile module. I have tried to deploy a cluster with these module and the pods always remain pending. I even deployed with eksctl and I was comparing permissions of IAM, VPC, Tags etc … and apparently it is the same on the AWS side, but with eksctl the pods work and with the terrafom modules not.
Terraform module to provision an EKS Fargate Profile - cloudposse/terraform-aws-eks-fargate-profile
did you see the complete working example https://github.com/cloudposse/terraform-aws-eks-fargate-profile/tree/master/examples/complete
Terraform module to provision an EKS Fargate Profile - cloudposse/terraform-aws-eks-fargate-profile
Terraform module to provision an EKS Fargate Profile - cloudposse/terraform-aws-eks-fargate-profile
take a look at this https://github.com/cloudposse/terraform-aws-eks-fargate-profile/blob/master/test/src/examples_complete_test.go#L109
Terraform module to provision an EKS Fargate Profile - cloudposse/terraform-aws-eks-fargate-profile
before you deploy any k8s resource to the fargate nodes (into the namespace for which the fargate profile was created), the nodes will be in Pending state
@Manuel Pirez ^
Thanks @Andriy Knysh (Cloud Posse)
2020-03-03
So I’m trying to understand what the minimal permissions OpsWorks requires are - https://www.terraform.io/docs/providers/aws/r/opsworks_stack.html.
I’m supposed to give it a service role and give instances a default profile. The only thing I’m supposed to use OpsWorks for are users and SSH keys, I want the rest immutable.
Now, logically this would only require opsworks agents running on instances running on instances to be able to pull keys. (This is VERY simple on Google Cloud… but this is AWS…)
Can I give opsworks an empty policy and the instances - some policy that only allows it to pull keys somehow?
Provides an OpsWorks stack resource.
Does this mean I cannot use OpsWorks to manage SSH keys (and nothing more, ever) on my spot instances in ASGs?
@Karoline Pauls why do you want to use ssh when you have system manager available?
TBH I don’t want to have anything to do with OpsWorks and I don’t know what system manager is.
I just want to get the SSH keys thing out of the way without doing anything stupid in IAM.
I think i’ll just ignore what was done before and will use https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/Connect-using-EC2-Instance-Connect.html
Connect to your Linux instances using EC2 Instance Connect.
Because I don’t have time for learning about yet-another-semiredundant-overengineered-feature-of-aws. Don’t want to sound dismissive but I want working infrastructure with few carefully chosen bits of AWS, not a menagerie of AWS services.
Looks like AWS also doesn’t recommend OpsWorks for what I’m supposed to use it for because stack creation is taking 20 minutes already.
I would avoid OpsWorks competelly, I’ve had the chance of using it and I can only describe it as a mess.
@Nikola Velkovski puppet 4 life! :D
I liked Salt, you could render states with jinja (unlike Ansible when i used it) and since Jinja can almost run like normal Python code and definitely can build data structures, for advanced uses you could use the json filter to output some dynamically built code that would parse as YAML.
Of course, as someone who dabbled with Clojure, I find this whole “let’s render data with text interpolation” thing shameful to our industry. Any expression-oriented dynamically typed programming language with rich data literals may be used to render heterogeneous data.
interestingly, even terraform acknowledges that: https://www.terraform.io/docs/configuration/functions/templatefile.html#generating-json-or-yaml-from-a-template
The templatefile function reads the file at the given path and renders its content as a template.

it seems i managed to find the minimal set of permissions to register an instance, now i’m seeing it wants to install Ruby before proceeding (and gets 403)… other than the 403, installing Ruby is exactly something that I want to happen on Spot EC2 Kubernetes workers in an autoscaling group… Where I want startup times to be as fast as possible…
Hi, why do you need to install ruby ?
I don’t, OpsWorks agent wants
I’d have thought that would be all done in an omnibus package or similar
Been many years since used Chef (never used opsworks)
Opsworks with spot instances for k8s workers, am I reading this right ?
Agree with others here, wouldn’t go near Opsworks especially for your use case. ^^
You will loose so much time with opsworks, and it’s from a time docker wasn’t really there yet.
Why are you using Opsworks when you clearly don’t want to?
I agree with you all, I wouldn’t touch OpsWorks too
but ?
But someone decided to use OpsWorks to manage people’s SSH access while I was busy working in another team porting a particularly blobby bit of software to Python 3.
Ah ok, but then it’s a good moment to communicate that to this person that this might not be the best way forward, copy paste the slack to this person when needed.
and start again
include me in the screenshot!
