#aws (2021-08)
 Discussion related to Amazon Web Services (AWS)
Discussion related to Amazon Web Services (AWS)
Discussion related to Amazon Web Services (AWS)
Archive: https://archive.sweetops.com/aws/
2021-08-02
I’ve created an Automation Document using cloud formation to update the live alias for a given function. It runs ok without any errors and I’m not seeing anything cloud trail. But when I check which
Not sure if this is the right place to post but I am having a heck of a time trying to figure out why my Lambda is is not getting triggered by MSK. When I setup the trigger I end up getting this error after a bit of time: PROBLEM: Connection error. Please check your event source connection configuration. This error is not super helpful so I am wondering if there is another spot to get more details. I have tried a number of things including trying to run the lambda in the same VPC as my cluster but no luck. This could be related to how the cluster is setup but wonder if anyone has any pointers on where to get some more troubleshooting logs or info (also, my lambda does nothing, just logs right now cause I want to make sure everything is wired up first).
sounds like a case for aws support. Does the Lambda VPC configuration need to access a MSK endpoint in your VPC? Does the security group allow this?
2021-08-03
Hi there, I was wondering if I could duplicate traffic with ALB. we want the same traffic that goes to production also goes to the staging ECS target group as well. Is there a way to go around this?
Is that what you want? https://aws.amazon.com/fr/blogs/aws/new-vpc-traffic-mirroring/
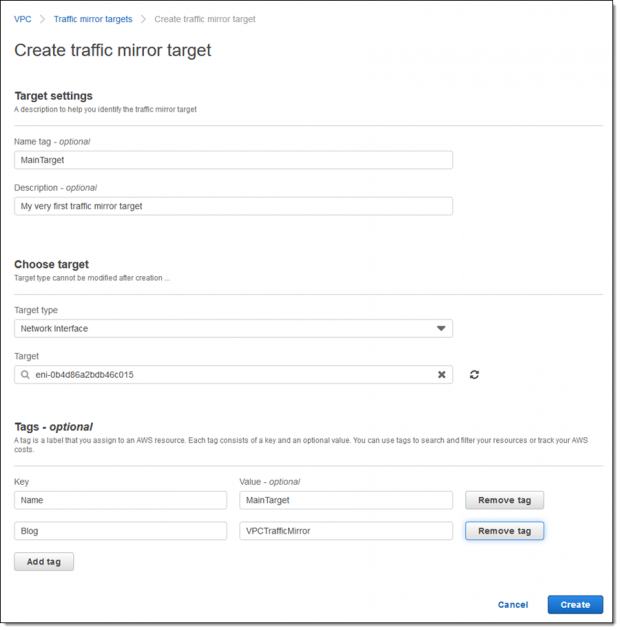
Running a complex network is not an easy job. In addition to simply keeping it up and running, you need to keep an ever-watchful eye out for unusual traffic patterns or content that could signify a network intrusion, a compromised instance, or some other anomaly. VPC Traffic Mirroring Today we are launching VPC Traffic Mirroring. […]
2021-08-04
https://github.com/jpillora/chisel
Exploring this reverse tunneling tooling in chisel project and wrapping my head around this and how it would work with a containerized infrastructure with ECS Fargate.
Is anyone using Docker containers for a service that assigns random ports for each open session? I really want to stick with ECS Fargate if I can, but with several hundred ports maintaining open sessions and passing traffic though, I’m not certain yet that it will support that without issues.
On a high level, I’m assuming (correct me if you disagree), if a server needs to maintain open sessions with each = unique random port, I’m going to have to stick with a normal EC2 Server most likely if scaled beyond a couple tunnels.
A fast TCP/UDP tunnel over HTTP. Contribute to jpillora/chisel development by creating an account on GitHub.
I have an issue with the HTTPS Listener on ALB not been updated when the Green/Blue Deployment is done. Since this uses two target groups to handle the traffic shift, it automatically changes the HTTP listener to the replacement task while the HTTPS remains on the Green(Old) target. in the case the ALB to return 503 error since both Listener is not on the same target groups. To solve this I have to go to the HTTPS listener and change it to the replacement task target group. Is there a way I can get HTTPS to listen to the deployment and update the target group itself as the HTTP Listener does?
