#aws (2020-05)
 Discussion related to Amazon Web Services (AWS)
Discussion related to Amazon Web Services (AWS)
Discussion related to Amazon Web Services (AWS)
Archive: https://archive.sweetops.com/aws/
2020-05-01
Yes, they said that the 1.15 slowness was something exceptional as they we’re refining processes for faster support of future versions of kubernetes
Hi, I’d like to provide a file in S3 to users in an easy way. This means no additional client software, no access key overhead. Therefore I thought about loading it to SharePoint online as this is rather the corporate platform including proper authentication. Unfortunately I didn’t find a connector yet. Anybody had a comparable challenge, solution, thoughts to share?
RDS question, I’m seeing this when attempting to create a slot in Postgres:
ERROR: must be superuser or replication role to use replication slots
If I remember correctly, RDS doesn’t actually give real superuser privileges. It’s a big drawback. Let me look up a link for you.
I have an AWS EC2 instance connecting to an RDS instance (Postgresql). When I created the RDS instance, I told it the DB root’s username was: my_user1 and the password was password1. Now I’m attem…
lol, yeah
I ended up needing/creating a logical replication slot
Cool — Glad you figured it out. Similar thing tripped me up a couple months back and I was pretty surprised by that one.
It’s funny, I’ve been using AWS for years. . . so many rabbit holes
Yeah — Learn something new all the time haha.
However. . . I am authenticated as the superuser
AWS has launched new Cert badges https://www.youracclaim.com/earner/earned
Acclaim is an enterprise-class Open Badge platform with one goal: connect individuals with better jobs. We partner with academic institutions, credentialing organizations and professional associations to translate learning outcomes into web-enabled credentials that are seamlessly validated, managed and shared through Acclaim.
2020-05-03
guys what do you recommed to hold Kubernetes Secrets on Github ? Has anyone used SealedSecrets of Bitnami ?
Why do they need to be on Github ?
where do you store them
i need best practices
SSM or Vault ?
• You can store them in k8s secrets directly.
• You can store them in your pipeline directly and have k8s secrets populated from there
• You can use any other secret manager like vault & ssm together with the pipeline to populate the secrets
• You can use ssm or vault directly from the container or container helper
i am doing the second one but i need to secure it more and also i need to make it versioned so i need some sort of SCM capability
are you only using it for passwords or all kinds of config items ?
only password
Do you really need SCM on a password which you probably have stored somewhere else already ?
Hi, do you use Helm to deploy? Helm secrets plugin can help to encrypt secrect information and you can commit encrypted file into git. And also Decrypt action will be invoke when you deply via helm
Maarteen for GitOps stuff
A helm plugin that help manage secrets with Git workflow and store them anywhere - zendesk/helm-secrets

This is a living document that is meant to address the most frequently asked questions about GitOps. What you see today will evolve as we all learn more together. Contact us if you have any comments or questions you’d like to see answered on this page.
Sealed-secrets solves the following problem: “I can manage all of my Kubernetes configs in Git, except Secrets.” Sealed Secrets is a Kubernetes Custom Resource Definition Controller that lets you to store sensitive information (aka secrets) in Git.
I never use Sealed-secrets, but I believe the concept is very similar as other secrets management in version control
Currently i use KMS to encrypt my passwords etc and put the output string in terraform.tfvars file
I want something better
I randomly generate a pass, encrpyt it via KMS put it on terraform.tfvars (as encrypted output of KMS) and re-read and decrypt it to create kubernetes Secrets (which is not encrypted but only base64 decoded)
Maybe i can talk with developers so they can develop the code to use injected variables with AWS KMS encrpyted instead of using it plaintext
A pattern/workflow I used is this; have Terraform create a random password. Use that password to set the DB pw, store the password in SSM for later use by application or deployment.
Implemented SealedSecret it is very easy to install/maintain also AWS recently published a blog for that https://aws.amazon.com/blogs/opensource/managing-secrets-deployment-in-kubernetes-using-sealed-secrets/

Kubernetes is an open source system for automating the deployment, scaling, and management of containerized applications. It is especially suitable for building and deploying cloud-native applications on a massive scale, leveraging the elasticity of the cloud. Amazon Elastic Kubernetes Service (Amazon EKS) is a managed service for running a production-grade, highly available Kubernetes cluster on […]
Hi All, I am trying to figure how to get cloud front working with my elastic beanstalk app, i have used this terraform module https://github.com/cloudposse/terraform-aws-elastic-beanstalk-environment to setup my beanstalk app. I went for nat instance instead of nat gateway for cost reasons, and i have 2 instances running. My domain is managed as part of Gsuite, whilst i have permission to add a cname entry or something i cant do much more. I have tried to manually setup cloud front and i selected the origin domain to be the load balancer resource in the drop down. apart from that most of the page i left as defaults except whitelisting one cookie. When i try to hit the url generated for cloud front i keep getting 502 error wasnt able to connect to origin. My ssl certificate for my domain are managed by AWS ACM but my dns is managed by Gsuite. From what i understand i will eventually have to update my dns to point to cloudfront instead of the load balancer as it is now, but before i do that i want to make sure the cloudfront url is correctly configured
Terraform module to provision an AWS Elastic Beanstalk Environment - cloudposse/terraform-aws-elastic-beanstalk-environment
is your app running OK from the Beanstalk (not CloudFront) URL (e.g. `myapp.us-east-1.elasticbeanstalk.com) ?
Terraform module to provision an AWS Elastic Beanstalk Environment - cloudposse/terraform-aws-elastic-beanstalk-environment
I managed to get it working, I had to create a ACM cert in Virginia in order for it to allow me to use my own domain. My load balancer was rejecting the Https request because the referrer was not correct I think so the Https negotiation was failing.
Now I just need to figure out how to terraform it
2020-05-04
2020-05-05
is it possible to specify specific data center using Cloudformation (for example, I want to spin up subnets on the same datacenter with another account/subnets). Since the us-east-1a might not be the same physical location for me than someone else, how can this be done via Cloudformation?
noticed some of our devs were using an ELB for just a health check so the ELB itself has 0 requests. I understand that target groups have a health check and ECS can leverage the HEALTHCHECK argument in dockerfiles.
how do people here do health checks for applications without an ELB ? do you use a target group ? or do ecs / fargate with a healthcheck arg in the container ?
if target group, can this be used without an ALB ?
also wondering if anyone has used route53’s health checks in lieu of the above ?
I take it these are applications that don’t serve web traffic then? They’re some sort of data/job processors?
yes for the most part if I understand those services correctly
having an ELB do nothing but perform healthchecks is a bit expensive for what its doing, granted its like $20/month with no traffic but still. (And a bit absurd)
agreed!
