#aws (2020-06)
 Discussion related to Amazon Web Services (AWS)
Discussion related to Amazon Web Services (AWS)
Discussion related to Amazon Web Services (AWS)
Archive: https://archive.sweetops.com/aws/
2020-06-01
Do we have any recommendations on how to write into dynamo table using EMR - we are using com.audienceproject1.0.1 lib and this takes ages to write into dyanamodb , even though I used provisioned WCU to 100, the consumed write capacity stays < 8
2020-06-02
Hi Folks..the certificate things are pretty confusing if we are new ..are there any difference in usage of the below 2 cli commands? aws iam upload-server-certificate ….. and aws acm import-certificate….?
@Prasad ACM cert management and IAM cert management are two different things. You’re correct that it’s confusing, but I would suggest you investigate the two solutions.
ACM is definitely the suggested route, but I believe it’s not available in all regions.
if i need to upload a internal custom signed cert and assign to a Internal LB which one do we prefer ..? Internet is restricted for us and white listing is being done only when its absolutely necessary. Can we use Endpoint for acm service and perform this? i believe aws iam has only public endpoints..Have you come across any pointers that explains the difference between the 2…Thanks again!
Regarding the “Amazon ECS ARN and resource ID settings”. Has anyone had any issues turning on the new arn format for ECS container instance, service, or task ?
aws ecs put-account-setting-default --name containerInsights --value enabled --region us-west-2
aws ecs put-account-setting-default --name serviceLongArnFormat --value enabled --region us-west-2
aws ecs put-account-setting-default --name taskLongArnFormat --value enabled --region us-west-2
aws ecs put-account-setting-default --name containerInstanceLongArnFormat --value enabled --region us-west-2
aws ecs put-account-setting-default --name awsvpcTrunking --value enabled --region us-west-2
you need to do that
on the cli
is an account wide setting you could I think AWs organizations to do that
right because its region specific. i thought it was an account wide setting too
it is pretty stupid
so wait after you enabled it, did you see any issues with the new arn format?
awsvpcTrunking
and containerInsights is not needed for the ID thing
not issues at all
I did this in a very old prod account
nothing happened
awesome! that makes me feel a lot better
seems easy enough to opt out anyway
They were supposed to make these the default settings earlier this year, but then they backed out. It’s a real pain.
 1
1yes
Is there some way to convince AWS console that yes, I will use their new interfaces, please stop reverting to the old one?
don’t mess with your cookies?
To my knowledge I haven’t been
2020-06-03
My client just using AWS like RDS to save their customer data (financial service), how to improve the security on it? Any best practice?
Follow these best practices for working with Amazon RDS.
any suggestions on tagging policies ? we use
Name - for whatever
env - for production, staging, etc
role - function
team - team name which corresponds to slack channel
we have a new one from terraform called git_repo which is dynamic based on where the terraform was applied
The https://github.com/cloudposse/terraform-null-label also has namespace , stage, and attributes tags
My recommendation on tagging policy…. not too much, not a couple
We have a Billing tag
what is the value of Billing tag ?
It depends… normally it’s gonna be the team/system that;s gonna pay for that cloud service
So we can charge back and split the AWS bill based on that
we have a similar tag. out accounting provided cost allocation numbers for teams and we use those to tag resources in shared accounts. if an application is using a separate account (e.g. aall production environments are separated) it’s automatically attached to a certain number and we don’t have to do it (but we still do to simplify our cf templates)
thats pretty cool
i also found this nice doc on best practices
https://d1.awsstatic.com/whitepapers/aws-tagging-best-practices.pdf
does anyone use tags for access control ?
We do…
We use AWS Session Manager
ah interesting. found this example for that.
For costs/billing purposes
AWS seems to recommend putting IAM Policies onto Groups, then adding IAM Users to Groups, as opposed to directly adding Policies to the Users.
But this seems in conflict with having a non-increasable service limit where IAM Users can only be in 10 Groups.
How do you all manage situations where you feel a User should be in >10 Groups?
You can put 10 policies in one group, so I’ve honestly never needed to associate a user with more than 100 policies.
we hit that limit already
we have users in more than 10 groups
and more than 10 policies per group
AWS limit that you can request to be bumped then?
We are looking at ways to use Service policies for the ORG
not, it can’t be bumped, that is what they told us
it is a hard limit
So you have users who you want to put in more than 10 groups and add more than 10 policies to those groups is what you’re saying?
mmmm no I think I’m mistaken, we have more than 10 team/groups and some users need to belong to more than 10 groups so we attache policies directly to the users
it is a mess
you can’t add users to more than 10 teams
Ah that is a mess. So @David’s is valid and you’ve already run up against. That sucks.
Can’t you create new pseudo groups for those that need to be in more than 10 groups? You might require some automation to manage the pseudo groups.
For example the automation would take two groups and make a new Group1_Group2 group with the policies from both. Would need to listen for updates to Group1 or Group2 to sync the policies over.
That sounds like hell @jose.amengual - Perhaps you need to simplify your users / groups configuration or move to something like Okta / SSO and externalise user / group management instead allowing users to assume roles based on groups in the Identity Provider.
It’s been a long time since I’ve had any AWS accounts that contain actual AWS users in them.
We’re using assumed roles only, same deal. I have a few ‘legacy IAM Users’ that I’ve been giving a countdown to for their access to be removed
it is a mess, it has been done for a log time by hand and now we have a team of people starting to automate, finally
Ah… the joys… How are your groups organised? Around business function or capability? I’m guessing all the users use a single account?
For the users with 10 groups you might be better off either consolidating their permissions into more powerful groups or creating roles that have the policies attached and allow those users to assume those roles.
I think that anything you do will be coding around the problem and your account(s) is probably due a bit of an IAM refactor. I’ve done similar things with various places migrating from IAM users / groups to IAM users / roles to SSO / roles with permissions boundaries.
These things are always scary but can be done gradually allowing experimentation and learning. You can enable SSO and run it alongside plain old IAM users. There are a few good articles out there on the subject (https://segment.com/blog/secure-access-to-100-aws-accounts/) and lots of tooling to help your users (aws-vault, aws-azure-login, aws-okta). Maybe it’s worth a chat with your friendly local AWS TAM to get some ideas?
That said, I don’t know how big the real problem is for you or if it warrants the work needed to refactor your accounts / IAM. It would be satisfying for you once it’s “done”

The Segment team’s latest thinking on all things data, product, marketing, and growth.
we have groups that we attach roles to it so it is not soooo bad but there is a mix of user with policies attached, users attached only to groups or direct attached policies
so we need to cleanup and take one approach
2020-06-04
2020-06-05
Quick question Do we need security group (ports open) to talk internally in vpc services
you can use “default” security group for that. all machines with this group can see each other in internal communication
what about services like rds
same with rds, it had security groups too
so you are saying default one have special permission to talk with in vpc
well, not a permission, but an inbound rule that says: allow all traffic from the same group (must be in same region)
It is bad practice to use the default vpc, usually default vpc is fully open, inbound and outbound
in our case I think we delete it or at least change the rules to not allow anything and then we create SG for each resource
and you always need an SG to open ports to talk to other services inside AWS
anyone get logging working between aws and datadog ? looking at datadog’s ecs_fargate#log_collection and considering fluentbit over the lambda log forwarder
Yep, the fluentbit approach is working like a charm. The only downside is that you should have sidecar (which needs resources) for every workload that need to ship logs to datadog
ah fantastic. i was planning to do the following, add a datadog sidecar container, use the fluent configuration from that document, and is there any additional configuration ?
do i have to manually open the tcp port on the agent or can i just add a port mapping for that ?
