#aws (2020-04)
 Discussion related to Amazon Web Services (AWS)
Discussion related to Amazon Web Services (AWS)
Discussion related to Amazon Web Services (AWS)
Archive: https://archive.sweetops.com/aws/
2020-04-02
2020-04-03
Hey Folks i need to make docker swarm cluster on EC2 with auto scaling in Terraform scripts how can i add new scaled up Ec2 to docker manager setup
What is docker manager?
Do you mean add to docker swarm cluster?
In this case you should use userdata.
yes
something like this
I am trying to create a Docker Swarm cluster using Terraform, I created 1 manager and 3 worker nodes. I installed Docker and initiated the Docker Swarm and created the manager token. How can I for…
Thnx for help got it
NOOB here please help
How can I update an RDS master password in a way that my backend connections don’t have downtime? We currently are passing in the database URI onto our servers via an SSM param
you need to restart the writer for that?
I will recommend to use Secret manager integration to autorotate passwords
You can create a new user with similar permissions, configure these credentials at the clients. Then you can change the master password as much as you want without causing downtime.
Yea, this is what we do. We don’t use the RDS master password for anything except creating roles and databases for our apps. FWIW we use the postgresql ansible modules for this.
Hey guys, IAM related question. Suppose company A aws account has for instance three users who access the company A aws accounts using company SSO (auth linked to Azure AD). These 3 users additionally want access to a different company B AWS account (access to S3 buckets in company B account, both read/write). Requirement is, to use the SSO based credentials of company A. How can this be achieved? Requreiment is NOT to create separate IAM users in company A (and then trusted relationship), but to use SSO based temp credentials (24 hour tokens). Does anyone has any insight on how it can be achieved?
The easiest implementation would be for company B to create roles for people from Company A to use. In those roles the assume role policy would allow the SSO-linked Roles from company A to assume the role in company B.
This article goes over cross-account role assumption and permissions. It talks about dev/prod accounts, but the fundamentals of cross-account role assumption in it still apply to your situation.
Learn the steps for delegating API access in your AWS account to an AWS Identity and Access Management (IAM) user in another account. (First of four).
Besides cross account roles you can use bucket policies: https://aws.amazon.com/premiumsupport/knowledge-center/cross-account-access-s3/
For Federation I would look into Okta if I were you, they can maybe also supply temporary access credentials. Okta can work together with Azure AD and AWS.
thanks for the input guys. We dont use okta.. to pricey for us haha
If it’s just S3 buckets you can add policies right to the bucket to allow principals in another account
I’m not sure how Azure AD gets setup but with anything SAML (Okta included) you can have the IdP (Azure AD/Okta) specify the allowed AWS roles in the SAML assertion so users can log right into specialized roles with various access
2020-04-06
2020-04-07
I’m looking for scripts to make 2 common AWS actions easier:
- A script to simplifiy starting a session on an instance, ideally something that lists instances, autocompletes names, etc.
- A script that will 1) execute a state manager association and then poll until it finishes and output the log (from the s3 bucket) to my console Anyone know if something like these exist?
have you tried this one? https://github.com/pmazurek/aws-fuzzy-finder
SSH into instances using fuzzy search. Contribute to pmazurek/aws-fuzzy-finder development by creating an account on GitHub.
https://github.com/claranet/ssha
it’s project based, so each project defines a settings file with the relevant settings (like aws profile to use, filters for environments, etc). you cd into the project repo and run ssha and then browse through the instances and connect to one.
SSH into AWS EC2 instances. Contribute to claranet/ssha development by creating an account on GitHub.
(we have hundreds of AWS profiles with various projects and environments so being project/settings-file based is very helpful in our case)
Interactive CLI tool that you can connect to ec2 using commands same as start-session, ssh in AWS SSM Session Manager - gjbae1212/gossm
AWS SSM Session manager client. Contribute to danmx/sigil development by creating an account on GitHub.
Easy connect on EC2 instances thanks to AWS System Manager Agent. Just use your ~/.aws/profile to easily select the instance you want to connect on. - claranet/sshm
So many to choose from
Found another https://github.com/xen0l/aws-gate
Better AWS SSM Session manager CLI client . Contribute to xen0l/aws-gate development by creating an account on GitHub.
Awesome
What about a tool for #2?
Running and outputing logs from state manager associations
what are you trying to get? the console session logs?
not session manager logs, but the output of associations, in our base the results of running ansible playbooks
not really sure what ‘state association’ is in this case…
the results of running ansible playbooks
Have you looked at ARA?
https://ara.readthedocs.io/en/latest/
I could write a script I suppose, wouldn’t be too difficult:
• input state association id
• trigger association
• get execution id for the association
• poll for it to complete
• get execution output s3 directory
• fetch file from s3
• print file to console
State Manager Associations are found in: AWS Console > Systems Manager > State Manager
ahh - we only use systems manager for the Session connection and param store, so I’m not familiar with the rest of it. But ARA is a good tool for looking at the output of Ansible runs (just stick to the ara-api server for now, the ara-web is behind on development)
Looking at all these ssh-alternatives, I really like ssha because it has per-project configs. And you can use tags to filter the instances you want.
But it doesn’t seem to work when using aws cli v2 and AWS SSO
Looks like this might be a boto3 limitation: https://github.com/boto/boto3/issues/2091
Hi, It would be great if you can add support for AWS SSO. needed actions: Create new AWS SSO permission sets (including the managed and custom policies). Assign users/groups to permission sets. Get…
Damn. I haven’t used AWS SSO nor AWS CLI v2, so it’s never come up.
2020-04-08
Hi, We have been using SSM parameter store and chamber with clousposse modules and everything is good but now we have multiple teams that need access to RDS and we have testing users added in and we added the password to Parameter store and we allow each user to assume a role that can decrypt and read the parameter but it is pretty cumbersome and prone to user error. We have been looking at RDS IAM auth which is too cumbersome so I was wondering what you guys will recommend in this situation ? I thought about setting the users with chamber to read the secrets or something like that
IAM auth too cumbersome because of the work on the back-end or because of the effort needed on your (potentially diverse) set of clients?
this is a people problem mostly
people have a hard time using assume role policies and such
in my side I have everything setup with assume role and it works
Is it a people or a tooling problem? …
If the diversity in client software isn’t too large - usually you can “help out” provide tooling..
I used hasicorp Vault before and with vault you need to use the client or know how to make a curl request
If it’s more or less a “free-for-all” on the client side, you really have to try to strip out the complexity on the back-end instead
you are thinking too far
this is way before any software is written
So it’s even on the basic “accessing credentials” level.. for human consumption of said credential?
is like “hey I need to access this Mysql for the software I need to write, ok so I will test the connectivity first, o I need a user and pass”
correct
Well, can you instead curate a few preferred tools for doing so?
“reveal-my-credentials.sh” “mysql-client-wrapper.sh” “my-mysql-proxy.sh”
consider providing a docker which gives them a local unauthed mysql proxy on 127.0.0.1
abstract all the horrible things in a “docker-proxy” …
(sorry for just spitballing’ :D)
I think it’s an interesting problem but I don’t have an immediate solution.
it has to be very easy for them to do, that is one problem
imagine that they had issues doing this on the console….
Can they run docker? ..
they could yes
how about using terraform to store details in a password service? https://github.com/nrkno/terraform-provider-lastpass https://github.com/camptocamp/terraform-provider-pass https://github.com/anasinnyk/terraform-provider-1password
Terraform Lastpass provider. Contribute to nrkno/terraform-provider-lastpass development by creating an account on GitHub.
Pass Terraform provider. Contribute to camptocamp/terraform-provider-pass development by creating an account on GitHub.
Terraform provider for 1Password. Contribute to anasinnyk/terraform-provider-1password development by creating an account on GitHub.