Probably best to have a conversation with them and figure what they’re trying to do and why …
@RB I use the healthcheck configuration in ECS task definitions on most projects and wire it up to a script that either checks the PID of the primary process or if it’s a web server then executes a curl against that process.
That’s if you need customization beyond Docker’s HEALTHCHECK. I personally haven’t used the Docker healthcheck before.
Task definitions are split into separate parts: the task family, the IAM task role, the network mode, container definitions, volumes, task placement constraints, and launch types. The family and container definitions are required in a task definition, while task role, network mode, volumes, task placement constraints, and launch type are optional.
isnt it the same thing ?
The container health check command and associated configuration parameters for the container. This parameter maps to HealthCheck in the Create a container section of the Docker Remote API and the HEALTHCHECK parameter of docker run
@RB Ah it is the same. The Task Def just provides a wrapper around those same configuration arguments. I hadn’t looked deep enough at the Dockerfile HEALTHCHECK ref or the Docker run ref. Didn’t know it provided that level of granularity, so I though AWS was providing added configuration as a benefit.
TIL
2020-05-06
Great summary of aws networking… Breathe it in, we’re all network engineers in the cloud… https://blog.ipspace.net/2020/05/aws-networking-101.html
There was an obvious invisible elephant in the virtual Cloud Field Day 7 (CFD7v) event I attended in late April 2020. Most everyone was talking about AWS, how their stuff runs on AWS, how it integrates with AWS, or how it will help others leapfrog AWS (yeah, sure…). Although you REALLY SHOULD watch my AWS Networking webinar (or something equivalent) to understand what problems vendors like VMWare or Pensando are facing or solving, I’m pretty sure a lot of people think they can get away with CliffsNotes version of it, so here they are ;)
anyone know of a terraform module for opengrok or a similar code search app that can be run in aws ?
2020-05-07
aws global accelerator is the bees knees
@Zach would you say its pretty cheap?
yah, if you aren’t pushing boatloads of data out
its negligible
we used it so that we could have a static IP on our entry ALB, and to move them private at the same time
we’re getting charged roughly ~400$/mo for ALB bandwidth
i am excited about moving the ALB to private and we will benefit from the static ip as well
Ah, you are in a different tier of traffic than we are then haha
i assume global accelerator is a subset of that?
so we’ll probably pay maybe $600/mo
oh, yah its on top of the ALB costs.
@Zach do u also use a CDN?
I’m waiting on some IP whitelisting for using it. But loving the idea.
Hi, I am little bit confused regarding AWS Secrets Manager. If I have lets say one AWS Secret with 4 key/value pairs, is that considered as one secret or 4 secrets?
one!
You can do single value secret or you can store multiple. For instance I did RDP users secret and setup multiple users on local systems, while my rds logic uses 1 for admin. It is a little clunky getting the values out as ends up being key = username sorta from what I remember. Basically was like: $secret.MyName = $secret.MyName.Value or something like that. Found it confusing at first and later I tried to avoid embedded multiple and instead tried to stick with single value when possible
My understating is that should be one secret, but who knows
2020-05-08
is there a way to do a rolling deploy in ECS without updating the task definition ?
no if you want to tag the images
if you are doing “latest” then you could
yes, let’s assume the docker image stays the same
so the image doesnt need to change in the task definition
then you can
how ?
you set min to 50% and max to like 200%
you make sure you have enough resources to run more than one task
but this is not blue green
so you will have old/new containers running at the same time
while all get updated
i was just having an issue finding this in the cli
one sec
i think i found it //stackoverflow.com/a/50497611/2965993>
I am trying to restart an AWS service (basically stop and start all tasks within the service) without making any changes to the task definition. The reason for this is because the image has the la…
im dumb for not finding that earlier
does that command align with yours @jose.amengual
we do thi s:
aws ecs update-service --cluster ${clusterName} --service ${serviceName} --force-new-deployment
brilliant, thank you very much!
lol is the same command
the key is on the deployment config
not the command
looks like this can be even easier using a task set but currently this is not in terraform yet
Community Note Please vote on this issue by adding a reaction to the original issue to help the community and maintainers prioritize this request Please do not leave "+1" or "me to…
correct
2020-05-09

It is my great pleasure to tell you about a price reduction for Amazon Elastic Compute Cloud (EC2) customers who plan to use, Standard Reserved Instances or EC2 Instance Saving Plans. The price changes are already in effect, and so anyone buying news RIs or a new EC2 Instance Saving Plan will be able to […]
2020-05-10

He makes some decent points against due to his own experience, but it seems in a number of those cases he should have RTFM and done some service comparison before jumping head first into those services.
The lambda one is pretty funny — sounds like the worst nightmare of them all if that’s the implementation path their team went down.
2020-05-11
aws-okta is on a hiatus? Someone picking that up? … or did you all move on to more hipster solutions? I think aws-okta at least has very good usability… Plus, I did this to get rid of some annoying obstacles: https://github.com/frimik/aws-okta-tmux
Wrapper that makes aws-okta cred-process communicate with the user via tmux panes. - frimik/aws-okta-tmux
Did not seem like anyone was going to pick up aws-okta maintenance, so we moved to gimme-aws-creds (maintained by Nike)
Wrapper that makes aws-okta cred-process communicate with the user via tmux panes. - frimik/aws-okta-tmux
i’ve really been impressed by aws-okta-processor, https://github.com/godaddy/aws-okta-processor/
Okta credential processor for AWS CLI. Contribute to godaddy/aws-okta-processor development by creating an account on GitHub.
how do these methods work for delivering aws creds ?
you configure Okta as a SAML provider to AWS, and these allow you to assume a role in the account. It then passes back a temorary credential pair
and if they do it right, they refresh the aws temporary cred automatically (until your Okta session expires, then it re-prompts)
^ we haven’t gotten that part to work correctly
try aws-okta-processor
I’ve only just managed to get everyone switched to gimme-aws … I might get tarred and feathered if I make anyone swap again
it’s the only tool i’ve used that gets caching of both aws and okta sessions right, and works with mfa, and works with credential_process, and manages stdout/stderr well enough to work with pretty much any tool built for any sdk
plus the maintainers have so far been super responsive and open to prs
well, it’s your box, authenticate however you like if they keep using gimme-aws-creds that’s fine. you can enjoy the goodness of aws-okta-processor
is anyone here using https://docs.aws.amazon.com/secretsmanager/latest/userguide/rotating-secrets-one-user-one-password.html for RDS aurora ?
Automatically rotate your secrets by configuring Lambda functions invoked automatically on a schedule that you define. You can use this scenario for authentication systems that allow only changing the password. For a list of the different available scenarios, see .