Nope, sidecar can talk to the main container in the task and vice versa without any additional rules or port openings. And obviously the task should be able to communicate with datagod’s intake for logs (i.e. have egress rule in sg)
perfect!
so the firelens and fluent portion, firelens is built into aws, but for fluent, do i need to install fluent ?
Firelens is a log driver that allows to route logs and fluentbit (in a sidecar container) receives them and forward to the destination (datadog in your case). You don’t need to install anything, you should only change your task definition as suggested in the docs you’ve mentioned
ah so it sounds like i need fluentbit sidecar with my app as a sidecar for sending logs
i figured if i wanted apm, i also needed the ddagent as a sidecar too
so then ddagent, fluentbit, and my app
Not necessarily, AFAIK you can also have ddagent deployed as a service and configure your app to send metrics and traces to this service. So sidecar for ddagent in your app’s definition is not a must.
AWS has a fluent image design to work with firelens. Makes it easy to setup. You’ll need to add datadog plugin to it or route all traffic through an aggregator that has the plugin
interesting so perhaps to make our fargate more scalable, it would be best to deploy the ddagent as a service in my cluster, and then have all my fargate services (app + fluent with firelens config) configured
so that way ddagent will get apm for the fargate services and each fluent sidecar with firelens config will send the logs to datadog
yes
we have multiple regions, multiple clusters. would every cluster in a region need its own ddagent service ?
Yes, each instance of ddagent would monitor the cluster it’s deployed to.
 1
1i got fluent to work appropriately using a fluent sidecar
running into this now. hoping someone from this thread might be able to weigh in
Regarding fluent-bit pushing logs from ECS to Datadog, we noticed there is a log key being used for every log entry. Is there a way to rename this to datadog’s expected msg key ?
hey everyone, I am having an issue with an AWS deployment. I am very new to both AWS and to terraform. I get this error when I apply the terraform configuration. I am using the default VPC with a security group with the following configuration:
ingress {
from_port = 443
to_port = 443
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
ingress {
from_port = 80
to_port = 80
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
}
https://stackoverflow.com/a/30140563/5356465 according to this, the issue could be with the VPC, but this is the default VPC, isn’t it supposed to have internet access by default? I haven’t associated this with any VPC at all
The error message is: Stack named ‘awseb-e-r3uhxvhyz7-stack’ aborted operation. Current state: ‘CREATE_FAILED’ Reason: The following resource(s) failed to create: [AWSEBInstanceLaunchWaitCondit…
is this because of the VPC or is it related to something else? do you guys need any other information? if it’s related to VPC, is it because I am using the default VPC and aren’t associating the Elastic Beanstalk environment with any VPC?
I’m looking for experiences with the Amazon Partner Network ? Are there freebies involved with certification ? Other benefits ?
You get credits that exceed the membership cost
2020-06-06
Hello. Just found you. Would you have any idea about using AWS CloudWatch Agent on Fedoura CoreOS? I have the SSM Agent working but I want to copy logs file to CloudWatch and SSM is deprecated. Wish I knew that last night.
SSM is deprecated?
the log agent part, yes
2020-06-07
Any objections with storing secrets using kms encryption in s3?
I think is better to use parameter store or secret manager
Doesn’t that cost a lot more compared to s3? I do like the idea of secret rotation with secrets manager
secrets manager does seem rather pricey in comparson
personally i see nothing wrong with kms-encrypted s3 objects. i think it is a fantastic option. to me, really the only difference between the three are their APIs, and any integration with other aws services (for automatically retrieving/decrypting values, e.g. cloudformation + parameter store)
Parameter store and Secret manager have version for secret, use KMS for the encryption etc
SM is 3x more expensive than Parameter store
s3 buckets can be set public very easily so having secrets could be a risk
Also, Parameter Store have size restrictions so you’re often forced to use S3 anyway.
hello. migrating from my self hosted k8s cluster to EKS. considering switching my ingress controller. I guess the popular approach is to use a hybrid ALB + nginx setup, best of both worlds.
got 2 questions
- it seems there are two different nginx ingress.
https://github.com/kubernetes/ingress-nginx/
https://github.com/nginxinc/kubernetes-ingress
the one released by nginx team looks interesting, wondering if anyone has experience with it? not sure if it’s even worth considering if i’m not getting the paid version
- while the hybrid approach seems like the way to go, i haven’t been able to find steps online to setup. i guess the AWS way is to just use the ALB ingress controller. anyone point me in the right direction? or convince me i should just use the ALB ingress?
NGINX Ingress Controller for Kubernetes. Contribute to kubernetes/ingress-nginx development by creating an account on GitHub.
NGINX and NGINX Plus Ingress Controllers for Kubernetes - nginxinc/kubernetes-ingress
2020-06-08
I have an existing Beanstalk application which is running as single container applications. I just enabled CloudWatch logging and now all log data is streaming to CloudWatch (nginx, docker, etc) except for the log messages written to stderr/stdout. In other words the log messages I care most about.
I can see exactly what's wrong, the config file for the Cloudwatch agent (/opt/aws/amazon-cloudwatch-agent/etc/amazon-cloudwatch-agent.toml) is configured to track a stderr/stdout log file at this path /var/log/eb-docker/containers/eb-current-app/stdouterr.log. However, my applications are logging to this path /var/log/eb-docker/containers/eb-current-app/eb-f54b7e030fd5-stdouterr.log
The CloudWatch log group uses the path with 'eb-current-app/stdouterr.log' in it (no surprise there).
The f54b7e030fd5 is the (short) ID of the running Docker container.
Does anyone know how I can configure this? I'd like to do it in a way that will of course survive beyond containers and instances as they spin up and down. I can define additional log files in .ebextensions which allows Beanstalk to become aware of non-standard log files but that would require me knowing the container ID ahead of time i.e. when bundling the Beanstalk application version.
It seems like the best fix would be to force Beanstalk to log stderr/stdout from the container to the path which CloudWatch expects.
The file attribute in the config file supports wildcards I’m pretty sure. Have you tried that?
yes, didn’t seem to work for me
Do you get any errors in eb-activity.log?
no
the service runs fine
The logs just aren’t being streamed to CloudWatch
Yeah, I do remember when this happens awslogs agent should notify if the file match pattern doesn’t match. Perhaps it was in its own log file.
It’s been a while since I looked at this
Turns out it’s a bug, AWS is working on it.
Wow, ok. Thanks for updating. Is it a bug with the agent or in the EB processes?
I think EB
the way it configures the Docker env
Ok I see.
Fun with Beanstalk. . .