Are you using CodeDeploy?
Yes @Mohammed Yahya
you need to make sure traffic shifting happened on all listeners http and https - the question is why you need both,
For the SSL. i believe if i didn’t add the HTTPS listener to the ALB the subdomain won’t be available on the API once pointed to the ALB. Correct me if am wrong please
you need one listener HTTPS, and create redirect rule on ALB from HTTP to HTTPS, the api, or any subdomain should work - you can create rules on the ALB for subdomains
you can publish the api two ways, using subdomain or using sub paths
Oh, Now I get. I should
- add API subdomain to with HTTP host Header and redirect to HTTPS
- On HTTPS add subdomain again and forward to the target group. Is that correct?
Yes.
2021-08-05
I want to check an interpretation of “least-privilege” in AWS IAM, and see if others interpret this differently. If someone were to ask me to design a policy that is “least-privilege”, I would think the more exact the Actions and Resources, the better.
{
"Sid": "",
"Effect": "Allow",
"Action": [
"lambda:*",
"events:*"
],
"Resource": [
"arn:aws:lambda:region:123456789012:rule/my-pattern-*",
"arn:aws:lambda:region:123456789012:layer:*",
"arn:aws:lambda:region:123456789012:function/my-pattern-*"
]
}
Is this accurate or is “least-privilege” more so on the Actions that are in the policy and not the resources?
{
"Sid": "",
"Effect": "Allow",
"Action": [
"s3:PutObject",
],
"Resource": [
"arn:aws:s3:::bucket-name/*",
]
}
https://docs.aws.amazon.com/IAM/latest/UserGuide/best-practices.html#grant-least-privilege I can’t really tell from the best practices page, what is actually “good enough”. Or is it actually, resources would ideally be specific arns only?
Follow these guidelines and recommendations for using AWS Identity and Access Management (IAM) to help secure your AWS account and resources.
I would say least privilege would be specifying exactly what can be done and by whom.
In your first policy, any of those resources can perform any lambda or event action. To me that seems dangerous as it could allow a lambda function to create/delete other lambda functions at will.
The second policy is what I would consider a good least-privilege policy. A user/role with that policy attached can upload to a single bucket. There may even be cases where you’d want to restrict that further and only give access to upload to a single path inside the single bucket, but that’s just a further enhancement that may or may not be useful.
Follow these guidelines and recommendations for using AWS Identity and Access Management (IAM) to help secure your AWS account and resources.
So with the first one, do you find any value on the lambda name prefixes? Or is wildcarding actions just a bad idea?
There are exceptions to every rule, but I’d avoid wildcarding actions unless you have a really good reason.
One problem with a wildcard is it can actually grant more permissions over time if/when AWS adds more features to an API. And suddenly your policy allows more permissions than you intended.
It takes more effort to get the list of actions right, but IMO it’s worth it.
Good points. Thank you!
i’d agree that least privilege involves restricting both actions and resources
One thing I don’t like in the initial policy is how it combines two service namespaces into a single statement. Eg allowing lambda and event namespaced actions, and relying on the fact their ARNs are different. I prefer to explicitly separate them like:
{
"Sid": "",
"Effect": "Allow",
"Action": [
"lambda:*",
],
"Resource": [ "arn:aws:lambda:region:123456789012:layer:*",
"arn:aws:lambda:region:123456789012:function/my-pattern-*"
]
},
{
"Sid": "",
"Effect": "Allow",
"Action": [
"events:*"
],
"Resource": [ "arn:aws:events:region:123456789012:rule/my-pattern-*"
]
}
I walked into a sticky situation regarding SSO with multiple AWS accounts, roles, and external groups that’s tied into AD. There is a group per role per team per account or something to that extent. I spun up a mgmt account and plan on making a role that looks like <Prod/nonProd>-<team>-<role> so we’d have nonProd-SRE-admin, nonProd-SRE-readOnly, Prod-SRE-admin, and Prod-SRE-readOnly for starters. I don’t think that’s scalable beyond 4 or 5 teams, but it’s a huge improvement over 100+ groups. Any advice on a better short-term solution? I want to use some of the CloudPosse modules because it’s going to take a lot of effort to fix some of this.