(i have not used any of those providers, nor do i know if those services work well for teams)
it sounds like you just want to make passwords really easy for people to access, which isn’t a problem specific to RDS
but we do not have company wide contract for those tools
pass is open source, can be backed by git for syncing, and has an ios client
i’m not saying it’s definitely the way to go, just an avenue to consider
absolutely
I did a thing which might be relevant to y’all//twitter.com/iamvlaaaaaaad/status/1247929989137403905> ( hope useful self-promotion is allowed here — if I’ve failed please let me know )
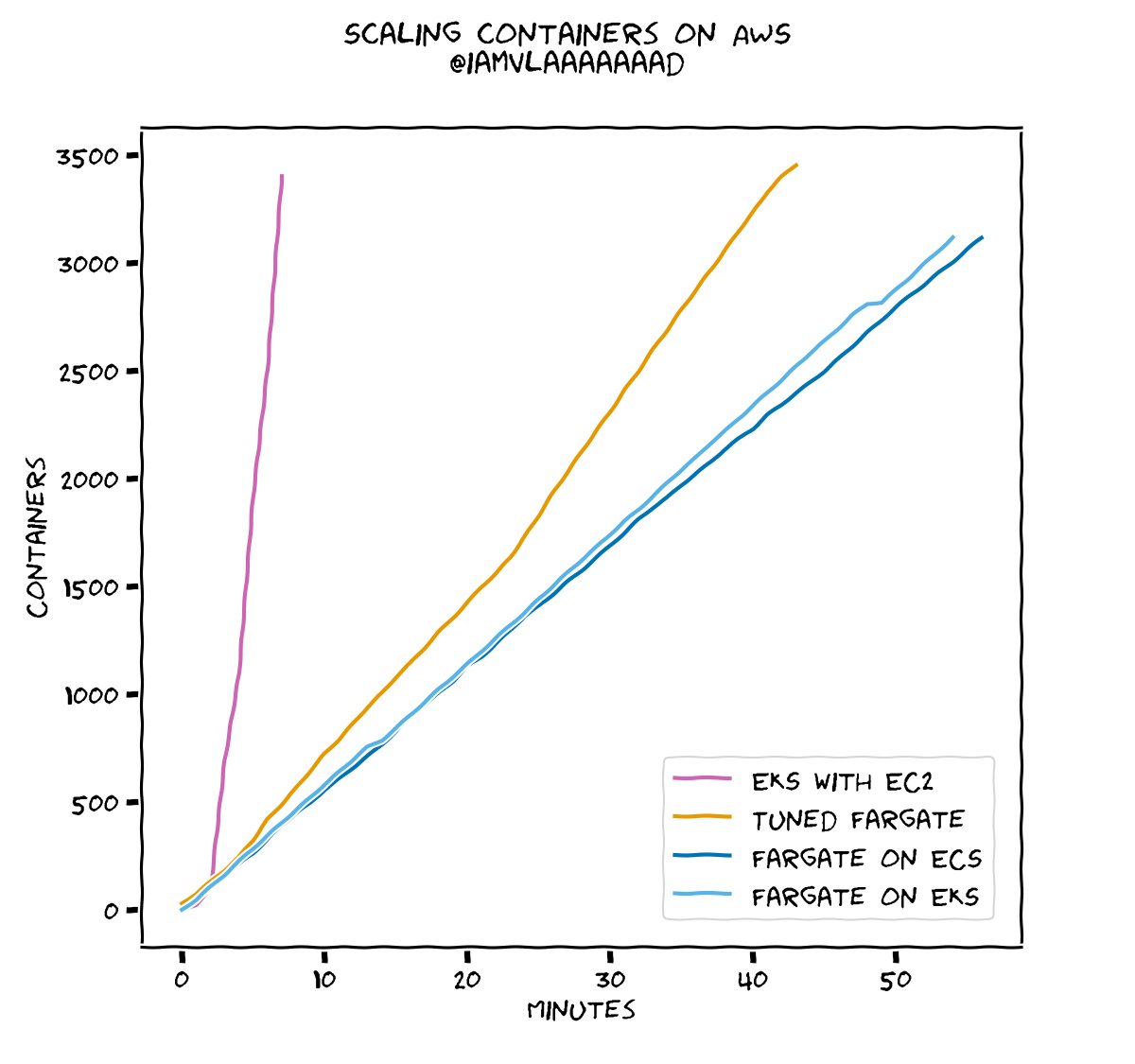
How fast do containers scale up in AWS?
Is ECS faster than EKS? What about Fargate? Is there a speed difference between Fargate on ECS and Fargate on EKS?
Now we know! The results are what matters, but for the curious, full blog post at https://www.vladionescu.me/posts/scaling-containers-in-aws.html https://pbs.twimg.com/media/EVE3dX-UEAAIz8M.jpg
Great work!
How fast do containers scale up in AWS?
Is ECS faster than EKS? What about Fargate? Is there a speed difference between Fargate on ECS and Fargate on EKS?
Now we know! The results are what matters, but for the curious, full blog post at https://www.vladionescu.me/posts/scaling-containers-in-aws.html https://pbs.twimg.com/media/EVE3dX-UEAAIz8M.jpg
 1
1Anyone here have experience with NLBs? I’m looking at trying to expose an elasticache redis instance to the internet by putting an NLB in front of it

The NLB’s target group sees the redis instance as healthy, using an IP target and TCP health check. But hitting the NLB with redis-cli ping, I get a timeout
I’m sure there’s a reason why this won’t work, and just curious what it is
do NLBs handle the egress traffic as well as the ingress? Or does an NLB only handle ingress?
Traffic both ways goes through them
On k8s I thought ingress only and egress via Nat gateway. Depends if you’re using local value to preserve ingress source IP and DSR. Could do double check with an external endpoint..

It has only been five years since Jeff wrote on this blog about the launch of the Amazon Elastic Container Service. I remember reading that post and thinking how exotic and unusual containers sounded. Fast forward just five years, and containers are an everyday part of most developers lives, but whilst customers are increasingly adopting […]
Ooh this seems like a big deal
It has only been five years since Jeff wrote on this blog about the launch of the Amazon Elastic Container Service. I remember reading that post and thinking how exotic and unusual containers sounded. Fast forward just five years, and containers are an everyday part of most developers lives, but whilst customers are increasingly adopting […]
Fargate becomes viable for more things
nice
2020-04-09
Hey Guys need help with RDS backup i have scenario in which many site data is stored in single RDS need to automate backup for particular site data and store it to S3
AWS Backup | Centralized Cloud Backup https://aws.amazon.com/backup/
AWS Backup is a fully managed backup service that makes it easy to centralize and automate the back up of data across AWS services in the cloud as well as on-premises using the AWS Storage Gateway.
does it help me to create of part of rds like a mysql query
How are folks monitoring their Fargate clusters/containers?
Prometheus? CWL?

Amazon Elastic Container Service (Amazon ECS) lets you monitor resources using Amazon CloudWatch, a service that provides metrics for CPU and memory reservation and cluster and services utilization. In the past, you had to enable custom monitoring of services and tasks. Now, you can monitor, troubleshoot, and set alarms for all your Amazon ECS resources using […]
cAdvisor?
I want framework + app + container level metrics
this is a pretty good one to sidecar https://github.com/influxdata/telegraf/tree/master/plugins/inputs/ecs
The plugin-driven server agent for collecting & reporting metrics. - influxdata/telegraf
Aye, have used telegraf, great tool and flexible!
Hey folks — This is more of a bash question, but I’m sure there are aws-vault users here and folks have dealt with this before so I figure I’ll have a quick answer…
Issue is if I’m using aws-vault exec gowiem --no-session -- $ALIAS_OR_FUNCTION I get errors similar to the following:
aws-vault: error: exec: Error execing process: exec: "tfplan": executable file not found in $PATH
I have a bunch of functions and aliases for my Terraform workflow, so this throws a wrench into my works when I don’t want to specify a specific profile in my provider and instead want to use aws-vault. Does anybody know how I can have aws-vault pick up my non-PATH based commands?
You essentially would have to start an interactive shell, source your aliases, then run the alias command …
I’ve just used this after aws-vault exec command:
source ~/.bash_profile
oof I was hoping that wouldn’t be the answer. Maybe I’ll update my aws-vault aliases to include sourcing my shell and see how long that’ll actually add to my command. But in general… that sucks.
I’ve made a few aliases with env embedded. Ideally though you could make your aliases functions which take an optional --profile param?
I have few enough profiles that I don’t really need anything esoteric.
Mind sharing your aliases where you’ve included your env?
it’s way too simple:
alias saw-prd="aws-vault exec battlelog_prd -- saw"
alias tail-bl-prd="saw-prd watch /infra/bl-prd/svc/battlelog.log | ccze"
here’s what we use
example of your alias command?
alias foo=’echo “bar”’
Haha yeah, not sure if the aliases matter, but here they are just for sharing:
alias tf='terraform'
alias tfyolo='tf apply -auto-approve'
alias tfrun='tf apply run.plan'
alias tfw='tf workspace'
alias tfws='tf workspace select'
alias tfi='tf init'
alias tfout='tf output'
and my tfplan function:
function tfplan() {
if [[ -d "./.terraform/" ]]; then
workspace_name=$( terraform workspace show )
if [[ -f "tfvars/${workspace_name}.tfvars" ]]; then
echo "Running terraform plan with ${workspace_name}.tfvars..."
WORKSPACE_ARG="-var-file=tfvars/${workspace_name}.tfvars"
fi
if [[ -f "tfvars/secrets.tfvars" ]]; then
echo "Running terraform plan with secrets.tfvars..."
SECRETS_ARG="-var-file=tfvars/secrets.tfvars"
fi
terraform plan -out=run.plan $WORKSPACE_ARG $SECRETS_ARG $*
fi
}
out of curiosity, what shell? The solution might vary depending on that
Zsh
so, I don’t know if this is an option but..
if I do:
alias foo='echo "aws iam get-user"'
aws-vault exec androogle-profile -n -- `foo
` that seems to work
you’d have to either rework your aliases and functions or have separate copies
Haha hacky. I like it. I’m going to play around with a few things, and I’ll add that to the list.
