#aws (2020-11)
 Discussion related to Amazon Web Services (AWS)
Discussion related to Amazon Web Services (AWS)
Discussion related to Amazon Web Services (AWS)
Archive: https://archive.sweetops.com/aws/
2020-11-03
anyone have successfully updated eks from 1.14 using terraform terragrunt? using terraform-root-modules
How can we restrict aws IAM users not to generate their own access or secret keys by themselves.
Deny iam:CreateAccessKey
Though, is that really the right way to go? If you do that, you have to manage them, including rotating them.
Create, modify, view, or rotate access keys (credentials) for programmatic calls to AWS.
You can allow them to create keys for themselves
right
If you create my access keys for me and give them to me, that means you know them. As the user I don’t like that. I want to be the only person on the planet that knows those keys
Do you allow users to set their own passwords (within the confines of a secure password policy)?
@kalyan M what are you trying to achieve? Or what is the risk you’re trying to mitigate?
previously one of the developer machine keys got malwared and there are c9 large clusters spinned in the Ireland region, other regions, which we are not aware. the ec2 spin up is done from china region. we got a a billing of $10K on that month. Looking for a way to remove their keys after work is done.
Encouraging use of secure development practices like pre-commit hooks that check for AWS keys before a commit, or use of tools like aws-vault which always creates a temporary key using AWS STS (and better training on protecting keys and other security practices) would be a better strategy. What you mentioned is a serious problem and one that really needs to be solved, but it should be solved in a way that increases trust in the dev culture, not locking things away
A vault for securely storing and accessing AWS credentials in development environments - 99designs/aws-vault
[tl;dr] Organizations going through a DevOps transformation must review their culture, to evaluate whether it is meeting the requirements of a true DevOps organization An absence of trust is the root cause
Okay here’s an actual strategy you can use instead of what you are proposing: You can configure IAM policies such that MFA must be used, even when running console commands with an access key. aws-vault supports it beautifully.
You can also lock out regions that you don’t use via IAM
Or use something like CloudCustodian to monitor AWS activity
Agree with Andrew 100% here. Making things harder for devs won’t solve your problem here. Also, dev’s are very resourceful and find ways around the blocks you set up. You need to make sure you build something that’s easy for them to adopt.
We use aws-vault and AWS SSO (with G Suite IDP). The keys are never saved to the HD. Malware can try and make aws-vault calls, so it’s not fool-proof, but you’re adding more hurdles for the malware to try to overcome.
2020-11-04
2020-11-05
Hi! Is there any way to increase Security groups per network interface other than through service quotas. Maximum number is 16, is there any way to have it set on, let’s say 30 or 50? Should I contact AWS support? Thanks!
Be aware that if you increase the number of sg-per-eni then the number of rules-per-sg will decrease.
Thanks! I use only a few rules-per-sg. The thing is, I’ve created separate sg for every ECS cluster, and I have a lot of ECS clusters…
I’ve created everything trough Terraform. So other option is to redesign everything
You can redesign things by creating a common security group, and having each ECS cluster add rules to the common group.
If you have this many clusters you might want to consider some other form of security. You could have a single rule based on CIDR and use dedicated subnets
Thanks @Alex Jurkiewicz - at the end there was no problem at all to begin with since I’ve misunderstood how VPC endpoints work :)
2020-11-06
2020-11-07
I have a cloudwatch alarm for read iops where I want to set the threshold for alarming at a certain number (i.e 5000) but every night at 2am we run some sync jobs that are read intensive that spike up to higher than that number for a short period of time (i.e 7000) is there a way to configure the alarm threshold to be higher for that short period of time
i don’t necessarily want to set it at the higher threshold all the time as prolonged iops will lower our burst balance but the 2am spike is when we are at our lowest traffic and the sync jobs don’t last too long
And what about increasing the duration of elevated iops?
Also, this is something you should be able to control with your escalation platform
Yeah, if you feed these alerts into pager duty, you can have scheduled maintenance to silence alarms for a certain time period. But that brush might be a little broad.
There’s no way to do what you want natively in AWS, except the hammer of a lambda scheduled action.
I wonder how useful this alert is though. Why do you want to be notified about high write iops? Can you instead be notified about degradations in application performance directly? Or if you must alert on the database, maybe there are other metrics which are more useful. Like number of connections or CPU.
Hmm, I don’t necessarily want to increase the duration as I think it could lead to slower reaction time to a system that might be impaired soon. Also I’m not sure if we can get that granular in our escalation platform (victorops) to be in maintenance mode for just a specific alert type? I’m reading that people have set up lambdas to disable/enable alarms. So I could have an alarm with a higher threshold enabled between 2am PST and 3am PST while disabling the general alarm during that period.
@Alex Jurkiewicz we alert on many things including cpu, connections, and iops. for us, we are very read heavy and increased read iops past our specific threshold for a longer period of time can drop our burst balance (which once depleted will cause read latency and service degradation) I like to alert on read iops because it generally gives us the most time to verify if we’re likely to be in trouble soon. Alerts on low burst balance, queue depth, read latency generally would come after as they are lagging symptoms of the problem. I feel like alerting on degradation in application performance to me is reactionary and you definitely want proactive alerting like prolonged read iops spikes as it gives you time to debug and hopefully prevent an issue that hasn’t happened yet.
Thanks for the explanation. That makes a lot of sense, alerts are always application/system-specific. I agree with your point that if something is going wrong, it’s better to know before than after. But I think this situation is a great example of how difficult it is to build an alert that predicts problems in a reliable manner.
I’m reminded of a tweet from one of the original YouTube SREs, who said something like “in the early days, YouTube monitoring alerted on two metrics only: stream starts and number of uploads”. If you are a large company with a big complement of on-call staff, you can get tricky and predictive and build automated remediation based on this alert! But if not, you will end up with overly sensitive alarms and a culture of alert fatigue.
agree on alert fatigue!