in our org, we’re given a standard set of roles by the platform team’s automation whenever a new account gets spun up:
• org.app-or-program-name.nonprod.administrator
• org.app-or-program-name.nonprod.operator
• org.app-or-program-name.nonprod.readonly
• org.app-or-program-name.prod.administrator
• org.app-or-program-name.prod.operator
• org.app-or-program-name.prod.readonly the readonly accounts have access to AWS Support, so they can at least open support tickets.
i dont like it . none of it is mapped to AD. It’s still nice to use AWS SSO but still… bleh
Is anyone else having issues with yum on amazonlinux? http://amazonlinux.default.amazonaws.com/2/core/latest/x86_64/mirror.list is returning a 403 which seems not-correct
2021-08-09
Hello,
My company is interested in leveraging the Cloud Posse repo to build out a brand new AWS infrastructure, but I have no idea where to start.
All I (believe) we need to set up is
Accounts
IAM policies for these accounts?
Probably a VPC? Basically we will be running a couple HaProxy Enterprises in here
Probably route 53 configurations to point to haproxy?
Also, is there an easier way to n…
you will need all that
Hello,
My company is interested in leveraging the Cloud Posse repo to build out a brand new AWS infrastructure, but I have no idea where to start.
All I (believe) we need to set up is
Accounts
IAM policies for these accounts?
Probably a VPC? Basically we will be running a couple HaProxy Enterprises in here
Probably route 53 configurations to point to haproxy?
Also, is there an easier way to n…
you can find any module we have like for ecs eks and look at the /example/complete folder to get an idea of what is needed to get it running
2021-08-11
heads up that us-east-1 is having issues with AMI filtering incorrectly classifying images as ‘paravirtual’ which breaks a lot of things if you are trying to use ENA
support says this is “impacting other services” too
2021-08-12
Hello, I am trying to create a msk cluster with the module (https://github.com/cloudposse/terraform-aws-msk-apache-kafka-cluster) . When i provide the number_of_broker_nodes = 2 with two subnet ids (different AZs) . It is expected to create 4 broker in the cluster . but the module is creating only 2 . If i change the number_of_broker_nodes = 3 or more then i am getting the error ,
Error: Invalid index
on .terraform/modules/kafka_msk.kafka_msk/main.tf line 158, in module "hostname":
158: records = [split(":", local.bootstrap_brokers_combined_list[count.index])[0]]
|----------------
| count.index is 2
| local.bootstrap_brokers_combined_list is list of string with 2 elements
The given key does not identify an element in this collection value.
Error: Invalid index
on .terraform/modules/kafka_msk.kafka_msk/main.tf line 158, in module "hostname":
158: records = [split(":", local.bootstrap_brokers_combined_list[count.index])[0]]
|----------------
| count.index is 3
Has anyone encountered this before and have any workaround for it ? Thanks in advance
Terraform module to provision AWS MSK. Contribute to cloudposse/terraform-aws-msk-apache-kafka-cluster development by creating an account on GitHub.
Could the issue you’re experiencing be the same as this one?
https://github.com/cloudposse/terraform-aws-msk-apache-kafka-cluster/pull/24
what Added IAM broker list to the broker combined list why When you try to deploy a cluster with IAM support , the module don't found brokers on the combined list , raising an error like thi…
@Ashwini Thillai can you try that feature branch and see if it solves your issue?
module "kafka" {
source = "git::ssh://[email protected]/krainet/terraform-aws-msk-apache-kafka-cluster.git?ref=krainet:bugfix/broker-dns-iam"
# ...
}
@RB I have tried to run this, the module still throws me the Invalid index error .
