#aws (2020-09)
 Discussion related to Amazon Web Services (AWS)
Discussion related to Amazon Web Services (AWS)
Discussion related to Amazon Web Services (AWS)
Archive: https://archive.sweetops.com/aws/
2020-09-01
Hi, Is GuarDuty required for CIS Benchmarks for AWS ?
anyone knows ?
https://aws.amazon.com/bottlerocket/ BottleRocket has gone GA
Anyone tried S3 upload from browser directly using POST policy - to a bucket with AWS Signature Version 4? I have the code which generates policy and signature - it’s working with old buckets, but not anymore with new ones, as AWS made required sig-v4 for new buckets after June2020. My form contains: <input type=“hidden” name=“x-amz-algorithm” value=“AWS4-HMAC-SHA256” /> still getting “The authorization mechanism you have provided is not supported. Please use AWS4-HMAC-SHA256.” Any idea?
Is enabling key rotation on an existing kms key safe?
any breaking changes?
it depends on whatever is using it if it can handle the rotation
in our case it will be somewhat catastrofic
no way, really ?
i pinged aws support and they said that it wouldn’t change the arn or alias the rotation is completely done in the backend. it doesn’t even require re-encrypting data.
id like to know why it would be catastrophic for your setup in case it also affects mine
the arn does not change?
well I thought the arn will change if you rotate it
if that was the case then it will ber catastrofic
the arn does not change

I though it did
i’ll let you know what happens after we enable it
lol
it’s the key material that changes, nothing else about the key changes. Yes, you should rotate.
2020-09-02
what’s a good strategy for turning on and off agents on a golden ami using tags ? cannot find any blog post on it
we have way too many AMIs and it’s due to combination of installing agents
id like to switch this so we can use a single AMI, install all the agents, turn them all on by default, and turn them off using tags
Bake a script or config mgmt agent into the ami, set it to “run once” at startup, read the tags and apply the desired state?
Or maybe use ssm documents/automation?
ah interesting so maybe i can configure something like this.
I’d like to schedule a command to run after reboot on a Linux box. I know how to do this so the command consistently runs after every reboot with a @reboot crontab entry, however I only want the co…
can an ssm document run on all new instances only once they are brought up ?
cloud-init also has a “run once per instance” feature… pretty sure you can drop a script in the directory and it will run it. linux-only, of course
+1 to cloud-init and tags
i’m pretty sure ssm could do it somehow, but i find the service to be highly confusing, so it’s usually my last choice
ah ok, ill stay clear of ssm for now then regarding the enablement of agents
i’ll try the cloud-init and tags method. thank you everyone.
im surprised there isn’t a blog post on this but guess we cannot rely on blog posts for everything
someone has to be first! go for it!
AMI tags can’t get read cross account fyi, if that changes your approach
yes that’s true. zach, you can configure a lambda that copies the tags across accounts
i have not configured it, but it seems like a good method to keep tagging consistent.
i also did not mean tags on the AMIs itself but on the EC2 itself
so if you spin up EC2 with tag datadog_agent=false , the cloud-init script can run, check the ec2s tag, if it is true, then install the agent, if it is false, then do not install
Oh sure if you are copying the AMIs that works. We keep the AMIs in a single account and pull from it. It caused some problems when we tried to do something clever, only to find it was not so clever once we went to the other account
Yes I was talking about ec2 tags retrieved via metadata
gotcha
ssm association for sure based on my quick scan
SSM isn’t intuitive. i should do a blog post on this as i found it super confusing and have written a bunch of internal things on it.
Basically ssm association targed to tag can be just like cron job, or can be a one time bootstrap. I use it to bootstrap 200+ instances so anything newly created gets agents installed, and i can also reapply on a whim.
the key is that you ensure your docs are idempotent so you feel safe running at anytime.
You can do an automation dog for adhoc runs and execute against a tag with a few clicks or automatically too.
Just be warned it’s not super intuitive on the naming, that’s what makes it tough.
I have basically zero dependency on user data or any init now. This means I can update my scripts independently of the infra to patch/fix issues too.
My packer pipeline also runs the same scripts pretty much so my effort for better tooling also helps me try to move stuff to better golden images (i’ve given up on immutable at this time )
That’s fantastic sheldonh
Do you use any terraform modules when creating your ssm docs?
I like to post blog posts on issues people are asking about so I’ll do my best to
I use a mixture to create my SSM docs.
What are some tips with ssm and creating a run once doc?
If I was creating something in the future I might explore the template file
Right now I use Powershell to generate the docks from native Powershell scripts so I can let them for format and so on.
And the build script output is a yaml doc. Terraform manages it after that. Probably better way to do… But it worked for generating docs as code at the time. Can even use vaporshell and validate syntax.
Probably would first look at template file in future
What you need to understand about the docks is there is no concept of a run once doc.
They are just docs. It’s up to you to execute it or to link it up to an association so that it can run automatically
ssm association with no schedule applied will automatically apply on a new resource or existing resources that haven’t yet had it run and that’s it. Unless you re deploy the doc
Once you add a cron then it’s running on a schedule. Otherwise it is already a 1x run.
Will catch up tomorrow in case you have more questions
Think of SSM as a perhaps less featured puppet, chef etc. Some bugs and all but overall I’ve had a reasonable experience. It’s not super intuitive and like any aws service gotta figure it out
Thanks a lot Sheldon! I’ll try this out. Ssm seems like a good strategy
Does anyone have a cool way to generate the equivalent of a temporary s3 “dropbox” for a client to securely upload with a token, and tear down? I was thinking of just doing a AWS Automation doc that would create a randomized s3 bucket, create scoped credentials for just that bucket and upon finish tear it down. This AWS SSM Automation doc would be a self-service dropbox option for larger database transfers and all.
is there a better way to do this?
I’ve used Firefox Send many times. Very happy with it
“It was launched on March 12, 2019 and taken offline on July 7, 2020”
I’m talking about enterprise clients with a sensitive database that miught be 100GB. They need to drop it over to us and S3 is preferred destination for us. I want to do the equivalent of an upload a file only to a specific place with an access token only and minimize the need to have them run scripts if possible.
If no online service with s3 to do this, then maybe a golang cli app that takes a single run token, askes for a file path, and does an upload to a desiginated s3 bucket only might be a cool way to do it, Just mulling over ideas
I’ve not done it myself, but you could run your own firefox send instance https://github.com/mozilla/send
Simple, private file sharing from the makers of Firefox - mozilla/send
Not sure what this is getting me over some s3 solution? I still have to get it to s3 right?
firefox send supports using s3 as the file store
interesting. thanks for this i will review further then
aws-vault just released v6, looks like some good stuff in there… https://github.com/99designs/aws-vault/releases/tag/v6.0.0
Added Support for AWS SSO #549 docs Support for Yubikey TOTP #558 docs A shell script for adding a Yubikey to IAM #559 aws-vault exec –ecs-server starts an ECS credential server offering many adv…
2020-09-03
anyone use this for okta as a replacement for gimme-aws-creds from nike?
https://www.okta.com/blog/2020/05/how-okta-aws-sso-simplifies-admin-and-adds-cli-support/

looks promising as it simplifies the process
aws sso has its fans, but i still can’t get past the limited ability to define granular policies with per-account references to resources/ids. closest i can get to is a permission set that only allows assume role to a more constrained role
We’ve been using https://github.com/godaddy/aws-okta-processor and really liking how it works. It’s a nicer workflow than aws-okta was.
Okta credential processor for AWS CLI. Contribute to godaddy/aws-okta-processor development by creating an account on GitHub.
there are so many methods to do this. it would be ncie to have a comparison of all of them
ideally we’d want granular permissions like iam role perms as we do now.
and be able to click a button in okta to auto login to a specific account in AWS
aws sso has its fans, but i still can’t get past the limited ability to define granular policies with per-account references to resources/ids. closest i can get to is a permission set that only allows assume role to a more constrained role
could you explain more on this limitation ?