I wonder how effective it is? there seems to be quite a bit of config + lambda to just enable this feature that when I compare this to Hashicorp Vault seems more convoluted
Automatically rotate your secrets by configuring Lambda functions invoked automatically on a schedule that you define. You can use this scenario for authentication systems that allow only changing the password. For a list of the different available scenarios, see .
@jose.amengual what will you be using it for ?
The AWS counterpart of Vault would be SSM by the way, not the secret manager. For Aurora you can use this: https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/UsingWithRDS.IAMDBAuth.html
Authenticate to your DB instance or cluster using IAM database authentication.
I’m talking about this : https://docs.aws.amazon.com/secretsmanager/latest/userguide/rotating-secrets-rds.html
Automatically rotate your Amazon RDS database secrets by using Lambda functions provided by Secrets Manager invoked automatically on a defined schedule.
I want to use the automatic secret rotation feature for programatic access
~I think IAM Auth is perfect as alternative there, unless you expect 200 new connections per second.~
we are going to use IAM auth for users
but for apps we want to rotate the secret
I don’t know if IAM auth is recommended for apps
I’m thinking it might be a tad slower with connection creation, so I’m not sure. I take it back.
We recommend the following when using the MySQL engine:
Use IAM database authentication as a mechanism for temporary, personal access to databases.
Use IAM database authentication only for workloads that can be easily retried.
Don't use IAM database authentication if your application requires more than 200 new connections per second.
MySQL Limitations for IAM Database Authentication
so for users is fine
but apps maybe not
Is there a iam policy example that deny whole subnet and just allow one ip from that subnet?
@raghu What’s the goal you’re trying to accomplish?
Typically IAM Policies do not involve network whitelisting / blacklist. You can restrict certain actions only be allowed if they’re coming from a certain IP using the SourceIP Condition, but that is pretty uncommon.
If you’re trying to do network related whitelisting / blacklisting for requests in-coming to your application then there are typically 3 places you should look (in order of preference likely):
- Security Group
- VPC NACL
- WAF Rules
Use this IAM policy to deny access to AWS based on the source IP.
Oops, I mean, In bucket policy
This is likely what you’re looking for then: https://aws.amazon.com/premiumsupport/knowledge-center/block-s3-traffic-vpc-ip/
Absolutely, but i have to add one more condition on top of that.Thankyou @Matt Gowie
2020-05-12
Hello, It is a bit K8S/AWSEKS related so i don’t know where to post Anyway is there a way to make a Pod to get ingress(inbound) traffic only from ALB Ingress ? As ALB Ingress will change Source IP address i can still get traffic to this pod but simply will deny access from other Pods that is living on same namespace.
I am interested if you are able to do this… I have been wondering the same thing. I am not setting things up yet for a new project, but was wondering the same things as I was laying out the architecture
Still no luck
The only thing comes to my mind is seperating namespaces
And installing 1 ingress for each ns
And seperate ns communication with networkpolicy
Hopefully someone has a simpler answer.
Also that means a seperate external-dns in each ns as external-dns can only wathc 1 ns for each deployment
@chris so far nothing
The only answer is istio
Thanks for the update
interesting that one cannot remove the Server header from cloudfront… but at least it no longer will show AmazonS3
https://stackoverflow.com/questions/56710538/cloudfront-and-lambdaedge-remove-response-header
I am trying to remove some headers from a Cloudfront response using Lambda@Edge on the ViewerResponse event. The origin is an S3 bucket. I have been successful to change the header like this: exp…
2020-05-13
Hello,
I am a bit confused around the usage of --queue-url and --endpoint-url when a VPC Interface endpoint is created. One of the three private DNS is exactly the same as the context of the --queue-url and if I do a dig it indeed resolves to a private IP. What is the purpose of the other two DNSes with vpce-* in their names and when should they be used? One of them seems region specific while the other seems AZ specific.
found my answer @ https://docs.aws.amazon.com/vpc/latest/userguide/vpce-interface.html
An interface VPC endpoint (interface endpoint) enables you to connect to services powered by AWS PrivateLink. These services include some AWS services, services hosted by other AWS customers and Partners in their own VPCs (referred to as endpoint services
Hey guys, total AWS noob here
I have a subdomain attached to a Route53 privately hosted zone
It’s supposed to load a webpage, and I want to be able to give access to certain people. Preferably with a username / password, though just whitelisting individual IP addresses would be doable
What strategy should I use to go about this?
it depends on the target of your subdomain – are you hosting your content in S3, on an EC2, in Fargate?
@Darren Cunningham thanks for responding! I’m using EC2
I was able to get my subdomain to work on a public hosted zone, but I want to restrict access to it. So I thought that moving to a private hosted zone was the move, and idk where to go from here
private hosted zone juts means that your zone would only resolve within the VPC – that’s not what you want
@Darren Cunningham use a security group , restrict access to port 443 or 80 , whatever port the webserver is running on
For username and password, you might use ngnix as proxy , whitelist the IPs of the users in the security group
@Joey — Sounds like a combo of putting Basic Auth in front of your app + updating the Security Group inbound rules for your Application’s SG would be what you want.
Is it possible to do this without updating the app?
Would the security group be enough?
basic auth would require updating the app
security group is “enough” if you’re ok with it
Also, how do I find the security group? Is it tied to the VPC?
yeah I’m okay with just having the security group to allow it
Your security group is tied to your EC2 instance.
it would be easier to find by going to the Ec2 and seeing which SGs are allocated specifically to it
if you go to VPC you’re going to find ALL of them in your VPC/Account
And @Darren Cunningham is correct — you don’t want a private hosted zone. That means your DNS entry for your site will only be visible inside your VPC, which means the public won’t be able to access it. You want a public hosted zone.
@Matt Gowie okay, but is there a way for me to just choose who accesses the VPC?
The VPC as a whole? You can do that via your VPC’s NACL (Network Access Control Lists) but you likely just want to do that via Security Groups.
Yeah right now the NACL says “All Traffic” but I still can’t load the domain on my computer
so maybe it is best that I just make it a public hosted zone with a security group, thanks
Yeah, go with a public hosted zone and check your security group’s inbound rules. Likely your NACL is not the issue. The default rules are typically user friendly.
When I do this, would I be able to have the security groups recognize a username/password? Or do I just simply whitelist specific IP addresses?
Security Groups purely deal with the network so they cannot be configured to help with username/pass. Username / password needs to be a layer 7 level so on a proxy or application layer.
@Matt Gowie so I’ve been trying a lot of combinations of security groups the past 2 hours.