2020-06-09
did anyone use CW>>lambda>>firehose>>splunk integration? We have an issue where the logs have a delay around 3m. Is there a better solution for app logs from AWS to splunk without any delay. I’ve used kinesis streams in the past but seems like the driver isnt supported and if the log data is huge it seems to be dropping logs
we are using, but w/o firehose. if you’re just shipping logs to HEC, wondering the need for it
How are you sending the logs to directly to hec from cloud watch?
lambda
just don’t see what you’re using firehose for
so if the logs arent being processed then they can send it to s3 in firehose
can we do that with lambda?
Any Storage Gateway File Gateway users? Wondering if I can pick somebody brain… My file gateway keeps getting created with a private IP as if I’m trying to associate it to be an internal / VPC gateway which is not what I want.
Figured this out. AWS is a PITA… They show / provide the private IP of the Storage Gateway instance in the console and corresponding file share mounting commands. That led me to believe AWS was only exposing the File Gateway privately inside my VPC, but that’s not the case. Using the Elastic IP that is associated with the storage gateway instance did the trick.
In the coming few months, AWS Fargate will update the LATEST flag to Platform Version (PV) 1.4.0. This means all new Amazon Elastic Container Service (ECS) Tasks or ECS Services that use the Fargate launch type and have the platformVersion field in their Task Definition set to LATEST will automatically resolve to PV 1.4.0. For customers who use Amazon VPC Endpoints along with their ECS tasks running on Fargate, the new platform version has changes that may require customer action. For more information see the FAQs below. If you do not use VPC endpoints for Amazon ECR, AWS Secrets Manager or AWS Systems Manager no action is necessary.
2020-06-10
Hi I have an interesting problem, I’m enabling IAM auth for RDS and I have users that have U2F keys so the aws cli does not support them and so they can’t get a token for the RDS host, BUT they do have console access so I was wondering if there is a way to run trough the console the the command to get the token and then they can use it to connect to the host aws rds generate-db-auth-token is the command. I was thinking that maybe an SSM doc or like a container they can fire up and get the token or something like that, I do not want to use a Bastion host for this
Not an exact answer to your question… but I’m in a similar situation using a YubiKey for programatic/cli access, and I do use it for IAM auth with RDS.
Specifically I’m using aws-vault and the YubiKey with OATH-TOTP support. More details on setting it up here: https://github.com/99designs/aws-vault/blob/master/USAGE.md#using-a-yubikey
You can do the same setup without using aws-vault as well.
For console access, I use Alfred on Mac to run the ykman cli command to generate the token and paste it in the MFA prompt.
A vault for securely storing and accessing AWS credentials in development environments - 99designs/aws-vault
Alfred is a productivity application for macOS, which boosts your efficiency with hotkeys, keywords and text expansion. Search your Mac and the web, and control your Mac using custom actions with the Powerpack.
So essentially, the easy way is to use the YubiKey with OATH-TOTP and not U2F.
that is interesting
we use aws-vault all the time
this specific user is on windows so I hope this works for him
It looks like the ykman cli is installed along with the GUI of YubiKey Manager for Windows (details), that should be all that is needed. Good luck!
I will report back
2020-06-11
does anyone know if we can heapdump or thread dumps from fargate?
As long as you can remotely trigger it and output to STDOUT, it would be possible. But haven’t done myself. We use APM and haven’t needed to dig deeper yet
what are peoples thoughts on using https://eksctl.io/ vs terraform modules to setup an EKS cluster? Pros/cons
The official CLI for Amazon EKS
if everything else in your environment is terraform - use terraform.
The official CLI for Amazon EKS
if not then the tool seem solid
It’s a new setup, using variant2 for the orchestration
that seems brave. be interested to see how you go with that
Brave or something else, a fine line. I will report my experiences
hahaha good luck
TY
It’s great, don’t use cloudformation, it sucks..
eksctl is great?
Yes, if you are new comer of AWS, it’s very easy to use eksctl to create AWS networking components such as VPC and subnets.
Maybe I’m a bit late to the party, but eksctl it’s great. We’re using it for our EKS and I love it.
2020-06-12
theoretically, would you replace web -> sqs -> worker -> firehose with a simple web -> firehose approach? I’m load testing the app currently with double the traffic I have normally and altho everything seems stable I’m having second thoughts about it because of increased latency (not much just 100-150ms on avg).
firehose is designed for handling large amounts of data ingest - so if you’re putting things in front of it that’s probably defeating the purpose somewhat
where’s it going after firehose?
s3
previously the sqs -> worker -> firehose/elasticsearch made sense becauyse of how the elasticsearch indexes were created
and firehose wasn’t able to deliver messages the way we needed into the index but since we have dropped elasticsearch I started to question the architecture
i’d say you’re probably running more than you need to, and bottle-necking firehose. this is without knowing your specific use case though
also spending several k more per month for maintaining worker instances
yup
AWS, Create IAM Role API Collapsed https://stackoverflow.com/questions/62341775/aws-create-role-rate-exceeded?answertab=votes#tab-top
While creating a new IAM role I am getting Rate exceeded I have around 215 roles for my AWS account. Is that a limit, if it is how can i increase it? if not a limit how I can resolve it?
How do people use and switch between different AWS accounts (hundreds) in the AWS console? We currently have a CLI command that opens the browser for the specified AWS profile but it’s not great.
and a config file for the cli
I do not however manage 100 accounts, so don’t know what the experience is at that level.
We use assume-role at the CLI
And same Chrome extension as @Tyrone Meijn
Using aws-vault exec or login depending on the need
SSO w/ all the accounts under an org master
At a previous role I used different Chrome profiles for the different IAM authentication accounts (2) and then different AWS Extend Role Switcher Config for the two profiles. You could also generate the AWS Extend Role Switcher config using a NibleText template or some other templating tool so that you can switch the config between different groups of accounts.
Anyone any advise what to use for encrypting environment variables for AWS lambda, so any opnion about using SSM with KMS or AWS secret manager?
SSM secured string uses the aws managed KMS.
There is an option to encrypt environment variable on lambda itself. You can use KMS key to encrypt those lambda variables
2020-06-13
2020-06-15
anyone using aws ecr get-login in a Makefile here? I’ve this annoying issue that whenever I execute any aws cli command that assumes a role and the source_profile is MFA protected I get following error:
aws ecr get-login --no-include-email
Enter MFA code for arn:aws:iam::AWS_ACCOUNT_ID:mfa/USER: docker login -u AWS -p [...]
make: Enter: No such file or directory
make: *** [ecr_login] Error 1
here’s my makefile target
ecr_login: AWS_REGION ?= us-east-1
ecr_login:
$(shell docker-compose run --rm -e AWS_PROFILE=$(AWS_PROFILE) $(DEV_IMAGE) aws ecr get-login --region us-east-1 --no-include-email)
as far as I can see it fails because I’m trying execute the output of the command which is returned to STDOUT but the Enter MFA code is also provided via STDOUT and the execution going nuts. 2nd execution succeeds because boto3 stores a session and doesn’t ask for MFA for another hour. What’s also puzzling is that the Enter MFA information is not shown and you need to assume it’s there because terminal ‘hangs’ while expecting an input.
yeah it’s just to execute the docker login command. But your approach was right. I just had to replace the
$(shell command)
with
`command |tr -cd "[:print:]"
`
the piped tr is there to cut all non printable chars from the output before execution
was a shot in the dark, but glad it helped!
sometimes the simplest solutions are hiding from us because of “experience”
I’m working on tightening up our NACLs and was trying to find out whether NACLs apply to load balancer ingress. I have the same question regarding the new Transfer Servers VPC; you can configure a security group, but it’s not actually in a subnet, so NACLs shouldn’t apply. Am I off-track here? Thanks, as always.