I still see this as not an alert problem but an escalation problem. That alert escalation should be associated with a schedule. Very easy to do in something like opsgenie, but not sure about victorops
opsgenie
got it @Erik Osterman (Cloud Posse)
2020-11-08
2020-11-09
Hey all is there a way to create multiple databases in an RDS instance as part of terraform provisioning ??
use the postgresql provisioner
and I’m sure there’s a mysql one
You mean using postgresql provider in the terraform specification?
yah
Interesting didn’t think of that thanks!
A provider for PostgreSQL Server.
That one right?
That’s it. I do this exact thing. The only rough part about this is that you typically want a separate root module to do this because :
- You typically need a SSH tunnel into your VPC so you can access your private RDS instances for the postgresql provider to do its work.
- It’s not done often, so keeping it isolated and not having to share that tunnel across multiple root modules is the right way to go.
I’ve also found that the postgres provider doesn’t seem to integrate very well with the terraform dependency graph. It tries to ‘jump the gun’ and execute before things are ready
Anyone know any tooling to keep AWS Config files (+ Kube config files as well) up-to-date across an org? I’m considering writing a script around a gomplate template for this but before I do I figured I should check that this isn’t already a thing.
You mean like users AWS configs, configs for the “AWS Extend Switch Roles” plugin etc…? I created a simple Jenkins job at a previous employer so that users could self-serve getting configs for their user (email). Currently, I have some janky Ruby / rake tasks that do some of those things. I haven’t found anything out in the wild that does it.
Yeah, that’s what I was referring to.
What is AWS Extend Switch Roles? I should check this out…
Oh a browser extension. Interesting.
It’s great if you work across many accounts without SSO or some sort of app portal like you get with Azure AD.
2020-11-10
Requesting upvotes https://github.com/aws/containers-roadmap/issues/256 (for ecs automatic asg draining)
Request for comment: please share your thoughts on this proposed improvement to ECS! With this improvement, ECS will automate instance and task draining. Customers can opt-in to automated instance …

Last year, we launched Virtual Private Cloud (VPC) Ingress Routing to allow routing of all incoming and outgoing traffic to/from an Internet Gateway (IGW) or Virtual Private Gateway (VGW) to the Elastic Network Interface of a specific Amazon Elastic Compute Cloud (EC2) instance. With VPC Ingress Routing, you can now configure your VPC to send all […]
Can anyone tell me if it’s possible to decrease an FSX once it has been increased?
The FAQ https://aws.amazon.com/fsx/windows/faqs/
says:
Q: Can I change my file system’s storage capacity and throughput capacity?
A: Yes, you can increase the storage capacity, and increase or decrease the throughput capacity of your file system – while continuing to use it – at any time by clicking “Update storage” or “Update throughput” in the Amazon FSx Console, or by calling “update-file-system” in the AWS CLI/API and specifying the desired level.
Thx @Alex Jurkiewicz I also saw that as well. I’m guessing the only option is increasing but you cannot decrease as aws doc doesn’t mention this.
I’m sure they would mention if it’s possible. AWS prefer to say nothing than to say “you can’t do X”
Can’t decrease the storage space of a FSX. Only thing that can be decreased after creation is the throughput.
Thx
2020-11-11
is there any software that can restrict the users to just view the code. instead of modifying or downloading the code. even copy/Paste?
There are solutions for this but they tend to be very intrusive and enterprise-y. Not really an #aws issue. Some examples:
• Citrix makes a remote-access virtualization product. You open up your app through it, and then users log in via a special Citrix agent that prohibits copy/paste.
• On iOS and Android there are enterprise management tools (i.e., rootkits but from your employer) that can create special sandboxes that prohibit copy/paste, screenshots, etc.
• A simpler one is Windows Remote Desktop. IIRC you can set it so that copy+paste works within the RDP session but is disallowed between remote and local.
if you can view the code, couldn’t you also copy and paste the code ?
screenshot and paste the image 
The most suitable software is a contract making them pay you lots of money if they copy the code, I think.
Does anyone have any experience around Aurora Failures in Prod?
(We’re going through planning on migrating to Aurora, but just curious of pitfalls to be aware of.. like.. “too many writes will knock Aurora over” or something based on past experience, instead of hypothetical: ‘it should be great!’)
We migrated to aurora (MySQL) and very happy.
The replication is disk block based, so during failovers you lose almost no data, and they are very fast.
The biggest caveat is that Aurora is slower for writes than a traditional MySQL master. Because it waits for writes to be acked across multiple AZs. Not that much slower, but AWS don’t really mention this anywhere as it’s the only meaningful regression
Can’t update from 5.6 to 5.7 in place. Cloudposse module wants to recreate instances on minor engine version change. You can avoid by forking module and add lifecycle version ignores…
Otherwise been great for us too. Fail over quick. Odd MySQL error resulted in crash and fail over but fixed on later versions.
very heavy concurrent writes will force a failover of the cluster instances due to the things mention about the storage so as long as you can slow down your writes then you will be ok
I’m talking about millions of rows here
we have tables with more than 1B rows
I haven’t seen failover caused by high write load. We’ve hit >30k WIOPS sustained without issues
we can literally crash it at will on an aurora 5.6 but again that is usually not a limit you will get to and there is still ways to avoid it
we use aurora for many other things and no issues
One of the things I like the most is how fast the clones are since is basically “sharing” the same storage it is pretty fast
@jose.amengual We have like ~3TB of data we’re going to migrate and I do think one or more of our tables have > 1B rows
We’re also going to migrate to Aurora Postgres rather than MySQL. @jose.amengual curious if you could clue me into how many writes would cause you to fall over?
mmmm I do not know exactly how many but I can tell you how I did it
yeah, that’d be good to know, if possible
I work with @rms1000watt and we just did a sync of data using pglogical from rds pg -> aurora pg (11.8) and it went up to 100k WIOPS and stayed there without any issue. This is not live traffic just syncing data over. Really pleased with the performance as of now.
| I had 15x10GB files with two columns Name | MD5 hash and I had 15 tables, each table named after the file like file_1, file_2 etc and I was importing those files into each table, it was able to load 3 in parallel ( although writes are sequential) when I aded to more then it will just failover |
but you need to keep in mind that the size of the instances matter
so it is a combination of the two, I was using db.r5.4xl
yes we are using r5.24xlarge
lol
I do want to scale it down but not during this transition
and keep in mind too, no tuning nothing, straight aurora
we use mostly the reader for the app so we can basically write all the time
you can do multimaster too that can double the WIOPS
and does some sort of sharding capabilities
I am really interested in multimaster!! Do you have any doc or article around this?