OPSWORKS
Also why is ssh access needed to begin with ?
most of the time it’s unnecessary but sometimes it’s useful to SSH to strace something in a container (yes, there is probably a tool for that), or do other sorts of debugging
I don’t really SSH there most of the time
For executing inside the container kubectl exec can be used, ssh is not needed there.
you cannot really strace this or other containers from there
IIRC even if you run as the root, you cannot [normally?] strace from docker because that would circumvent security
yeah, you need --cap-add sys_ptrace
Ok but in that case you can also run telepresence from a host with trace capabilities and do it there.
https://www.telepresence.io
Telepresence: a local development environment for a remote Kubernetes cluster
Might look complicated, but it’s far less complicated than maintaining Opsworks
i currently can ssh, except it’s done by a 10 lines long script executed on instance init
looks like it will remain so for now because I’ve got real work to do
and i’ll later probably try out https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ec2-instance-connect-methods.html
The following instructions explain how to connect to your Linux instance using EC2 Instance Connect.
https://docs.aws.amazon.com/systems-manager/latest/userguide/ssm-agent.html is worth a look too. It can be used for SSH access (look up SSM Session Manager) and also to run commands on multiple instances and get back the results (look up SSM Run Commands)
Install SSM Agent on Amazon EC2 instances, and on-premises servers and virtual machines (VMs), to enable AWS Systems Manager to update, manage,and configure these resources.
here an example of a bastion using the ssm agent
AWS Bastion server which can reside in the private subnet utilizing Systems Manager Sessions - Flaconi/terraform-aws-bastion-ssm-iam
looks better
OpWorks is a steaming pile of trash - I’ve had to do demos of it for AWS and even in that tightly constrained scenario it rarely worked
SSM instance connect is actually worth a look though - the rest of the SSM space is pretty questionable as far as I’m concerned (except param store) but the instance connect takes away a lot of pain pretty simply - gives you iam controlled, audited connectivity from either console or cli.
2020-03-04
Anyone able to help me with a CloudFormation/LandingZone issue? (description in thread)
I have two templates - one defining the execution role and the other the assumed role. I need to link these accounts in a trust relationship. How do I import the value of the execution role into the template for the assumed role? I had created an Outputs section in the executionrole.template, hoping to use SSM but I feel that it will get exported to the SSM in the master account while the value will be needed in the child account. So I need to pass the execution role ARN from one account to a stack running in a different account
not sure 100% but it seems that this CF feature might help you https://aws.amazon.com/about-aws/whats-new/2020/02/aws-cloudformation-stacksets-introduces-automatic-deployments-across-accounts-and-regions-through-aws-organizations/
has anyone got any direction on the tls issues surrounding bucket names with periods ?
the S3 deprecation plan https://aws.amazon.com/blogs/aws/amazon-s3-path-deprecation-plan-the-rest-of-the-story/
Bucket Names with Dots – It is important to note that bucket names with “.” characters are perfectly valid for website hosting and other use cases. However, there are some known issues with TLS and with SSL certificates. We are hard at work on a plan to support virtual-host requests to these buckets, and will share the details well ahead of September 30, 2020.
For example, we cannot use the <https://company.bucket-name.s3.amazonaws.com/mypath> url if our bucket name containers a period. In this case the bucket name is company.bucket-name. If we use curl and its https link, it will fail unless we skip certificate validation using --insecure
don’t use periods in bucket names?
lol. let me just get in my time machine
have you tried using cloudfront as a workaround? you can use cloudfront to front an s3 bucket for https access
we haven’t. for now, we were waiting to hear back from amazon to see what they say while we use the old url
though the article says they are trying to come up with a solution for bucket names with periods…
Bucket Names with Dots – It is important to note that bucket names with “.” characters are perfectly valid for website hosting and other use cases. However, there are some known issues with TLS and with SSL certificates. We are hard at work on a plan to support virtual-host requests to these buckets, and will share the details well ahead of September 30, 2020.
Host a static website on Amazon S3 by configuring your bucket for website hosting and then uploading your content to the bucket.
they did say they would share the details well ahead of the sep 30, 2020 timeframe so looking for the official reply.
i quoted that same bit in the OP
ive asked my TAM and am waiting to hear back
they’ve adjusted the plan once already. i’m half-expecting the date to push out. with these blog posts being a scare-tactic to get customers to come forward with issues and use cases, and start folks changing behavior earlier so there are fewer issues after the real, eventual change
my brain just exploded
lol
we also depend heavily on other company’s s3 urls and they use periods in their buckets
now we have to nag them to get them to add an access point? ridiculous…
yep
well, it sounded from the blog that if the bucket already exists then you’ll be fine. just new buckets after 30 september get impacted
Revised Plan – Support for the path-style model continues for buckets created on or before September 30, 2020. Buckets created after that date must be referenced using the virtual-hosted model.
Seems the version for this module went from 0.7.0 to 0.3.2 recently https://github.com/cloudposse/terraform-aws-s3-bucket/releases
Is that the correct next version?