I tried eval and a few other things like $(something here) but shell expansion doesn’t happen there or at least in the order you want
I’d like to be able to do this too (same / similar use-case having tf + aws-vault play nice together)
When I asked the question I was thinking this was a solved problem… but if it’s not it’s likely smart to open an issue with aws-vault and see if we could get it fixed upstream instead of local workarounds. I’ll try to open an issue with them later today.
you could make it a bash script and call the bash script instead of using alias
Yeah — could add all my aliases and functions to a bin folder and go that route. I’d like to avoid that if I can…
I did just try the following… adds a full second onto my execution time.
alias avgow='aws-vault exec gowie-aws --no-session --'
alias avgow_withsource='aws-vault exec gowie-aws --no-session -- zsh -c "source ~/.zshrc" &&'
For now… a second is worth it I guess. Not like any of Terraform commands take less than a second anyway.
Well seems I had a bad example in using terrform workspace with local state…
Seems my source ~/.zshrc actually clears my environment variables which includes the aws-vault environment variables. They get cleared and then any command which needs them doesn’t work. Haha back to the drawing board on that one.
Okay… so this works, but I don’t like it…
function av_cmd() {
local profile=$1
local cmd=$2
av exec ${profile} --no-session -- zsh -c "source ~/.zshrc && ${cmd}"
}
And that doesn’t actually work because alias commands don’t allow usage of the alias until the next shell invocation and && doesn’t cut it. So I ended up converting all my aliases to functions. Ugh this problem sucks.
here’s what we use
source <(chamber exec kops -- sh -c 'export -p' 2>/dev/null)
that imports your aws session into your current context
then you can use all your bash aliases as-is
@Erik Osterman (Cloud Posse) You’re saying with aws-vault usage? Am I getting it right that you run a source export -p to export the AWS_ vars out to your current session and then just continue on as normal from there?
Yup
The problem is that those aliases are a language construct of bash
They can only ever be interpreted by bash
Either move the aliases to standalone bash scripts (“stub scripts”) or use the pattern above
Sorry - was distracted when posting that example above. I realize that is for chamber, but the same applies to aws-vault
source <(aws-vault exec $role -- sh -c 'export -p' 2>/dev/null)
Gotcha — That’ll definitely do it and is ~likely~efinitely cleaner. Seems to go against what aws-vault is trying to do in regards to not having the AWS session persist outside of the exec command, but I’m not sure I really care too much about that…
Thanks @Erik Osterman (Cloud Posse)!
2020-04-10
Are there any examples of a good EC2 AMI delivery pipeline across multiple stages/accounts? Our system is all EC2 instance based, running services in ASGs behind an ALB. The ‘pipeline’ such as it is at the moment, is just building AMIs with packer and then running terraform to swap the ASG out (we have the ASG name linked to the AMI creation date, so it creates a ‘blue green’ AS swap). Fairly manual at the moment although we’ve got some limited scripting around these to allow jobs in Rundeck. I’m just not sure how we’d best move an AMI through several stages in an more automated fashion. We don’t release very quickly is the other problem (which I’m hoping to accelerate)
We used to do this and we used codedeploy
With codedeploy you can setup blue/green or canary deployments
You could Also integrate codepipeline in the mix but we didn’t ended up using it
Is your idea to promote environments?
Yes, promoting the AMI from dev to qa to prod
it would probably need manual approval steps due to some sensitivities with changes in our app from the customers
You can do manual steps in codedeploy
Ok so maybe we’ll look at that… and it handles cross account deploy?
But are your amis the same in every stage?
not sure how this will fit with our terraform though
Yes the same AMI. RIght now we’re building the application artifacts and THEN building an AMI somewhat ‘manually’ on-demand, but I’m in the middle of making the packer build of the AMI part of the overall build step, so the AMI itself is a build artifact
Sound almost the same we did and I think codedeploy can do it but not alone
I remember we used a jenkins promotion plugin for it and chef to do some Infra changes
Which I don’t recommend, there is plenty of new ci/CD tools out there that can do this
Like code fresh or harness
right we have jenkins for the builds, we’re not happy with it overall
jenkins is not bad for what it was build but people blame jenkins for plugin X, plugin Y
oh I’m a long time user of it, I agree. Its more that its at a point where it doesn’t fit the use-case
people send automated letters to grandma using jenkins these days and they complain about jenkins
not USPS
How/where did you store an app/ami version or build number for something that needs to progress to next stage?
it depends
if you go from one account to another is a bit tricky
there were parts of the system I did not build but if I remember correctly the “golden” AMI will be pushed from packer to the different accounts
I think at the end the promotion process was more like deploy to dev, test, deploy to test, test, deploy to stage and be very carefull and test and then there was a push to prod that basically used the stage stuff except for the configs of the different endpoints
we used Spinnaker at some point too, wich is cool but I do not recommend that much
it is hard to mantain
that is why I said CodePipeline and Code deploy can do what you need
gotcha
that’s how we move the process now (we share the AMI with the other accounts so have access, but they can’t see the tags due to AWS limitations), its just very manual in that I go run the terraform to deploy dev, wait a day for testing, then run the terraform to deploy it in test, etc
but if you can use something like harness.io or codefresh I will recommend that instead
we treated the AMI as code as well
so we had some pything scripts that will run on the jenkins pipeline to move things around so that codedeploy could pick it up and such
or ASG if you use them
I create container definition + service “skeleton” with terraform… but there’s alot of stuff I dislike about having the skeleton in terraform and the deployments in codepipeline… combining the two isn’t all glory. but there are so many infrastructure things to tie together with the service in question that it’s the best I can do right now… once a service itself is more or less “stable” in its shape and form - the only thing happening is new code => new build, new container to ECR => new ecs deployment anyway so once you’re there, the Terraform parts really don’t move at all until you decide you need to restructure something
Zach: I share AMIs cross accounts to… due to tag restrictions I have quite long “descriptive” image names instead, so the tags aren’t really needed. all needed info is in the image name itself.
something like myimage-branch-version-gitsha
we do the sam with containers, a non empty tag def so TF can run and then the rest is manage by an external app, which we wrote in GO
but it can be any other
is the glue in between that is needed and that is between TF and the code being deployed that somewhat leaved in a weird place
Multi-stage yaml pipelines in azure devops + SSM parameters update in terraform. Just run the SSM parameter terraform plan when ready to refresh your SSM parameter containing the id of the ami
You can also use labels on the SSM parameter to allow continual updates to the value while only pulling the labeled ‘release’ Ami id in the history of the SSM parameter
we used consul key/value as a store for config per environment, you can do the same with Parameter store or Secret manager, that is agood suggestion
2020-04-12
2020-04-13
guys is there a standard on CloudPosse terraform outpus ? I see it is not Json compliant
for example:
[
{
"autoscaling_groups" = [
{
"name" = "eks-72b8b964-bfb4-e582-36d5-a0cb231a4ab5"
},
]
"remote_access_security_group_id" = "sg-01f490d95dcc8f35b"
},
]
which command you use to parse this ?
jq is not parsing this
@omerfsen The JSON is malformed
terraform output -json eks_node_group_resources | jq -r
[
this does the trick
Just found it
Anyone here familiar with RDS Event Subscriptions? I have one made by Terraform that says Status is NULL and im unable to edit it. If I make one manually in the console it works just fine. Same settings.
I’ve been meaning to set something like this up. I tried an older cloudposse one or something someone else created and found out it was only 0.11 compatible so I couldn’t setup event subscriptions at the time.
I’d love to have this a enable/disable option in my terraform rds module for sure!
2020-04-14
hey guys, running ssm run(Applyansibleplaybook) command but ansible using python2 but when i run locally(EC2) its working fine help
You want ansible to run with python3?
Ensure ansible_python_interpreter: /usr/bin/python3 is in your vars
thnx @Abel Luck
Hello Guys I m looking for scripts that can trigger Gitlab-CI from AWS lambda and trigger lambda via slack
please
2020-04-15
I don’t know of any off the shelf scripts that do that, you might have to write your own. Gitlab has docs for triggering pipelines via the API here https://docs.gitlab.com/ee/ci/triggers/README.html
Documentation for GitLab Community Edition, GitLab Enterprise Edition, Omnibus GitLab, and GitLab Runner.
We have a CICD pipeline on AWS. Written entirely in cloudformation templates. But the annoying thing is we can’t delete stuff in S3 after the stack is done. Any idea how to work around this so we delete everything when the stack is no longer needed.
The bucket you tried to delete is not empty. You must delete all versions in the bucket. (Service: Amazon S3; Status Code: 409; Error Code: BucketNotEmpty; Request ID
terraform has a flag for that https://www.terraform.io/docs/providers/aws/r/s3_bucket.html#force_destroy
Provides a S3 bucket resource.
this is an S3 API feature so I guess the same can be done in CloudFormation
interesting. thanks for letting me know about this
2020-04-16
Hello, I am a bit confused with how Cloudfront works with an S3 SSE-KMS bucket (Cloudfront uses OAI to access the bucket). I am able to fetch an index.html file perfectly fine by hitting the CDN DNS in the browser when AES encryption is applied. However when SSE-KMS encryption is enabled on the bucket, kms.unrecognizedclientexception shows up for the same page. What needs to be done in this case to enable access to the html page residing in the bucket to be accessible by CDN ? Why is the decryption not transparent in this case ? Any pointers appreciated.
You can only use AES256 for your s3 bucket which is accessed by cloudfront via OAI from my experience.
Thank you for sharing .. as far as I have googled that’s what seems to be thus far.