Use multi-master clusters for continuous availability. All DB instances in such clusters have read/write capability.
I will check it out.
This seems to not support PG
Currently, multi-master clusters require Aurora MySQL version 1, which is compatible with MySQL 5.6. When specifying the DB engine version in the AWS Management Console, AWS CLI, or RDS API, choose 5.6.10a.
oohhhh yes PG is always behind
You can tune things. For example we disable per commit sync for MySQL Aurora through parameter group tuning. I’m sure there are similar knobs for postgres
yes they are, but you can’t disable fsync in postgres aurora, you need to play with workmem, temp tables and such
2020-11-12
hi, for the cloudposse/elasticache-redis/aws module, there is no mention of tags. anyone able to tel me how to?
So what kind of problems are you folks trying to or have successfully solved recently?
I am trying to get IaaC right in oder to deploy the same EKS cluster with service roles and helmfiles for alb, ingress, cert-manager, external-dns, etc. And for several environments (dev, prod, stg, …) And keeping the differences between them low. At the end Gitlab CI will deploy each branch to an own namespace “deployment” to be accessed using an unique URL. VPN access too. And you?
that sounds like a beautiful endeavor! I tried to do something similar. EKS has been lowered in priority for us so we won’t get to conquer it until Q1 next year.
I’m currently trying to solve giving devs iam permissions using a permission boundary. I’m hoping I can get this out the door this week and unblock a lot of devs. Meanwhile, I’ve been exploring arm a lot in our ECS clusters so it always seems to be a balancing act.
@RB here’s how we manage the requirement for the permissions boundary…
Thanks Loren. I’m using basically this same policy from the aws blog on perm boundary

Today, AWS released a new IAM feature that makes it easier for you to delegate permissions management to trusted employees. As your organization grows, you might want to allow trusted employees to configure and manage IAM permissions to help your organization scale permission management and move workloads to AWS faster. For example, you might want […]
yeah, that one flips the logic, using Deny with StringNotEquals instead of Allow with StringEquals
may i ask what you use for the permission boundary policy ? we’re still trying to figure out what’s the best maximum permissions to give without giving too much. we were thinking of removing all deletion, for instance.
we actually use the same policy we assign to the role. it’s primarily to prevent privilege-escalation, for our use case
that doesn’t work of course if you apply multiple policies to the role
but say you have a DEV role, with only the DEV policy attached, you can require the DEV policy as the permissions boundary for any role/user they create to prevent privilege escalation
pain points have been places where the console will auto-create roles when the user first attempts to use the service. such as service-linked roles, and the rds-monitoring role, etc… so we pre-create those in the account as we identify them
ah so whatever access the DEV role has, it can also create roles with max permissions as the DEV role since the single DEV policy is used as the boundary
our issue is that we have multiple iam policies associated to our DEV role
so i was going to create a separate maximum iam policy to use as a perm boundary policy
yeah, so that doesn’t work so well then, and you have to come up with an actual policy for the perm boundary separately
pain points have been places where the console will auto-create roles when the user first attempts to use the service. such as service-linked roles, and the rds-monitoring role, etc… so we pre-create those in the account as we identify them
yes, i can see this being an issue. we have most of these created in our accounts so hopefully this wont be an issue. we’re worried about existing iam roles exceeding the perm boundary so retroactively attaching may be an issue
yeah, so that doesn’t work so well then, and you have to come up with an actual policy for the perm boundary separately
exactly. we’ll have to be crafty here. not much online about this except for the aws blog side.
yes, we also rolled through all accounts and slapped the perm boundary on pre-existing roles/users when we shipped the perm boundary requirement
awesome! how did you verify that each role did not exceed the permission boundary tho ?
it’s a fairly permissive policy for this environment, so we didn’t expect issues and encountered none
ah I see. We have a more strict environment. Perhaps that’s something we can work on.. making things looser.
yeah, the stricter the perm boundary policy, the more likely you’ll have problems
we stick with basic stuff around security and auditing that we manage in the account. if we create it, you can’t touch it. that kind of thing
Thanks everyone this looks like will help us out with IAM permissions for devs in their sandpit account. Currently IAM:* is basically off but we need to enable so they can do lambda etc. Will do some reading.
We’re currently investigating rabbitmq service. Want to kick our k8s one out of cluster and get from 115 to 118 etc.
Has anyone played with https://github.com/aws-samples/aws-secure-environment-accelerator/ before ? It’s massive.
The AWS Secure Environment Accelerator is a tool designed to help deploy and operate secure multi-account AWS environments on an ongoing basis. The power of the solution is the configuration file w…
i have not. i dont think i would touch it because it is massive. i’d prefer if it was broken up into modules.
we dont use code commit either.
The AWS Secure Environment Accelerator is a tool designed to help deploy and operate secure multi-account AWS environments on an ongoing basis. The power of the solution is the configuration file w…
Hi, one noob question - what about ALB outbound traffic? When client make request on port 443, for example, to some application the request will go through ALB to that EC2 instance and then response will go through ALB again (on high number unprivileged ports), so I was wondering, if I restrict egress traffic on my EC2 instances’ SG, should I also do the same for ALB? Is there a reason to restrict egress traffic on ALB? Thakns!
Is there a reason that this can’t be handled directly on the ALB itself? I’m a beginner too.
ALB has it’s own security group.
How did you teach yourself about SGs?
not enough I need to just read some simple code and keep moving
Does anyone here use a framework for testing CIS Benchmark foundations in AWS? I’ve seen things like: https://github.com/mberger/aws-cis-security-benchmark#description, but I’m wondering if they’re worth the risk.
Tool based on AWS-CLI commands for AWS account hardening, following guidelines of the CIS Amazon Web Services Foundations Benchmark (https://d0.awsstatic.com/whitepapers/compliance/AWS_CIS_Foundati…
and by testing, do you mean ensuring your safeguards for CIS compliance are working, or putting the safeguards in place?