Gimme creds by Nike works great
Gimme creds by Nike works great
how do you open aws console using nike’s tool ?
plus nike’s tool came out before the sso integration. wouldn’t the new solution be better than nikes ?
aws sso has its fans, but i still can’t get past the limited ability to define granular policies with per-account references to resources/ids. closest i can get to is a permission set that only allows assume role to a more constrained role
two links to forum responses i posted, that might get at the underlying issue
• https://forums.aws.amazon.com/thread.jspa?threadID=282793&tstart=0
• https://forums.aws.amazon.com/thread.jspa?threadID=312303&tstart=0
wow. aws sso users cannot assume a specific role !?
it’s more making it automatic… and that’s a workaround to a limitation of permissions sets. i either have to create a permission set for every combination of account/role in order to reference the account id (think arn) or a resource id for policy resource-level restrictions, or create a permission set per role that only allows assumerole to the “real” role in the account
ah i see the issue. so the workflow is…
- idp (like okta) click button to login
- aws console opens up but is not using a specific role
- manually assume role
xyzthrough console this requires the rolexyz‘s policy to have every sso user enabled to assume it
i don’t think the last bit is an issue, far as allowing people access to accounts they shouldn’t have. more just that the workflow is burdensome on the user. a workaround for the limitation of permissions sets would be for aws sso to do step 3 itself and perform the assume-role
idp (like okta) click button to login
aws console opens up but is not using a specific role
That’s how our okta/aws saml federation works anyways but thats so that you can choose particular roles for things. You get a little selection menu of which account/role you want to use, and only the ones that your okta groups map to are visible.
That’s the okta->iam workflow, which is great. okta->aws-sso is different and subject to the limitations of aws-sso
Ah
unfortunate because my teams really dislike having to use a tool at the CLI to authenticate before using the AWS CLI
I just told them to suck it up because security is hard
aws-okta-processor integrates authentication into the aws-cli usage, so the login is inline
anyone here knowledgeable about Envoy proxy?
if I had an existing service in AWS
with an alb
and the dns of the service is https://pepe.null.com and this service runs on ECS and is a simple webapp with a mysql backend
if I wanted to add an envoy proxy to my task def ( with or without app mess)
does envoy requires to know what is the hostname if the request that this webapp supposed to respond to?
or just by adding the proxy I could just getting it going with minimal config like a listener ?
I want to know what is the minimum configuration required to have it running
and then plug in to other services
I’ve been working on it just yesterday , Im not there yet but but this is a great resource https://youtu.be/D0cuv1AEftE
I saw that video, made me much more confused about everything
there is a lot of assumptions about microservices and service discovery
but moving from monolithic to this is what I want
2020-09-04
anyone knows of a way to identify if a user already has the “login-profile” enabled?
Is this what you’re looking for? https://github.com/aws/aws-cli/issues/819
We use several different profiles for uploading our static website to different environments, each environment has it's own profile. It would be nice to have a way to check if a profile is conf…
hmm not quite what im looking for, but turns out it’s just this: aws iam get-login-profile
What’s a good way to profile my AWS API usage? We’re hitting some RateLimitExceeded exceptions, and it would be great to start with data on what the calls are (you know, profiling instead of guessing). I’ve googled without success so far.
interesting idea… i don’t see anything on the aws side that reports on that… could you write those exceptions to Cloudwatch Logs, and use a filter or subscription to collect the events?
This is a good question. I would start with cw monitoring for “RequestLimitExceeded” on the AWS/EC2/API Namespace and then also make sure CloudTrail was on.
Hopefully when API throttling kicked in, I could go to CloudTrail 10 minutes later and see what was hitting often.
Haven’t tried turning on “RequestLimitExceeded” monitoring yet though - in the docs, it says you need to contact AWS support to turn it on:
This is an opt-in feature. To enable this feature for your AWS account, contact AWS Support.
i did see that, wasn’t sure if it was specific to just calls to the ec2 api…?
i think it is specific for ec2, but lots of services ride on ec2 - it still might give a good picture.
i’m quite certain that dynamodb has different api throttling limits than ec2, so i guess it depends on what you’re after.
for me, when i see “RateExceeded” in the AWS Console, I have a hunch it’s the EC2 API. too many describes* within a short period of time,
Thanks for the tips. I am going to tweet that, and unfortunately it’s Cognito not EC2. I’ll check if I can enable CloudTrail logging for Cognito requests
Anyone know a way to profile AWS API calls? When you get a TooManyRequestsException it would be great to be able to identify every call to that service, instead of just guessing. #AWSWishlist
Cloudtrail can give you some insights into what’s being called a lot (if it’s something that is logged by cloudtrail)
2020-09-05
2020-09-06
I’ve been troubleshooting an IAM policy , Objective - Give EC2 permission to add/remove security group rules , Inbound and Outbound , This is the policy I’m using , Funny thing is it works if I attach it to an IAM user and Use awscli ( I checked , the IAM user has no other permissions than what the policy grants ) , but when I attach an IAM role with same policy to ec2 , it doesn’t , does iam users and roles interact with aws differently , Thanks in advance :)
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"ec2:AuthorizeSecurityGroupIngress",
"ec2:RevokeSecurityGroupIngress",
"ec2:AuthorizeSecurityGroupEgress",
"ec2:RevokeSecurityGroupEgress",
"ec2:UpdateSecurityGroupRuleDescriptionsIngress",
"ec2:UpdateSecurityGroupRuleDescriptionsEgress"
],
"Resource": [
"arn:aws:ec2:us-east-1:acnumber:security-group/*"
],
"Condition": {
"StringEquals": {
"ec2:ResourceTag/Name": "$NameOfTheSecurityGroup"
}
}
}
]
}
and Instance profile = a profile attached to a instance
I think using instance profiles is not possible to allow the instance to modify it’s own security group since is very unsafe from a security prospective
Yeah I get that , the use case was there are some services exposed to the internet , the Only way around it is to give the guys using the machine add/remove rules on the fly and delete the 0.0.0.0 rule , since the users know what they’re doing and security group changes are very frequent so that was it
I figured we can only update them using the console or pragmatically
Thanks for the help
np
hi has anyone knowledge around the iam role association to pods through service-account , Im able to do assume the role (assume-role-with-web-identity) of the same account , but now I need to assume a role present in a different account, I already tried out with attaching assume-role policy to my role for that (role present in 2nd account ) and even editing its trust relationships. Thanks in advance
Troubleshooting IAM policies is a nightmare , use IAM policy simulator if that helps , in cross account access both sides have to agree and there shouldn’t be any SCPs denying the action ( in case you’re using scps )
no its working fine with kiam but facing access denied when assuming iam role via service-account.
2020-09-08
2020-09-09
AWS IAM Service Account assuming role in various other accounts in Terraform Cloud
Background: I have 8 AWS Accounts. I have 8 terraform cloud plans for deploying an IAM Service Account to each. Each get’s its own key.
I want to have
• create each of the service account users in a “home account”
• deploy the role for the service account to the remaining 7 (probably with group/role)
• in terraform cloud stop using the access keys (using data source lookup from terraform cloud state for the service account). Instead, I want to use assume role for all the other accounts. My main questions
- Anyone have a module laying this basic structure out?
- Is there a problem with using assume role with terraform cloud agents?
- I believe there are limitations when assume role is used, such as can’t update IAM role or something (haven’t gone to double check exact limits). Does this become problematic with using Terraform Cloud because things will start failing due to inherent limitations on an assumed role?
I’m ready to begin refactoring this from the access key approach to better design, but hoping someone else has laid this out in a blog post or willing to talk through it here or on call.
I did not know you could assume rule in terraform cloud
Well, I thought it is part of the provider SDK
I thought f TF cloud account was tight to each aws account only
it’s just one of the arguments you provide for assume role, so I “assumed” that that’s it.
No. Terraform Cloud agents (not self-hosted) are hosted by them. It has no knowledge of your AWS infra without what you provide. There is no “system level aws connection”
Basically I use a data source lookup right now for one workspace that manages service accounts and get data.terraform_[cloud.credentials.my](http://cloud.credentials.my)_user.access_key type of thing. I want to stop using access keys for each and instead use assumed roles since it seems to be a better practice
I have a primary/root account in our AWS Organization. I set up TF Cloud with keys to a user in the master account that has the ability to assume roles in the other accounts. We use provider defs like this, using a single set of AWS keys:
provider "aws" {
region = "us-east-2"
profile = "infra"
assume_role {
role_arn = "arn:aws:iam::${var.account_number}:role/OrganizationAccountAccessRole"
session_name = "Terraform"
}
}
This way, the account_number is passed into TF as a variable and used to assume this role in the subaccount.