2020-04-17
Here’s a weird scenario. We’re playing with AWS Global Accelerator and have it pointed at a public facing ALB, which is fronting a bunch of EC2 instances. The GA is referenced by a Route53 record. We have another Route53 record that points directly at the ALB. ga.mydomain –> globalaccel –> ALB alb.mydomain –> ALB
In the course of some other network troubleshooting, my colleague went onto one the EC2 instances and ran a long series of queries and pings to the Global Accelerator R53 record, and to the ALB R53 record. When we compared the results, the Global Accelerator was 2x faster than going ‘directly’ to the ALB itself. We’re not sure how that works, since the GA is based on ‘edge’ locations, while the ALB nodes should be co-located with our instances. This seems like voodoo magic and we’re not sure what to make of it.
Global accelerator is a basically layer 4 CDN in a way
that is why we use it
it will route your request trough a faster aws network (same as cloudfront) and will server the request back from a router closer to your location
same as a CDN
yah but if the requestor is already on the aws network (ie, an ec2 instance) and the target is the ALB, shouldn’t that already be the fastest route possible?
it just seems to defy our undestanding
ohhh you were doing your test from whiting aws ?
yes thats what was bonkers about it
nothing should be faster than doing it from the same vpc
except the GA was 2x faster
mmm but you were doing tests to the public ip of the alb from a private subnet inside the vpc ?
Yes - we have a not-so-great setup right now with our APIs
you could do a traceroute and see what is the path is taking from each place
and you could add an internal alb and do the same test
I wonder if the “firewall” effect of the IGW could be adding to much time to your request
that’s related to why we were checking this in the first place. We have a bunch of go apps and the net/http lib was complaining of ‘client header timeouts’ (we had it set to a 5sec max time for the response) - we did a whole bunch of testing, and we found that sometimes the ALB would take as long as 8 seconds to ‘ack’ the request
if you do a test from the private subnet, it needs to go out trough the nat gateway then igw then BGP aws routers , back to the IGW, ALB backend and then response out again to the IGW , aws BGP , IGW, NAT gateway and finally instance
so we wired up some tracing and found that these bad connections in the applications were taking up to a minute to get the response back from the alb. We suspected maybe we had a bad node or something, so we blew away the ALB and tried a new one. Same issue.
if you have internal service that talk to each other you should never use the a public alb for intercommunication , that is going to be slow a not so secure
only internal albs
or you can use app-mesh too
yah, the slowness is now evident. the security we do an auth check on every call - which is how we found this problem because that suddenly started killing a lot of requests
when I worked at a big game company, we used to have like 5 public ALBs and like 20 internal albs
we even have ALB with special rules for the same service but different clients
kinda like treating the ALBs like api gateways
but internal facing only
Yes thats how the ALB is run right now, its basically an API Gateway
bu if the alb does not need access from clients or external integrators, then it should be only internal
but, all our services are run off EC2 right now, I’m working to migrate that
I see ok
yah agreed - the problem I stumbled upon is that our actual client apps talk to these internals too, so I still need the public facing ALB to route to the internal services. I’ve been pretty suspicious of having our apps talk to each other “internally” through the public ALB, so this is good confirmation
And unfortunately App Mesh isn’t HIPAA eligible yet
so basically you will endup with the setup we had a public facing alb for external clients and and internal for inter-app communication
you will double up the cost of albs but I think it will be faster
ygotcha
thanks for confirming, we’re gonna run some tests and I’ll start working on a reworked architecture…
let us know how the tests go
Interesting - added an internal ALB in 2 AZs. Depending on which node of the ALB I hit, the ping response is < 1ms avg; if I get the other AZ node it is more like 1.5-2ms avg which is the same as if I query the public ALB.
cross AZ that will happen
but your new internal ALB is multi AZ and on the same subnets than the instances ?
Yup
and the service behind the alb is deployed in the same AZ ?
Its deployed in the same AZs yes. But you still get a random node of the ALB, not the one in your AZ every time
I think though internal albs will do the selection automatically depending of the AZ
or that was some fuu with sessions or something like that
I can’t remember
Doesn’t seem to - you’d think that would be a feature though! I put the ALB into 2 AZs, and assigned it just a single instance in a target group. From that instance, a ping flips between the 2 IPs of the ALB node using the AWS DNS entry.
Well that is against the HA in a way
about the GA speed is because the ACK will come directly from the GA node and it will route it to the ALB
so you mean it will not go out to the internet and then to GA ?
I think it does, but the GA does a ‘parallel’ connection to the ALB while its sending you the ACK. But even still, the GA endpoint is ‘edge’ and so I would still have thought that the ALB endpoint in the VPC itself would respond faster
Also still unclear why we have these weird connections that just ‘dangle’ for almost a minute before the ALB even responds to the initial connection
time to enable vpc flow logs
I think our use of the public facing ALB for ‘internal API chatter’ breaks the usefulness of the flow logs to a degree, since the traffic keeps going out and back in. I’m just going to take this is the time to get this broken apart correctly, it had irked me when I first saw it and now I have some actual weight to say its not right
also, if you’re going internal instead of Internet egress and back in, there’s at least a chance that you’ll be within the same AZ and thus won’t pay 100% cross-AZ traffic.
2020-04-18
From time to time I get bots trying to scan our AWS servers. I often get this error in the application log. I am trying to find effective ways to stop this higher up in the stack. Maybe at the nginx level or cloudflare level. Any recommendations? This is obviously not AWS specific but that’s where I am seeing happening most frequently for us.
Invalid HTTP_HOST header: 'example.com'. You may need to add u'example.com' to ALLOWED_HOSTS.
We use cloudflare firewall rules for this
Happy to share a our list of tricks
Ideas are to challenge certain ASINs
Challenge requests from countries you do not primarily conduct business with
Also, on AWS IPs for ELBs float around so stale dns caches will send traffic from previous tenants to your load balancer (and the other way around)
Hi @Erik Osterman (Cloud Posse) Did you completely migrate your dns to cloudflare? Do I need to do that to make cloudflare more effective in fighting attacks for me, what’s your opinion on thios?
Yes using cloudflare prob makes most sense. Will look into this. Any tips appreciated
You don’t need to necessarily migrate your entire dns stack to Cloudflare but it makes using the service MUCH more effective.
I’m a long time CF fan
Oh Okay! Thanks @Zachary Loeber
you can also fix this on nginx level with ease. I guess it happens mostly when bots/malicious actors scan the ip ranges for some webapps. You can define default nginx server which always returns 404 except the the context used for elb healthchecks and define servers for your actual domains
this way whenever anyone tries to connect via IP and puts trash into Host to be http/1.1 compliant the request will end up in 404 limbo and only valid actors knowing the domains will end up on the actual site
in nginx you can use server_name _; as a default to catch them all
@HS we typically use 2+ DNS zones. One is for service discovery and not used by end users. This is typically hosted on Route53. Then we have our branded domains (aka vanity domains). These are what we’d host on Cloudflare.
Branded domains are what end-users access and typically change very seldom. While records on the service discovery domain change all the time and have short TTLs
Interesting approach..thanks for that @Erik Osterman (Cloud Posse)
2020-04-19
Hey folks, does anyone know what the typical way to run cloud-nuke or similar tools is? Is everyone re-inventing their own solution to run that on a schedule or is there a terraform (or other) solution out there that will spin up a small instance and run that periodically without nuking the instance as well?
Asking before I build that myself…
Hey folks, resurfacing this thread since I posted on a Sunday night and I’m looking to get more eyes on it.
Also any strong opinions on aws-nuke vs cloud-nuke? They seem to have similar levels of community involvement, which makes it a toss up in my mind.
Nuke a whole AWS account and delete all its resources. - rebuy-de/aws-nuke
A tool for cleaning up your cloud accounts by nuking (deleting) all resources within it - gruntwork-io/cloud-nuke
I was using aws-nuke in the past. one really annoying thing was that when you had a large s3 buckets processing them was taking ages. fastest way was to exclude items inside the bucket (which afair required a bucket name) so the report would be much faster and then the bucket would be deleted recursively
also regardless of the tool exclude users/roles and permissions which you are running the tool with.
because you may end up in access denied situation
Haha yeah, definitely planning on using tags for things that should stick around.
Regarding S3 — I don’t believe I will need to blow away any large buckets but good to know.
any s3 bucket with logs will prove you otherwise
2020-04-20
How would you approached RDS (mysql) migration to another account while introducting cloudformation and minimazing the downtime?
Vpc peering and read replicas is how we do it if we can’t have downtime
yeah, if there wouldn’t be a cloudformation in the mix it would be quite simple. AFAIK (and correct me if I’m wrong) if you have a cloudformation managed read replica when you remove the sourcedbidentifier and deploy cloudformation will delete the read replica and create a new database
Use the AWS CloudFormation AWS::DBInstance resource for RDS.
Update requires: Replacement
so maybe instead of relying on the aws to instantiate a read replica I could just create an instance using cloudformation and then configure it manually to replicate from master
I hate cloudformation so I can’t give you an answer but you could split it in a different cloudformation and have a nested stack or something like that ?
I have not used cloudformation in a long time
I remember there was something like a reference stack
I’m already using nested stacks. AFAIK what you’re proposing is not possible because cloudformation will delete an instance when you change/delete source_db_identifier attribute and will create a new resource in place of read replica.