What @Chris Fowles said, NACL’s provide a good way of blocking IP addresses VPC wide. Security Groups are the instrument to do the actual firewalling with.
Thanks for the input, guys, but my question was whether NACLS actually even apply to ingress on load balancers.
I have heard and like the idea of keeping NACLs to a minimum.
Most of the time NACLs are not a great pattern to follow.
Trying to tighten nacls beyond “this subnet should only receive traffic from this other subnet” is generally going push down more on the reduced functionality side of the functionality vs security balance.
2020-06-16
hey guys Need help regarding Application Load balancer i have setup aws acm and attach it to the listener of alb on port 443, which is redirected to target group for 443 and a simple listener for port 80 redirected to target group on port 80 target group(instances are same but on different port 80 and 443) instances are serving webapp on port 80 I am getting 502 with https and working well on http(which not showing ssl)
what i am doing wrong?
and a simple listener for port 80 redirected to target group on port 80
target group(instances are same but on different port 80 and 443)
instances are serving webapp on port 80
This seems mixed up, not sure if you just typed it incorrectly?
What you probably meant/want is 1 ALB rule that redirects port 80 to 443 on the ALB 1 ALB rule that forwards 443 to your targetgroup (etiher on 80 or 443 at that point, whatever the group is configured to listen on)
shuold i forword alb 443 listner to 80
now i have simple config listener 443 to target ec2 port443 listener 80 to target ec2 port 80
You want both 443 and 80 to reach the instance?
if so, yes thats the config
most setups though you redirect port 80 on the ALB to 443 so that it establishes the TLS
@Zach Thnx man its working now
omg!
i was writing my own ASG roller
now i can do something else
Question now is how long will it take the AWS provider to support it in terraform
I’m kinda curious what it would even look like in terraform… You still have to change the launch config… So, would it be a non-replacing change to that property of the asg? Maybe send the StartInstanceRefresh command instead of force replacing the asg?
Yah might be odd. Maybe this is just deployment command rather than something in the state.
Here’s a better article describing how the feature works, strangely not linked from the what’s new post… https://aws.amazon.com/blogs/compute/introducing-instance-refresh-for-ec2-auto-scaling/
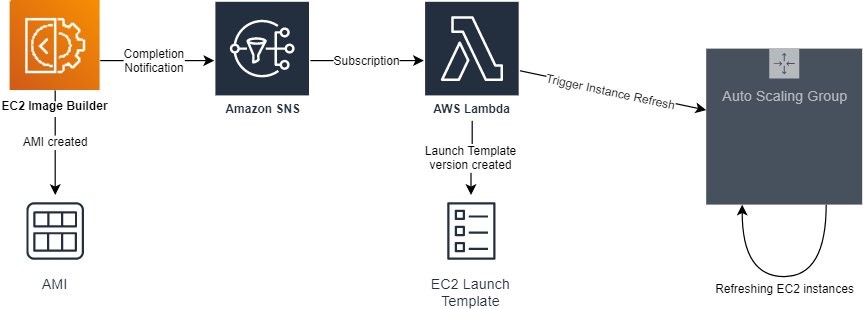
This post is contributed to by: Ran Sheinberg – Principal EC2 Spot SA, and Isaac Vallhonrat – Sr. EC2 Spot Specialist SA Today, we are launching Instance Refresh. This is a new feature in EC2 Auto Scaling that enables automatic deployments of instances in Auto Scaling Groups (ASGs), in order to release new application versions or make […]
SWEET. Stoked this is around. “Instance Refresh” seems like a pretty poor name for this though…
I kinda like the name. I can’t think of a better one off the top of my head.
I think “Instance Rollout” would be my name. Not saying that is much better, but “instance refresh” makes me think of updating static instances. Not that it is swapping out old instances with new ones.
Ahh, I guess I just see your point. I’m bet Product Marketing said Refresh sounds better, so they went with that.
Haha yeah likely.
Couldn’t you just scale up with the new launch template and then scale down? That’s how we refreshed instances.
Yes, if you have one cluster to manage
Yes that’s what people tended to due, or just replace the ASG entirely. The downside of those methods is that they take awhile to execute, and you double (or more) your number of running instances during the swap - which could run into account limits or temporary AWS capacity shortages.
2020-06-17
has anyone tried this with ECS EC2 instances to see if those will be adequately drained ?
Is there a good pattern for managing DataPipelines for EMR between dev/staging/prod in some sort of sane manner? Its simultaneously ‘infrastructure’ and software all rolled up in one. We tried doing it all in terraform but its a mess because the Data team has no idea how to maintain that, and its got like 100 more options than they need … and then we’re stuck trying to use terraform as a config mgmt tool
I’ve run into this problem a few times. It’s always turned into “Data Engineering Team owns EMR”. We might try to bootstrap something for Security and watch IAM and SGs and the normal stuff, but I haven’t really found a good way to bring EMR clusters into a Central DevOps/SRE team.
End up easier that that team just hired their own DevOps/Infra person and managed stuff in that space more loosely coupled than the central team.
Yah that is what I’m trending toward. They were comfortable writing some Ansible/boto stuff to create the EMR, but we took it off their hands because we didn’t want to give them all these resource creation permissions for the SGs and IAM. That then turned into a constant “hey can you guys update the json in terraform with X”. But maybe I just let them do that and turn it into an automation job they can run
Hmmm…maybe do a Jenkins job with a bunch of build parameters to launch the cluster and me okay as it morphs away from code
I dunno. I’m my older years, I really believe in decentralized DevOps squads now, esp. in my current role. It’s super expensive to have teams with their own SRE though. Only big successful orgs can do it.
yah we’re a small company, I don’t have time to micro manage this stuff
the constant json updates reminds me of this: https://info.acloud.guru/resources/why-central-cloud-teams-fail-and-how-to-save-yours

After years of watching central cloud teams struggle, I found a surprising metric that predicts whether your cloud transformation will succeed.
We initially tried it as this HUGE parameterized terraform module, with a Rundeck job for it, where they could specify overrides and stuff, but it was just too much for them to figure out how certain settings mapped into what they saw in the execution. For whatever reason they understand the boto reprsentation of the Pipeline better than how it actually ends up rendered in the AWS side
Yah I dunno. I’m happy to remove it from my terraform repo and just tell them to make some python to create their pipeline and we’ll run it from a job
that might be a fair idea. create a repo they can PR too, devops approves the merge and the jenkins job fires off the apply
if they get python templating and don’t get TF, it’ll make them more productive, you still get security review with the PR review and jenkins maintains IAM applies/SG permissions
Right, mostly just need to see that they didn’t stick in “super_secret_admin_role”
Woah. I just noticed https://aws.amazon.com/about-aws/whats-new/2020/06/introducing-aws-codeartifact-a-fully-managed-software-artifact-repository-service/ Per usage pricing
So we have to maintain a list of iam roles that access our s3 bucket within kms or those roles will have s3 access but not decryption access
aws iam list-entities-for-policy --policy-arn arn:aws:iam::snip:policy/s3-access --query 'PolicyRoles[].RoleName' | egrep -v '^\]|^\[' | cut -d'"' -f2 | sort | uniq
we have to manually update the kms policy based on this list. is there a way of automating this to keep our kms policy in line with any iam role containing the policy ?
there doesn’t seem to be a terraform list-entities-for-policy data source to tie into this
Does anyone here know how to add instances to Systems Manager? I’ve got a few showing up somehow but the majority of my instances aren’t in the list and I’m not sure if it’s something I did in the web interface that added them or something I changed on the box somehow.