Also discovered that the module does not calculate the bootstrap_brokers_combined_list properly . I am running totally 4 brokers on my cluster, but it consolidates that to 3 brokers
@Ashwini Thillai could you create a ticket in the module repo with the exact terraform code youre using ?
Think there is already an open issue, related to what am facing - https://github.com/cloudposse/terraform-aws-msk-apache-kafka-cluster/issues/17
Found a bug? Maybe our Slack Community can help. Describe the Bug Invalid index error when changing number_of_broker_nodes variable from 2 to 4. (The # of AZ's is 2 instead of 3 like the exampl…
@Ashwini Thillai try this
Found a bug? Maybe our Slack Community can help. Describe the Bug Invalid index error when changing number_of_broker_nodes variable from 2 to 4. (The # of AZ's is 2 instead of 3 like the exampl…
@RB Amazing ( pr #29 ) fixed my issue. However, just discovered that the broker endpoints is outputting only 3 brokers even though the cluster runs 4 brokers . I think fixing bootstrap_brokers in the outputs file should resolve the issue
I also read this from the tf page - so am kinda doubtful if it is the module or if this is how AWS works ,
• bootstrap_brokers - Comma separated list of one or more hostname:port pairs of kafka brokers suitable to bootstrap connectivity to the kafka cluster. Contains a value if encryption_info.0.encryption_in_transit.0.client_broker is set to PLAINTEXT or TLS_PLAINTEXT. The resource sorts values alphabetically. AWS may not always return all endpoints so this value is not guaranteed to be stable across applies.
Yes, i included that info in the pr. It’s not a stable output unfortunately
Ah, sorry ! just noticed it . When can we expect the PR to be merged ?
As soon as it gets approved. I’ll merge
@Ashwini Thillai try using 0.6.2 of the module and it should work
module "kafka" {
source = "cloudposse/apache-kafka-cluster/aws"
version = "0.6.2"
# ...
}

I reached out to AWS support to understand why only 3 endpoints are being outputted . Here’s the response from them . Incase it helps someone,
In order to get more insight, I reached out to our MSK service team and they informed me that this is an expected behavior that both UI and getBootstrapBrokers API gives maximum 3 brokers as the output as you will only need a maximum of 3 broker node details to successfully connect or programmatically connect to the MSK cluster at any given moment. The broker node details presented may randomly change as part of the connection string when retrieving the broker node connection string, alternatively you can still connect to any other available broker nodes on your cluster or make use of, as a connection string (Thus, you will only ever need a maximum of 3 broker nodes to ensure high availability when connecting, producing or consuming from the cluster).
Having said that, only 3 brokers will be listing in bootstrap list irrespective of the number of brokers configured in the cluster and this is by design. However, all brokers will be part of the cluster.
Very interesting. Thanks for reaching out to them and sharing
@Ashwini Thillai our slack removes messages over time as this is a free slack so if you want to share this, it might be better to share it on the same github issue so it persists
sure, i can do that I think there is also a workaround for getting the list of all the nodes . I’ll add that to the github page too !
Is it possible to request Pinpoint SMS phone numbers via API? I cannot find any documentation.
Detailed reference information for the Amazon Pinpoint SMS and Voice API, including supported resources, HTTP methods, parameters, and schemas.
Yep. That’s the APIs, but I wasn’t able to find any api specific for requesting new SMS numbers.
2021-08-13
Hi, I am using “terraform-aws-eks” & “terraform-aws-eks-node-group” modules. Can I have examples to add multiple node groups, which have different settings like name, instance type, desired_size, private vs public?
hello Amit, did you ever find a solution for this? I’m trying to achieve something similar.
2021-08-14
2021-08-16
2021-08-17
Hi Champs, can anyone help with k8s deployment script for ingress with tls on fargate eks ..thanks
Will try, what’s the issue you’re having?
Hey @HillOps,
Good questions and wish you luck on the journey. Definitely a lot to unpack.
The best place to start would be https://docs.cloudposse.com/ to get an idea for the tools and processes. It’s not as complete as we’d like it to be, but it does provide an overview of some of the essentials and should point you in the right direction of thought.