What I could actually do is the create a read replica manually, promote it to be master and then pull it in using cloudformation’s import resource, but it’s such a pain to work with import and I would like to skip that part (-:
yeah it’s using the most shitty dsl you can have i feel like writing puppet manifests when I’m working with terraform …. sooo 2005
well I can tell you that in TF I have multi regions cluster and if I delete the source_db_identifier it does not delete the instance
lol
I don’t mind either of them. it’s just a tool and depending on the context you can use it on not.
what about aws cdk? Is it the same as using vanilla CF ?
in this case cloudformation is used across all other projects and it’s easier for everyone else to pick it up if needed.
@Nikola Velkovski no, AFAIR in cdk you define your infra in a language you use (e.g. in my case it would be python) and then it’s generating the templates for you in the process
IMO that’s really the only valid way to use CFN… render the templates. the templates are an artifact of the release. trying to manage them directly is a big fail
but, side tracking. i have nothing helpful to contribute to the question at hand. sry, just early morning venting for me
@loren IMO by rendering templates by tools like cdk you remove the ability to fine tune your environment because not every option is supported.
Also with cdk generating the cloudformation templates you end up in a situation that some features are not available in cdk which are alrady available in cloudformation so you create additional boiler plates just to make it work. at least in native cloudformation you have custom resources which are closing the gap of stuff not available natively in cloudformation
just my experience talking. cloudformation is way too limited without something writing out the template for you ¯_(ツ)_/¯
as I said, I don’t mind it the same way as I don’t mind working with terraform or any other tool. it’s just a tool which depending on the context will be used or not
i just get tired of the boilerplate in CF. i want a way to define a library of common use cases and organizational standards, and use those across all my templates. copying and pasting it throughout every CF template is unmanageable. we’ve tried getting there with other CF features, like transforms, but those require very special handling and their own deployment/versioning workflow. it’s just annoying. much easier to do though with something like the CDK
there is this thing called sparkleformation
it tries to make CF better
invented before CDK
now CDK is far better than CF it self
has anyone tried pulumi ?
hey, tried that, but stayed with terraform. If I was the only one in the team I’d probably go with pulumi, it has some cool features (managing secrets, shared state out of the box, code completion when used with typescript, cool web UI, etc.) but the pricing model for bigger teams was too expensive for my case. Also terraform doc seem to be way better.
here’s my slides for terraform<>pulumi<>AWS CDK talk ~3months ago: https://gitlab.com/ikar/infrastructure-as-code/-/tree/master/doc sadly the talk wasn’t recorded (it was in Czech anyways )
a none of this solves @Maciek Strömich problem
yeah, sorry, was just the first thread i read as i woke up and am still a little grumpy. hit a nerve with bad CF experiences
@loren you’re excused. drink some coffee before talking to your colleagues
#truth
I have not tried but I have been looking at it
@Nikola Velkovski I was looking at it recently but the pricing put me off a little bit.
Just discovered AWS param store does not allow you to store values containing ‘{{{ .. }}’ in them
wierd….
what happens?
Parameter value: 'This is a test. Hello {{ name }}, how are you today?' failed to satisfy constraint: Parameter value can't nest another parameter. Do not use "{{}}" in the value.
wow, that’s pretty explicitly not permitted. surprised we haven’t run into that before
yea, this is unfortunate.
I’m trying to pass a piece of dynamic config through from terraform -> SSM param store -> ansible.
Ugh, am I going to do some ugly string replacement? I think so.
ya, or base64 encoding
base64 is more of a catchall, so if you get that to work, it covers all your bases.
oh good idea!
Was that meant to be a pun Erik, because it it definitely hit all the bases of one
Haha wasn’t that clever!
I’ve run into something similar. In an ssm doc you can’t specify {{ when I checked last as it was used to substitute variables in. It’s a restriction. If I find anyway to bypass/escape i’ll post here, but pretty sure I just didn’t end up including that in any of my content. Thankfully it’s not really needed with PowerShell except in a very edge case.
2020-04-21
has anyone got a simple little tool for rolling launch template changes through an auto-scaling group
Manage rolling upgrades for AWS autoscaling groups - deitch/aws-asg-roller
AWS CDK, Cloudformation or Terraform can help you
terraform will not roll an updated launch config or template through an autoscaling group
it will change the config for new instances but won’t replace existing ones
cloudformation does - but i don’t want to use cloud formation for just this
thanks @Aleksandr Fofanov - i was looking for something to run in a ci/cd pipeline rather than a service to run
you could in Tf add a cron autoscaling event to scale up and down after the deployment and then delete it
it will work
but it is hacky
can you use Terraform for that ?
Hello SweetOps people. Is there a way to see within the logs all the permissions required to constrict IAM roles to only the permissions they use ?
If this is all logged, I was hoping to see the past 3 months for a particular ECS task to see what perms it uses, create a new IAM role with only those perms, apply the role to the task, see if anything breaks, if so, add additional perms. If not, move to the next ECS task.
Try this? “Achieving Least Privilege Permissions in AWS” by Alex Nikulin https://link.medium.com/qmM4zz9XR5

One of the basic principles of cloud security is the Principle of Least Privilege. The idea is simple: give every user or process the…
if you’re planning to go with trial and error phase I would suggest to start with a clean IAM role and add priviledges as you go. also Netflix has a tool called repokid which was doing something similar
awesome, thanks folks. ill check out repokid and the medium post
Let us know your experience with it. I will explore it as well.
Duo labs GitHub. They have a tool for this
 hi folks, while refactoring for 0.12 noticed https://github.com/cloudposse/terraform-aws-ssm-parameter-store doesn’t appear ready yet. there are a couple PRs which seem to address the issue. any reason those haven’t been merged? is there a better module to be using for this now? TIA!
hi folks, while refactoring for 0.12 noticed https://github.com/cloudposse/terraform-aws-ssm-parameter-store doesn’t appear ready yet. there are a couple PRs which seem to address the issue. any reason those haven’t been merged? is there a better module to be using for this now? TIA!
Terraform module to populate AWS Systems Manager (SSM) Parameter Store with values from Terraform. Works great with Chamber. - cloudposse/terraform-aws-ssm-parameter-store
IMO you’d be better off using the resources directly.
Terraform module to populate AWS Systems Manager (SSM) Parameter Store with values from Terraform. Works great with Chamber. - cloudposse/terraform-aws-ssm-parameter-store
@Mike Hoskins I’ve got one of those PRs, it’s stuck in review cause CP is requiring tests and other 0.12 updates (which I fully understand).
I need to take another crack at updating that, but if you want a working 0.12 version you’re welcome to use my fork: https://github.com/masterpointio/terraform-aws-ssm-parameter-store/tree/terraform_0_12
Terraform module to populate AWS Systems Manager (SSM) Parameter Store with values from Terraform. Works great with Chamber. - masterpointio/terraform-aws-ssm-parameter-store
Also, it’s a very simple module so @randomy’s suggestion is not a bad idea either
hey @Matt Gowie thanks for the info. i pulled your branch last night (sorry i made noise before looking closer) and saw your good work. was going to try and work through the blockers and share anything i learn in your PR. i’ll see how that goes, maybe two heads will be better than one
in many cases direct resource usage can be better that is true…maybe this is added complexity w/o enough gain to justify it. will chat with my team on that, but since the module exists would be nice to help get it fixed up!
@Mike Hoskins Awesome, sounds good! I got bogged down with their bats test + Makefile stuff. Personally don’t have enough experience (any really) with Make to fully grok the CP setup and I just put it down. Need to fix that though…
that is understandable i have a little more experience with Make and bats, but new to terratest. ramping up on a new env is hard w/o someone pairing with you the first time – to encourage community involvement, it feels like the test setup/expectations could be better documented in the project READMEs. maybe that’s on the agenda (understand there are always too many things to do), just some feedback for the larger group…always room for improvement
@Erik Osterman (Cloud Posse) and CP folks do a good job of documentation AFAICT, but a lot of it is tied up in their docs site: https://docs.cloudposse.com/
Which I have likely failed to ~reference~ead enough
(our docs are painfully behind (1-2 years) where we are at these days!)
where are you at these days?
kops -> eks
one repo per aws account -> single repo for all foundational infrastructure
terraform 0.11 -> terraform 0.12
helm2 -> helm3
Docs update complete!
poor gitops -> better gitops
no idp -> keycloak
no aws sso -> cognito, gsuite, okta aws sso
bitly oauth2 proxy -> gatekeeper
list goes on…
it’s a good list, thank you
Would love to see what ya’ll are doing with aws sso — That’s on my list of problems I’d like to better solve for clients.
@johncblandii has also now implemented full coldstart implementation of a new kind of reference architecture (wholely unlike the one on our github). literally, run one command and it can bring up any number of aws accounts with any number of kubernetes clusters, fully provisioned with all services and iam roles.
is that public?
we haven’t had any downtime from our consulting engagements to open source the new ref architecture.
@Maxim Mironenko (Cloud Posse) just putting this on your radar. Maybe after the vpc peering module upgrade you can work on this?
? I have infra in QA account vs prod not just region. So you would setup one repo that has duplicate code for a different account?