This works:
Type - All Traffic
Protocol - All
Port range - All
Destination - 0.0.0.0/0
This doesn’t work:
Type - All Traffic
Protocol - All
Port range - All
Destination - <my ip address>/32
& I don’t know why
(for outbound rules)
I’m ready to give up and just create security in the app. Do you have any idea why inserting my personal IP address doesn’t seem to work though?
The second one should work. How are you finding your IP?
I select “My IP” from the dropdown
Ah. Interesting. And your request times out?
granted, this is an ELB security group created from Kubernetes
if that at all makes a difference
Ah if you’re in K8s land then I’m unsure.
gotcha I’ll post on that channel
thanks for the help!
Hi Guys, Is there any better auto remediation tool you guys are using for aws security,like remediating ports that are open globally etc. We are currently using cloud prisma, but its currently just detecting and sending us notifications,but auto remediations are not ready yet. I am planning to write my own scripts meanwhile to remediate them, but my scripts call boto3 api and it needs to call every 30 mins or so how i define, i was thinking if i can log the actual real time data and auto remediate it when ever it detects any alert. Any inputs how to do it.
2020-05-14
Anyone have experience with RDS IAM connection throttling?
Pray tell. That sounds like an interesting story
¯_(ツ)_/¯
We don’t need any of that newfangled pooled connections
We were looking into RDS password rotation and the IAM Auth looked appealing, I heard good things about it, but was cautioned “be careful not to get throttled” because, supposedly, they will deny connections for 10-15minutes
read the docs, tested, warned my teams “make sure you don’t blow through the connection rate”
Now we have a couple of cases where we suspect we are being throttled, and I have a support ticket open … but AWS is incredibly vague about this
the postgres logs, once we enabled IAM Auth, are filled with all sorts of nonsense that’s hard to decipher. There’s no single error that says “stop connecting so fast” so we don’t know what we’re looking for
Is there any RDS metric you can pull that might shed light?
Nope
The docs on it just give you some very rough guidelines. It works great though - until you hit the wall. At least we think we’re hitting the wall, we can’t tell for sure.
omg, I was thinking about enabling that in the near future. This interests me.
same, please update the thread when you figure out what’s going on
I strongly suspect it was one application in particular causing the issue because it was not using pooled connections, and not even using persistent connections I’m just waiting on AWS support to tell me that yes, those errors in the PG logs are “iam throttling”
it’s silly that there’s not a metric that you could be monitoring
I agree … and I will be commenting about that to our support rep. I suspect they’re obfuscating it for “security”
There is a postgresql query to show active connections
Which of the following two is more accurate? select numbackends from pg_stat_database; select count(*) from pg_stat_activity;
Yah I can see the current connections no problem - but those are the ones already established. RDS exposes that as a metric directly.
The issue that I cannot see how many connections are being attempted through RDS IAM - which has a hidden max rate of connections per second
I could be well under the max connections the DB will allow but if I try to create those too fast, IAM will throttle the entire RDS instance - which is bad enough for a single application, but if you’re being economical and several apps with databases on a single instance, its really bad
also interested in this
@Zach you can maybe use vpc flow for that. You can query Tcp Syn packets coming to RDS 5 min interval or 1 min interval etc.
https://docs.aws.amazon.com/vpc/latest/userguide/flow-logs.html#flow-logs-basics tcp-flags 2 means SYN
Create a flow log to capture information about IP traffic going to and from your network interfaces.
3 vpc-abcdefab012345678 subnet-aaaaaaaa012345678 i-01234567890123456 eni-1235b8ca123456789 123456789010 IPv4 52.213.180.42 10.0.0.62 43418 5001 52.213.180.42 10.0.0.62 6 100701 70 1566848875 1566848933 ACCEPT 2 OK
“ACCEPT 2 OK “ 2 means SYN here.
SELECT SUM(numpackets) AS packetcount, destinationaddress FROM vpc_flow_logs WHERE destinationport = 5432 AND protocol = 6 AND tcp-flags = 2 AND date > current_date - interval ‘5’ min GROUP BY destinationaddress ORDER BY packetcount DESC
You may need to create table like https://github.com/awsdocs/amazon-athena-user-guide/blob/master/doc_source/vpc-flow-logs.md including tcp-flags
The open source version of the Amazon Athena documentation. To submit feedback & requests for changes, submit issues in this repository, or make proposed changes & submit a pull request. - …
2020-05-15
2020-05-17
2020-05-18
hey, anyone experienced aws fargate inability to resolve hostnames? After migration I’ve noticed that for some number of requests Django is not able to resolve RDS hostname which is ultra worrying.
Hi all. I’m trying to understand how to replace the use of security groups when using transit gateway
I’m used to using VPC peering, where peered security groups can be referenced, but I’m not clear on how this is meant to work if using TGW
in TGW you still need subnets and IPs AFAIK
the only case when this is not true is when you use Shared VPCs ( which we are using)
then you use SGids
Got it. I’ve set it up with CIDR.. does the trick, just a little less secure
I wonder how much you need to know about Amazons internals to understand why they descided to do it this way
well I guess their mistakes keep me employed
and keep the AWS wheels turning
lol
my company has just decided to hard pivot towards Azure
no good reason, but lots of work to do
2020-05-19
any reason why a route53 record would be pointed at an elastic ip of an ec2 instance instead of creating a load balancer and pointing the r53 record to it?
if you have an instance with an EIP associated to a route53 record, the instance was killed, how do you make sure the route53 record is then killed so no one gets a hold of the EIP and takes over the subdomain ?
You need to see the EIP as reserved for the AWS account, no-one else can use it unless you explicitly release the EIP.
The lifecycle of an EIPs is not dependent on the instance is associate to AFAIK. You retain that EIP even if the associated instance dies.
Oh yes — You gotta reserve it though
we release our EIPs
sounds like we gotta write up a script for this
thats true. hmm. i thought we had to release the eips due to cost.
from https://aws.amazon.com/ec2/pricing/on-demand/, i suppose the cost is pretty low
Amazon EC2 pricing is based on instance types and the region in which your instances are running. There is no minimum fee and you only pay for what you use.
Yes, I mean, if you have 10 unused EIP’s the whole time, you might want to clean up
otherwise it’s not the hassle
reserved EIPs are not very expensive. Much cheaper than a LoadBalancer. If you only have 1 instance that is sitting behind the R53 record, then pointing at the EIP is a reasonable approach
2020-05-20
question, say you wanted to create a static site in aws and your not allowed to use an s3 bucket, besides ec2 what are your options. i tried crying which didnt get me anywhere?
@James Woolfenden AWS Amplify.
Really great option. Comes with CI / CD, ENV var support, building pipelines, Git integration, etc etc etc. It’s the best.
yeah that could do it, it was supposed to be typescript serverless congnito with app lambdas and api gateway
type of thing
doesn’t amplify use s3 under the hood?