Very nice. We aren’t using orgs right now. See any issues with this without org?
For someone that switches between accounts a lot, is there a better workflow with aws-vault than to remember to log out first and then use the cli to log in?
This doc has some info on using multiple browsers with aws-vault login https://github.com/FernandoMiguel/aws-vault-quick-guide
Contribute to FernandoMiguel/aws-vault-quick-guide development by creating an account on GitHub.
Ty, good tip
This question’s a bit different, but I need some opinions: https://twitter.com/iamvlaaaaaaad/status/1303727463072239616
Which one do you like more, A or B?
A: official AWS icons B: custom icons with no colorful backgrounds https://pbs.twimg.com/media/EhfFMgCXkAMwl8r.jpg
B - I like the consistency. The difference between the old/new icon styles in A makes me wonder if the new ones are third-party tools or something at first glance.
Which one do you like more, A or B?
A: official AWS icons B: custom icons with no colorful backgrounds https://pbs.twimg.com/media/EhfFMgCXkAMwl8r.jpg
Nonono, all the icons in A are part of the latest and greatest pack from AWS.
Some just have backgrounds, while others don’t. It looks like generic service icons have backgrounds, but specifics don’t. Like ElastiCache has a background, but ElastiCache for Redis does not
This must be what happens when design decisions are made by the same people who name aws services.
Colour is good, consistency in diagrams is overrated. Infra diagrams become outdated instantly anyway
I’d say A cause I prefer the color / official icons as well.
colors are good, but i would recommend making them lighter colors so the black is easier to read.
^^^ you can reply here, I just posted the Tweet link so I don’t have to copy/paste the photos
I know it’s a broad question , but how would you approach compliance in aws Let’s say ISO27017 or any other as a startup granted you’ve limited resources , may be share some of your stories :)
Hahaha savage , exactly what we were thinking
2020-09-10
We use a 3rd party agent that requires the ec2 describetags perms. We were thinking of creating a managed policy and attaching this policy to all of our roles since this agent will be installed on everything.
Is there a better way to solve this problem?
Datadog?
nah. it’s a security agent
we have a few of this policies attached to difference instance roles
a nice way to solve this could be using SCPs in AWS Organizations
it will be easier to manage
that is brilliant
i completely forgot about SCPs
Hello Guys, how do you manage the deployment for containers in ECS? I have one service and one task, how to utilize the ec2 instances because right now I have two ec2 instances but only one has my containers and the other empty. and If I make it one instance only will not able to deploy the new version.
Any reason not to go for Fargate? Takes a bit of the headache off of you.
I just want to try it out with ec2, but I’m not sure what is the best practice for it.
Ah, I don’t have much experience with EC2 mode.
mmm, so how does it work with Fargate?
With Fargate, you just care about the task definitions and the service. All the management of the VM is done by ECS for you.
So, start with the task definition.
Then, define the service, and use the task definition there.
And that’s pretty much it.
(depending on what the task is)
Oh, that’s cool. do you use any external tool for your deployment?
Terraform
Here’s one example (it’s not the best, because you should have all the resources defined in terraform and not use ARNs, but it’ll give you an idea):
resource "aws_ecs_task_definition" "streamdelayer" {
family = "streamdelayer"
container_definitions = file("task-definitions/service.json")
task_role_arn = "arn:aws:iam::123456789012:role/ecsTaskExecutionRole"
execution_role_arn = "arn:aws:iam::123456789012:role/ecsTaskExecutionRole"
network_mode = "awsvpc"
cpu = "256"
memory = "512"
requires_compatibilities = ["FARGATE"]
volume {
name = "chunks_efs"
efs_volume_configuration {
file_system_id = aws_efs_file_system.chunks.id
root_directory = "/"
/*transit_encryption = "ENABLED"
authorization_config {
access_point_id = aws_efs_access_point.aws_efs_mount_target.id
iam = "ENABLED"
}*/
}
}
}
resource "aws_ecs_cluster" "cluster" {
name = "streamdelayer-cluster"
setting {
name = "containerInsights"
value = "enabled"
}
}
resource "aws_ecs_service" "service" {
name = "streamdelayer-service"
cluster = aws_ecs_cluster.cluster.id
task_definition = aws_ecs_task_definition.streamdelayer.arn
desired_count = 1
platform_version = "1.4.0"
launch_type = "FARGATE"
network_configuration {
subnets = [aws_subnet.external.id]
security_groups = [aws_security_group.allow_ecr.id]
assign_public_ip = "true"
}
load_balancer {
target_group_arn = aws_lb_target_group.main.arn
container_name = "server"
container_port = 8000
}
depends_on = [aws_lb_target_group.main]
}
so every time you hard code the new version for the image in the task definition?
nope, I use “:latest”
Oh, nice that’s good way, but if you want to rollback you will have to build and push the old image to ecr?
Yes. I could always peg a specific version in the task definition and update that.
Cool cool, thanks man I really appreciate your help.
NP
Highly recommend Fargate Spot if you’re going to try it out, the normal on-demand Fargate pricing is pretty steep
this tool is nice https://github.com/fabfuel/ecs-deploy
Powerful CLI tool to simplify Amazon ECS deployments, rollbacks & scaling - fabfuel/ecs-deploy
we initially create the task definition in terraform and then use ecs-deploy tool to deploy
we use both Fargate and ECS+EC2, do I like any? No I HATE ECS but we use different deployment models
we use jenking to trigger a deploy in some cases with the task def managed in TF since it does not change much
and we created a Go tool to deploy in multiple regions since we have multi region deployments
ecs-deploy tool is nice an can do a lot for you
What do you hate about ECS?
Welcome to PaaS
You could run kube instead
it is hard to setup, you need to understand a lot concepts the make it run etc
and that is why we will be moving to K8s
I do not see any benefit in ECS that K8 could not do and K8s makes the deployments way easier
to be honest ElasticBeanstack is way easier than pure ECS and it does what most people will need
I think it’s a matter of use cases, as always. ECS can make things really easy if you don’t want to deal with the complexities of K8s (workers, kubectl, etc. etc.). However, once you grow beyond certain levels of complexity in your application, k8s probably better. Also it’s portable.
how is ECS vendor lock? You can take your containers and walk away anytime you want
thats the illusion
Yes, but you build a whole operation around it. Think of monitoring for example - you end up using CloudWatch to monitor it (because other solutions aren’t great). You’re entire way of running it becomes tethered to ECS.
Not necessarily a bad thing, just something to be realized.
can you go easily from one paas (like ecs) to another ?
By that definition your just as vendor locked onto K8s when “the next big thing” comes out
it’s kind of comparing apples to oranges.
ecs is paas and is closed source which means i cannot deploy it to GCP
in comparison, eks or kubernetes, is at least open source, and can be deployed to any cloud, no ?
I’m just looking at it from an application standpoint more than ‘the thing running it’
K8s have been out for a while and we are a Open Source Company so we are more tan willing to contribute
which you can’t on ECS
I never saw or though of ECS as the next big thing, for me it felt like learning Chef after using ansible
and I felt the same way with K8 in the early stages but now there is so many resources that does not hold true anymore
2020-09-11
Any recommendations on a dashboard for business users to review upcoming scheduled events (CloudWatch Rules)?
Can someone ELI5 how cpu_options works in a Launch Template? https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/launch_template#cpu-options
this may help: https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/instance-optimize-cpu.html
In most cases, there is an Amazon EC2 instance type that has a combination of memory and number of vCPUs to suit your workloads. However, you can specify the following CPU options to optimize your instance for specific workloads or business needs:
Number of CPU cores: You can customize the number of CPU cores for the instance. You might do this to potentially optimize the licensing costs of your software with an instance that has sufficient amounts of RAM for memory-intensive workloads but fewer CPU cores.
Threads per core: You can disable multithreading by specifying a single thread per CPU core. You might do this for certain workloads, such as high performance computing (HPC) workloads.