I was trying to think of doing repo/region/stage/plan…. Curious if this per account is because of the typical prod vs QA being same account/different region for you
one repo per aws account -> single repo for all foundational infrastructure
we’ve inverted the typical design. we define a module exactly once. Then in a conf/ of each module, we define one .tfvars file per “environment”. To deploy an EKS cluster, for example, in 2 regions, we would just define 2 .tfvars files, one for each region and define the region therein.
no code is duplicated.
but it takes the opinionated route of not version pinning the root module per environment. Instead, taking the route where a PR is not merged until it’s been successfully applied to all regions. That way, there’s “no change left behind”
 1
1and it enforces that each environment is updated in the same order.
what’s been pretty conventional in terraform land is to create a folder structure that mirrors what’s deployed. e.g. prod/us-east-1/eks/*.tf
but this led to either duplication of code in that folder, or necessitates something like terragrunt which supports remote modules (e.g. terraform init -from-module=...)
our current approach is then to define a single YAML file that represents the entire configuration for a system composed of dozens of terraform projects. each terraform project has it’s own terraform state and lifecycle. our configuration file looks something like this:
# Cold start provisioning order for services
order:
# Deploy foundation
- terraform.account
- terraform.iam-primary-roles
- terraform.cloudtrail
- terraform.vpc
- terraform.dns
# # Deploy EKS infastructure
- terraform.eks
- terraform.eks-iam
# Deploy core Kubernetes services on EKS
- helmfile.reloader
- helmfile.autoscaler
- helmfile.cert-manager
- helmfile.external-dns
- terraform.efs
- helmfile.efs-provisioner
- helmfile.metrics-server
- helmfile.nginx-ingress
# Deploy IDP configuration
- helmfile.idp-roles
- helmfile.teleport-auth
- helmfile.teleport-node
# Deploy Custom Services
- helmfile.vault
- helmfile.mongodb
projects:
globals:
assume_role_name: eg-acme-terraform
availability_zones:
- us-west-2a
- us-west-2b
- us-west-2c
namespace: eg
region: us-west-2
stage: acme
terraform:
account:
account_email: [email protected]
cloudtrail:
depends_on:
- account
vpc:
cidr_block: 10.10.0.0/17
dns:
zone_config:
- subdomain: acme
zone_name: example.sh
efs: {}
eks:
# Note: the `role_arn` attribute is dynamically provided through the tenant EKS project
map_additional_iam_roles:
- username: acme-admin
groups:
- idp:kube-admin
- username: acme-terraform
groups:
- system:masters
- username: acme-helm
groups:
- system:masters
- username: acme-ops
groups:
- idp:ops
- username: acme-observer
groups:
- idp:observer
Since we’re using YAML, we can use the same configuration with Terraform, Helmfile and Helm. All of them consume it. Then we’re using variant to define the pipelines to bring it all up and package it into a self-contained cli tool.
Oh totally going to think through this. I like the ideas!
I actually designed the big terraform project I first implemented with
plans
-- prod
----- rds-instance-1
-------- override.settings.yml
----- rds-instance-1
--- default.prod.yml
(and and then use terraform remote state EVERYWHERE possible to make passing values between modules trivial)
Ya, so that’s somewhere in between: YAML for configuration and some folder hierarchy
All of the main settings are in yaml and then it allows me to override. Was kinda questioning that as felt like not a “native” but was there so I basically copy and paste a deploy, change the name and have a full rds stack up (using your module + other resources).
I want to improve this and reduce duplication. I’ll definitely be looking at your feedback
So it can be more or less “native”. THe problem with the YAML, is there’s no schema validation.
So what we’re doing is actually taking the values from the YAML config and passing them to the variables in terraform, so we’re still achieving validation.
e.g.
module "eks" {
source = "../../../projects/eks"
# Add other IAM roles and map them to Kubernetes groups here
# <https://kubernetes.io/docs/reference/access-authn-authz/rbac/>
map_additional_iam_roles = local.map_additional_iam_roles
allowed_security_groups = module.config.combined.allowed_security_groups
allowed_cidr_blocks = module.config.combined.allowed_cidr_blocks
apply_config_map_aws_auth = module.config.combined.apply_config_map_aws_auth
cluster_log_retention_period = module.config.combined.cluster_log_retention_period
cluster_endpoint_private_access = module.config.combined.cluster_endpoint_private_access
cluster_endpoint_public_access = module.config.combined.cluster_endpoint_public_access
enable_cluster_autoscaler = module.config.combined.enable_cluster_autoscaler
enabled_cluster_log_types = module.config.combined.enabled_cluster_log_types
desired_size = module.config.combined.desired_size
...
}
I don’t have a lot of collaboration right now on modules. 1 person uses jenkins + homegrown make files, another from laptop and then me with Terraform Cloud remote fully. That’s why I haven’t done a master root repo. I want to help guide towards this but have to figure out the method so when I bring others in it’s clean.
I’m trying to avoid MORE repos because it’s impacting collaboration i think so root plans i want to centralize once I figure out the way to run these.
Very nice. With the new 0.12 validiation features in alpha this should make it even better.
Have you seen this article? https://www.terraform.io/docs/cloud/workspaces/repo-structure.html
Terraform by HashiCorp
I’m using merge to take two lists of locals and get the final setting. Sounds like I need to look at your examples though to better understand. Do you have this content online for or is that client specific
I kind of like their hybrid approach which is somewhere inbetween “poly” and “mono”. Basically, grouping infrastructure into various repos related to some business use-case (e.g. terraform-networking)
And yes I’ve read lots of repo structure. I’ll revisit it again with a fresh take. They don’t tend to do very creative stuff on settings, it’s a lot of repeated code, which I’m trying to avoid where possible. Terraform is great… but hcl2 coming from someone who codes is great until you hit these limits and it feels like I’m doing recursive cte’s again in SQL to get a running total… ugh
Btw, terraform merge on YAML sucks (found out the hardway). It doesn’t do a deep merge.
very aware of that
Lots of pain points on it. I keep my map flat. And didjn’t go to the deep object merge route for sure
That’s also why I was revisiting the concept. If I hit limits, I try to look and see if what I’m doing is idiomatic to the technology, or I’m overcomplicating something that will cause accidental complexity. I’m mixed on yaml basic merging. Was hoping for something like env.auto.tfvars and it just merge stuff automatically
Yup, that’s the only way to avoid it in terraform.
Have you played with the triggers in TF cloud? …where one workspace can trigger another?
Sounds like your tfvars solution might offer me some of what i need. If you have any github repos with this pattern let me know. Appreciate the dialogue for sure
No use case right now.
I’m asking these repeated questions as I’m basically trying to in the next year improve our stance with consistency as a team.
I want 100% remote and regular cicd using terraform, but it’s a long process. Right now everyone is creating modules left and right that do like 1 resource or are wrapped up in massive custom make files. I love scripting but I’m seeing that TF Cloud does force one thing… simplicity. Working properly with this so i setup a team for maybe not the most efficient but the most understandable and easy to sell and show the velocity improvement on is what I’m going to have to go with
This is why terragrunt as much as I really love the concept, I’m not confident it would work on selling those points vs me demoing TF cloud and showing in a few minutes I can have a CICD complete pipeline up.. even if I want matrix builds in azure devops or something like that
anyway good stuff, any links welcome. talk to you later. thanks for the great feedback
Yup, more or less mutually exclusive
Terraform Cloud is pulling you deeper into the HashiCorp ecosystem (not a bad thing, just something to acknowledge)
Like using Terragrunt is pulling you closer in the gruntworks direction. The terragrunt approach is effective, but vendor locks, breaking compatibility. Also, doesn’t address how things outside of terraform get automated.
Yeah. The alternative to hashcorp is homegrown/pipelines. I think that maybe something like Azure DevOps (we migrated to), would be great, running InvokeBuild/variant/etc. Something like that.
The key is I am at ground zero here. The only other person who implemented anything CICD with this did a big terraform + makefiles + jenkins thing.
the “terralith”
So for me, I’m trying to make this accessible and quick to iterate on. Selling azure pipelines/builds for a team that has only done big project jenkins, not spun up quick jobs , i think it would be easier
I think terraform cloud has a lot to fix, needs groupings, shared secrets and more. But not sure I can see the other solutions as easier for adoption, only more technical knowledge and support required. If you think otherwise all for hearing about other options! (we aren’t using k8s, just ec2/ecs)
Info Following up on #10, this PR uses that fork and then applies the most recent requirement: Updates the type for parameter_write variable so terraform can run without errors.
@Matt Gowie when you have a chance to go over that, let me know if anything doesn’t make sense. i can probably even find time to hop on a google meet and work through any new issues you find (who doesn’t have extra time for virtual meetings these days?)…i think it really is just about getting the test harness/dependencies happy.