Terraform module that creates an S3 bucket with an optional IAM user for external CI/CD systems - cloudposse/terraform-aws-s3-bucket
^ maybe in the #terraform channel
Terraform module that creates an S3 bucket with an optional IAM user for external CI/CD systems - cloudposse/terraform-aws-s3-bucket
We sometimes release a bug fix for earlier versions of the module for 0.11
Issue is the version went backwards I think
Also, one heads up on this module: make sure the lifecycle rules are right for you
we’re going to disable them by default in an upcoming PR, but still expose the functionality
(also not sure where to post that question )
2020-03-05
Hello team. What do you suggest to fine tune permissions on AWS EKS pods ? I am planning to setup an multi-tenant AWS EKS and plan to use Namespaces for seperation but i need some advice I have found https://aws.amazon.com/blogs/opensource/introducing-fine-grained-iam-roles-service-accounts/ . I know AWS EKS does not have built-in fine tuned separation of duties. So what would be your suggestion ? I plan to hold each customer on separate namespace and only allow a service account to accesss to specific namespac
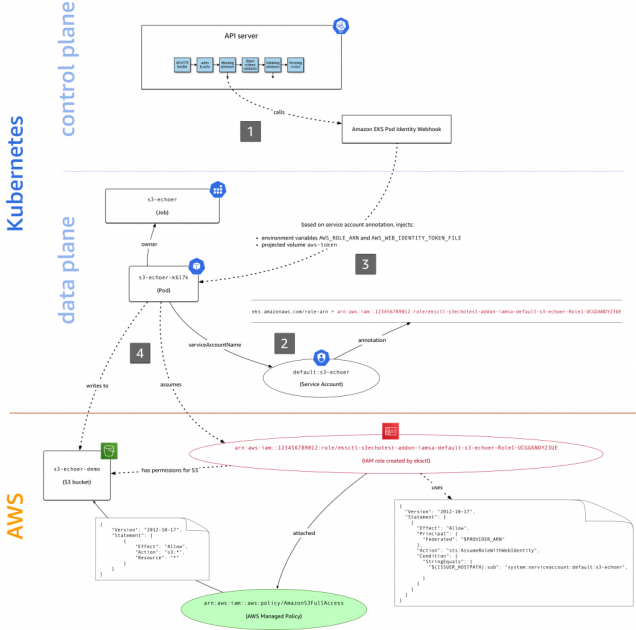
Here at AWS we focus first and foremost on customer needs. In the context of access control in Amazon EKS, you asked in issue #23 of our public container roadmap for fine-grained IAM roles in EKS. To address this need, the community came up with a number of open source solutions, such as kube2iam, kiam, […]
Also i am planning to use Fargate on this setup.
Or should i use https://docs.aws.amazon.com/eks/latest/userguide/enable-iam-roles-for-service-accounts.html
The IAM roles for service accounts feature is available on new Amazon EKS Kubernetes version 1.14 clusters, and clusters that were updated to versions 1.14 or 1.13 on or after September 3rd, 2019. Existing clusters can update to version 1.13 or 1.14 to take advantage of this feature. For more information, see
We use IAM roles for service accounts, and associate each service account with the pods that need it. E.g. we create an IAM role with the requisite polices for external-dns then associate that with a service account that we pass to the external-dns deployment/pods.
The IAM roles for service accounts feature is available on new Amazon EKS Kubernetes version 1.14 clusters, and clusters that were updated to versions 1.14 or 1.13 on or after September 3rd, 2019. Existing clusters can update to version 1.13 or 1.14 to take advantage of this feature. For more information, see
We then do this for every other service we deploy
like cert-manager
I see so you dont use kiam or kube2iam but this newly announced feature of AWS Eks https://aws.amazon.com/blogs/opensource/introducing-fine-grained-iam-roles-service-accounts/
Here at AWS we focus first and foremost on customer needs. In the context of access control in Amazon EKS, you asked in issue #23 of our public container roadmap for fine-grained IAM roles in EKS. To address this need, the community came up with a number of open source solutions, such as kube2iam, kiam, […]
Yes, for EKS we use the new service accounts. for kops we still use kiam- haven’t explored it yet.
Service accounts are much better once you have it working.
Yep to service accounts. For multi tenant if you need hard boundaries I’d consider a separate cluster. Otherwise namespace network policy, service accounts, pod security policy, OPA on admission, etc.
When making requests to a private AWI GW through an internal NLB the request is routed to the correct stage but the stage name is also included in the resourcePath which breaks the request. This only happens when making the request thought the NLB.