Specify CPU options for your instance by specifying the number of CPU cores and disabling multithreading.
got it thanks, so you still pay for whatever instance type you pick but you can customize if you need to for some special reason
2020-09-14
Hi guys, I’ve a question. In QA environment how do you provision and deploy the containers? For example if I have a lot of QAs and all of them want to run in the same time, images tag are following the branch name, and we are using terraform, and userdate to run the docker-compose file and run the containers, and after we finish the testing we destroy the resources using terraform destroy, but I’m feeling this is a bad way, so any recommendations? or how you guys do it?
hello peoples, anyone know why the commit hash doesn’t appear when the buildproject is automatically triggered.? I’m expecting refs/head/master^{commit_hash} but i get refs/head/master when i don’t trigger it manually
2020-09-15
What do you all recommend for deploying to ECS, specifically need to just change a task definition json to modify the image tags and then deploy it up to a service. I have this automated via github actions using the aws-actions, but I need a “break glass” in case that isn’t working right or need to revert to an older image tag. I’m leaning just interacting with the AWS api myself and using jq to do the image tag substitution - probably best…
Why not use terraform?
Playing with AWS APIs directly may be painful. Unless there’s something TF does that you don’t like (it can sometimes destroy resources without need).
I’ve never had success using Terraform as a deployment tool
I use it with ECS/Fargate + Task Definitions etc without issues
I’m using Terraform to just get the ecs service and all supporting resources like vpc, lb, etc bootstrapped
But maybe my use cases are different to yours
yea i don’t know, it just feels a bit clunky to me… do you update the image tag you are deploying manually and terraform apply?
Well, I use “latest” in the taskdef. I upload to ECR via an Orb in CircleCI. The I use “aws cli” to restart the task.
- aws-ecr/build-and-push-image:
name: build-grabber
path: grabber
repo: python-stream-grabber
tag: 'latest'
requires:
- aws-ecr/build-and-push-image:
name: build-server
path: server
repo: python-stream-server
tag: 'latest'
requires:
- restart_task:
requires:
- build-grabber
- build-server
...
restart_task:
executor: aws-cli/default
steps:
- aws-cli/install
- run:
name: Restart task
command: |
TASK_ID=`aws ecs list-tasks --desired-status "RUNNING" --cluster "streamdelayer-cluster" | grep arn | sed 's/[ "]//g'`
AWS_PAGER="" aws ecs stop-task --cluster "streamdelayer-cluster" --task $TASK_ID --reason "Restarting task due to new ECR image deployment"
I preferred to use aws-cli over APIs directly. Less headache that way.
ah okay - so you roll forward in case of issue? what happens if your latest tag has a bug and need to go back to last tag?
Correct, I roll forward. I could change the task def to go back, but I noticed roll forward works a lot smoother.
I could rollback the code changes and re-run the build, which will upload a new latest image which is the same as the previous version
yep - valid strategy … thanks for sharing!
Powerful CLI tool to simplify Amazon ECS deployments, rollbacks & scaling - fabfuel/ecs-deploy
Simple shell script for initiating blue-green deployments on Amazon EC2 Container Service (ECS) - silinternational/ecs-deploy
This one is 1.6k , never tried it myself though
always used https://github.com/silinternational/ecs-deploy
Simple shell script for initiating blue-green deployments on Amazon EC2 Container Service (ECS) - silinternational/ecs-deploy
I liked fabfuel/ecs-deploy when evaluating the two because it wasn’t built in bash. Bash is a necessary tool, but it isn’t a great tool to actually write a library in.
Anyone have seen this error before ?
rror: lost websocket connection with ECS Telemetry service (TCS): websocket: close 1008 (policy violation): InvalidContainerInstance: Missing container instance arn" module=handler.go
After name change and 3 complete destroy and restart with TF the instances are not registering with ECS service
the error on ecs looks like
"status": "REGISTRATION_FAILED",
"statusReason": "Unexpected EC2 error while attempting to Create Network Interface in subnet 'subnet-0f1c1aff459ba2755': InvalidParameterValue",
"agentConnected": true,
and I do not have trunking enabled
this is running in host mode not awsvpc
I did this yesterday in staging
I do it in prod today and it
id create an urgent aws support ticket in chat mode
its been 2 hrs since your last reply in this thread. did you figure it out ?
we do not have a support contract
I did not figure it out
I used the same TF project, changed the task def to add CPU and wen to Fargate
started first try
ah dang, at least it’s working again!
but now I need to figure out why
this is one of the most useless command ever
aws ecs list-account-settings --effective-settings
set trunking to disable and still shows as enabled
sooo it looks like this was the setting that was not enabled:
aws ecs put-account-setting-default --name containerInstanceLongArnFormat --value enabled
although the useless cli shows are everything enabled
now the instance is registering
no that was not it it was this :
aws ecs put-account-setting-default --name awsvpcTrunking --value disabled --region us-east-2
``
so we are using Shared Vpcs
and Trunking was enabled but is not compatible with shared vpcs
ahhhh wow, i would never have guessed
are these account level settings configurable via terraform ? i wonder if there is a terraform module for sane defaults that include the setting that caused that issue
they are not
you need to run those stupid commands
wow youre right, it’s not: https://github.com/terraform-providers/terraform-provider-aws/issues/10168
Community Note Please vote on this issue by adding a reaction to the original issue to help the community and maintainers prioritize this request Please do not leave "+1" or "me to…
I enabled trunking again and it failed
so now I need to know who changed this setting in my account recently since this was working before
isnt there a way to disable toggling it via iam ?
cloudtrail should show who changed it if cloudtrail is enabled
cloudtrail is enabled but this are account settings that I think can be done from organizations or at least that is my theory since we have been moving things recently
but there is one guy that is working on TGWs and networking stuff and I wonder if he did something to all accounts
2020-09-16
This is really strange, so I have an ALB and a Target Group with a path based health check, for some reason the ALB is hitting my application at / periodically (along with the normal healthcheck that hits the /health-check/path
it’s on a different cadence, and I can’t figure out why on earth it does this if I don’t have my health check pointing to /
I should mention the target group does have ECS Fargate instances that roll in and out - now I wonder if this is some default target group behavior i haven’t overriden
Any chance you have another health check configured?
The default one is indeed on “/”
arg, so task def
hmm my task definitions have healthCheck: null
What about the target group?
Try describing target groups: https://docs.aws.amazon.com/cli/latest/reference/elbv2/describe-target-groups.html
only 1 target group:
"HealthCheckProtocol": "HTTP",
"HealthCheckPort": "traffic-port",
"HealthCheckEnabled": true,
"HealthCheckIntervalSeconds": 30,
"HealthCheckTimeoutSeconds": 5,
"HealthyThresholdCount": 3,
"UnhealthyThresholdCount": 3,
"HealthCheckPath": "/health",
"Matcher": {
"HttpCode": "200"
},
do you have datadog or any other test from outside ? OR a container level check?
if you are using ecs
no container level check that i can find at least… no external test or service from outside.. hmm actually let me confirm the latter
confirmed nothing from external sources
Got a source IP showing in your logs?
i have the logs from the app itself and it shows the ALB IP, I need to go look at the ALB access logs i think
thanks for talking this through all! I’ll continue to dig into the access logs - if I do find anything I’ll come back and close the loop here
anyone know a safe and fast way of rebuilding an ecs cluster ? we recently opted into long arn format but have to recreate the cluster to take advantage
we’re thinking of creating a new cluster, migrating services to it, destroying the existing, and migrating clusters back
you do not have to
is is ECS+EC2 it will not affect running clusters
but the easiest way is to create another cluster
otherwise you need to recreate it
I did that yesterday like 15 times
we have around 200 services in our cluster tho
I have enabled long format etc on running services and we did not have an issue
i dont believe it works on a previously created cluster
maybe im having trouble conceptualizing migrating services from 1 cluster to another
hmm ya looks like it will be a manual process with the new cluster…

Update – August 21, 2020 – Added a section with the latest timeline. Starting today you can opt in to a new Amazon Resource Name (ARN) and resource ID format for Amazon ECS tasks, container instances, and services. The new format enables the enhanced ability to tag resources in your cluster, as well as tracking […]
in our very old dev account we had like 50 services
I just went an enable the new format for the whole account
all services keep working
but new services will adopt the new id format
i think the cluster has to be recreated tho
i also enabled the new format
oh i see so new services on an old cluster will be able to use the task tags ?
no, only new cluster I think
we do not use it so we don’t care
but if you want to use it then you are screw you will have to recreate or migrate
anyone having IAM issues right now?
yes, it’s down hard
3:17 PM PDT We are investigating increased authentication error rates and latencies affecting IAM. IAM related requests to other AWS services may also be impacted.
https://status.aws.amazon.com/
Real-time AWS (Amazon Web Services) status. Is AWS down or suffering an outages? Here you see what is going on.