Tool based on AWS-CLI commands for AWS account hardening, following guidelines of the CIS Amazon Web Services Foundations Benchmark (https://d0.awsstatic.com/whitepapers/compliance/AWS_CIS_Foundati…
Because if you mean the latter, that’s what you get with SecurityHub standards.
We’ll have support for security hub in the next day or so. @matt is working out the last details fixing our tests for https://github.com/cloudposse/terraform-aws-security-hub/pull/3
what Create the basic initial AWS Security Hub module and test
I really don’t know what that code is doing. I learned what a resource and datasource was last week. Time to give it the old college try.
are you using terraform at your company?
Yes
I keep on getting
Error updating CloudTrail: InsufficientEncryptionPolicyException: Insufficient permissions to access S3 bucket nf-cis-benchmark or KMS key arn:aws:kms:us-east-1:721086286010:key/af37e59b-e5fa-446c-b43c-180b425c6222.
when I try to apply my terraform with a kms_key
resource aws_kms_key "cisbenchmark" {
description = "cis-benchmark"
enable_key_rotation = true
}
I’m trying to setup my cloudtrail with a key like so
resource "aws_cloudtrail" "cisbenchmark" {
name = "cis-benchmark"
s3_bucket_name = aws_s3_bucket.cisbenchmark.id
enable_logging = var.enable_logging
enable_log_file_validation = var.enable_log_file_validation
is_multi_region_trail = var.is_multi_region_trail
include_global_service_events = var.include_global_service_events
is_organization_trail = var.is_organization_trail
kms_key_id = aws_kms_key.cisbenchmark.arn
# CIS Benchmark 3.1 Ensure CloudTrail is enabled in all regions
# for a multi-regions trail, ensuring that management events configured for all type of
# Read/Writes ensures recording of management operations that are performed on
# all resources in an AWS account
event_selector {
# Specify if you want your event selector to include management events for your trail.
include_management_events = true
# Specify if you want your trail to log read-only events, write-only events, or all. By default,
# the value is All. Needed for logging management events.
}
}
I stole some of this from your guys code.
@matt has joined the channel

You can now send logs from AWS Lambda functions directly to a destination of your choice using AWS Lambda Extensions. Lambda Extensions are a new way for monitoring, observability, security, and governance tools to easily integrate with AWS Lambda. For more information, see “Introducing AWS Lambda Extensions – In preview”. To help you troubleshoot failures […]
2020-11-13
Hi Everyone. I just stared experimenting with IRSA on EKS and it is working great.
I just have one quesiton about the projected volume with the JWT token from AWS
volumes:
- name: aws-iam-token
projected:
defaultMode: 420
sources:
- serviceAccountToken:
audience: sts.amazonaws.com
expirationSeconds: 86400
path: token
What happens when the expirationSeconds expire ?
I know from the k8s documentation ( so one where audinece is not external ) that it will renew at 80% … is it the same in this case ?

The AWS Heroes program recognizes individuals from around the world who have extensive AWS knowledge and go above and beyond to share their expertise with others. The program continues to grow, to better recognize the most influential community leaders across a variety of technical disciplines. Introducing AWS DevTools Heroes Today we are introducing AWS DevTools […]
Am trying cluster migration in AWS, Both k8s clusters are in same region. Cluster 1 : Deployed 2 Application with PV reclaim policy one as Delete and another as Retain, and annotated so it will take Restic backup. Cluster 2: Restored those 2 applications, worked fine.
again
Cluster 1: Deployed same 2 application with Reclaim policy as Delete and Retain but not annotated so it took snapshot when i backup.
Cluster 2: Restore did not work as PV volume is failed to attach with the following Warning FailedAttachVolume pod/<pod-name> AttachVolume.Attach failed for volume "pvc-<id>" : Error attaching EBS volume "vol-<id>" to instance "i-<instance-id>": "UnauthorizedOperation: You are not authorized to perform this operation.
So, Snapshot restore feature will work in the same AWS region or am only getting this error????
2020-11-14
planning out a future website structure and wondering if I can have a single cloudfront distro with two S3 bucket origins
cloudfront distro: sample.cloudfront.net CNAME/Alias that points foo.com to sample.cloudfront.net
S3 bucketA contains: foo.com [foo.com/foo/](http://foo.com/foo/) [foo.com/bar/](http://foo.com/bar/)
S3 bucketB contains: [foo.com/bat/](http://foo.com/bat/) [foo.com/biz/](http://foo.com/biz/)
seems like I cannot do this at the cloudfront origin level even with using a custom behavior and a pattern match
can I: put redirects in bucket A to redirect [foo.com/bat/](http://foo.com/bat/) and [foo.com/biz](http://foo.com/biz) to bucket B ? if I do that ^ should I put another cloudfront distro in front of bucket B (bucketB.cloudfront.net) and point the redirects at that ?
so that:
[foo.com/](http://foo.com/)-> alias for sample.cloudfront.net -> bucketA [foo.com/foo/](http://foo.com/foo/) -> alias for sample.cloudfront.net -> bucketA [foo.com/bar/](http://foo.com/bar/) -> alias for sample.cloudfront.net -> bucketA
[foo.com/bat/](http://foo.com/bat/) -> alias for sample.cloudfront.net -> bucketA -> bucketA redirect to bucketB.cloudfront.net -> bucketB [foo.com/biz/](http://foo.com/biz/) -> alias for sample.cloudfront.net -> bucketA -> bucketA redirect to bucketB.cloudfront.net -> bucketB
any other options ?
some top level router thing that points paths to cloudfront distros ?
You can do that. It would be represented as two origins, four url behaviours, and one default url behaviour
There’s a rather low limit on url behaviours by default though (I think 20) so you can’t scale it up too far if that’s a concern
It can scale using lambda@edge : https://docs.aws.amazon.com/AmazonCloudFront/latest/DeveloperGuide/lambda-examples.html#lambda-examples-content-based-S3-origin-request-trigger
Examples of functions for Lambda@Edge.
@Alex Jurkiewicz thanks! testing it out today.