2020-03-06
hey, does anyone has ready to use cloudwatch alarms for kinesis firehose in cloudformation format e.g. for Delivery.DataFresshness, or ThrottledRecords or even better for those math expressions specified in https://docs.aws.amazon.com/firehose/latest/dev/monitoring-with-cloudwatch-metrics.html#firehose-metric-dimensions? (my friday lazy ass is asking (-: )
Learn how to use CloudWatch Metrics to monitor delivery streams in Amazon Kinesis Data Firehose.
Not for that exact use but math expressions in CL alarms aye…
I wonder why they don’t include cw alarms in the docs of the resource.
e.g. https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-kinesisfirehose-deliverystream.html has a complete example with bucket, roles, policies and deliverystream
Use the AWS CloudFormation AWS::DeliveryStream resource for KinesisFirehose.
why they wouldn’t just add an example cw alarm in there?
ok, so for data freshness it should alarm only if 900 secs mark is crossed because that’s the maximum firehose limit
for anyone interested ;-))
FirehoseDeliveryDataFreshness:
Type: AWS::CloudWatch::Alarm
Properties:
AlarmDescription: Firehose Delivery Data Freshness Alarm
AlarmName: FirehoseDeliveryDataFreshness
ComparisonOperator: GreaterThanThreshold
Period: 60
EvaluationPeriods: 3
Threshold: 150
Statistic: Maximum
MetricName: DeliveryToS3.DataFreshness
Namespace: AWS/Firehose
Dimensions:
- Name: DeliveryStreamName
Value: !Ref FirehoseDeliveryStream
TreatMissingData: breaching
AlarmActions:
- !Ref 'AlarmTopicArn'
InsufficientDataActions:
- !Ref 'AlarmTopicArn'
my bufferinghints are set to 120 secs which means that on avg kinesis will deliver on the 121 second.
I gave it a littlebit more room
2020-03-10
Hey all, I have a two questions regarding AWS Parameter Store:
1) Does anyone know of a good way to find when the last time a secret has been accessed? 2) Is there a good way to find how many times a given parameter has been accessed in a given time frame (ideally 24 hours)?
I think cloudtrail would be best suited to answer both questions
So i’ve been looking into using cloudtrail for the latter. For the former I was hopeful that I wouldn’t have to do something like query all cloudtrail logs for the last time GetParameter(s) was called on each secret
Anyone familiar with Firehose delivery to Redshift? From everything I can tell, it seems like your redshift needs to be publicly addressable (IE in a “public” subnet with an internet gateway) for Firehose to talk to it, complete with a /27 CIDR block range for Firehose to allow through the SG. Seems just weird to me to keep data stores publicly accessible like that. Is there any configurations out there where it can stay in the private subnet, but still get delivered to from firehose?
You can deliver to S3 and pull the data from there into redshift.
Yeah, thought of that work around this morning before seeing the message. Seems to be the way to do it.
Hi @Alex Siegman . I think that you can achieve this using aws vpc endpoint. With Redshift in the VPC, it should be able to communicate with Firehose through the endpoint without leaving the vpc(aws backbone). I haven’t used this solution but it may work for you.
https://docs.aws.amazon.com/vpc/latest/userguide/vpc-endpoints.html
Use a VPC endpoint to privately connect your VPC to other AWS services and endpoint services.
my impression was that was for outbound connectivity to services, if redshift was “Reading from” firehose, not the public firehose service delivering to redshift. Could be wrong. Might try it in a test account
anyone have strong opinions on where ETL/ML structure should be set up? i currently have airflow in our staging k8s cluster but its kind of a pain to manage cross account permissions:
• could move airflow to our prod k8s (worried about doing this)
• could create a new k8s cluster in prod account and move it there
• or could create a new aws data account that has access to everything?
any insights/experiences are appreciated
Have you tried/seen kubeflow?
@Marcin Brański does kubeflow do ETL?
but yeah for ML side at least it seems good, but havent tried
2020-03-11
https://github.com/bottlerocket-os/bottlerocket -> AWS’s container OS looks interesting. Has an update strategy that reminds me of upgrading F5 LTMs….