Probably impacting other things since I just got some alerts about ASG activity that shouldn’t happen…
2020-09-17
anybody have any experience with or recommendations for AWS WAF alternatives like signal science or anything.
We used SigSci at my last gig. It was pretty simple to set up and pretty transparent. I can’t speak to the functionality. I didn’t suck…mainly, because my exposure was limited.
Currently – in fact 5 mins ago – we started our first PoC for the Cloudflare WAF. This is the second attempt at insinuating CF between our browser apps and our load balancer. So far, their docs are a little all over the place (the dark side of documentation), and left us hanging at a number of places. We worked with their tech support, via the on-page chat, and even though the engineer that was hellping us was cool and helplful, it feels very commoditized. Obviously, i’m not new to curl, but at the level we play at, a company providing curl commands to hit its api, rather than wrapping that up in code in a command-line tool or web page, they give you curl commands in which you need to figure out by trial-and-error what values are to be replaced.
All that said, we are starting our Cloudflare WAF evaluation today.
Thank you this was very helpful, and sounds about right.
Cool. Glad to help. One of the things we like about Cloudflare is that it will allow us to manage WAV implementations across multiple accounts/client installations, and we need to be able to manage resources globally like that. Let me know how things go with your search. We are definnitely not sold on CF. In fact, we’re leaing toward the AWS WAF offering, in no small part, becuase it’s integrated wtih everything else we have in AWS. If this doesn’t go smoothly, we will probably opt for a vendor with more of a stake in our sucess, whcih means AWS where EVERYTHING lives over CF, where we are planning to use only the least amount of of one of their non-core offerings (WAF)
Yea the problem with the aws waf is it has no capability for learning, and adding exceptions is a pain and can be too permissive. Also version to of waf with terraform the readability of the code is basically non existent compared to version 1
However having said that being able to have lambdas auto attach lbs to different web acls and such is pretty nice
2020-09-18
Hey folks, anyone using pro version of localstack to be able to use cognito locally? Does it work as expected and is the $15/per month/per developer worth the price?
2020-09-21
Can anybody help me with advice on what is the best practice for creating IAM users for multiple aws accounts? Ideally I’d like to create users in a “root” type account and then those users are granted access to perform actions in other actions dependent on what type of account it is e.g. Dev/prod
If there’s a way to do this with an SSO type product like Okta that would be even better.
Thank you
Using assumed roles much better than actual users in my opinion
Yeah I was thinking assumed roles with SSO okta integration. Then having short-term credential support for api/cli
thats what we use
much easier to manage 3 or 4 roles than 30 iam users in 10 accounts
2020-09-22
AWS Perspective is a solution to visualize AWS Cloud workloads. Using Perspective you can build, customize, and share detailed architecture diagrams of your workloads based on live data from AWS. P…
Looks amazing!
AWS Perspective is a solution to visualize AWS Cloud workloads. Using Perspective you can build, customize, and share detailed architecture diagrams of your workloads based on live data from AWS. P…
it will not replace everything of my old code : https://github.com/claranet/aws-inventory-graph
Explore your AWS platform with, Dgraph, a graph database. - claranet/aws-inventory-graph
is there a way to route your AWS ALB to a different target group if the first target group fails a healthcheck?
I never heard a feature like that, what you can do else, it to set up 2 ALB, with 2 target groups, and you use a route53 entry set to the 2 ALB and with an healthcheck
When you have more than one resource performing the same function—for example, more than one HTTP server or mail server—you can configure Amazon Route 53 to check the health of your resources and respond to DNS queries using only the healthy resources. For example, suppose your website, example.com, is hosted on six servers, two each in three data centers around the world. You can configure Route 53 to check the health of those servers and to respond to DNS queries for example.com using only the servers that are currently healthy.
gotcha @Issif
Yes, this sounds similar to canary deployments using multiple ALB + route53 weighted records
unfortunately thats not the problem im trying to solve. We have a WAF (sigsci) deployed in our k8s cluster as a reverse proxy and it’s a part of the request path. We want to allow ourselves to upgrade these WAF agents w/o causing downtime so we were thinking of a solution where the ALB will generally route traffic to the WAF agents which routes to our ingress controller agents unless the WAF agents return an unhealthy healthcheck, otherwise route straight to the ingress controller
Like issif said, two ALBs should let you do this
If you have a lot of load on the ALB, it might not be at the correct prewarmed size if you use a failover design with a hot/cold ALB. ALB scale fast, but if it’s a huge rp/s cutover, I’d expect lots of timeouts in the beginning of the switch.
in k8s two waf deployments, every deployment with an alb and on top of that route53
2020-09-23
Has anyone migrated their orgs into control tower? looks like pain in the butt
Simplest static site hosting in aws that I can use security groups with to keep internal?
Thinking a fargate task that cicd builds with static site and hosts with something like “ran” and done. S3 buckets don’t seem to have anything with groups and ec2 while ok wouldn’t allow me to set target tasks at 1 for it to autoheal itself.
Any better way?
s3 bucket with a vpc endpoint and a bucket policy that restricts access to the vpc endpoint?
Nice. But if the folks needing to access it are not in the vpc and access is controlled through security groups would that work. Would the vpc endpoint have this option? I’m new to vpc endpoints. Don’t know if easy to plug one in and do that
i suppose i was going off “internal”… depends on really what you mean by that
but you can have a bucket policy with a statement that allows the vpc endpoint, and another statement that allows specific IPs
Describes each of the AWS global condition keys available to use in IAM policies.
Describes each of the AWS global condition keys available to use in IAM policies.
I think i get it. Not sure that solves what I’m looking for. I want anyone at my company to be able to access, but I don’t want to host internally. I want to host in AWS. This means I’d need to use security groups to avoid it being a pain. If I could gate keep this behind SSO with microsoft that would be fine too, but didn’t want to complicate this or deal with any security other than security groups if possible. I’ve done lots of reading in the past on this and determined that s3 buckets just can easily be used like that
well now with SSO you’re talking about an authenticated site. that’s a whole different thing again
with security groups, that’s not authenticated. or at least, it is delegating the authentication to something else.
i feel like now we have a classic X/Y problem, where the question doesn’t really address the problem
Simplest static site hosting in aws that I can use security groups with to keep internal?
I don’t think I’m off from what I posted
I’m up for other things if I’m missing something basic I could do, but mostly I’m talking about having an security group protected instance that serves up my static content… or I have to move to sharepoint
alright, if you’re that focused on security groups being the answer, then you’re right. but that’s the part that is the X/Y issue, to me. they are a solution looking for a problem
you could try lightsail. it’s more than a static site needs, but has a specialized cost model that might work, while being easier or more intuitive to manage than fargate. have you looked at this page yet? https://aws.amazon.com/websites/
AWS offers a cloud web hosting solution that provides businesses & organizations with a flexible, scalable, low-cost way to deliver websites & applications.
does it need to be a security group, or can it be CIDR based ACL?
I could probably use the security groups as a data source and write the cidr blocks this way. That might work.
this is not really what security groups are for and it sounds like you’re painting yourself into a corner by trying to make it work with security groups.
 2
2Internal only static sites are annoying. Love static but the placement is annoying.
It could be that they already have a list of acceptable CIDRs associated with the security group, so this would keep it “dry” by looking up those permitted ranges and then adding that to the bucket policy.