I don’t know if cloudfront supports multiple origins but I have done this with cloudfront and a nginx proxy and many buckets with different routes
2020-11-17
so I have a distribution working with 2x origins, but having trouble getting the /bat/*, /biz/** routes to flow to bucketB in example above ^
404 Not Found
Code: NoSuchKey
Message: The specified key does not exist.
Key: bat/index.html
so all content needs to be in the /bat/ directory on the target origin ^
Instead of using a bucket as origin, you can also use a bucket as “Custom origin”, this way it should be possible to change the default path.
yep
2020-11-18
hey all, was going to cross post here as it sounds like this is a better channel for these types of questions https://sweetops.slack.com/archives/CB6GHNLG0/p1605655766298600
:wave: Is there a way to define the session expiration time for the role an ECS task assumes in terraform? The AWS docs state that the default is 6 hours. max_session_duration for aws_iam_role only sets the allowed max session but it looks like when changing that to 12 hours, the ECS task’s role still uses the default 6 hour session duration
I’m annoyed by the AWS Support Feedback experience. I selected Good rather than Excellent and I got an email from the support engineers reporting manager asking why I gave the engineer a “low” grade. I can’t stop thinking about how awful that is and now every time I go to fill out the AWS Support Feedback form now a little part of me dies. I felt that it was necessary to try and do something about it. http://chng.it/gmtG8xqF
and yes I realize that “that’s how all feedback systems work” but I feel like this is something that we collectively can ask for better options
I’m totally open to feedback too
good old “5 stars is normal service” rating as popularised by the service economy
“help keep our employees precariously employed by giving us an excuse to fire them if they get close to a benefit date”
send this to Corey Quinn
forgive me I’m socially dysfunctional …who’s that?
I can Google, but I just feel weird sending somebody I don’t know a DM…again bad at the social thing. I don’t really take part in the social medias. Slack is the only thing I stick with because it feels like less of a blackhole of dialog..and people are generally more rational.
he runs the Last Week In AWS blog
and does AWS consulting
very funny guy
if others agree with my position and want to share it out I’m all for it. I want to try to do something to change the stats quo because (1) it hurts our fellow engineers (2) it doesn’t help us at all
buuuut, my amount of trying probably equates to about 1hr of effort
you could just email that to jeff bezos and ask him “wtf”
I could, or I could just drop a dumbbell on my foot
? I mean that Bezos pretty famously deals with customer feedback like this in a very serious way
oh sorry, I thought you were being facetious
heh, no - his email at amazon is public and people will on occasion send him product complaints about amazon or aws
I can give that a shot too but just figured that the only way real change was going to happen if Amazon saw that it’s something we collectively cared about as it’s customers…you k now how typical large enterprises operate
thanks @Zach I sent it off – who knows if it will go anywhere but makes me feel like I’m doing my part to try to help our fellow engineers working the support desk at AWS
2020-11-20
Has anyone restricted outgoing traffic from ec2 instances via security groups with success? I’ve enabled a lot of VPC endpoints, but I still see a lot of outbound traffic towards AWS subnets for which I cannot identify the service that they belong to.
do you have non-VPC Lambdas? those are usually the culprit for me
wait, you mean just from the ec2? Sorry I thought you meant account wide
Hello
My company has a domain purchased say mydomain.com with GoDaddy and it is today mapped to servers running on prem. We are migrating to AWS and have our Route 53 DNS and public hosted zone setup as ourcoolcloud.com (say). We want to setup the DNS routing such that when our clients hit mydomain.com it actually gets proxied to ourcoolcloud.com. We do not want the ourcoolcloud.com to appear in the client browser and we may drop mydomain.com at some point and purchase a cooler name. We do not want to keep changing our AWS HZs. Is there some DNS voodoo we can do to make this routing happening from mydomain.com - > ourcoolcloud.com without the client seeing this in the browser ?
Can you change the A record for mydomain.com to be the same value as the one for ourcoolcloud.com? If you are using an alias to an AWS ALB/ELB then probably not, but if you are just pointing at an IP address then you should be able to just point both A records to the same IP address
I am thinking not since ourcoolcloud.com would typically point to a CloudFront distribution and would have other record sets say ALBs etc.
Would a CNAME record suffice ?
I’m not an expert at DNS. I know just enough to be dangerous. If I was in your shoes I’d be finding someone who is an expert, and if there aren’t any that I can get, hiring a consultant.
DNS can be quite complicated, and in most cases it is a single point of failure. If you screw something up your whole site will go down. Most of the downtime for the big players like CloudFlare, AWS, etc, have been because someone screwed up a DNS setting
thank you so much for taking the time to understand the problem. I’ll try and see if I can do a spike or something to test how this would work using a test DNS maybe. I’ll share the results here just for future reference. Thank you again
https://github.com/awsdocs/aws-cloudformation-user-guide/pull/438
A >1 year old trivial doc change finally getting attention, but they require YOU to rebase it. Contributing to AWS docs in a nutshell.
Issue #, if available: Description of changes: By submitting this pull request, I confirm that you can use, modify, copy, and redistribute this contribution, under the terms of your choice.
2020-11-21
Hello All, How are you today? ‘Im looking for a cloud formation stack to deploy traefik reverse proxy on ecs
Can you use Terraform instead?
https://registry.terraform.io/modules/colinwilson/traefik-v2/docker/latest
nope :(
2020-11-23
Hi, I have a domain, for example test.com and I want to delegate delegate.test.com to another AWS account. I was able to do that but I can only create A records for a.delegate.test.com and b.delegate.test.com for example but I need to create A record for delegate.test.com. Can I do that from the account to which I delegated the zone to? Thanks!
you have two hosted zones now: test.com delegated.test.com
test.com has an entry [delegate.test.com](http://delegate.test.com) IN NS …
This means that all records for the domain delegate.test.com (including the A record for the top level domain) will be handled by the NS servers configured in the test.com IN NS record and those records are handled by delegate.test.com hostedzone (in whatever aws account this hosted zone is deployed)
Thanks Maciek!
2020-11-24
using: https://github.com/cloudposse/terraform-aws-efs is it possible to turn off the creation of a security group and pass one to it instead?