It’s the SSM-Agent running on those instances. It comes with Amazon Linux 2 AMIs.
You can install it yourself on other linux distros if that is what you’re looking to do:
sudo yum install -y <https://s3.amazonaws.com/ec2-downloads-windows/SSMAgent/latest/linux_amd64/amazon-ssm-agent.rpm>
sudo systemctl enable amazon-ssm-agent
sudo systemctl start amazon-ssm-agent
Ok, so just having the instance on the box is enough?
You mean the agent? Yeah. You may also need an EC2 Instance Profile with correct permissions… I forget actually
Here are the docs: https://docs.aws.amazon.com/systems-manager/latest/userguide/ssm-agent.html#sysman-install-ssm-agent
Install SSM Agent on EC2 instances, and on-premises servers and virtual machines (VMs), to enable AWS Systems Manager to update, manage,and configure these resources.
Pretty sure I’m wrong about the Instance Profile — You don’t need that. I have a module written around ssm-agents, so I should remember these things haha.
Ah, I think I’ve cracked it - some of my instances didn’t have the correct IAM policy.
Ah what was the IAM Policy they needed? I was looking back at my module and thinking they didn’t need anything…
I’m using it with cloudwatch so I needed both of these
"arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore", "arn:aws:iam::aws:policy/CloudWatchAgentServerPolicy",
Aha yes — AmazonSSMManagedInstanceCore
Beware the AmazonSSMManagedInstanceCore policy, it gives access to all SSM parameters.
Is that not what I need to use SSM with those instances?
@Harry It is. @randomy is just saying it’s pretty permissive which can be a bad thing. If that sounds scary to you (probably if you’re in a large org) then you can look at the underlying policy and pull it apart. I’d only do that if you’re worried about security / POLP / etc within your org / team.
Ah ok, good to be aware of but I’m definitely at the scale where I’m not going to worry too much about that. I’m the only one doing any ops work here.
yep, that’s what i meant, thanks. a colleague of mine found that this policy worked: https://gitlab.com/claranet-pcp/terraform/aws/tf-aws-iam-instance-profile/-/blob/master/ssm.tf#L42-68
plus this if you want to use session manager: https://gitlab.com/claranet-pcp/terraform/aws/tf-aws-iam-instance-profile/-/blob/master/ssm.tf#L109-124
holy smokes, why on earth does ManagedInstanceCore have GetParameter[s] ? argh… sometimes i hate the aws managed policies so so much
2020-06-18
Regarding fluent-bit pushing logs from ECS to Datadog, we noticed there is a log key being used for every log entry. Is there a way to rename this to datadog’s expected msg key ?
I’m hoping I won’t have to create my own fluent container
Id like to use an environment variable if possible
Worst case scenario, I have to use a custom fluentbit configuration which I should be able to store in S3 and retrieve easily upon starting a new task
I'm using a fluent-bit sidecar in ECS to ship logs from my app to datadog. I want to use the msg key that datadog expected and I've been seeing the log key coming from fluent. Is there a wa…
Are you importing your logs as JSON?
yessir
I believe that is done by using this in the firelens config
"config-file-type": "file",
"config-file-value": "/fluent-bit/configs/parse-json.conf"
If you have it coming in as JSON, I think you need to remap the values in the log config in 
In my case I had to run a simple grok pattern that parsed the log as JSON. When you do that, DD will identify all the properties of the log as metrics you can add as columns in the log explorer
I believe that is done by using this in the firelens config
Yep, I was thinking about using an s3 conf file if I cannot use an env var to remap the key
Once they are separate metrics you can remap them in DD
If you have it coming in as JSON, I think you need to remap the values in the log config in
Have not considered this. Would this affect all services ? I wonder if it would be better to do it in fluentbit or in datadog itself.
In my case I had to run a simple grok pattern that parsed the log as JSON. When you do that, DD will identify all the properties of the log as metrics you can add as columns in the log explorer
Once they are separate metrics you can remap them in DD
that’s really good to know. I will investigate further
This is the message mapper ui. Go to Logs > Config then create a pipeline (filtering for your apps logs). All logs the filter catches will run through the pipeline and be remapped
2020-06-19
2020-06-21
Anyone here use Client VPN with Transit Gateway? It doesn’t look like Client VPN is supported as a transit gw attachment. So I’m trying to think of creative ways to make it work.
No experience with Client VPN, and this will most likely kill the way you setup security; I think you can create a NAT instance in a routable transit gw subnet, in which you MASQ the VPN traffic through.
2020-06-22
Did someone here already run the a1 instances with eks ? How does it full to run k8s on arm?
Hello there ! Does anyone know how to enable S3 access logs to a bunch of S3 buckets (100+) I don’t want to go one by one through the AWS UI ?
Seems like the aws cli does not have an option for doing that
Thanks @bradym !!!!
Happy to help.
Interesting / odd that there is no way for reversing that
’Cause I want to enable logging for a couple of weeks and then disable all the logging
You use the same command. From the manpage aws s3api put-bucket-logging help:
To enable logging, you use LoggingEnabled and its children request elements. To disable logging, you use an empty BucketLoggingStatus request
element:
<BucketLoggingStatus xmlns="<http://doc.s3.amazonaws.com/2006-03-01>" />
Hmmm interesting
Thanks again !
Hi folks - I have general question on AWS networking. Is there any limits on how many packets per seconds allowed for a AWS ENI?
No implied limits other than physical limits of the networking infrastructure.
Actually I tried to pump more than 150K packets per second(pps) with 128Bytes frame size to the instance type c5a.4xlarge(supported up to 10Gbps speed) . I got only around 100K pps inside the aws instance.
2020-06-23
Does anyone have an idea why SSL connections to Influx Cloud would get stuck establishing much more if done from EKS pods running on nodes in private subnets, with aws-vpc-cni, as opposed to EC2 instances with public IP addresses?
