#aws (2021-09)
 Discussion related to Amazon Web Services (AWS)
Discussion related to Amazon Web Services (AWS)
Discussion related to Amazon Web Services (AWS)
Archive: https://archive.sweetops.com/aws/
2021-09-01
2021-09-02
Hi all, anyone has ever used the EC2 serial console connection? i am getting this message while trying to use it to all of our instances
What EC2 instance type?
Error message indicated you are not using a nitro based instance
EC2 instance types comprise of varying combinations of CPU, memory, storage, and networking capacity. This gives you the flexibility to choose an instance that best meets your needs.
Thank you Conor, if i understand well this nitro system is for a little bit more expensive ec2’s, as we use the smallest possible t2, i don’t see it in the table
T3 instances are supported so you could possibly change the instance type. Also https://docs.aws.amazon.com/systems-manager/latest/userguide/session-manager.html is a great alternative option
Manage instances using an auditable and secure one-click browser-based interactive shell or the AWS CLI without having to open inbound ports.
Thank you Conor, the reason that i am asking all these things is that every month as we install some python related packages our server crashes, and none of the 4 methods works EC2 Instance Connect and SSH client should work out of the box (they are unreachable, as server crashed). Session Manager should be configured by me and EC2 Serial Console says that our instance is not compatible (wants nitro)
T3 should be the same price as T2. You can even use t3a which is even cheaper
If the server is crashing that easily its likely undersized
the day of crash it reached 34% cpu usage but i dont see anything else weird about utilization
You can see your CPU credit balance is getting very low (at that point the performance will be throttled) this is not the cause of your issue in this particular case but worth watching
Its likely memory exhaustion
What instance type is it exactly?
t2.micro
Not really suitable for most production workloads unless they are incredibly small / bursty
This is an “insert credit card” fix
Try a t2.medium for a while and see how it goes
what if i change to t3a.micro like alex suggested above? btw how is it possible to have double cpu but be even cheaper? is it because of the switch to AMD?
I doubt it will make any difference if memory consumption is the problem
Lists the on-premises and additional Amazon EC2 metrics made available by the CloudWatch agent.
aha, now i noticed that RAM status is not showing in any graphs, right?
by the way, the serial console didnt help either, only black screen appears
there is a bar going up to the right of the screen
Hello everybody!
AWS DocumentDB related question - https://github.com/cloudposse/terraform-aws-documentdb-cluster
Can anyone please help me configure my terraform module to NOT create a new parameter group, but instead use the default one provided by AWS (or any previously created param group)? There is no mention in the docs on how to do this, only a way to pass parameters for the module to create a new one.
You might need to patch the module. Why is it a problem to use a custom parameter group?
If you use the default one, applying parameter changes in future will require you to first apply a custom parameter group, which will cause downtime
Hello Alex, These are clusters that will almost never need a parameter change. My boss is a kinda OCD about having N amount of parameter groups (and any other unnecesary resource) laying around when all the clusters (more than 30) all use the same params.
that’s too bad you have an irrational boss
It’s helpful to have a custom param group if you ever need a custom param in the future…
Did you want to use an existing param group instead? Or simply not use a param group at all? I think expanding the module to use an existing param group and existing subnet group would be a nice feature
If you want to put in a pr, you can start here
Terraform module to provision a DocumentDB cluster on AWS - terraform-aws-documentdb-cluster/main.tf at 5c900d9a2eaf89457ecf86a7b96960044c5856f4 · cloudposse/terraform-aws-documentdb-cluster
2021-09-03
Hi People, anyone ever had this issue with the AWS ALB Ingress controller:
failed to build LoadBalancer configuration due to failed to resolve 2 qualified subnet with at least 8 free IP Addresses for ALB. Subnets must contains these tags: 'kubernetes.io/cluster/my-cluster-name': ['shared' or 'owned'] and 'kubernetes.io/role/elb': ['' or '1']. See <https://kubernetes-sigs.github.io/aws-alb-ingress-controller/guide/controller/config/#subnet-auto-discovery> for more details.
So there three subnets with the appropriate tagging and many ips I could not yet find the reason why it is complaining about the subnets
Other thread in #kubernetes
Hi People, anyone ever had this issue with the AWS ALB Ingress controller:
failed to build LoadBalancer configuration due to failed to resolve 2 qualified subnet with at least 8 free IP Addresses for ALB. Subnets must contains these tags: 'kubernetes.io/cluster/my-cluster-name': ['shared' or 'owned'] and 'kubernetes.io/role/elb': ['' or '1']. See <https://kubernetes-sigs.github.io/aws-alb-ingress-controller/guide/controller/config/#subnet-auto-discovery> for more details.
So there three subnets with the appropriate tagging and many ips I could not yet find the reason why it is complaining about the subnets
2021-09-07
hi guys, is it any possible way to automate the enablement of ec2 console cable connection in every new ec2 i spin? the commands i am executing for ubuntu instances are the following:
sudo -i
vi /etc/ssh/sshd_config // and go down to edit line
passwordAuthentication yes
// saving with :wq!
systemctl restart sshd
passwd // input password 2 times
you can play with the cloud-init or user data section of your instance
Does the virtual console really use sshd??