Terraform Module to define an EFS Filesystem (aka NFS) - cloudposse/terraform-aws-efs
try #terraform
Terraform Module to define an EFS Filesystem (aka NFS) - cloudposse/terraform-aws-efs
thanks
Hi All, We are having an Application in Lambda, is there any way we can backup that for Disaster Recovery. or how Amazon does this for us. Thank you.
Hey @Shreyank Sharma Im not sure what do u mean by backing up a lambda function for DR - I would just keep the infra configuration and the lambda application + cicd code in a git repo ?
The backup is simply your code in your repo, the ‘lambda’ in AWS is just the runtime configuration
Help, is there any way to list all services that I’m using on my AWS account?
You can use CostExplorer to get the list of AWS resources/services that you are being charged for
my attempt at lifecycle hook niche awesome list https://github.com/nitrocode/awesome-aws-lifecycle-hooks
Awesome aws autoscaling lifecycle hooks for ECS, EKS - nitrocode/awesome-aws-lifecycle-hooks
i couldn’t find a resource that aggregated all of it. it was a bit disparate. i tried to put it all together.
Awesome aws autoscaling lifecycle hooks for ECS, EKS - nitrocode/awesome-aws-lifecycle-hooks
if anyone knows of additional lifecycle hooks for other services or whatever, please let me know
im still trying ot figure out the difference of using only cloudwatch (ecs-drain-lambda), using sqs (claranet method), and using sns
2020-11-25
and this is why I tell people DO NOT DEPLOY in us-east-1
I know better and yet one of my larger clients is running in us-east-1
Do you mean us-east-1 is the aws staging environment?
tbh for me it’s the 2nd larger outage that I’m affected by in roughly 7 years of running stuff in us-east-1. first one being s3 outage (happily we lived through it without downtime) few years back.
and currently i see longer response times from firehose endpoint (800-1000ms instead of normal 50-80ms) and cognito endpoint is completely down
We’re having troubles with ECS auto scaling and scaling out. Desired tasks threshold is not triggering new task creation and some tasks are failing to be placed due to “limited capacity”. I think it’d all tied to CloudWatch problems.
yeah and CW is failing because of kinesis streams which IMO started the domino to fall. Happily for me I’ve quite good understanding of CPU needs and cosidering those few k rpm i’m receiving on a constant basis if no instance will be replaced i should be fine
@rei I always thought that
when AWS has issues, a lot have too
still down…..shit tomorrow 3000 people from amazon fired
so now that shit hit the fan people will start migration to us-east-2 and then it will go down
hey guys, just dipping my toe in with https://registry.terraform.io/modules/cloudposse/tfstate-backend/aws/latest and I can’t get it to create the bucket, lol
Initializing the backend...
Successfully configured the backend "s3"!
...
Error: Failed to get existing workspaces: S3 bucket does not exist. <--
The referenced S3 bucket must have been previously created. If the S3 bucket <-- uhhh, what?
was created within the last minute, please wait for a minute or two and try
again.
Error: NoSuchBucket: The specified bucket does not exist
status code: 404, request id: 08C447AD410DF430, host id: a6btOtHixZYbFcNJ8E+gpLoFP9vw4MIvFfibWxHrtQwB+tf2HSDJ9bbMvmGRBDt9BmqW/XoZUzY=
You need to first create the resources with a local backend and then transition over.
Usually you should do this through having a separate root module for your tfstate-backend which bootstraps your backend
@voidSurfr did you see these? I think the above is your immediate problem.
sorry, I was attending office hours. I’ll double-check your notes against my issue.
you do something like : terraform apply -var-file='production.tfvars' -target module.terraform_state_backend
with local state defined
once the s3 bucket is created , hen you can define the backend-config on a file or main.tf and then
terraform init -var-file='production.tfvars' -backend-config=production-backend-us-east-2.tfvars
and it will ask you to move the local state over
this is all on the README
can someone help me to understand this?
2020-11-27
Hi guys! QQ we are in AWS, and we are finding some global cron scheduler to run tasks. I know Rundeck but something more SaaS? Something that dev teams do not depend on IT operations to create things in terraform like lambdas triggered by cloud events, or ECS tasks that run based on events…. need something easy and fast for dev’s. Thx!!!!!
Cloudwatch events has cron support for scheduled triggers, codebuild works as a target and can run arbitrary commands
Or cloudwatch events to lambda works fine
I think ssm automation is also an option
yeah thx! I have found as well this https://github.com/blinkist/terraform-aws-airship-ecs-service
Terraform module which creates an ECS Service, IAM roles, Scaling, ALB listener rules.. Fargate & AWSVPC compatible - blinkist/terraform-aws-airship-ecs-service
We even have an #airship channel :-)
cool!
Sounds like you want something managed? But how about Serverless Framework? It satisfies your Lambda requirement easily. Defining events is really easy in the serverless.yml file.
Not sure how well it’ll fit with ECS but found this: https://www.serverless.com/plugins/serverless-fargate-tasks
Part of the challenge here is coming up with sufficiently restrictive policies to allow developers to deploy without being able to change things they shouldn’t.
Also managing everything for cost and tracking purposes will require some thought. Serverless.com paid offering might help with that but I’ve not used it yet.
A plugin to run fargate tasks as part of your Serverless project
also, since you mentioned something easy one thing we use a lot of is Zapier and Integromat. Both of them have cron like functionality.
Oh yeah, ofc! @Erik Osterman (Cloud Posse) just curious - would you choose one over the other? I was looking at doing something with Xero the other day, and for some reason the Integromat connector was more full-featured.
Yea, we started with Zapier so we have ~300 zaps there. However, if we were starting from scratch would 100% use Integromat. Easy things are a little bit harder to do in integromat (compared to Zapier), but it more than makes up for it with all the advanced features. I feel like Integromat is more geared towards advanced users / programmers. It has iterators, routers, variables, etc. If their integration doesn’t provide the API endpoint you want, they usually provide a raw method to use the integration. Integromat supports handling errors, while Zapier doesn’t.
Ah thank you for the insight! Very useful.
Integromat’s API looks pretty good too
very valuable info, thx all!