Public EC2 instances have default sysctl net.ipv4.tcp_keepalive_* settings.
anyone have thoughts on cost cutting of fargate services ?
we’re using a ddagent and fluentbit sidecar for each of our apps
we’re constrained by the task definition mapping of fargate services, such as 1024 cpu has to use minimum of 2048 mem
I will say they stupid answer you are not hopping for but use ECS+EC2
ah crap. ya thats not what im looking for as we’re migrating off of that haha
we’re simultaneously “rightsizing” these tasks to reduce costs
we calculated that fargate when it gets close to the limit of cpu unit and memory it is 3 times more expensive than ecs+ec2
oh wow
we run docker with 300 GB of memory
we’re in the middle of cost comparing now and willing to pay extra to forego managing our own cluster instances
Even with the recent-ish price changes?
maybe now is about 2x
I keep looking at it because I’d rather not have to manage ECS but my VP would slam the door if I told him it was 2x the cost of our EC2 instances
do your math, I could be wrong too, I did this last year
as a test with real data, you could spin up your most expensive ECS service in both fargate and ec2 and have 50% of production traffic hit 1 and hit 2
then use cost explorer to see which costs more (provided each have different tagging)
Back in Jan 2019 when they did the last price cut AWS blogged this, which is why I keep looking at it now
If your application is currently running on large EC2 instances that peak at 10-20% CPU utilization, consider migrating to containers in AWS Fargate.
sure, if it uses less than 16GB of ram and whatever is the limit of cpu units
if you are using ebs or efs need to watch that out
they just rolled out EFS support
but I do not know about EBS, I do not think is possible
Oh yah, in my case I’m using a lot of t3 nano/mico/small instances for our EC2 apps
its my goal to get the company into containers but its slow and the price of the managed services makes my bosses unhappy
Prices have gone down a couple times in last year. But new options have been added as well. Savings plans discounts apply to fargate and spot for fargate is available. We just cut $50K by moving services from fargate to fargate spot
interesting
how does one enable fargate spot with terraform ?
yah kind of a secret squirrel definition … their docs don’t mention what the potential names for the capacity provider are
aws_ecs_cluster has a default_capacity_provider_strategy and aws_ecs_service has a capacity_provider_strategy that can set the capacity_provider to FARGATE_SPOTcutting costs further.
yah kind of a secret squirrel definition … their docs don’t mention what the potential names for the capacity provider are
yep. looks a bit confusing from the docs but that issue makes it look pretty easy
We had to create new ECS clusters to get the fargate spot capacity provider defined. Don’t know if they fixed that. But easy to setup services to use it
have you all noticed any issues betw switching from fargate back to ec2 ?
we were thinking perhaps it would be as easy as changing the launch type from fargate back to ec2
this was thought of as a failsafe if the few services that we’re POCing have a significant cost over the EC2 launch type.
There are a few changes needed. How many depend on your config on the EC2 side. But it is all straight forward and consistent. Assuming EC2 side is consistent
one thing that comes up is that before going to fargate, our ec2 containers would log to cloudwatch whereas our fargate containers use the ddagent and fluentbit containers to send logs to datadog so we’d have to remove those too
You can have fargate log to cloudwatch or use fluentbit sidecar. Again easy to change in task def. If you’re doing ddagent as a sidecar, that will also be easy. If you have it in your app image, this just got outside of terraform’s complete control
ooh, does anyone have a pointer to a KISS implementation of a elasticsearch/kibana logging sidecar?
@RB if you want a code sample for enabling Fargate Spot I can provide
Yes please! @Joe Niland
@RB
Cluster example:
resource "aws_ecs_cluster" "fargate_cluster" {
count = var.enabled ? 1 : 0
name = var.cluster_name
capacity_providers = ["FARGATE_SPOT", "FARGATE"]
default_capacity_provider_strategy {
base = 0
capacity_provider = var.default_capacity_provider
weight = 1
}
setting {
name = "containerInsights"
value = var.container_insights_enabled ? "enabled" : "disabled"
}
lifecycle {
create_before_destroy = true
}
}
cluster .tfvars:
default_capacity_provider = "FARGATE_SPOT"
container_insights_enabled = false
ECS Service example (from https://github.com/cloudposse/terraform-aws-ecs-alb-service-task/blob/master/main.tf#L253)
# this is within resource "aws_ecs_service" "a_service" {
dynamic "capacity_provider_strategy" {
for_each = var.capacity_provider_strategies
content {
capacity_provider = capacity_provider_strategy.value.capacity_provider
weight = capacity_provider_strategy.value.weight
base = lookup(capacity_provider_strategy.value, "base", null)
}
}
Service .tfvars:
capacity_provider_strategies = [
{
capacity_provider = "FARGATE_SPOT",
weight = 1,
base = 1
}
]
Terraform module which implements an ECS service which exposes a web service via ALB. - cloudposse/terraform-aws-ecs-alb-service-task
1base is minimum tasks per provider
weight is a proportion, so you could put 1 for FARGATE and 1 for FARGATE SPOT and 50% of your tasks will run on each.
Amazon ECS capacity providers enable you to manage the infrastructure the tasks in your clusters use. Each cluster can have one or more capacity providers and an optional default capacity provider strategy. The capacity provider strategy determines how the tasks are spread across the cluster’s capacity providers. When you run a task or create a service, you may either use the cluster’s default capacity provider strategy or specify a capacity provider strategy that overrides the cluster’s default strategy.
Are you able to use API Gateway to point directly to Target Groups (specifically, I’m curious about getting to ECS services WITHOUT using a load balancer in front of ECS)?
Why don’t you want to use a load balancer ?
To support a crazy architecture
But actually, we came to a different conclusion, so this is not needed anymore
(where we are putting load balancers in front, haha)
Hey Guys aws rds (mariadb10.4) root user by default cant give GRANT ALL permission how can we make it do that I need grant all permission
Are you using a managed instance? If so then it makes sense that you wouldn’t be full admin on that DB instance.
2020-06-24
Does anyone have SAP-C01 dumps to share ?
For anybody using ECS — I released a side-project over the weekend that may help you avoid writing an ugly bash script in the future: ecsrun. It’s a small golang CLI tool that provides a wrapper around the ECS RunTask API and it aims to be much more easily configurable than invoking the AWS CLI yourself. It enables invoking admin tasks like database migrations, one-off background jobs, and anything similar that you can cram into a Docker CMD. I’m eager to get some feedback if anybody ends up using it!
Easily run one-off tasks against a ECS Task Definition - masterpointio/ecsrun
2@Joe Niland If you get a chance, check out this project. Would appreciate your thoughts if you end up getting to use it.
Not suited for your node project because why not just invoke RunTask through the native AWS JS SDK but it might help you out elsewhere!
Easily run one-off tasks against a ECS Task Definition - masterpointio/ecsrun
That’s a great project. I’m thinking of various ways to use it.
One tool I’ve been looking for is one to update a task definition’s single container definition’s container image. Currently were using ugly fabfiles that do this that are copied and pasted everywhere and they typically recreate the task definition instead of reusing the one in terraform.
As in update the image tag on the container def? So you don’t need to point to latest?
Right. If we point to the latest in the task definition and the latest image is updated, would it auto update the running task?
One thing we’d lose is the ability to know what version of our container is currently running. Its a bit hard to decipher with latest tag, no?
Nope — You need to invoke update-service (I think that is the API name).
And the latest tag is an anti-pattern anyway. It’s a bad practice.
Yeah, latest tag is crap. Don’t use that
Ya we dont use the latest tag
Not sure if were speaking about the same issue
So you need something to invoke after you push the image that updates the task def to use the newest image tag and then invoking update-service to update your currently running tasks.