(if not, where does it store html files?)
yeah that could do it, it was supposed to be typescript serverless congnito with app lambdas and api gateway
Haha this doesn’t sound static.
@randomy Under the hood I believe it is using S3. But it isn’t using S3 directly 
that’s cheating
you could use cloudfront + lambda@edge to serve static files. you’ll probably cry more though.
Yeah — I feel like trying to host static sites without S3 in some way is going to be painful. Maybe the right question to ask is: Where is the requirement against / opposition to S3 coming from?
You could use Dyanmo DB to store the contents of each file in a separate key and then create a docker container and host it on ECS. Then for each page request you pull the corresponding dynamo DB HTML content and then serve that.
You could do that
The above is obviously just a poor joke. Not trying to poke fun too much.
You could chuck the site in a container and run it on Fargate
Sheehs, If I had too… probably the API Gateway with Lambda@Edge with static files..not in S3? Its all gonna bit more than a bit hacky though
amplify might work, customer suggest using azure
Azure Storage static website hosting, providing a cost-effective, scalable solution for hosting modern web applications.
also fargate
thanks @roth.andy i was hoping not to go multi cloud on one small website
what would i know…
github pages?
would be easy enough, aye
Where is the requirement against / opposition to S3 coming from?
well, if this webpage were the landing page for a facebook app, for example, s3 hosting doesnt work because even for a nice flat static page it has to answer a POST request on /…..
(no idea if that still applies, I haven’t tried to burn that bridge since the last facebook game I worked on deployed in ‘16..)
god no, this the enterprise. Security says no to s3 buckets, yes to Azure Blobs.
Fire your security team
(Just kidding of course, but that seems very strange and I can’t imagine why a company would be OK with AWS but not S3)
 2
2@randomy quite. some eejit made some blanket policy about s3 that buckets cant be public and now that policy is baked into every account.
Ah that connects the dots. Still not a smart policy, but makes sense.
Amplify would get around that for you. The bucket and everything underneath Amplify are hidden from everyone, so I don’t believe you would run into that account restriction AFAIK.
Netlify!
I will say I’m really impressed with netlify just getting up and running. They can really take you from zero all the way up to running and minutes for a full static website solution. If you’re using a static website generator like I am with Hugo for example for blogging you can even add forestry into the mix and have a nice web editor that is all CICD. To do most of what netlify would do would be just an exorbitant amount of effort in my opinion. You can add serverless, CICD, and more for free. Only need to pay at more commercial grade tier.
And you can redirect your GitHub pages to netlify with a simple file in the repo too. Definitely take a look at it. They even have deploy templates with the full stack ready if you take a look.
@Kevin Doveton you cant match a private bucket with cloudfront
you can use an origin access identity https://docs.aws.amazon.com/AmazonCloudFront/latest/DeveloperGuide/private-content-restricting-access-to-s3.html
Restrict access to your Amazon S3 content with an Amazon CloudFront origin access identity (OAI).
ill have to stomach a static sie in azure, its not ideal but its “ok” with security
i cant actually make the bucket to do that
i know in effect it will make it private enough, besides this is supposed to be a website so the content is actually public
thanks for all your input, hoping for someone to see sense today
Still worth checking out netlify if possible. It makes static site stuff a breeze. It’s kinda like jumping into a first class product for that. Only reason I wouldn’t use if I had to do some internal to the box static site or something.
Does any one here have some good links with ecs in terraform? seems like the terraform-ecs-alb-service-task seems to be deleting the task definitions. I’m coming from the cloudformation/troposphere world where I updated the task definition and then it persisted and then though automation I updated the service to point at the latest task definition.
terraform-ecs-alb-service-task is a good module. There are also good modules from Airship - https://airship.tf/getting_started/airship.html
Regarding deletion of task definitions - it doesn’t delete them. You can’t change the task definition itself, if you want to make changes - you create a new revision of this task definitions with the changes applied and then update your ECS service to this new revision of task definition. So terraform’s aws_ecs_task_definition resource does exactly that - creates a new revision and deactivates the previous if you make changes. In the plan you’ll see that it will destroy (deactivate) the existing task def resource (revision) and create a new one (revision).
Flexible Terraform templates help setting up your Docker Orchestration platform, resources 100% supported by Amazon
There is also a flag ignore_changes_task_definition in terraform-aws-ecs-alb-service-task module that allows to ignore external changes to task def applied to the service in case you modify task definition externally (e.g. changing image tag in CI/CD pipelines) and don’t want terraform to revert changes to task def on each apply
Maybe delete was the wrong word. But from my understanding inactive tasks are not allowed to referenced by new services, so it’s almost as useless in my mind. Keeping a history of active task definition allowed me to “roll back” bad deployments quickly, but updating a container version and updating the task again works as well. I guess I’m just a bit confused on how to use terraform for ecs.
How to do you deploy new images to ecs? From CI/CD pipelines or manually? Do you use any CLI tool for deployment?
In the past I queried the CFT, updates the version number using sed, and applied the new change set.
You could use https://github.com/fabfuel/ecs-deploy for example to deploy from CI/CD pipelines. There is an option to prevent task def de-registration when you do a deployment if that works for you.
Powerful CLI tool to simplify Amazon ECS deployments, rollbacks & scaling - fabfuel/ecs-deploy
Coo will check it out. Was hoping there was a pure tf solution, but poking around google doesn’t provide the solution I’m used to in cft world.
So you just use ecs to provision the infra and just do changes to app versions using tools?
Yes. This is just one way of doing deployments to ECS.
Yes, pretty much. At least that’s what we mostly see. Agree that a pure terraform approach would be nice, but the experience is more pleasant with some of the other tools for deployment.
Thanks I’ll look in to the tools
terraform is not really a deployment tool
for code/containers
in my opinion
2020-05-21
We’re currently just using awscli with circleci to push ecs deployments, but it seems very limited. No notifications out-of-the-box, no support for rollbacks. And then of course it messes with Terraform. I don’t want to ignore changes to task definitions, because we sometimes change the environment variables/secrets associated with the task. I wish there was a better way.
@Igor I think my suggestion to you would be to steer clear of managing env vars / secrets in the Task Definition itself. It’s painful and causes issues like this.
I suggest storing env vars + secrets in SSM Parameter Store and then using Chamber in your Dockerfile to pull those in at runtime. That combo is really nice.
https://aws.amazon.com/blogs/mt/the-right-way-to-store-secrets-using-parameter-store/
CLI for managing secrets. Contribute to segmentio/chamber development by creating an account on GitHub.