An operating system designed for hosting containers - bottlerocket-os/bottlerocket
2020-03-12
Hello, Im looking for . modules that deploy eks with s3 backend + dynamodb for lock state
2020-03-13

In July 2015, AWS announced Amazon API Gateway. This enabled developers to build secure, scalable APIs quickly in front of a variety of different types of architectures. Since then, the API Gateway team continues to build new features and services for customers. Figure 1: API Gateway feature highlights timeline In early 2019, the team evaluated […]
2020-03-16
Hi Guys, I am new to this channel and trying to get some advice on the rolling update EC2 on the ASGs. I am trying to use this module https://registry.terraform.io/modules/cloudposse/ec2-autoscale-group/aws/0.4.0 and seeing that everytime I update userdata, instance type it just creates a new version of launch template but doesnt do any rolling update on the ASG. Is there is any sort of workarounds available as discussed in https://github.com/hashicorp/terraform/issues/1552
Once #1109 is fixed, I'd like to be able to use Terraform to actually roll out the updated launch configuration and do it carefully. Whoever decides to not roll out the update and change the LC…
Please avoid cross posting, but if you do, link to your original post. #terraform is the correct channel
Once #1109 is fixed, I'd like to be able to use Terraform to actually roll out the updated launch configuration and do it carefully. Whoever decides to not roll out the update and change the LC…
got it
thanks
2020-03-18
Morning everyone ! Quick VPC/EC2 question. When you change the Route Table for a subnet, is it required to restart/launch new EC2 instances on that subnet to reflect the change ? Is it immediate ?
I guess there are some exceptions, but still not on the EC2 side. Like if you’re using BGP on a VPN and the routes are being propagated from your edge-device, then that device may need to push updates?
To be honest I’m not super clear on those VPN / Gateway scenarios. But if you’re just talking about entirely within the context of a single VPC, you should be good
2020-03-20
I’m trying to sign a request on an ECS task to sts using my Instance profile IAM Role. When I check the IAM Request headers on my requests, it looks like the session token for the instance role is not being included.
Is there a way to get the current session token on the task?
Wouldn’t you prefer to use task role instead of instance role?
2020-03-21
2020-03-23
How do people here lower replication lag in aurora replicas ? I’m looking at write operations and see a direct correlation with spikes in replication lag which is expected but the spikes are well over 100 ms reaching around 1 sec
Its been a while since I’ve messed with perf tuning Aurora but I would look at:
• instance classes you’re using since that directly impacts network throughput
• provisioned iops
• memory buffers (in cases of mysql / pgsql)
• any development usage of the replica (data-warehouse / etl / jobs)
Isn’t aurora replication done at I/O layer, have you contacted support ?
we haven’t contacted support because no degradation has been seen. this was just unnerving to see from our developers and i was wondering if any other people have noticed issues and successfully lowered replication lag
according to aws, it looks like replication lag is correlated well with write operations and we can see that side by side in the metrics
for now, we’re raising our alert from 0.2 sec to 1.5 sec since with 1 sec lag we’re not seeing issues
We removed READ replicas due to the lag on my project. The lag can mount to few seconds on heavy write operations.
We were having data state inconsistencies that blew up our workflow, so we end up removing the replica and up sizing the main cluster
I mean for READ replica’s
It was a pain the read replica’s in aurora… too much lag
2020-03-24
Hello People !! I have a simple problem and I would like to know if anyone here have worked around it. I need to know , from within an EC2 instance, what is the Target Group that the instance is attached to, and then be able to de-register from it…
I could be wrong but I don’t think you’ll find anything “standard” in this use-case for the following reasons:
• it predicates the instance is using a role (which isn’t required in general for launching an instance)
• the roles policy permissions would be pretty use-case specific
• sadly there’s no meta-data available for assigned tg’s (https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/instancedata-data-categories.html)
The following table lists the categories of instance metadata.
It might help if you provided more context around the use-case. I’d wonder why not conditionally assign the instance in whatever process is doing that
Thanks for the reply @androogle ! . We have an instance role with the proper permissions for querying the Load Balancers and Target Groups… and registering and de registering from them
what is the event that you’d like to trigger the removing of the instance from the target group?
We have a super big application with around 20 different Target Groups on Different AWS zones… so I want to create a small Python/bash script that would be executed by the Java JVM whenever there is a critical condition, so the instance can de register itself from the TG
So that script needs to know what is the TG the instance is attached to
Using the AWS CLI
aws elbv2 deregister-targets \
--target-group-arn arn:aws:elasticloadbalancing:us-west-2:123456789012:targetgroup/my-targets/73e2d6bc24d8a067 \
--targets Id=i-1234567890abcdef0
got it. I’m a python person so I’d probably do it with a mixture of metadata to get the instance-id and boto3 to get the target-group
Yep… the Instance ID is a piece of cake … getting the Target Group is more challenging … ’case we have 20+ TargetGroups
I mean.. it’s doable on either Python or Bash… I just wanted to avoid rewriting the wheel.. in case someone have already created it
yeah I follow. I was just saying because of those initial bullet-points it’d be hard for anyone to make a standardized approach to that. Its a pretty unique use-case
Yep… seems like
Out of curiosity, what happens with the instances that are failing?