Yes. That’s what I was wanting to use
anyone know any fancy cli magic to find ec2 instances that are NOT in SSM ?
if I query aws ssm describe-instance-information it only returns ec2 instances that have the ssm agent running
hacky but the only way i can figure out how to do this is to use the above command to dump out all the ec2 instances that have ssm and then filter them out from aws ec2 describe-instances to get the instances w/o ssm
is there an easier way to do this ?
so this doesnt really answer your question, but I have a lambda that tags all instances with ssm so I can then do a query to find all instances that doesnt have that tag
Aws config has a rule for this
ah I didn’t know aws config supported this!
if an aws config rule can auto tag ec2 instances with/without ssm
then could an aws config rule also trigger the installation of ssm on non-ssm compliant resources ?
at that point, we wouldn’t even need the ssm tag.
so i enabled the ec2-instance-managed-by-systems-manager aws config rule
next is the lambda to install ssm
@pjaudiomv how does your lambda determine if an ec2 has ssm or not ?
my ec2 instances are tagged with EX. SSM-Detected: true
so if that tag isnt there or isnt true
how do you set the SSM-Detected tag ?
does each EC2 have a script on it that checks if ssm agent is running and then add the tag to itself ?
Im acutally using a bash script on a pipeline schedule
basically something like this
#!/bin/bash
INSTANCE_IDS=$(aws ssm describe-instance-information --query 'InstanceInformationList[?starts_with(InstanceId, `i-`) == `true` && starts_with(PingStatus, `Online`) == `true`].InstanceId' --output json)
echo "$INSTANCE_IDS" | jq -r '.[]' | while read INSTANCE; do
aws ec2 create-tags --resources $INSTANCE --tags "Key=SSM-Detected,Value=true"
done
ah it checks PingStatus
so PingStatus can only be checked on ec2 instances that are already managed by ssm
yea
and thats the problem, i need to know which ones have ssm agent installed on them which means they don’t even show up as being managed by ssm
ahhh
in fact the aws config rule ec2-instance-managed-by-systems-manager that @sheldonh was alluding too, also checks pingstatus unfortunately
so it looks like i’m back to square 1 and im going to use the solution @jose.amengual agreed with which is hacky but it should work
yea seems best way I know of
wow. cloud custodian to the freaking rescue.
- name: ec2-ssm-check
resource: ec2
filters:
- type: ssm
key: PingStatus
value: Online
actions:
- type: tag
key: ssm
value: true
nice
I want to deploy cloud custodian. I was thinking fargate task
we use cloud custodian periodic mode which creates lambdas for us
pretty low cost for us
Wait I can use it to create lambdas for it’s functionality ? So cool! Even better
Reading docs. Very cool! Going to try and deploy at least one today
ya, ive implemented it at 3 companies and it’s a surprisingly underused tool
it’s basically creating lambdas as a free and open source service
you can toss out so many custom scripts that lay there in dying jenkins instances
Very cool! I bet it’s easier to create my own rules than aws config sdk. That is definitely not quick to learn.
2020-09-24
Looking to get alerts when AWS Secrets Manager rotation fails. There’s no CW metric, rather Secrets Manager events go to Cloudtrail. Don’t have much experience with Cloudtrail, how does one get alerts based off the cloudtrail event history?
you can create a cloudwatch event that triggers off of cloudtrail
then when the cloudwatch event triggers, you can then make it invoke a lambda if you like
here’s a nice example https://aws.amazon.com/blogs/mt/monitor-and-notify-on-aws-account-root-user-activity/
nice, ok. Hm, there’s no way to skip the lambda and go straight from cloudwatch logs into SNS?
Like how cloudwatch alarms go straight to SNS?
i believe it would be a cloudwatch event that would trigger on cloudtrail event
you dont have to invoke the lambda
i use cloudtrail events to trigger a cloudwatch alarm that invokes a lambda that alerts me in slack/email using a cloud custodian policy
is there a metadata file on ec2 amzn linux 2 instances that could possibly share the original ami that was used to create the instance ?
we have a base ami and teams that use packer to build off the base ami
now we wonder what the original amazon amis were that the team amis are based off of
we technically tag base amis with source ami but it would be easier if there is a file already on the instance itself that contains this info
if one doesnt exist, we’re thinking of figurign out a way to bundle the metadata into our base amis to child amis will also be aware of their parent (or grand parent)
ah wow. there is one.
$ cat /etc/image-id
curl <http://169.254.169.254/latest/meta-data/ami-id>
is that what you mean
nah thats the current ami
the parent ami
gotcha
process
- amazon outputs ami
- we create a base ami
- team creates ami off of base ami now what source ami is the team using? and amazingly it’s in the /etc/image-id file :D
nooice
Does anyone do AWS Access Key expiration / rotation via Terraform or otherwise in their org? Wondering how folks accomplish that without it being an “audit and ping team member” process.
Use assumed roles and then they only ever have temp credentials
I am using assumed roles for accessing other accounts, but team members still need a user account and a single access ID / secret for assuming the roles from the CLI. I don’t want those access ID / secrets to live too long.
Or maybe I’m misunderstanding your suggestion?
Can do cloud custodian I think and it can help setup notification and aws config rule.
@sheldonh I’ve seen Cloud Custodian before — didn’t have a need back then, but it would likely be beneficial for this company. Thanks for the suggestion!
is there a better way to put an acm cert on a static site without having to use cloudfront ?
Are you talking of an static site served from s3?
yessir
there is few ways, you can do it with a fargate task, nginx proxy to s3
with an alb or not
or cloudfront+s3
that is about it
you could abiously use any other proxy like envoy, haproxy etc
but it means an ALB before your proxy, you can’t extract ACM certs
You can do alb+nginx proxy+S3 using acm, it works just fine
exactly my point, or directly traefik with let’s encrypt
ah sounds like a pain to setup. i was hoping to do it with only aws stuff. i guess cloudfront+s3+acm is the only way (besides lightsail).
it’s the easiest way (and cheapest)
2020-09-25
this seems like it could have a lot of potential for simplifying authentication to api gateway endpoints and routes… https://aws.amazon.com/blogs/compute/introducing-iam-and-lambda-authorizers-for-amazon-api-gateway-http-apis/

Amazon API Gateway HTTP APIs enable you to create RESTful APIs with lower latency and lower cost than API Gateway REST APIs. The API Gateway team is continuing work to improve and migrate popular REST API features to HTTP APIs. We are adding two of the most requested features, AWS Identity and Access Management (IAM) […]
anyone use buildkite here ?
2020-09-26
Thought I’d ask here. I have a on-prem api accessible via VPN (and it has a public ip, although not accessible over internet) which I’m going to expose via api-gateway, however I see that NLB/ALB only supports private IP-ranges (https://aws.amazon.com/elasticloadbalancing/faqs/ “Can I load balance to any arbitrary IP address?“) - are there any elegant solutions to avoid having to deploy my own reverse proxy?
Using a lambda function is the best bet maybe?
Where do you want to place the ALB/NLB in that communication? It can be public facing.
those would have been private ones, but not doable since the api they are going to balance against:
- is reachable by vpn only
- has public address that combo rules out nlb/alb to front the api
I went with a small lambda function as reverse proxy instead
2020-09-27
2020-09-28
Has anyone used https://github.com/awslabs/aws-securityhub-multiaccount-scripts to mass enable securityhub across many accounts? Does the “master” account referenced in the README, have to be the AWS Org master account? Or can we use a child-account as the “master” security hub account?