This guest post was written by Evan Johnson, who works in the Security team at Segment. The way companies manage application secrets is critical. Even today, the most high profile security companies can suffer breaches from improper secrets management practices. Having internet facing credentials is like leaving your house key under a doormat that millions […]
I like the idea of using chamber to manage SSM Param Store, but I don’t like the idea of embedding chamber into the image.
It’s actually ultra light weight since it’s just a go binary and with Docker multi-stage builds it makes it super easy to pull in without many changes.
Also had huge benefit that it works with the ECS task role to pull the data from SSM / decrypt with KMS.
ECS does the same with secrets, but adding/removing/renaming secrets does require a new task to be created
Has anyone had luck with using CodeDeploy?
playing with that now. https://docs.aws.amazon.com/AmazonECS/latest/developerguide/create-blue-green.html It beats completely over writing my task definition and not having a trail in the family, even tho inactive tasks count against you on the qoutas - https://docs.aws.amazon.com/AmazonECS/latest/developerguide/service-quotas.html
Amazon ECS has integrated blue/green deployments into the Create Service wizard on the Amazon ECS console. For more information, see .
The following table provides the default service quotas, also referred to as limits, for Amazon ECS for an AWS account which can be changed. For more information on the service limits for other AWS services that you can use with Amazon ECS, such as Elastic Load Balancing and Auto Scaling, see
Most of my deploys with ecs have been update the task def and then tell the service to use the latest. Monitor the performance (which took time), and then roll back if needed. having a blue green on code deploy now seems amazing.
I remember seeing a detailed article of the issues someone ran into with codedeploy blue/green
That scared me away from it at the time
I think it was this one: https://medium.com/@jaclynejimenez/what-i-learned-using-aws-ecs-fargate-blue-green-deployment-with-codedeploy-65dde6781fcc
If you’re considering using Blue/Green deployments for ECS services and want to learn about the CodeDeploy tradeoffs, read on.
I used in in past for ec2 instances and worked pretty well. Only thing that I didn’t like was missing option to specify script arguments in appspec.yaml. So I ended in making wrappers of deploy scripts which were fully functional by itself already.
and last agent release is from Dec 6, 2018
how do you all automatically give ssh creds safely to everyone ?
I use ansible to create their accounts and grab their public keys from github. Then they can login using the same keys they use for pushing code. Just add .keys to a user’s github profile URL and you get their public keys.
 1
1Definitely not aws-centric, but it’s easy.
ah cool. we dont use ansible, we use puppet and trying to migrate off. we were considering doing something similar with ssm or use ec2 instance connect.
If I was starting now I’d probably look at ssm / ec2 instance connect first, but we’re pretty happy with ansible. Also, at this point we don’t have much that’s not in k8s so our ansible usage is pretty limited these days.
I should also mention, gitlab also gives you user public keys if you add .keys to their profile page.
Migrated away from bastions / ssh for client projects and only use ssm-agent / Session Manager. Got tired of managing client SSH keys. Session manager + gossm is a really nice combo.
Terraform module to create an autoscaled SSM Agent instance. - masterpointio/terraform-aws-ssm-agent
Interactive CLI tool that you can connect to ec2 using commands same as start-session, ssh in AWS SSM Session Manager - gjbae1212/gossm
using that setup @Matt Gowie what does the ssm agent accomplish ?
seems interesting but unsure how it all works
It’s a single instance in your ~account~PC that is dedicated to being your session manager instance. I have a couple Fargate only projects so that small instances acts as the “bastion” into the private network since I don’t have others.
That SSM Agent instance is also setup for session logging to S3 / CloudWatch, so sessions are auditable.
I wrote a short post on that setup: https://medium.com/masterpoint/time-to-ditch-your-bastion-host-f22cc782de71
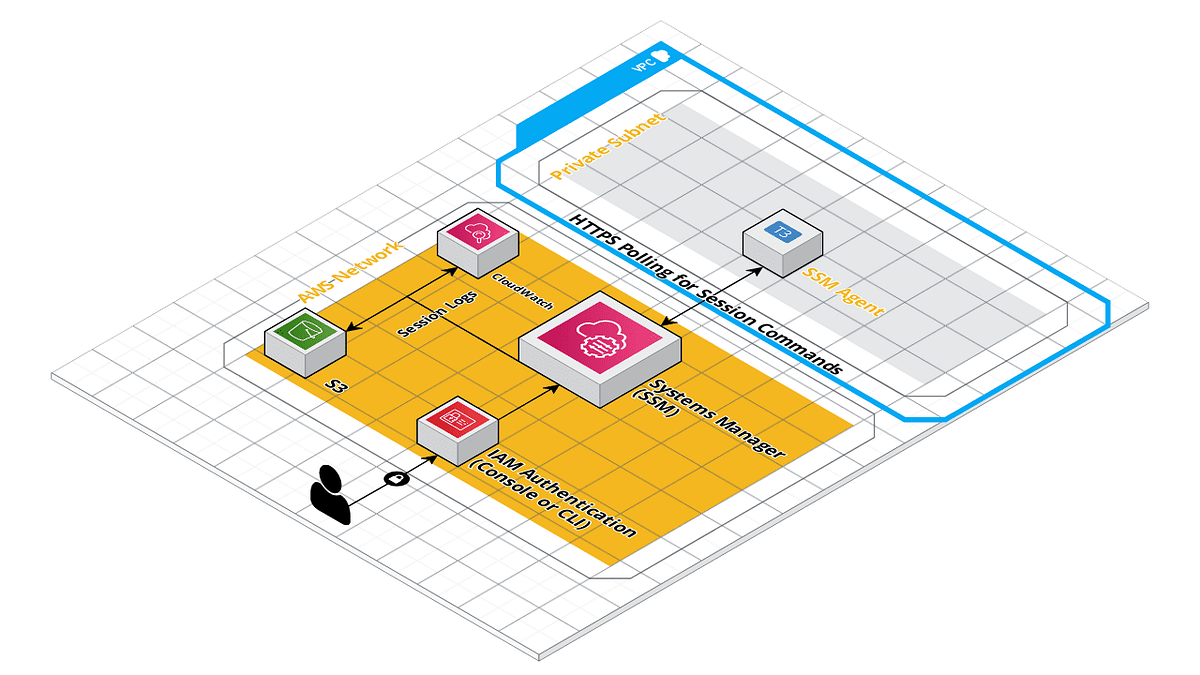
Time to ditch your Bastion host and change over to using AWS SSM Session Manager
Userify is a lightweight SSH key manager for the cloud.