The next place would be Slack. We have a v…
Is there an easy/efficient way to force destroy all resources in an AWS account (without destroying the account itself)? In this case, infra is managed by terraform. Often times we run into dependency issues (especially around networking resources) that result in failed terraform destroy attempts.
aws-nuke is your friend for this. I use it regularly and it’s awesome.
One cool aspect of it is that it will loop through the destruction process, to solve the dependency issue you’re mentioning.
oh nice! i’ve never seen this tool before. thank you!
2021-08-18
2021-08-20
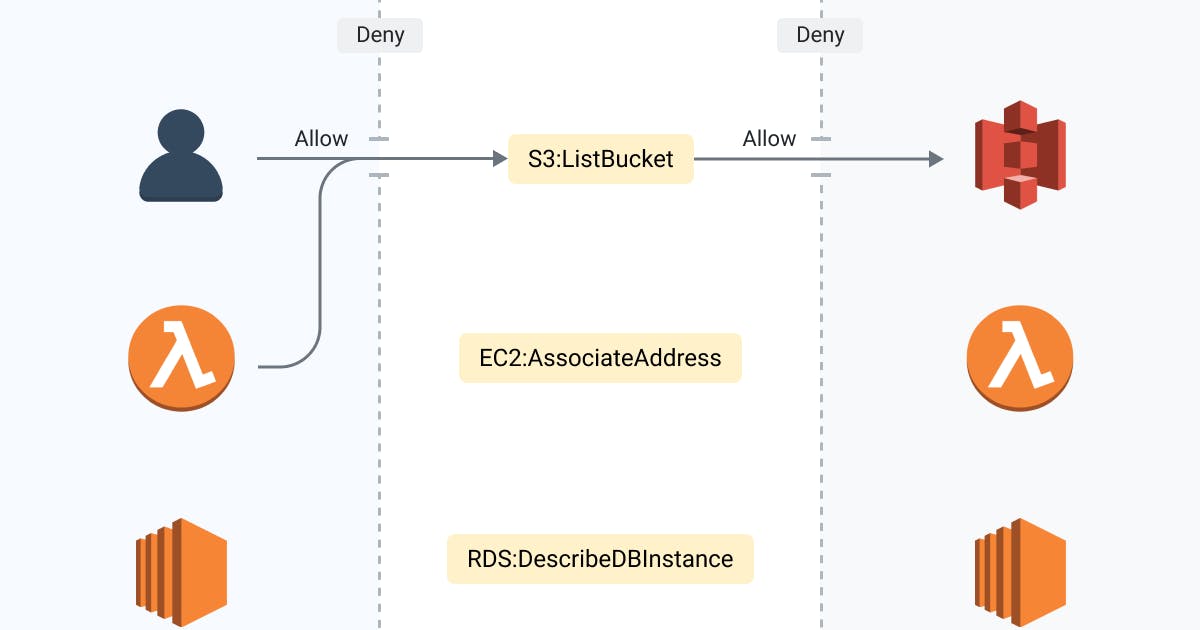
IAM is the AWS security fabric. Every developer must understand how IAM works and what are options for securing AWS Resources.
2021-08-23
I’m running two aurora postgres workloads in US-WEST-2 region:
cluster Regional cluster Aurora PostgreSQL us-west-2 2 instances Available
qa-0 Writer instance Aurora PostgreSQL us-west-2a db.t3.medium Available
qa-1 Reader instance Aurora PostgreSQL us-west-2b db.t3.medium Available
and yet my console reports:
Aurora is not available in this region (US West (Oregon)). Use the region selector to switch to a supported region.
Have you ever seen something like this?
clear the cache
of your browser
will do!
did clearing the cache actually fix that?!
I actually does in many of this weird issues
once I had a problem where I could not see any ec2 instances, tried in another browser a d it worked so I cleaned the cache and everything was fine
I didn’t get back to it! Will check now
if no issues are reported by Amazon then I will have to think the problem is between the chair and the keyboard
 1
1:)
2021-08-24
2021-08-26
EC2 is out of capacity for m6g.xlarge in availability zone us-east-1a
fyi - use1-az2
2021-08-27
Hi colleagues, anyone is aware of any article that explains how launch configuration and auto scaling groups are being used by EKS?