Ah yes. I suppose we could continue using the makefile to build and push the container then replace the fabfile with the update service command to update our running task
Yeah. You still do need to update the task def to point at the new image tag. Invoking update-service is just the piece that will actually deploy that new revision of your task def.
lol then back to square one
current process
- Makefile to create new build of docker and upload it
- copied and pasted fab file that registers a new task definition by recreating it and then runs update service to trigger an update of the task
new process that would be cool
- Makefile to create new build of docker and upload it
- community maintained script that will take an existing task definition, update a specific containers container image, recreate that task definition, and run update service to update the running task
the #2 from the new process would replace our wonky, drift ridden, copy pasta fabfile
it would also allow us to maintain our task definition in terraform while the separate script can reuse its params while only replacing the specific container image
@Matt Gowie I hope this makes sense
Yeah makes sense for sure. That’d be an interesting project — Basically a tool to do a ECS deploy given a task def + service. I’ve written a bash script around that too, but just never wanted to abstract it away from reuse.
so ive been thinking more about this….
why shouldn’t we use a latest tag for the docker image in our task definition? if we did, then to update the service would be as easy as running the update-service command with --force-new-deployment
we could update the docker labels in the Dockerfile itself for a git ref versioning so that could be a way to figure out what version hash is actually running
besides hitting the /status/version endpoint across out APIs
Others can explain better than I can: https://vsupalov.com/docker-latest-tag/ https://blog.benhall.me.uk/2015/01/dockerfile-latest-tag-anti-pattern/
Frequent issues and misconceptions around Docker’s most used image tag.
ah ok, so i skimmed through this. so instead of calling the tag latest, we could call the tag by it’s env name like production, no ?
I just learned it the hard way on a client project where I was using latest. It was a stupid mistake on my end, but had my CI / CD pipeline for production building my image, pushing it to the registry, asking for approval to deploy to prod, and then doing deploy to prod if approved.
We had a release candidate waiting for approval and during that time, our containers had died and restarted. That inadvertently triggered the release as the task def was pointed at latest and therefore the build that was a release candidate was deployed which the client wasn’t ready for and caused problems.
would that still be regarded as an antipattern if this tagged was used in the task definition ?
ah ok i see how that can be problematic
I think that’d still be a pattern as my above problem still would’ve exposed itself.
Yeah and then rollbacks require re-tagging the old image as latest or doing a full build of the old code and pushing that as latest
Kinda weak.
i wonder if using a different tag than latest and having strict controls in place to prevent pushing those tags can allow my proposed setup to work without causing headaches of accidental deploys
Possible. One of the problems with latest is that it’s implicit. I believe images get tagged that way in most repos regardless if you explicitly tag it that way or not.
right so we can easily solve that, at the very least, by renaming it to the env like production
Or docker tags newly built images implicitly with latest. That is the issue.
then if we can put in a policy for all engineer roles to be unable to overwrite this tag, then create another iam role used by cicd that does overwrite this image tag, then it should be safer, no ?
Yeah that solves some problems. But still gives you problems with rollbacks. Means you either need to tag your rollback image with production and push it or you need to rebuild with your old code possibly.
we could tag our images twice. once with the first 7 chars of the git ref or a version number and once with the env production and push both up
that would allow us to rollback fairly easily
Yeah, and you should definitely do that regardless.
we do
i wonder if there is a project out there that creates skeleton repositories for these kinds of sane defaults so you dont have to always reinvent the wheel. someone has certainly solved this before.
I would bring this up as a #office-hours question. I think it’s a good one. I’m sure Erik and crew have opinions / war stories with this
cool. ya i havent joined the office hours yet.
The first I heard of latest being an anti-pattern was from Zach L sometime a bit back during office hours. Then it bit me.
Link this convo over there and we’ll chat through it next week. Will probably spark some interesting conversation as we obviously just chatted for a bit about it.
If you can’t join the office hours, you can always listen / watch after the fact.
 1
1@Erik Osterman (Cloud Posse) and team suggested this tool
https://github.com/fabfuel/ecs-deploy#deploy-a-new-image
and the following approach
- setup a tag input for the terraform module to pass to the container definition
- when building a new docker image, continue to only tag it with something unique like the first X chars of the git log ref
- copy that new tag and pass that to the module using
terraform apply -auto-approvethat should be good.
Powerful CLI tool to simplify Amazon ECS deployments, rollbacks & scaling - fabfuel/ecs-deploy
we could use that tool in lieu of terraform with this command as it will only update a specific container’s image in our task definition
ecs deploy my-cluster my-service --image webserver nginx:1.11.8
We have a node.js worker that runs jobs that can take hours and don’t tolerate interruption. It has a graceful shutdown function which is called when catching sigterm and sigkill.
We’re currently running the worker on ECS Fargate.
We want to make sure the containers aren’t killed mid job. With the standard ECS deployment methods this isn’t possible.
Is anyone aware of a good way to achieve this? I’m looking into the external ECS deployment controllers. Perhaps Fargate is not a great choice for this however the client doesn’t have an Ops team, so if there’s any way to use it that’d be ideal.
Why is fargate a problem?
Is the task being killed at some point?
Hey PePe - sorry meant to say - the task will be replaced during a deployment based on the standard ECS deployment controller behaviour
also we’re using Fargate Spot in staging so that can have an impact too I think
Fargate also has a 120 second max stop timeout after which it kills the container AFAIK
So the issue is that you’re doing a service deployment and it’s killing your running jobs, which you don’t want? Or is it that you’re using Fargate Spot and the tasks are being killed because they’re spot instances and AWS is reclaiming them? Both?
Yes, both, but mainly the deployment. BTW, I am now realising that we won’t use Fargate Spot for this particular ECS service!
If you invoke via the RunTask API then it should live outside of the Service lifecycle and a deployment shouldn’t affect it.
And I wouldn’t think Fargate Spot would be the best choice for jobs that you’re hoping to keep.
How are the jobs invoked? Through a single service or are they scheduled?
It’s a node.js service managed by PM2 inside the container. The jobs are managed by Agenda and stored in Mongo. This architecture preexists AWS hosting.
Lightweight job scheduling for Node.js. Contribute to agenda/agenda development by creating an account on GitHub.
Thinking about how we could orchestrate RunTask in this case.
Huh got it. When a new job gets posted is agenda just scaling a service or is it invoking RunTask?
Or is agenda a long running service and it’s invoking jobs internally — Something similar to celery or sidekiq?
Yes that
it’s just running in a loop inside the node process
I don’t think I can move away from using it within this project scope
Got it got it. Okay — This might be hard to implement but I wonder if you could spin up a new service each time, let the old service finish its currently running jobs, launch a new service which is then the only one allowed to read from Mongo / launch new jobs, and then when the old service completes its jobs it shuts itself down.
Not sure if there is an ECS native way to deal with it.
Interesting. I had a similar thought using cloudwatch events to schedule the runs. It would run and pick up whatever jobs are waiting.
From what I can see your idea (or close) could be done with external deployment controllers
AWS support sent an example of doing blue/green with Jenkins - https://github.com/aws-samples/ecs-bg-external-controller/blob/master/Jenkinsfile
This repo contains the sample code for the blog post: https://aws.amazon.com/blogs/containers/blue-green-deployments-with-the-ecs-external-deployment-controller/ - aws-samples/ecs-bg-external-contr…
Huh. I mean yeah, depending on how complex things are you could similarly update all your jobs to invoke RunTask and then they’ll spin up new tasks for each job and the jobs on the agenda server will complete quickly so you won’t have to worry about interrupting them when you do a service deploy.