@Mike Hoskins Saw your comments this morning — Great stuff man, much appreciated! I will definitely dig into that today. On my list after I wrap up a few small client tasks.
cool sorry, don’t mean to rush…there is no rush. just want to say i’m happy to collaborate on it. some times little assumptions creep in
No problem at all. And I’ll definitely reach out if I have an issue. Seems you dug further than I was willing to at the time
2020-04-22
Hey folks — I posted this over the weekend. It (and the accompanying module) might be of interest to some folks who are running a Bastion host as part of their stack: https://medium.com/masterpoint/time-to-ditch-your-bastion-host-f22cc782de71
Terraform Module: https://github.com/masterpointio/terraform-aws-ssm-agent (Shout out to CP in there for using a few of their modules as well )
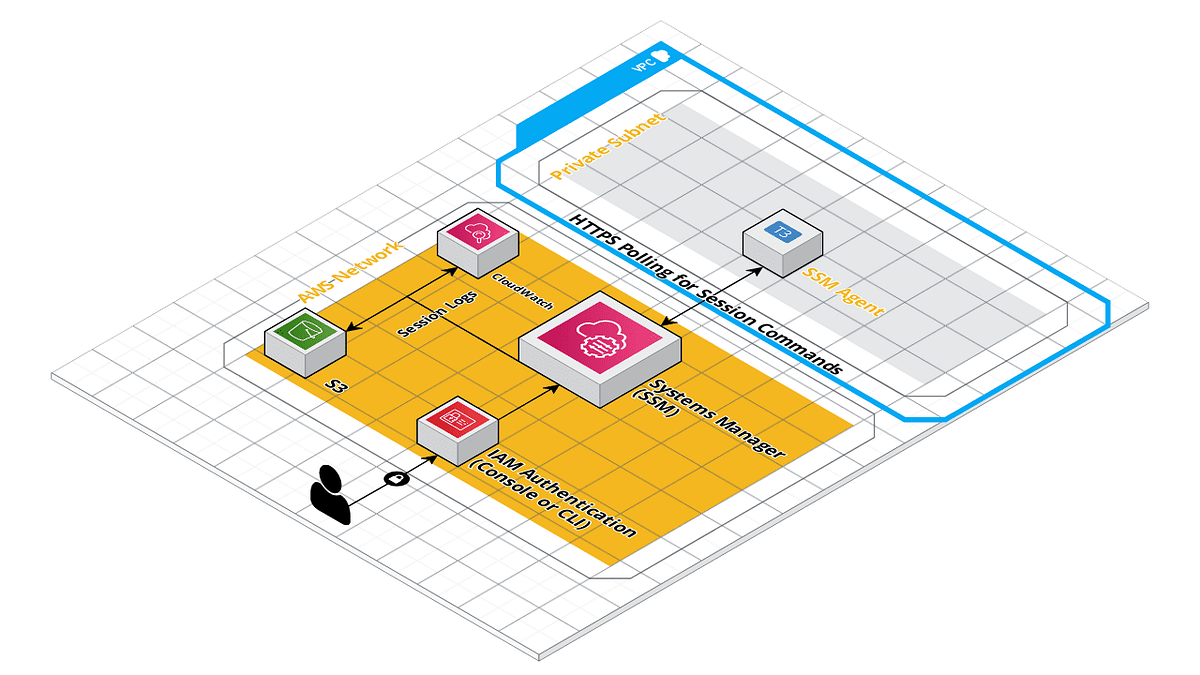
Time to ditch your Bastion host and change over to using AWS SSM Session Manager
Terraform module to create an autoscaled SSM Agent instance. - masterpointio/terraform-aws-ssm-agent
interesting aproach
Time to ditch your Bastion host and change over to using AWS SSM Session Manager
Terraform module to create an autoscaled SSM Agent instance. - masterpointio/terraform-aws-ssm-agent
so you are using SSM agent for one instance to access other instances ?
@jose.amengual I personally use this module to get into private networks and get access to the Database for running ad-hoc SQL commands or migrations. Access to other instances should likely be done through SSM as well if you have more instances. I’ve used this approach primarily on ECS Fargate projects where I don’t have many actual EC2 instances.
ahhh I see ok, make sense
I will recommend if I can, that you add the options for bucket login and kms
Bucket Login? Can you expand on that?
KMS for encrypting S3 logs?
I haven’t implemented S3 / CloudWatch logging yet. It’s top of my todo list for the coming day or two when I get a moment.
you can save sessions logs of session manager in S3
and if you enable kms you encrypt the connection using kms
Ahah you meant bucket logging not login — Yeah top of my todo list for that module.
KMS encrypt the Session Manager session or KMS encrypt the S3 Logs?
I have a module that does all this and I was asking permission to opensource it
the session manager session
Huh I didn’t know that was not encrypted. It’s all over HTTPS / TLS is it not? Is it further encryption on top of that?
correct
there is some reasons not to trust much on TLS
Got it, cool — I’ll add that to my list. Thanks for the suggestion!
np
AWS Bastion server which can reside in the private subnet utilizing Systems Manager Sessions - Flaconi/terraform-aws-bastion-ssm-iam
@maarten Oof
@Matt Gowie take all you need
I found out that for tcp forwarding you actually do need ssh forwarding as TCP forwarding by the session manager isn’t always working properly.
Hahah just wish I had known about it prior to building. Part of the problem of the Terraform ecosystem: most projects are not on the hashicorp registry and it’s common for multiple projects to do the same thing.
 2
2Hashicorp is not doing much to make the registry any better.. For that reason I skipped it.
I’ve always just accepted that folks don’t use the registry, but what’re the pitfalls that you avoided it for?
Search order has sucked for a long while, don’t know how that is now. You can’t order on anything, you can’t filter on 0.11 0.12
They made it once, and left it like it is
Gotcha. Yeah, that’s a bummer.
still can’t search using stars or last updated but you can search for those things using github search
for instance, you can search for all terraform aws bastion repos by stars and see last updated easily using github
https://github.com/search?o=desc&q=terraform+aws+bastion&s=stars&type=Repositories
GitHub is where people build software. More than 40 million people use GitHub to discover, fork, and contribute to over 100 million projects.
@johncblandii has joined the channel
Guys, for s3 and static website if I remember well if we want to use custom domain we need to name s3 bucket same as domain name? Is it possible to name it differently, and to serve assets from there only with custom domain, together with cloudfront, and without any webserver?
you can create a regular bucket (not a website) and add a CloudFront distribution in front of it
will be able to serve any files by their exact path/name
will not be able to automatically serve 404 and error pages, nor the root path / (will have to specify the exact file name. e.g. /index.html)
Thanks a lot, Thats exactly what I am looking for
2020-04-23
Hi, we have some huge s3 bucket copies that happen every night between accounts and is run from jenkins as a cron and I was wondering if there is a way to do this in aws where is automated and runs on a schedule
maybe SSM, or something like that
but it need to be schedule
is a mix between AWK, sed grep and other tools that then endup in a aws s3 sync command
data parsing job mostly
cron cloudwatch and a lambda could probably do it
batch job might work too
possibly emr
lambda timeouts will getcha
we though on that
but the job could take like 4 hours to do or all night
we thought about doing a timed autoscale group to do that
and SSM document or something
lambda timeouts are now at 15min now
one way to get around them is to recursively call itself at the end of the timeout but its a bit tricky to do
perhaps try the ssm method @jose.amengual. would love to see a blog post on comparing the different methods including costs
cloudwatch event with scheduled trigger to run a codebuild job. pretty much the easiest way to run admin-like tasks where you’re basically just running shell commands
codebuild job can run up to 8 hours
Describes the service quotas in AWS CodeBuild.
intertesting
8 hours hard limit ?
personally i’ve never had to ask for an increase, so no idea. don’t have any jobs that take more than an hour
but if it’s an s3 copy, you can partition the copy into multiple jobs by the s3 key/prefix and run each in parallel
one codebuild job, started multiple times with each run passing an env to control the prefix the job is responsible for
that is a good idea
if you are more comfortable with lambda, same idea would work there, just need more shards to stay in the 15min timeout. or get a little fancier with a step function to list the bucket first, put the list of object in a queue, and let lambdas scale out as needed to pull a file from the queue and copy it. i think this similar to the aws support article
oh, nope, that article is basically one of the jokes about aws solutions overcomplicating everything
we do use step function in lambda for that resons
Maybe AWS Data Pipeline?
I think is a bit expensive
I was going to suggest a Scheduled Fargate Task, but after thinking about it… creating a docker image, ECR, task def, and schedule event seems a lot more complicated than a simple CodeBuild job.
ECS is just nuts for this, we use it a lot and requires so much cruft
Not saying it’s better, but dang i thought this tool was awesome! Better to use native services typically but might also exam this. Cloud to cloud support and found it was great. It helped me personally merge 1tb in duplicate google drive folders and supports s3 . Just a thought
Synchronization Moving data between two cloud providers can be painful, and require more provider scripting if doing api calls. For this, you can benefit from a tool that abstracts the calls into a seamless synchronization tool. I’ve used RClone before when needing to deduplicate several terabytes of data in my own Google Drive, so I figured I’d see if it could help me sync up 25GB of json files from Azure to S3.
mmmm we have like 10 TB of data to parse
and then copy
cool. I’m sure glue or something is better, just wanted to mention as i think it does incremental sync
sounds like athena/glue/etc might give you massive improvements with parallel processing if possible. I didn’t get entire thread, just thought I’d mention. I like what I’ve seen in athena for sure
we tried athena, glue…and something else
at the end, we ended up with this because it was the fastest and cheapest
it is crazy how many options there is and and AWK program ends being the fastest
in comparison to running a cluster of things to make it faster
thanks for the suggestions
What about SRR or CRR, a feature of S3? https://docs.aws.amazon.com/AmazonS3/latest/dev/replication.html
Set up and configure replication to allow automatic, asynchronous copying of objects across Amazon S3 buckets.
we wanted to use replication but we use vpc endpoints
and without vpc endpoints operations that write to that bucket are pretty slow
you can’t have replication with vpc endpoints enabled
mmm I’m reading that document again and it looks like now you can have replication with vpc endpoints enabled ?