Java internal issues …. OutOfMemoryExceptions
like is it possible to configure the java app to return an http code that would cause the health-check to fail and remove it from the TG ?
and other conditions …. so we want to take the instance of out the load balancer so we can perform post-mortem
Otherwise the instance is terminated by the ASG
ahhh I gotcha
Anyways … @androogle thanks for much for your interest and for the tips !
Good luck
TY … I will post the resulting script..
I just don’t want to reinvent the wheel in case someone has a script for this
Thanks a lot !
2020-03-25
Hey,
can I somehow see which instances are out of stock for a specific aws region? we have been unable to launch c5.xlarge in eu-central-1a a couple of times this week and I am trying to find a source that will tell me when something is unavailable
do you mean spot or just in-general you couldn’t launch a c5.xlarge ?
in general
I’ve never run into that. hm I wonder if there’s anything in the API
Returns a list of all instance types offered. The results can be filtered by location (Region or Availability Zone). If no location is specified, the instance types offered in the current Region are returned.
maybe that?
hmm. is it presently happening? I don’t know if that metric is life or “general” availability
aws ec2 describe-instance-type-offerings --region=eu-central-1 | grep -B1 -A3 c5.xlarge
{
"InstanceType": "c5.xlarge",
"LocationType": "region",
"Location": "eu-central-1"
},
no happened mostly last two days in the mornings
but that still doesn’t narrow it down to zone
I’ve had issues where I can get certain instance types in us-east-1a but not like us-east-1e
next time it happens you could try:
aws ec2 describe-instance-type-offerings --region=eu-central-1 --location-type availability-zone | grep -B1 -A3 c5.xlarge
if it doesn’t return anything for the zone its erroring on then you know you can use that call
Hey guys! I have an ECS service running my api in containers and today I noticed that the running containers stopped after 24 hours. It happened on staging as well on production today after exactly 24 hours, with the events separated excatly by time the deployment from staging to production took. Is this expected behavior?
are these running as a service or a 1 off task?
This means they are running as a service right?
yup!
have you looked at the service / task logs when they stop?
also when you look at the stopped tasks, does it give a reason?
This is the event log in the service itself. To me it reads like ECS itself decided to drain connections and stop the containers, rather than an unexpected error occurring in the containers.
is the service mapped to a target-group?
if the target in the target-group fails health-checks, it will de-register the task
Also I’d check if the service is logging to cloudwatch (or anywhere) and check the logs of the api itself
but to your question, no thats not normal / expected
happy to help debug it with you
is the service mapped to a target-group?
Yes, indeed!
if the target in the target-group fails health-checks, it will de-register the task
I see in the ALB logs that there were HTTP 503 codes during the same time!
happy to help debug it with you
Thank you, really appreciate that! For your information, I’m quite junior in Ops, but still the most experienced in our company.
cool np at all What I would try and do if I were in that position is find the api logs and corollate them to the 503 response codes if you can
see if its an app issue, environment issue or combo of both
if the services have been setup to use the aws logger, you may find logs in cloudwatch that are for that api service
Thanks I found the problem: from the api we ping the postgres database to see if it’s still available. The client from node-postgres had an unhandled error, leading to a crash. Seems like the database drops connections active longer than 24 hours, but I’ll have to investigate more.
yeah postgres is probably doing a schedule backup or maintenance
if you’re using a HA setup of postgres (RDS with replicas) I’d ping the cluster url, not the individual instance
hopefully soon AWS RDS Proxy (assuming you’re using RDS) will become GA and make issues like this less prevalent
We are using Aurora Serverless and I think that one is using a proxy too already. However, in de api, I make a connection with the database and perform a simple query (SELECT true ).
do you know if you’re using the cluster-url vs the ro endpoint?
that may make a difference
when maintenance period happens or a scale-up, the resource for the replicas may change, but to be honest I don’t have a lot of experience with Aurora Serverless
this is the url: bouw-staging-db.cluster-xxxxxxxxxxxx.eu-west-1.rds.amazonaws.com
hm ok yeah that looks like a cluster-url format
since this is a staging environment, do you leverage Aurora for a cost savings measure and have it turn-off after a certain period?
though if the app is constantly doing a select 1 it should reset the countdown timer to shutdown, so thats probably not it. hmm
Hmmm, it happened happened exactly 24 hours after container startup, in different envs (staging and prod).
hehe, yeah indeed.
I guess I’d poke around in Cloudwatch Metrics for that Aurora instance. Look at connection count and other things to see if it drops all connections. See if the Aurora instance has events in its event log about restarting or applying queued maintenance
has this been recurring or just a one time thing per environment?
has this been recurring or just a one time thing per environment?
We deployed yesterday, looking in the logs now to see if it happened somewhere before the deployment.