I like that idea. I will look into whether we can integrate that somehow. Appreciate the input!
I think your idea is good because we don’t have to mess around with deployment controllers, which doesn’t look simple at all
Yeah that groovy code is non trivial. Ugh Jenkins, I’m glad I have no work with Jenkins right now
Hahah agreed
It’s been a while for me but I am talking to a client who may need some Jenkins pipeline updates
we have super long running job inside ECS as sidecards, not fargate but we used to set the Minimum healthy percent 100 and Maximum percent 200 and that way you can have running two versions of a task
we have sidecards as cron job basically
@jose.amengual how are you deploying the job containers?
yes
we deploy 3 containers at the same time
1 is the initial sync tas that sync s3 and then dies ( they run in order)
then we have the cron, that stays running for ever
and then the app that runs until a new deployment happens
I see and are you using the runtask API or codedeploy or something else?
basically a Go app we build that calls the standard api
it does not do any magic, it basically fires a deploy
the trick was on the deployment %
Ah I see
@jose.amengual Does your team primarily use Go?
I am thinking I need to do something similar because the standard ECS deploy switches the primary task as soon as the new one becomes healthy
you could have task in the same service and deploy independently ?
on service, two tasks same app
Yes we could. Sorry, I said task but I think I mean https://docs.aws.amazon.com/AmazonECS/latest/APIReference/API_Deployment.html.
The details of an Amazon ECS service deployment. This is used only when a service uses the ECS deployment controller type.
I am going to play with the percentages
Thanks PePe
Actually where do you run your go app from? CI process?
jenkins yes
I ended up not using ECS deployments for this service. Instead, within CodeBuild, I downloaded the latest task definition, and used jq to modify the image name/tag. Then registered this new task definition and used run-task to create new tasks. To kill off the old tasks, my client modified the worker code to use stop-task to shut the oldest tasks down when they see that there are more tasks than MAX_TASKS (which we stored in param store.) Hack? probably, but it is working
Hey is this what I think it is ?
Update AutoScalingGroup & launch template in place without the hassle or swapping them, or tweak around with terraform prefix / create before destroy ?
Anyone knows if Terraform will support this anytime soon in the V13 ?
fwiw, support for this is totally separate from tf 0.13, just a new resource/feature in the aws provider. Here’s the issue to track for the release… https://github.com/terraform-providers/terraform-provider-aws/issues/13785
Community Note Please vote on this issue by adding a reaction to the original issue to help the community and maintainers prioritize this request Please do not leave "+1" or other comme…
you’re completely right about the provider, good point
thanks for linking the issue
2020-06-25
Does anyone know the password for the ‘centos’ account in the Centos AMI? I want to remove NOPASSWD from the sudo function.
just set the password before removing NOPASSWD
Don’t I need to know the existing password before I can do that?
Oh.. I can sudo passwd. I had forgotten.
idk if this has been mentioned but this really makes a difference when all i get is an instance id from aws in an email
https://github.com/bash-my-aws/bash-my-aws
$ AWS_REGION=us-east-1 instance-tags i-snip
i-snip env=snip snip=snip snip=snip snip=true snip=0.56 team=snip Version=snip service=snip CreatorName=snip aws:ec2spot:fleet-request-id=snip CreatorId=snip snip=snip
Bash-my-AWS provides simple but powerful CLI commands for managing AWS resources - bash-my-aws/bash-my-aws
2020-06-29
Hi, does anyone know how “real time” the AWS Cost Manager is? For example when I launch an ECS task, should I see the cost already after 1h? Or hast it some delay - for example I need to wait 24h until I see the cost appear in AWS Cost Manager?
https://aws.amazon.com/aws-cost-management/faqs/
Q: How frequently is the AWS Cost & Usage Report updated?
The AWS Cost & Usage Report is updated at least once per day. An updated version of the report is delivered to your S3 bucket each time an update is completed.
AWS Cost Management Frequently Asked Questions (FAQs) - Tools to help you to access, organize, understand, control, and optimize your AWS costs and usage.
thx @Maciek Strömich . This relates to AWS Cost & Usage Report. Do You know if the 24h also apply to AWS Cost Explorer API?
AWS Cost and Usage Report Service is part of Cost Explorer API.
my guess is that both follow the same data freshness principles
I thought:
• AWS Cost & Usage Report - reports stored on S3 - more static
• AWS Cost Explorer API - more real time HTTP API
AWS wants 0.01$ per AWS Cost Explorer API request, so I thought one could expect more
Kind of worried about task definitions in ECS, is there a maximum number they can go up to? Do I need to worry about this?
nah, dw about it
according to https://docs.aws.amazon.com/AmazonECS/latest/developerguide/service-quotas.html
Revisions per task definition family is 1,000,000
Excellent. Thanks.
since it’s a default quota you could probably request an increase. this is per TD tho so you’d have to be really abusing task definitions to have to increase it lol
Haha, yeah. :)
2020-06-30
@channel what would be your choice for building a devops pipeline , use gitlab and go with a single vendor approach or use a combination of tools to keep it flexible? Thanks in advance
our choice is what we’re currently using.
we use buildkite. basically if a pr passes tests/linting and is approved by github CODEOWNERS, once it’s merged, the code is built into a container, and deployed on to ecs with zero downtime.
@nileshsharma.0311 Make a pilot project. Evaluate in a month. You need real world experience to decide. Other people’s experience can provide a guide but it is your skills that matter.
@David Medinets thanks for this one
are there enough people in this community to warrant a #cloudcustodian channel ?
@RB how’s your experience with it ?
im proficient with it. been using it for a couple years
but i do fall into snags where i need to hit up their gitter
or stackoverflow/reddit/etc
it works but it can be a pain in the ass to configure and setup
So the deployment part is kinda cumbersome
is that a question or statement
No just thinking out loud , obviously it depends on the skill level
Can you provide some input to my question , it’s in the channel, just above yours , it would be helpful
not sure how that related to cloud custodian but kk
¯_(ツ)_/¯
custodian isn’t hard to deploy. that’s the easy part. it’s hard to configure.
Gotcha
Yeah it wasn’t related but just needed some feedback
I ran it in a few minutes from a docker command without issue. Is there something more complex to it? Couldn’t you just set it to run periodically in fargate container and be done?
the deployment to a lambda or running it from the command line is dead simple
how would you rate cloudcustodian vs the services from aws like config, control-tower etc?
custodian doesnt do control tower
custodian does leverage aws config tho
yes, I know - but the tools kind of do the same
so you could roll your own with CC or go with AWS services ($$)
kindof. custodian will configure aws config for you using the yaml file. it doesn’t touch upon control tower as its not in its purview.
here are the different modes where you can configure custodian https://cloudcustodian.io/docs/aws/aws-modes.html
the only way you can use cloud custodian without aws specific services like lambda is by running it in a cron job like jenkins from the cli but you give up a lot of functionality
so you can configure your own lambdas to emulate custodian or create your own rules in aws config manually, but it’s a lot more convenient with cloud custodian because of its simplified yaml language
@David J. M. Karlsen thoughts ?