This script automates the process of running the Security Hub multi-account workflow across a group of accounts that are in your control - awslabs/aws-securityhub-multiaccount-scripts
you can use a “child” account, I do this across 8 acccounts and the one i aggregate to is not the org “primary”
This script automates the process of running the Security Hub multi-account workflow across a group of accounts that are in your control - awslabs/aws-securityhub-multiaccount-scripts
Did you use some other automation to deploy the role across every account?
yes so i used terraform but theres no way to accep[t an invitation right now so you can only enable it and submit a request with terraform
aws_securityhub_account and aws_securityhub_member
you could probably use a null_resouce and cli or python script but i decided i could make better use of my time for a one time operation like that
gotcha, guess I’ll go the same route
your module isn’t public is it?
no but its super basic i can post it
resource aws_securityhub_account security_hub {}
resource aws_securityhub_member prod {
depends_on = [aws_securityhub_account.security_hub]
account_id = "5675678467867"
email = "[email protected]"
invite = true
}
resource aws_securityhub_member dev {
depends_on = [aws_securityhub_account.security_hub]
account_id = "3457896543789"
email = "[email protected]"
invite = true
}
aws_securityhub_account just enables it for that account and takes no arguments
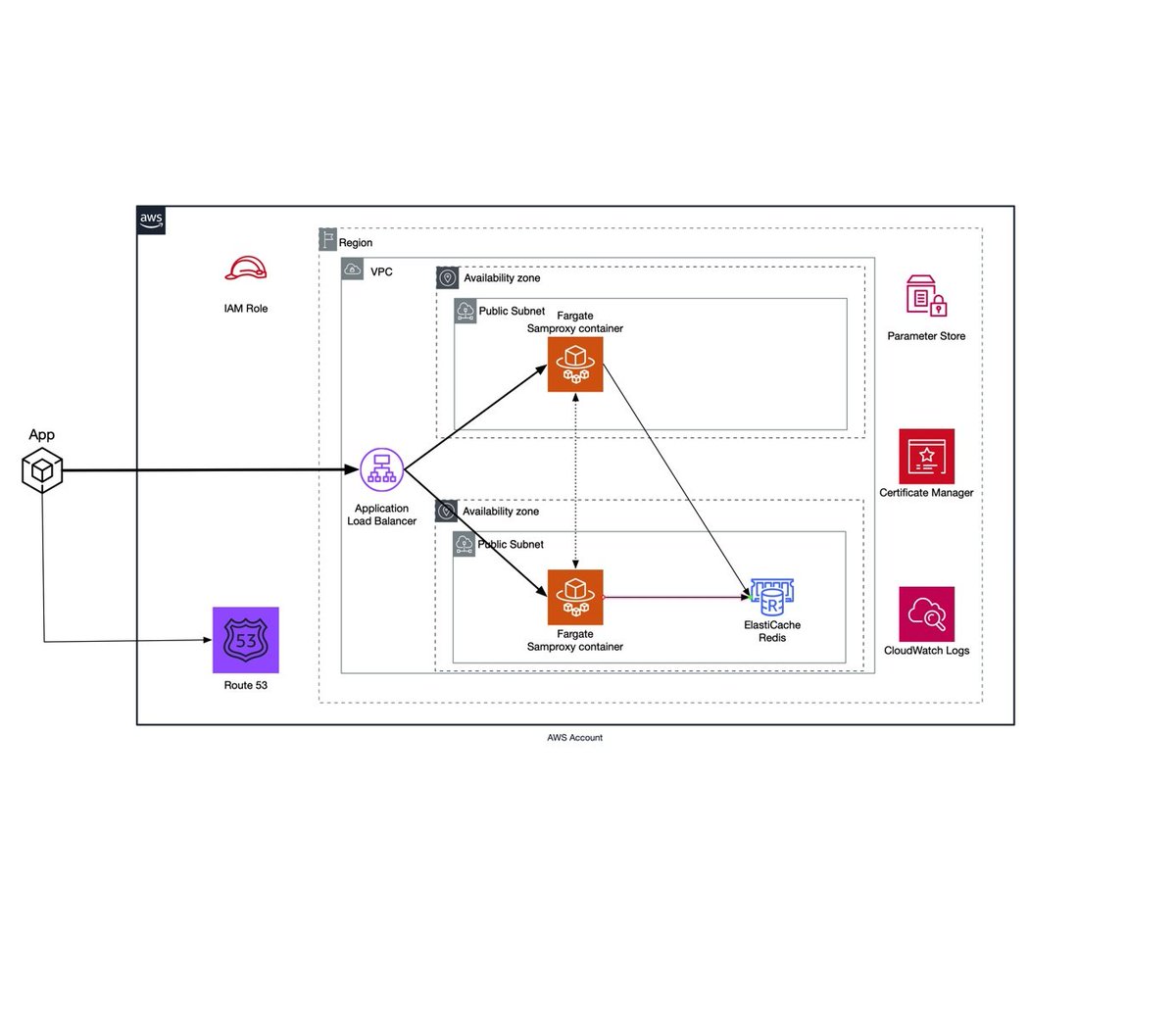
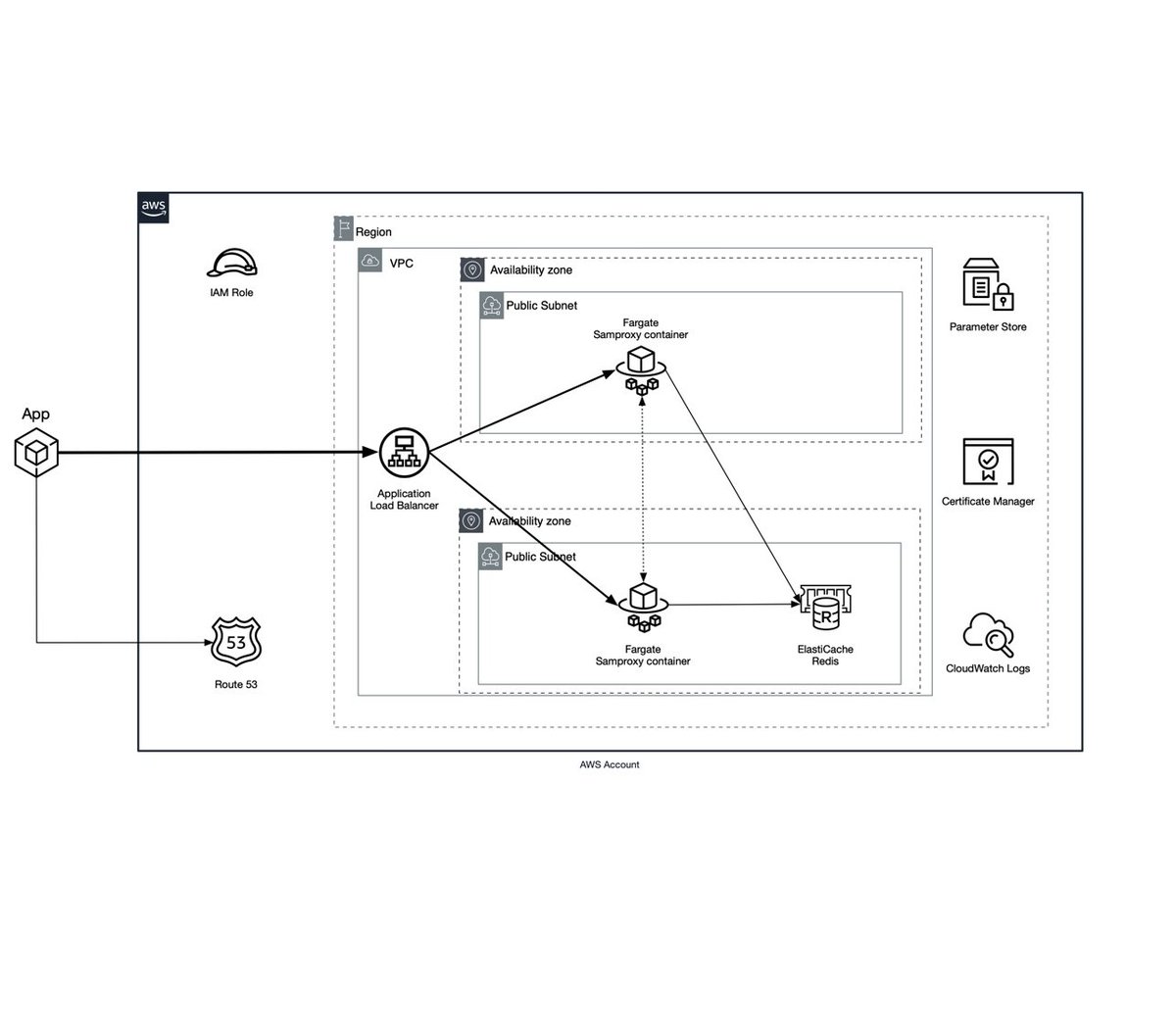
#aws Build once and run everywhere, is a great concept behind docker and containers in general, but how to deploy these containers, here is how I used ECS to deploy my containers, check it out and let me know how do you deploy your containers? https://www.dailytask.co/task/manage-your-containers-deployment-using-aws-ecs-with-terraform-ahmed-zidan
Manage your containers deployment using AWS ECS with Terraform written by Ahmed Zidan
I was wondering the best way to enable remote access to private resources (RDS, etc.) across different AWS accounts.