I’d like to thank you for your patience and suggestions in the meantime, appreciate it a lot
np One thing I’d say to keep in mind, recently AWS updated their RDS CA certificate for secure connections to RDS
and gave time for everyone to switch over, its possible that time has passed and anyone who hadn’t switched to using the new CA had it “forced” on them
causing a restart
hm that was supposed to be March 5th, so maybe it wasn’t that
I found one entry on staging staging having the unhandled error, but it didn’t down all the tasks it seems.
for the target-group this service is registered in. Does the health-check allow for multiple failures before considered unhealthy?
or just a single one? Technically the cluster-url should be 100% available but its hard to calculate what possible edge-cases there could be
Not much, but it should be enough for a recovery.
hmm ok so if this were on the Aurora side, it’d have to be unavailable for 30+ seconds to trigger this
Uhhmm, our app is not robust in that regard: one of those unhandled errors causes the container to crash, so when the connection gets terminated, it’s an unhandled, causing a container crash.
ah ok. so if the db was unavailable at the time of check the process exits.
I’ve had similar issues, in a lot of cases we used supervisord in our containers
and that would be the “watchdog” of the process. but we also had APM and other reporting so we knew when the process crashed
SELECT pg_terminate_backend(pid) FROM
pg_stat_activity WHERE application_name = 'api-health-check';
Just ran this, killing all connections from the api and they all crashed.
ouch
gotcha so error handling and retries might be a good takeaway
haha yep Still wondering why it happened at the 24 hour mark though, but could be connection cleanup or something like that…
I would look at the Logs & Events Tab in the Aurora Serverless Instance details
and see if there were any maintenance or restart events
Cannot see anything there happening around that time. Also nothing weird in the postgres logs
I find APM’s priceless in triaging most issues like this. Depending on your companies appetite there are some reasonable options out there ranging from really cheap DIY, to arm and leg hosted in cloud
NewRelic / DataDog are pretty common
I’m a fan of Elastic APM as its simple but effective
Thanks for the suggestions, unfortunately i’m not given the time (yet…..) to look into those solutions..
np, been there. Good luck Feel free to reach out
Thanks again! Will keep that in mind
No, that doesn’t sound right. I’ve just checked and have Fargate tasks running since January.
2020-03-27
Is chamber able to read secrets that it didn’t write? I have set the KMS alias, and I can list the keys, but they are showing up with Version 0, and I am unable to read them.
Looks like it’s related to this issue: https://github.com/segmentio/chamber/issues/251
Adding @discourse_forum bot
@discourse_forum has joined the channel
2020-03-28
With RDS IAM authorizations for database users, is it possible to have ‘real users’ (ie, Tom Jones) who log into AWS via Okta SAML and assume a common role (“Developer”) still have unique RDS IAM authorizations? ie TomJones has okta username tJones@myco and assumes the Developer role, I still want him to use a database IAM user tJones, and not have access to the ‘bSmith’ database IAM user that maps to user Bob Smith.
Answering my own question, we found an Okta blog post that showed us how to pass additional Principal Tags through the SAML response that AWS can use, which allows us to get the exact username from Okta.
, means that you don’t have to create a user for database, instead use the real user who signed using Okta SAML. Using a tag are you able to control which user should have an access to which database?
No you still have to create the user on the DB, and grant it the rds_iam flag so that it can use the IAM auth. What I was then seeing was that our ‘userid’ comes in as <roleid>:<oktaname> which was super user unfriendly as a login name. Eventually we found a blog from okta that said we could enable a beta feature on our account that would let us pass extra SAML tags into AWS. Note though - this required a change to ALL trust policies for the SAML, it actually broke some of our logins for awhile
thanks for sharing it!
2020-03-30
This message was deleted.
2020-03-31
Anyone have thoughts on only using Workmail to forward mail to another address? Im moving my domain away from GoDaddy to R53. I currently have my email setup to forward to my gmail address and then when I send from there gmail is set to make it look like im sending from my domain address. Can I use Workmail as a “proxy” the same way and have it dump all my email to my gmail address? My other option is to just go with Gsuite basic plan and basically pay $6 a month to do the same thing.
FWIW, I had a similar scenario and I accomplished it with SES forwarder
it required a lambda and s3 and some policies but it works (for the most part)
there’s the caveat that gmail won’t show attached .eml’s inline
but thats more of a gmail issue
so you have to download it and open it
https://aws.amazon.com/blogs/messaging-and-targeting/forward-incoming-email-to-an-external-destination/ if you’re interested

Note: This post was written by Vesselin Tzvetkov, an AWS Senior Security Architect, and by Rostislav Markov, an AWS Senior Engagement Manager. Amazon SES has included support for incoming email for several years now. However, some customers have told us that they need a solution for forwarding inbound emails to domains that aren’t managed by […]
I went that route since workmail is a lot more expensive
ill check that out
That blog post has comments where people complain about it, and link to a github project with a lot of issues. I ended up making an SES Lambda forwarder in Python that has seen heavy use and works for the most part. I can try to open source it if there’s interest. (it’s a Terraform module, it also uses Step Functions for retries)
“heavy use” = forwarding 10-15k emails per month
I do this, I think ?