2021-08-29
 Hi All!! Based on ease of administration… what do you recommend for VPN server in hub and spoke model in AWS across multiple AWS children accounts?
Hi All!! Based on ease of administration… what do you recommend for VPN server in hub and spoke model in AWS across multiple AWS children accounts?
- OpenVPN AMI
- OpenVPN via Helm Chart
- AWS VPN Client
We’ve used the AWS VPN Client in one case. We didn’t already have AD so getting that in place was more pain than I’d do again. I like OpenVPN. If I didn’t have a k8s cluster already I’d just go with the AMI.
Tailscale & ZeroTier, very nice!! I’ll check out both
ZeroTier pricing is fantastic
Have you used it before @Alex Jurkiewicz ?
Teleport can also be used for this as an alternate to VPNs: https://github.com/gravitational/teleport
Certificate authority and access plane for SSH, Kubernetes, web applications, and databases - GitHub - gravitational/teleport: Certificate authority and access plane for SSH, Kubernetes, web applic…
We use zerotier currently yes Ryan. We evaluated tailscale, teleport and strongdm earlier this year. All looked great, but the project we wanted them for never got off the ground so we didn’t pull the trigger
thx everyone, appreciate the tips!!
I would go with Client VPN, you can automate everything with Terraform, if you choose certificate authentications - you can even automate the creation of TLS certs, and you can easily integrate it with SAML like Google or Azure AD, and just yesterday there is a blog post about integration with AWS SSO, so if you are looking for simple and easy way this is it.
https://aws.amazon.com/blogs/security/authenticate-aws-client-vpn-users-with-aws-single-sign-on/

AWS Client VPN is a managed client-based VPN service that enables users to use an OpenVPN-based client to securely access their resources in Amazon Web Services (AWS) and in their on-premises network from any location. In this blog post, we show you how you can integrate Client VPN with your existing AWS Single Sign-On via […]
1
You will be up with vpn within 15 minutes
I believe tailscale doesn’t meet compliance requirements for companies that need it. i don’t know which benchmarks in particular, just I know it was ruled out by one of our customers for that reason.
https://tailscale.com/blog/how-tailscale-works/
I’m blown away with STUN and their DERP implementations

It’s very impressive. I’m going to take this for a spin. Worst case can fall back to another solution
Client VPN w/AWS’s SSO is pretty painless, assuming you’re already using AWS SSO
bonus: you get redundancy out of the box (set up endpoints in whatever AZ’s you like), unlike tailscale or similar which is going to be a whole other thing to manage
Cloudflare also has a product in this area, “Cloudflare Teams”, which can ensure things like anti-virus are active on clients
it does require you use Cloudflare for DNS to get the most out of it
@Matt Gowie is also a big fan of Tailscale
Big of tailscale, but I ran into the compliance problem with a customer. Though I know they’re going through a SOC2 audit now or soon, so I’m sure that’ll change things.
StrongDM is a good one — I like them and their support.
I’d recommend against Client VPN only because who wants to deal with VPN config files. They’re archaic and troublesome.
Zscaler is the other one that a few of our customers use
Oh yeah. How are you guys liking Zscaler compared to SDM Erik?
we’re not involved as end users, just helping deploy the agents
Got it.