Is anyone aware of a way to track unused IP address’ by subnet?
aws ec2 describe-subnets --query 'Subnets[0].AvailableIpAddressCount'
Subnets have AvailableIpAddressCount field which tells you how many IPs are available.
2020-04-24
2020-04-25
2020-04-26
anyone know if there is a public repository of common useful iam policies ?
Commenting to follow along here — I’m definitely interested in the answer to this question. I haven’t seen one and I can see that it wouldn’t be a very glamorous open source project to build, but it would be very nice.
Seems like gruntworks offers it as part of their service https://github.com/gruntwork-io/module-security-public/tree/master/modules/iam-policies
but yes, something open source would be nice! does seem like every org has to reinvent this wheel
The public documentation for the gruntwork-io/module-security repo, which contains packages for setting up best practices for managing secrets, credentials, and servers - gruntwork-io/module-securi…
I’ve been wanting to do this for a long time as well. Sigh.
also how do your companies allow devs access to resources ? we use hologram at my company to give ppl creds. engineers use the engineer role and sres use the sre role. currently iam is whitelist only and usually when engineers hit a wall, they pr into our terraform module, we review, merge, and apply the change. is there a better way to manage creds for engineers ?
Hadn’t heard of hologram, linking for others’ reference… https://github.com/AdRoll/hologram
Easy, painless AWS credentials on developer laptops. - AdRoll/hologram
We do a couple different things, depending on the environment… In pure dev spaces, we use more of a blacklist approach… Provisioning a permissive role that allows most anything, with explicit denies for resources we provision into the account for security/audit/networking/access purposes. In spaces more like prod, roles are whitelists using prs to manage updates similar to what you describe
we use Service policies in AWS organizations to limit what other people/teams can do in their AWS accounts
in our case we use multiple accounts per team
then we have specific OUs per accounts
from the “manager” account we have different policies per account
like, we do not allow user creation in any account
etc
Cloudonaut guys just talked about Organizations / Service policies in one of their recent podcasts. They’re not fans, but I can see that being one of the safest routes for an enterprise org.
Personally, I think I’d favor Loren’s approach for Dev + RB’s PR into terraform module for higher environments.

Show cloudonaut, Ep #17 AWS Account Structure - Apr 8, 2020
We use Okta for identity, and gimme-aws-creds to authenticate and assume a role in the AWS account. Similar to what you described we have terraformed IAM policies that restrict actions per role, per environment. The dev environment is much more “do what you want” with some blacklisting of certain Delete and all IAM actions.
A CLI that utilizes Okta IdP via SAML to acquire temporary AWS credentials - Nike-Inc/gimme-aws-creds
thinks of that nature,,,,
2020-04-27
hi everyone, have you find any proper way to manage the custom index mapping on AWS Elastic Search ? I think the most easiest way is store all those JSON template under your source control, every time when we need to manipulate something, just pick them up and using CURL. But you know we are all failing in CI/CD world. Therefore I am still finding any proper way to handle those stuffs under proper pipeline which provide us more robust to handle. Am I correct or just over engineering ?
It bugs me too. There is an unofficial Terraform provider but it requires a network route which is a bit annoying if you’re running ES inside a VPC.
But if you can curl it then networking is fine, so the provider might suit you.
Hi everyone, how could a “normal end user” access files on s3 using SAML authentication?
What do you mean by a normal end user ?
we have done that creating pre-signed URLs and or Cookies
But you need AWS CloudFront for that
If you need SAML authentication in front then you’d like need to build a small service to do the auth and then return back a pre-signed S3 URL to the user.
Right… that would be the solution… .’cause there is no AWS Out of the Box ready service for that
Use can do SAML to AWS roles if you are managing AWS access that way
I thought of an normal end user as someone with less IT skills, someone who just uses an app, logs in, and views the file without dealing with pre-signed urls, AWS console, roles, …
@github140 — The pre-signed URLs would just be a URL or link to them. You can make it completely transparent to the user. They would need to be authenticated into your service (SAML or other methods) which provides the pre-signed URL but they wouldn’t need access to the console or roles.
2020-04-28
is there a way within elasticbeanstalk to configure the application load balancer for authentication via cognito user pool? or do i have to configure the ALB outside of EB?
Yeah you need to go to the ALB console in the EC2 section. They seem to have simplified the config within the EB config. Of course, using some kind of automation would be best.
i’m looking for a way but I don’t see one on the load balancer config page in elasticbeanstalk
RDS question: I want to spin up an RDS read replica that will generally have pretty low read iops (1,000~2,000). However, during deployment time, I will be running a bunch of concurrent backups against the read replica, causing the read iops to spike to upwards of 10,000 during usually a window of less than an hour. What should I provision my read replica as? I’m thinking gp2 with a high storage size (> 1TB).
What I’m kind of confused about is I currently have a 500GB gp2 RDS instance which spikes to 8,000~10,000 read iops during deployment time but the burst balance is still pretty high post deployment (roughly low 90s). But documentation says the maximum iops will be 3,000. Anyone familiar w/ RDS iops credits can explain? https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/CHAP_Storage.html
Shows the different storage types available for a DB instance on Amazon RDS.
I think the “Maximum Burst Duration at 3,000 IOPS” is just an example of the formula beneath it in the docs
Shows the different storage types available for a DB instance on Amazon RDS.
Like you can burst greater than 3K, but your burst duration will be shorter
Did you calculate how long your credit balance will last post deployment at __ IOPS?
Baseline I/O performance for General Purpose SSD storage is 3 IOPS for each GiB, with a minimum of 100 IOPS. This relationship means that larger volumes have better performance. For example, baseline performance for a 100-GiB volume is 300 IOPS. Baseline performance for a 1-TiB volume is 3,000 IOPS. And baseline performance for a 5.34-TiB volume is 16,000 IOPS.
I’m curious if performance is throttled at higher than 3,000 iops? My credit balance is extremely high still (>90/100) post deployment and read iops in general is pretty low besides during deployment time.
How I read https://aws.amazon.com/ebs/features/ is this: Volumes smaller than 1TB can burst to 3000 iops. Volumes larger than that can burst 16.000 iops. And base iops you figured that one out.
@maarten that’s how i read it. But my rds instance right now is 500GB and its def bursting past 3000 read iops
Maybe you’re getting lucky like in this post: https://serverfault.com/questions/924709/amazon-rds-why-do-i-get-more-iops-than-i-have-provisioned
Even though you’re not on PIOPS, maybe you’re on a quiet host and they’re letting you abuse it until you get more neighbors
interesting, i wasnt aware that was a thing!
2020-04-29
Hey, I’m migrating one application which has a long running import task triggered by one of our views from beanstalk to fargate. this view when called enables scale in protection for the instance that runs the import task. I went through the logs available at https://docs.aws.amazon.com/AmazonECS/latest/developerguide/cluster-auto-scaling.html but I can’t find anything useful related to fargate. Has anyone solved a similar issue? Also rewriting it in a way that it can be triggered via run-task is currently heavily time constrained and I don’t want to do it.
Amazon ECS cluster auto scaling enables you to have more control over how you scale tasks within a cluster. Each cluster has one or more capacity providers and an optional default capacity provider strategy. The capacity providers determine the infrastructure to use for the tasks, and the capacity provider strategy determines how the tasks are spread across the capacity providers. When you run a task or create a service, you may either use the cluster’s default capacity provider strategy or specify a capacity provider strategy that overrides the cluster’s default strategy. For more information about cluster capacity providers, see
Have any using aws sso through cli? if so, how the switch b/w accounts happens?
2020-04-30
Trying to create S3 bucket with state using terraform, and create dynamodb with some tables. Works fine on one region, got this error trying on another one. What should I do next? Google alot.
Error: error using credentials to get account ID: error calling sts:GetCallerIdentity: InvalidClientTokenId: The security token included in the request is invalid.
How are you authenticating to AWS? Does this show anything meaningful?
aws sts get-caller-identity
Thanks, now I get it, I needed to export profile to work properly
export AWS_PROFILE=terraform-user
 2
2hi
just a quick one how can i sync s3 subdirectories like that:
aws s3 sync –delete <s3://bucket1/subdir1/*> s3:/bucket2/subdir2/
grr took a long time to figure it out
https://github.com/aws/containers-roadmap/issues/487#issuecomment-622135394
AWS actually shipped 1.16
Tell us about your request Support for Kubernetes 1.16 Changelog Release Announcement Which service(s) is this request for? EKS Tell us about the problem you're trying to solve. What are you tr…
is it just me or are they getting faster?
They are