Anyone have any ideas on how to setup any type of Directory Service (ie. AWS Managed Microsoft AD) in the Ningxia (China) region WHILE YOUR SOURCE DIRECTORY LIVES IN VIRGINIA. The documentation I’m reading is pretty much saying you need your source directory in China as well. I haven’t been able to Google this…
does the Ningxia region have cognito? Maybe setup an identity pool and point to the AD in VA as the User source?
more of an SSO than directory replication
Hmmm let me dig into that - I appreciate the quick response!
np, I was thinking something like this - https://medium.com/@zippicoder/setup-aws-cognito-user-pool-with-an-azure-ad-identity-provider-to-perform-single-sign-on-sso-7ff5aa36fc2a

This a step-by-step tutorial of how to set up an AWS Cognito User Pool with an Azure AD identity provider and perform single sign-on (SSO)…
with exception of AD being in AWS instead of Azure
I do NOT believe that AWS Workspaces supports Cognito as an IdP. You need to back the “workspaces” instances with a “Directory Service”.
ahh ok workspaces. gotcha
Yeah - here are my options. -AWS Managed Microsoft AD -Simple AD -AD Connector
I’m looking to back one of these directories with an LDAP server in Virginia if possible. I think I need to open a public IP of sorts…or create a VPN between the two, but that sounds illegal…
I’m not familiar with the restrictions of that region, does it not allow things like VPN / VPC peering etc?
I don’t even see a Ningxia region in my console
Oh, the AWS China partition (Ningxia and Beijing) is completely separate from the AWS that you’re (probably) currently using. It’s a completely different login and console with limited services.
ah ok. Well routing issues aside, I suppose you could setup something like FreeIPA in China region
and have that be a peer / slave to your VA region, assuming you can solve the connectivity issue
I think you could use AD Connector w/that? I’m not sure
I’ve never used FreeIPA - I am trying to determine if that would be better than just spinning up another Windows based domain controller in the China AWS region, instead of learning and testing this new tech (FreeIPA).
yeah just regular windows might be better if you have the experience there. FreeIPA is great but there’s a curve. I wasn’t sure what the availability was for MS licensing on that region
Oh goodness…if they don’t have MS licensing then we’ve got bigger problems lol
Hey folks — I’ve got a fun client problem I’m trying to solve. Looking for some input if anybody has a good idea…
I built the environment like so:
3 domains =
CloudFront distribution =
ALB =
ECS Service
This works great, the ECS Service webserver handles providing different views of the application depending on the domain name via the Host header. That in combination with a couple ALB Listener Rules does the trick for what each of those domains are expected to show.
One of the domains however is the “Admin CMS” domain. I just found out that the client would like to IP Whitelist this domain so only a couple VPNs can access it to help further lock down access to the Admin CMS. This is tricky of course since I cannot use standard security control mechanisms (the ALB security group or VPC Network ACLs) since ALL domains are routed through the same ALB, which means I cannot apply a security group rule to only one domain.
So I’m looking for a workaround… Maybe through an additional ALB Listener Rule? Has anyone used Listener Rules to block / allow CIDRs? Is that a thing? Looked into this shortly yesterday and I’m about to start researching more now, but figured I’d ask here in case somebody goes: “Oh yeah of course, do X”.
I could obviously spin up another ALB, point the domain at that, and then use that ALB’s security group to control access. But unfortunately that increases cost and complexity of the system which I’m trying to avoid.
Any suggestions?
When you say IP Whitelist, does that mean outbound from the client -> ALB ?
or inversely whitelist the clients coming over a VPN to the ALB
I think you might be able to do this with a WAF header based rule, using the host header?
I’m saying whitelisting client IPs so they’re the only ones who can access that domain.
WAF header rule is interesting. I already have a WAF ACL setup against the CF Distribution for the top 10… Will add that into my research
Yeah you could do a webacl at the ALB level, set it as a regular rule with two statements. The first to match the host-header, and the second to match the IP
whitelist by default and then blacklist if not matching that pattern maybe
or vice versa
I’ll check that out. Haha it’s funny that using the WAF for typical firewall usage didn’t come to me.
@androogle Was able to get that working via WAF rules. Thanks for the idea man!
Np!
Hi just wondering, anyone having some terraform modules to setup an EKS cluster with ondemand (only when needed) gpu scaling for KubeFlow?
Cluster auto scaler works great. Could set it up in a GPU node pool