@Ben Arent
2021-08-30
Hello Team, Can anyone help me how to pass multiple cidrs to security group AWS terraform module - https://github.com/cloudposse/terraform-aws-security-group i am trying to pass it like this, it seems terrafrom is crashing
module "sg" {
source = "cloudposse/security-group/aws"
attributes = ["primary"]
allow_all_egress = true
rules = [
{
key = "ssh"
type = "ingress"
from_port = 22
to_port = 22
protocol = "tcp"
cidr_blocks = concat(
module.global.le_egress_cidr,
module.global.shared_services_cidr,
module.global.ibm_egress_tdq
)
self = null
description = "Allow SSH from company egress"
}
]
vpc_id = module.vpc.vpc_id
context = module.label.context
}
cidr_blocks = concat(
module.global.le_egress_cidr,
module.global.shared_services_cidr,
module.global.ibm_egress_tdq
)
this looks like you are passing strings to concat, which expects 2 or more lists
the cidr_blocks input is itself just a list so you should be able to just do
cidr_blocks = [
module.global.le_egress_cidr,
module.global.shared_services_cidr,
module.global.ibm_egress_tdq
]
Thanks @Zach, i tried this but still seeing an error
Error: Invalid value for module argument
on security_groups.tf line 5, in module "sg":
5: rules = [
6: {
7: type = "ingress"
8: from_port = 80
9: to_port = 80
10: protocol = "tcp"
11: cidr_blocks = [module.global.le_egress_cidr, module.global.shared_services_cidr, module.global.ibm_egress_tdq]
12: self = null
13: description = "Allow HTTP access from egress"
14: },
15: {
16: type = "ingress"
17: from_port = 80
18: to_port = 80
19: protocol = "tcp"
20: cidr_blocks = []
21: self = true
22: description = "Allow HTTP from inside the security group"
23: },
24: {
25: type = "egress"
26: from_port = 0
27: to_port = 65535
28: protocol = "all"
29: cidr_blocks = ["0.0.0.0/0"]
30: self = null
31: description = "Allow egress to anywhere"
32: }
33: ]
The given value is not suitable for child module variable "rules" defined at
.terraform/modules/sg/variables.tf:33,1-17: all list elements must have the
same type.
I think you might be running into issues where you have self = null on 2 of the rules but self = true on the third
 1
12021-08-31
hello. i’ve been implementing https://github.com/cloudposse/terraform-aws-datadog-lambda-forwarder.git in our commercial and govcloud accounts. for the most part, everything on the commercial side is working, but when trying to implement on the govcloud side, i’m getting
│ Error: Error creating Cloudwatch log subscription filter: InvalidParameterException: Could not execute the lambda function. Make sure you have given CloudWatch Logs permission to execute your function.
│
│ with module.monitoring.module.monitoring_common.module.datadog_forwarder.module.datadog_lambda_forwarder.aws_cloudwatch_log_subscription_filter.cloudwatch_log_subscription_filter["vpclogs"],
│ on .terraform/modules/monitoring.monitoring_common.datadog_forwarder.datadog_lambda_forwarder/lambda-log.tf line 150, in resource "aws_cloudwatch_log_subscription_filter" "cloudwatch_log_subscription_filter":
│ 150: resource "aws_cloudwatch_log_subscription_filter" "cloudwatch_log_subscription_filter" {
i see no difference in the policies and wondering if this is something unique to govcloud.
Terraform module to provision all the necessary infrastructure to deploy Datadog Lambda forwarders - GitHub - cloudposse/terraform-aws-datadog-lambda-forwarder: Terraform module to provision all th…
this is due to more hardcoding of the aws partition
submitting a bug report and PR
Yes please. PRs are always welcome
I must have missed the other lambda-* files. good catch
doh. i missed these
@Brandon Metcalf ping me when you open a pr and i’ll review
what Lookup arn partition instead of hardcoding it so module will work in govcloud why govcloud references Fixes #8 Note, I was only able to test the functionality provide by lambda-log.tf an…
 1
1@Brandon Metcalf 0.1.3 released. thanks for the pr
it should also support china region, aws_partition data source cloud be used
@RB I’m thinking we should have a github action with a conftest policy that checks for arn:aws: and errors if any found.
probably would catch 99% of these
sounds like a good idea to me
agreed. seems like that crops up a lot. not many people use govcloud.
I’m working on a China region project and I’m crying everyday from these ARNs
i think the conftest would only prevent new additions of the arn:aws string, no?
we love the pull requests to fix these issues. please submit them when you see it and ill personally try to approve and merge them!
Do a wild sed to replace it if you want