2020-11-28
AWS Kinesis incident details: https://aws.amazon.com/message/11201/
Good week-ends reeding In short, use just EC2 instances and don’t use new and fancy services because everything is interconnected internally.
I deeply disagree with that. The best example against it is the experience iRobot had: https://twitter.com/ben11kehoe/status/1332391783829913600
Yes, they had a bad incident, but it was: 1) rare, and by managing EC2 themselves they would’ve definitely had more incidents + higher cost + huge opportunity cost 2) relaxed, as in they had to wait for AWS to recover. No stress, no fighting to figure out the root cause, no marketing hit of “Roombas are down” but “A bunch of IoT things are down”
I want to talk a bit about what this was like. tl;dr: it was long and inconvenient timing but, as an operations team, not particularly stressful. Questions of “when”, not how or if systems would come back. A lot of waiting and watching—and that’s desirable. https://twitter.com/ben11kehoe/status/1332028868740354048
I’m still working with my team to mitigate the after effects of the day-long AWS outage yesterday, including dealing with follow-on AWS issues. I’ve gotten three hours of sleep and it’s ruining my Thanksgiving day. Hot take: I am thankful we have built serverless on AWS.
… it was trolling from my side. I understand that such incidents happen all the time. Smaller or larger, and it is our job to prepare and minimize impact as much as we can.
welp, I did not catch that. Sorry!
Some people posted on linkedin during an incident that their EC2+RDS services were 100% up during that period, so they are lucky that they don’t use fancy services… and then it started a “discussion” ec2 VS serverless :)))
The discussion we’re having is: “should we replace AZ-level redundancy (within us-east-1), with the more resource intensive region-level redundancy”.
2020-11-29
Is there a simple explanation of minimum security group configuration for an internal load balancer, target groups, and ec2 instances ? I’m a bit confused
This explains the load balancer sg rules but not the ec2 instances
Learn how to update the security groups for your Application Load Balancer.
The security group on the EC2 instances should allow ingress and egress to the load balancer security group, and vice versa.
I would suggest adding allow all out egress rule to both groups as well though.
Anyone know if the a) asg instance refresh or b) manual termination invokes the lifecycle hooks?
There are only 2 references to lifecycle hooks here https://docs.aws.amazon.com/autoscaling/ec2/userguide/asg-instance-refresh.html
Describes the scenario of replacing the Amazon EC2 instances in your Auto Scaling group, based on an instance refresh.
It does yes
Well, I can say for sure it certainly invokes the create hook, we don’t make use of the termination one
You’re saying only the insurance refresh will invoke the lifecycle hook?
No I’m just confirming that instance-refresh definitely does. I assume it triggers in both cases that you’re asking though
we make use of it regularly
from my tests, it looks like manual termination of the ec2 instance does not invoke the lifecycle hook
ah and it looks like an instance refresh does invoke the lifecycle hook. thank you.
interesting. I guess they take the stance that if you manually asked for a termination that you want it done right now
weird. i spoke with support and they said that manual terminating should invoke the hook
perhaps the https://github.com/getsocial-rnd/ecs-drain-lambda just doesn’t work for the manual termination
Automation of Draining ECS instances with Lambda, based on Autoscaling Group Lifecycle hooks or Spot Instance Interruption Notices - getsocial-rnd/ecs-drain-lambda
ah ok it was a miscommunication. Confirmed with support that manual termination from the UI does not run the lifecycle hook but it does if the aws autoscaling terminate-instance-in-auto-scaling-group cli command is run
oh and what about asg max instance lifetime settings ? does it invoke the lifecycle hook too ?
Describes the scenario of replacing the Amazon EC2 instances in your Auto Scaling group, based on a maximum instance lifetime limit.
2020-11-30
is anyone able to help me understand VPC peering, I have created a terraform module and applied it but am struggling to understand one thing ….
I want to peer the private subnets from account X with the database subnets from account Y
Where do I need to enable dns resolution to allow the instances in the private subnet to use internal hosted zones in account Y ?
@Steve Wade (swade1987) you need to enable DNS resolution at the VPC peering config
Let me show you
thanks man your help is much appreciated
We enabled it for some of our VPC peerings.
so i need to enable in the VPC connection in account X, right?
Yep//// you’re right !
let me try that
it doesn’t seem to be working with nslookup
Wait… I think you should do it the other way….
ok let me try that
I read your config again
trying …
Cool… let me know how that goes
will do
nope
could it be security group related?
Wait…weird…. are you having issues with DNS resolution or with TCP connectivity ?
root@test-shell:/# nslookup elastic.logging.de.qa.underwriteme.internal
Server: 172.20.0.10
Address: 172.20.0.10#53
** server can't find elastic.logging.de.qa.underwriteme.internal: NXDOMAIN
Is that K8S by any chance ?
100% its EKS
Are you doing that from a POD ?
yes i am
I’m wondering if that could be an issue… would you be able to do that from a regular EC2 instance ?
we are using bottlerocket so going onto the node isn’t the easiest for me unfortunately
Hmmm gotcha
i might just try dns resolution from both sides
oh shoot is it because i am peering with the database subnets from the upstream VPC module which deny inbound, don’t they?
What do you mean. When you configure VPC peering, you peer the entire VPC
And then you configure SGs and Routing Tables to allow certain traffic
Have you configured both ?
let me create a gist it might be easier
i tried traceroute as well to no avail
i think my routing logic is correct
@Santiago Campuzano i have an update, i can nslookup from account X to an instance in the database subnet in account Y without a problem, the issue is just DNS resolution is not working
root@test-shell:/# nslookup redacted.cssoccfscup8.eu-west-1.rds.amazonaws.com
Server: 172.20.0.10
Address: 172.20.0.10#53
Non-authoritative answer:
Name: redacted.cssoccfscup8.eu-west-1.rds.amazonaws.com
Address: 10.60.26.86
@Steve Wade (swade1987) What do you mean by you can nslookup but DNS resolution is not working. ?