Speaking of gossm - we were moving everyone over to that, with anticipation of disabling ssh access once done. But now a bunch of people have complained that their terminals are all sorts of f’d up when connected to the remote hosts. And I’ve noticed it too - you get weird behavior if you try to cycle through your shell history, or even using page up/down in vi or less when looking at a file. Has anyone else seen that, and is there a solution? We can’ tell if the issue is SSM or goSSM
(we just disabled logging in dev and the behavior went away so maybe this is AWS’ fault)
Huh — I haven’t seen that. I’ll keep an eye out… that doesn’t sound great.
Post back here if you find out more… interested if I’m going to have clients run into that issue.
I started using this https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ec2-instance-connect-set-up.html
Amazon Linux 2 2.0.20190618 or later and Ubuntu 20.04 or later comes preconfigured with EC2 Instance Connect. For other supported Linux distributions, you must set up Instance Connect for every instance that will support using Instance Connect. This is a one-time requirement for each instance.
i was wondering about that. what are your thoughts on it ?
Its pretty good so far. I don’t have to deal with passing aroudn ssh
@Matt Gowie my colleague found that the issue goes away if you resize the terminal window, so he wrote a little script that we’re adding to the default bash profile on the AMIs we build
resize() {
old=$(stty -g)
stty -echo
printf '\033[18t'
IFS=';' read -d t _ rows cols _
stty "$old"
stty cols "$cols" rows "$rows"
}
resize
@Zach — Ah interesting… I may add that as a note to that small TF module I’ve got to give others a heads up. Thanks for providing your resolution.
Further followup - AWS Support was able to replicate the issue and it seems to be a bug between the SSM Session logging the SSM KMS Encryption option. When both are turned on, terminal sessions get mangled when using anything that can scroll the shell. They’re looking into it to see if there’s a bug on their end. For now the resize function above is an ok workaround
2020-05-22
2020-05-23
2020-05-25
Am i right that Secrets Manager is somewhat limited to showing only 2 secret versions at once? Is it possible to view values of all past secret versions?
2020-05-26
Hi folks, Lately I’ve updated to v0.3 a pet project who intends to push notifications when you left running AWS instances on the most expensive AWS services. (EC2, RDS, Glue Dev Endpoint, SageMaker Notebook Instances, Redshift Cluster).
I hope you can give a try and get me some feedback about features, bugs, or architecture.
It can be a side-car for Instance Scheduler from AWS, and easier than CloudCustodian. Only informative and dead-simple.
Let me know if it makes sense, or if you have any idea to improve this.
Instance Watcher
Introduction
AWS Instance Watcher will send you once a day a recap notification with the list of the running instances on all AWS regions for a given AWS Account. Useful for non-prod, lab/training, sandbox, or personal AWS accounts, to get a kindly reminder of what you’ve left running.
Currently, It covers the following AWS Services:
• EC2 Instances
• RDS Instances
• SageMaker Notebook Instances
• Glue Development Endpoints
• Redshift Clusters
Notifications could be:
• Slack Message
• Microsoft Teams Message
https://github.com/z0ph/instance-watcher
Features
• Customizable Cron Schedule
• Whitelisting capabilities
• Month to Date (MTD) Spending
• Slack Notifications (Optional)
• Microsoft Teams Notifications (Optional)
• Emails Notifications (Optional)
• Serverless Architecture
• Automated deployment using (IaC)
Get notified for Instances left running across all AWS regions for specific AWS Account - z0ph/instance-watcher
Hey @Victor Grenu — This is cool stuff! I built something similar for test / experiment accounts that nukes the account using aws-nuke: https://github.com/masterpointio/terraform-aws-nuke-bomber
I’m sure the combo of the two could really ensure the user has a cheap AWS account
A Terraform module to create a bomber which nukes your cloud environment on a schedule - masterpointio/terraform-aws-nuke-bomber
Great, sounds interesting, will take a look.
filter @logStream like /doesnt-exist/
| stats count(*) by @logStream
This CloudWatch insights query walks through all log streams in the selected log group, even though it could exclude log groups by name…
is it really that inefficient? There must be a way.
2020-05-28
how does one create a vpc with both private and public subnets ? our vpc has a public cidr but i cannot add a private cidr to it in order to add private subnets
Your VPC has a single CIDR range. You carve out blocks within that for the subnet ranges
oh i thought you could add multiple cidr ranges to a vpc
@RB Since you know Terraform — I’d check out the CP VPC + Dyanmic Subnet modules as a good example.
https://github.com/cloudposse/terraform-aws-vpc https://github.com/cloudposse/terraform-aws-dynamic-subnets
Uhh yah I think that’s a ‘thing’ but its for a particular use-case
thanks gowiem, ill check those out
zach, i was looking at this yesterday https://docs.aws.amazon.com/vpc/latest/userguide/VPC_Scenario2.html but was seeing errors when adding the cidrs
ill try the terraform approach. it might be easier
seems like the terraform example also only allows for a single cidr block per vpc
Right, that page is illustrating what I described though. Their example is a VPC with CIDR 10.0.0./16; the public subnet is 10.0.0.0/24 and the private subnet is 10.0.1.0/24. The subnets are formed within the VPC cidr
so it might be easier to create a new vpc for private subnets ?
I think you are misunderstanding how the subnets work
Note that in the diagrams from the AWS docs that the subnets are drawn within the vpc
What you’re talking about with multiple CIDR blocks on the VPC itself is more related to this - https://aws.amazon.com/about-aws/whats-new/2017/08/amazon-virtual-private-cloud-vpc-now-allows-customers-to-expand-their-existing-vpcs/
You should be using a private CIDR in the VPC, the only distinction between a public subnet and a private subnet is the gateway. You can use multiple CIDRs in the same vpc but it’s only for certain use-cases.
stay away from adding multiple CIDR to a VPC it is a nightmare to maintain and debug and it is in some ways not the “proper” way to do networking
ah ok, thanks everyone. it sounds like i can continue to use the same cidr but create a new subnet with a cidrmask and to make it private, just change (or remove) the gateway
use “proper” as hacky, short-cutting etc
the cloudposse module for dynamic subnets uses the cidr function to do subnetting
The cidrsubnet function calculates a subnet address within a given IP network address prefix.
 1
1it does it automatically for you ( +- some inputs)
we do multiple cidrs on a vpc now. haven’t had any problems yet… was surprisingly easy. we create the vpc first with a cidr sized to just private subnets, routed to a central natgw via the transit gateway. then if the account needs public ingress we attach another cidr to the vpc, add an igw, and carve new subnets out of the new cidr, and create a route table for the new subnets that sets the default gw to the igw
I’m having problems setting up a logging account and assigning buckets for S3 logging to buckets in a central account.
I’m setting up logging for our multiple AWS accounts, which are in AWS Organizations. We use a separate account for each client’s infrastructure (all accounts are basically the same…SaaS). I’m trying to set up a logging account and send all logs there, including cloudtrail, Load Balancer, and bucket logging.