Currently I have a bastion per account (dev stage & prod), but have seen solutions where there’s another VPC that peers with the 3 environments, then has a bastion/VPN for access. The added benefit being only 1 point of entry.
Any ideas/best practices to how this is implemented in 2020?
Basically that’s a management network. Sort of the equivalent of out-of-band of data centers.
You set up a mgmt and then peer with each of the other VPCs. You allow traffic between the mgmt and the peered VPCs, but not between the peered VPCs.
Of course, it means you have one point that, if compromised, will be very bad for you.
It needs to be very protected.
I would encourage you to rethink the “bastion” need, and see if there are other ways to access the data you need, while implementing strong IAM enforcement.
Thanks @Yoni Leitersdorf (Indeni Cloudrail) for the response
Do you have a preferred way to access RDS instances in a private subnet across different accounts with strong IAM/MFA enforcement?
This is the exact issue I’ve been trying to solve the last 2 days, the only solution I’ve come to is the management VPC with MFA at the VPN level.
Can you access the data not using the DB protocol directly? Through an API or something of the sort?
I don’t know what data you are looking to access, but maybe there’s a way to auto-collect it with Lambda and place it elsewhere.
I think Gravitational Teleport goes some way to help tidy up bastion ops but haven’t looked at RDS and other managed service access. Curious to see what other ideas come out of thread.
Did you guys notice any sqs random timeouts in last couple of days?
In Us-east1 only
2020-09-29
Anyone running ecs on 100% spot instances? Are there any risk of it terminating all my instances and not being able to provision new ones?
Yes there is a risk because you are only using a single instance type. If there is no available spot capacity for that instance type you will loose your spot requests until sufficient spot capacity is available.
I’ve seen this happen when there has been a service outage in a specific availability zone which has caused resource contention. Both on-demand and spot instances were not able to start as there wasn’t any availability of that instance type.
If you are going to go 100% ideally you want to diversify across instance types and families to ensure your cluster can survive at least a loss of one instance type.
makes sense. I will add more types of instances but I don’t want to make it too complicated. What about spot.io platform is it worth to try them or are asg with spot instances enough?
Just having multiple instance types in your Launch Template and running 100%-spot might well be good enough for you. It depends on your workload, if it’s critical production I’d always keep at least 1 on-demand instance in an asg to ensure that spot market fluctuation don’t impact you. But if your workload can handle an outage without service or data loss you might not need this.
relevant blog: https://aws.amazon.com/blogs/aws/new-ec2-auto-scaling-groups-with-multiple-instance-types-purchase-options/
Use as many AZ as possible. 1 of our services is 100% fargate spot and scales to 2000 tasks across 6 AZ. Been this way for about 6 months with no issues.
Yes indeed use all the AZ’s you can. Second nature to use them all I forgot to even mention it!
perfect, we use all az’s already. The production cluster actually has one base on demand instance. I’m not sure what would happen if no spot instances were available would it launch on demand or not?
My old team at GumGum really loved Spot.io.
If believe if your Launch Template doesn’t specify any on-demand in Optional On-Demand Base or On-Demand Percentage Above Base your instances won’t start and you’ll get instance-terminated-no-capacity status
Anyone have any thoughts on Control Tower? We’ve our own half-baked landing zone impl in terraform, but could consider moving to Control Tower now that it supports enrolling existing accounts. It would require moving our AWS SSO to a different region however, which, oof but we’d like to spend less time managing the stuff Control Tower would do for us. Any success or horror stories?
at previous job we did a pretty extensive review of control tower for a national retail org and found the solution lacking in quite a few areas, as well as being hard to maintain or customise and extremely opaque to troubleshoot.
this was > 1 year ago and it might be much better now.
looking over the headlines briefly now it doesn’t sound like they’ve added much.
i’d recommend approaching with caution.
2how do you recommend creating new aws accounts programatically ?
oh interesting, i’ve been dumbly doing it from the command line.
aws organizations create-account --email <newAccEmail> --account-name "<newAccName>" --role-name <roleName>
thanks for sharing!
welcome
We’re onboarding us to the Control Tower on my new job. Thursday I have a demo from the engineer deploying it. Nice timing.
is it still 5000+ lines of cloudformation and a couple of step functions?
Yes it is still CF. May be some improvements as it was turned into a product. But basics are the same
I just deployed it in a sandbox Org and I didn’t see any CF at all, can’t comment on what happens behind the scenes
It doesn’t automatically setup securityhub and guarduty though, which is a PITA
It does configure cloudtrail however
I even tested the enrolling of existing accounts into Control Tower and it worked fine, once I added a role to the child account
Anybody attending the AWS summit today? Any good sessions you’d recommend? I just spent 10 minutes looking for an agenda or calendar of sessions…or anything and just bailed, due to lack of info.
So I want to run more tasks in docker containers. I have some migration tasks and other things that are more long-running than a lambda really fits.
I’d use azure devops containers but they need to be able to access a private subnet so that’s kind of out.
Couple basic questions
- if I deploy an ECS fargate task … It still requires ECS cluster. Is it basically just metadata at that point since I don’t have any running tasks and I’m not actually provisioning any server?
- the only reason I haven’t done a lot more docker ad hoc type tasks is all the plumbing required to get that stuff running. Does the new docker and ECS integration hold a lot of promise for me to quickly deploy something I tested locally? This is for devops type tasks not running application stacks right now
- can I mix fargate test with Windows and Linux or is it still not support windows in fargate?
I’ve been dealing with almost two days of environmental issues on my build agent box. I’d like to transition to more docker related jobs and stop managing more ec2 instances
if I deploy an ECS fargate task … It still requires ECS cluster. Is it basically just metadata at that point since I don’t have any
Yeah. There are nodes under the hood, but since it’s fargate, they’re abstracted from you and you don’t deal with them at all. You just think of tasks.
Windows — I have no clue unfortunately. I wouldn’t be surprised if Fargate did not support windows. It’s still young in my mind.
Does the new docker and ECS integration hold a lot of promise for me to quickly deploy something I tested locally?
I feel it’s better than doing things through EC2 for sure, but there is a good bit of domain model cruft in any container orchestrator.
I would suggest looking at CLI tools that help manage ECS easily for this type of things:
- AWS’ ecs-cli — https://github.com/aws/amazon-ecs-cli / https://github.com/aws/copilot-cli — Haven’t used, but they’re putting a lot of effort into this toolset so I would imagine it’s got some good stuff going for it.
- https://github.com/fabfuel/ecs-deploy — I’ve used this lightly, but would suggest this over doing the bash scripting that everyone does to manage ECS deployments / scaling.
- https://github.com/masterpointio/ecsrun — This is my own project for maintaining YAML configurable ad-hoc jobs like you’re talking about.
The Amazon ECS CLI enables users to run their applications on ECS/Fargate using the Docker Compose file format, quickly provision resources, push/pull images in ECR, and monitor running application…
The AWS Copilot CLI is a tool for developers to build, release and operate production ready containerized applications on Amazon ECS and AWS Fargate. - aws/copilot-cli
Powerful CLI tool to simplify Amazon ECS deployments, rollbacks & scaling - fabfuel/ecs-deploy
Easily run one-off tasks against a ECS Task Definition - masterpointio/ecsrun
Windows containers are only supported for tasks that use the EC2 launch type. The Fargate launch type is not currently supported for Windows containers.
2020-09-30
live streaming all day, https://www.twitch.tv/cdkday
cdkday streams live on Twitch! Check out their videos, sign up to chat, and join their community.
Does anyone know if Service Discovery (Cloud Map) DNS can be used outside of ECS? It seems to work in Lambda, although I haven’t tested it personally - my client tells me it does.
Ideally we need to resolve service discovery DNS on a Client VPN Endpoint.
i don’t see why not. it’s just a zone in route53, so it should resolve fine as long as your dns resolver uses the vpc dns server
Ok, yes I can retrieve the zone id. I am going to try configuring the resolver. Thanks @loren!