That is like contradictory
I mean… nslookup is pretty much DNS resolution
i can nslookup to an AWS known DNS record (see above)
Ok… and you’re able to get the private IP address from that RDS instance
i can’t resolve custom private DNS addresses
e.g. [yellowfin.rds.de.qa](http://yellowfin.rds.de.qa).underwriteme.internal which is a CNAME to an RDS endpoint
Hmmm got it… you’re resolving the public IP, not the private one
currently i have dns resolution setup on both sides
maybe i need to turn off account X like you said before?
I would give it a try….
made no difference
i wonder if this has something to do with coredns configuration?
or maybe i need to create a route53 resolver?
I was checking my config, and I don’t have the R53 resolver configured
but are you peering the whole VPCs together?
or subnets in account X to others in account Y ?
The whole VPCs together
yeh i think that might be the difference
Well…. wait.. is it possible to peer certain subnets ?
AFAIR you peer the entire VPC
not certain subnets/CIDRs
well the route tables are subnets
Ok… The route tables indicate what traffic to send through the VPC peering…
yeh mine looks right
the issue is just the private dns resolution is not working
I would discard. the EKS component of this equation
I’d create a simple Ec2 instance and try from there
The DNS resolution
EKS/K8S DNS resolution is weird sometimes
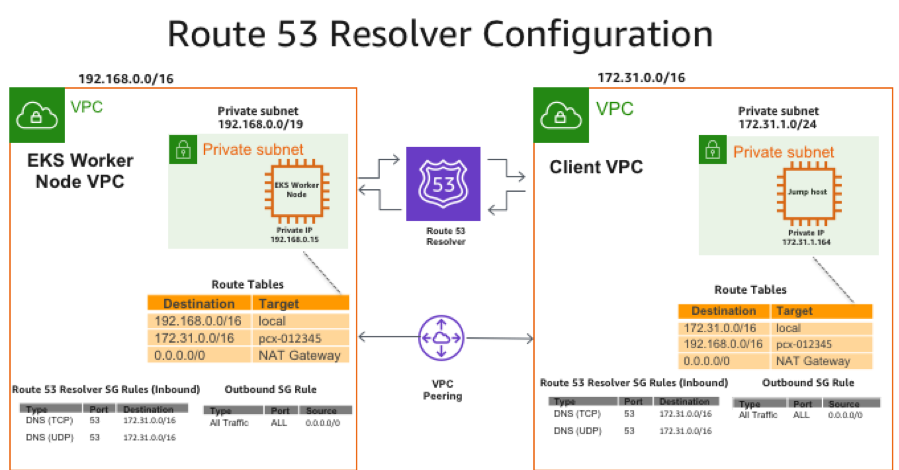
Update – December 2019 Amazon EKS now supports automatic DNS resolution for private cluster endpoints. This feature works automatically for all EKS clusters. You can still implement the solution described below, but this is not required for the majority of use cases. Learn more in the What’s New post or Amazon EKS documentation. This post […]
Morning @Steve Wade (swade1987) !
How this ended up for you ?
The DNS resolution issue ?
after talking to AWS you can do this via the command line
Anyone using ACM private CA (PCA) with root CA and subordinate CAs in separate accounts (as recommended by the best practice section of the PCA docs)? I’m bashing my head against the wall trying to work out how to have the root CA sign the subordinate’s certificate and import the certificate to get it into an active state.
If I try a RAM share of the subordinate into the root CA’s account (which uses the RAM-managed permissions) trying to sign the subordinate from the root account fails with 1 validation error detected: Value at 'csr' failed to satisfy constraint: Member must satisfy regular expression pattern: -----BEGIN CERTIFICATE REQUEST-----... which makes me suspect that the root CA/account can’t read the CSR for the subordinate, but of course I can’t change the permissions since RAM manages them. Can’t see what the alternative workflow would look like - I don’t see anything in the docs.
Oh and yes, trying to view the CSR of the subordinate as shared by RAM in the root CA account just beachballs, which is another tint on the permissions side of things.
Going the other way, and sharing the root CA into the account with the subordinate doesn’t work with the “Import CA” -> “ACM private CA” flow in the console, as the root isn’t presented as an option.
…And Terraform doesn’t support most of the PCA operations.
Hey folks Whats the recommended way to partition environments and related infra? want to keep prod env as much isolated as possible, but still want to ensure pace of development. We are a relatively new startup ~6 eng, so am just setting things and process up.
either separate AWS accounts or separate VPCs is what we do (depending on scale)
@Erik Osterman (Cloud Posse) did a good overview in office hours a few weeks ago
ah thanks, do we have recording of those? Till now I have decided to go with separate vpc, not sure where shared services like logs/metrics etc should go. I have read that they should generally go into a different “shared” environment, but not sure of how their config etc would be tested. Like where should staging version of such shared services go?
We’re a DevOps accelerator. That means we help companies own their infrastructure in record time by building it with you and then showing you the ropes. If t…
I couldn’t find the exact video (there’s a lot there). A “Cloud Posse Explains: AWS Account/Environment Laydown” video would be helpful
Who the hell is that ugly guy @Erik Osterman (Cloud Posse)?? You really should keep out the rifraf
ah thanks for the help and the direction.
We’re actively releasing stuff every week as part of our reference architecture. It’s too early to point you to something concrete. But by end of december it will be much closer. Documentation will begin in earnest Q1 2021.
All of our top-level AWS components are here: https://github.com/cloudposse/terraform-aws-components
Catalog of reusable Terraform components and blueprints for provisioning reference architectures - cloudposse/terraform-aws-components
this is the future home of our reference-architectures https://github.com/cloudposse/reference-architectures but its documentation is stale and examples incomplete.
[WIP] Get up and running quickly with one of our reference architecture using our fully automated cold-start process. - cloudposse/reference-architectures
we’ll definitely be recording lots of videos, demos, walkthrus in addition to more step by step documentation.
re:Invent gets extended: https://twitter.com/txase/status/1333559564998828032
Looks like three weeks of @awscloud #reInvent2020 may not be enough for folks. Ready for a round 2 in January? https://reinvent.awsevents.com/agenda/ https://pbs.twimg.com/media/EoHBPa9VgAAo9Si.jpg
what, they do not have enough seats?????????
scalpers probably going to sell seats on ebay
HAHAHA lol