Right now, I’m working on the bucket logging, and it appears from this page (https://docs.aws.amazon.com/AmazonS3/latest/dev/ServerLogs.html) that the source and target buckets must be in the same account, which completely negates any thoughts of sharing log buckets across accounts in the organization.
I have a bucket policy that does grant access to the other accounts in the organization, with this:
{
"Sid": "AllowPutObject",
"Effect": "Allow",
"Principal": "*",
"Action": [
"s3:PutObject",
"s3:GetObjectAcl"
],
"Resource": [
"arn:aws:s3:::${local.log_bucket_name_east_2}",
"arn:aws:s3:::${local.log_bucket_name_east_2}/*"
],
"Condition": {
"StringEquals": {;
"aws:PrincipalOrgID":[
"o-7cw0yb5uv3"
]
}
}
},
but, though I can write to that bucket from any of the other accounts in the org, when I try to assign logging to those buckets (which are in the separate logging account), I get this error:
Error: Error putting S3 logging: InvalidTargetBucketForLogging: The owner for the bucket to be logged and the target bucket must be the same.
status code: 400, request id: FEDF21FAA89472BD, host id: v+LjsDLH+EpNXzcfjxVYiNDLH1HOhY5NpHFbPwGTpketFpeEyUVQxp+7DCCNE9ZDy/vdNUd8+Pg=
Discusses enabling Amazon S3 server access logging to track requests for access to your S3 buckets.
I had the same issue. AFAIK, it is a limitation of that feature. Basically, you can only define a target bucket that is in the same region and account.
If you want to centralize the logs, you have to implement a custom solution.
Discusses enabling Amazon S3 server access logging to track requests for access to your S3 buckets.
So, can I set up a logging account to receive s3 access logs?
Hi Everyone, looking for some EMR ETL advise, Use case : When a csv file (appx 1GB size) arrives in S3 - Launch EMR cluster, which will run Spark Script Steps and transform the data, and write into a dynamodb. There will be maximum 10 files that will arrive at a set time window of the day.
I have been thinking to use Event bridge rule - >Step function - > launch EMR cluster with Spot Fleet Task nodes Looking for advise if this is a good architecture?
quick question because I can’t find it in the docs… The sticky sessions on a NLB use a cookie or it’s based on Source IP?
I would like to have AWS EKS setup using Terraform in such way that we have 2 VPCs. One VPC where I should deploy AWS control plane and other VPC I should have my worker nodes running. Do we terraform suite for this in cloudposse or any other repo?
We haven’t attempted this configuration before. I was talking to some one at a bank through that ran something similar. It was the first I heard of the pattern. @Andriy Knysh (Cloud Posse) do you think the EKS modules we have would work this way? I don’t see why not - but the e2e automation might be difficult. Might require multiple terraform runs to avoid races.
this is not possible with managed Node Groups, not in the EKS console, nor in a terraform module (e.g. https://github.com/cloudposse/terraform-aws-eks-node-group) - EKS places the node groups into the same VPC
Terraform module to provision an EKS Node Group. Contribute to cloudposse/terraform-aws-eks-node-group development by creating an account on GitHub.
might be possible with unmanaged workers (e.g. https://github.com/cloudposse/terraform-aws-eks-node-group) if you allow communication b/w those two VPCs. Both control plane and the workers need to communicate with each other, so you have to make sure the two VPC can communicate and the security groups of the control plane and the worker nodes have the corresponding rules (e.g. allow from a CIDR block of the other VPC)
They are also using unmanaged workers..I dont know how to achieve this using Terraform. I was relying on using cloudposse terraform modules for EKS deployment. But this scenario I am not able see any help on online or could see here in cloudposse..If you could guide me or share some lead on how to achieve it would be really great..
I don’t know all the details involved, but I believe you have to at least do these two things (more things could be involved, not sure):
- Allow communication b/w the VPCs using any of the methods https://docs.aws.amazon.com/whitepapers/latest/aws-vpc-connectivity-options/amazon-vpc-to-amazon-vpc-connectivity-options.html . VPC peering is prob the best for the task (e.g. https://github.com/cloudposse/terraform-aws-vpc-peering)
Use these design patterns when you want to integrate multiple Amazon VPCs into a larger virtual network.
- Cluster and workers security groups: You have to use CIDR blocks from the other VPCs to allow communication b/w the control plane and the workers
Terraform module to provision an AWS AutoScaling Group, IAM Role, and Security Group for EKS Workers - cloudposse/terraform-aws-eks-workers
Terraform module for provisioning an EKS cluster. Contribute to cloudposse/terraform-aws-eks-cluster development by creating an account on GitHub.
Thanks @Andriy Knysh (Cloud Posse) for the links..let me go over it and try to setup something with 2 VPCs.
I don’t have an answer as to how, but I am very curious as to “why?”
the “why” is a good question regardless of whether you put it into one or two VPCs, you have to allow communication b/w them anyway. I don’t see any benefits of doing two VPCs besides a more complicated setup
Coz my customer EKS setup is like that.. Customer business workloads (pods) running under worker nodes on different VPC and control plane is running on different VPC.. I need to replicate that for our testing.
Environment variables can be passed to your containers in the following ways:
2020-05-29
I would like to create EKS unmanaged worker nodes 1 on VPC1 and Worker node 2 on VPC2. Control plane on maybe running on either VPC1 or VPC2. Is it possible to setup something like this?
it’s possible. as we already discussed you have to do this:
- Create two VPC and add VPC peering between them
- Add the CIDR block of VPC1 to the ingress rule of the SG of VPC2
- Add the CIDR block of VPC2 to the ingress rule of the SG of VPC1
yep looks similar request..but here was talking about worker nodes in different VPCs. But implementation looks same from your inputs..Also just for the update..Managed to bring up with Cluster and Node1 in VPC1 and Node2 in VPC2 with VPC Peering enabled. It works fine..Only things still not working is, not able to go to bash prompt using kubectl(from local machine) of a POD running in Node2 VPC2. Pod to Pod ping across nodes are working fine..only bash prompt is failing to connect. Will work through that.
did you open the entire CIDR blocks as ingresses?
and all ports?
could be that some ports are not allowed
Yep opened all port all traffic with VPC CIDR block on both Node2 n Cluster secgrps. Still no luck.
2020-05-30
2020-05-31
how are people managing AWS CLI 2FA ? I find it very hard to manage the usage of the cli right now with 2FA enforced
aws-vault? https://github.com/99designs/aws-vault
A vault for securely storing and accessing AWS credentials in development environments - 99designs/aws-vault
thanks I will check it out.
it’s great