I would assume a virtual console is using a tty, and bypassing ssh
@Almondovar yeah, the ec2 serial console is serial access, not ssh. A handful of ec2 AMIs come preconfigured forit (e.g. amazon linux and i think ubuntu 20). You also need to turn the service at the AWS account level and use an IAM role/user permissioned to use the service.
Hi Carlos, do i understand well that the steps i performed are not necessary to enable cloud console connnection? tbh once i followed them they instantly allowed access to the console connection
@Almondovar hey, missed your IM, yes, that is my understanding. But if the changes made worked, then even better
Does anyone know of anything similar to https://github.com/sportradar/aws-azure-login but written in Go?
Have you checked out using Leapp instead?
Leapp grants to the users the generation of temporary credentials only for accessing the Cloud programmatically.
We used to use all kinds of scripts, hacks, and tools but leapp has replaced them for us
It’s an open source electron app distributed as a single binary
Cc @Andrea Cavagna
interesting @Erik Osterman (Cloud Posse) you just use the free one?
Yup
Leapp is free for anyone, it’s an open source projects, we are going to close the federation with AzureAD and AWS pull request this week and having a release, for any further question, @Steve Wade (swade1987) feel free to text me :)
The only paid solution by now is the enterprise support to the opensource project, made by the maintainers of the app
Btw @Erik Osterman (Cloud Posse) I grant you that in the next weeks I will partecipate to an office hour so we can respond to any question about Leapp!
I currently have a script (see below) but it seems a little hacky …
#! /usr/bin/env bash
AWS_PROFILE=${1}
AZURE_TENANT_ID="<redacted>"
AZURE_APP_ID_URI="<redacted>"
AZURE_DEFAULT_ROLE_ARN="arn:aws:iam::<redacted>:role/platform-engineer-via-sso"
AZURE_DEFAULT_DURATION_HOURS=1
# Make sure user has necessary tooling installed.
if ! which ag > /dev/null 2>&1; then
echo 'Please install the_silver_searcher.'
exit
fi
# Run the configuration step if not set.
# shellcheck disable=SC2046
if [ $(ag azure ~/.aws/config | wc -l) -gt 0 ]; then
printf "Already configured, continuing ...\n\n"
else
printf "Use the following values when asked for input ... \n"
printf "Azure Tenant ID: %s\n" ${AZURE_TENANT_ID}
printf "Azure App ID URI: %s\n" ${AZURE_APP_ID_URI}
printf "Default Role ARN: %s\n" ${AZURE_DEFAULT_ROLE_ARN}
printf "Default Session Duration Hours: %s\n\n" ${AZURE_DEFAULT_DURATION_HOURS}
docker run -it -it -v ~/.aws:/root/.aws sportradar/aws-azure-login --configure --profile "$AWS_PROFILE"
fi
# Perform the login.
docker run -it -it -v ~/.aws:/root/.aws sportradar/aws-azure-login --profile "$AWS_PROFILE"
printf "\nMake sure you now export your AWS_PROFILE as %s\n" "${AWS_PROFILE}"
2021-09-08
Does anyone know if it’s possible to reserve/allocate a small pool of consecutive Public IP/ELastic IP Addresses on AWS ? I’ve been searching documentation with no luck
Has anybody used AWS Config Advanced Queries? basically, pulling aws describe data using SQL) i’m trying to pull config data using the aws cli, then throw it into a CSV or some other datastore for querying.
aws configservice select-aggregate-resource-config \
--configuration-aggregator-name AllAccountsAggregator \
--expression "
SELECT
resourceId,
resourceName,
resourceType,
tags,
relationships,
configuration.storageEncrypted,
availabilityZone
WHERE
resourceType = 'AWS::RDS::DBInstance'
AND configuration.engine = 'oracle-ee'
AND resourceName = 'rds-uat-vertex-9'
" \
| jq -r '.'
.. i’m having problems parsing the outputs. this is mainly a JQ problem.
We should chat tomorrow, I have some code in ConsoleMe that parses the nested json config returns
When using shield, is it best to put protections on a Route53 zone, or an ALB that that zone connects to, or both?
And then the same question with Route53 pointing to CloudFront, API Gateway, etc.
2021-09-09
before I start writing my own … does anyone know of a lambda that takes an RDS snapshot and ships it to S3?
wild, I’m doing that right now.
mysql? postgres? sqlserver? oracle?
rds snapshot or a db-native (like pg_dump or mysqldump)?
@Matthew Bonig mysql and rds snapshot
gotcha. So what I ended up doing was writing a lambda that did the dump (using pg_dump) and then streamed that to a bucket. I then have another process that reads that object from the bucket and restores it in another database. Nothing is packaged up nicely for distribution yet, but so far it seems to be working ok.
The plan is to have that Lambda be part of a state machine that will backup and restore any database requested from one env to another.
nice thats pretty cool
the dump into S3 makes sense as a lambda
what you write it in?
only concern is that you can’t get the entire database in 15 minutes =-/
nodejs
you can’t get it?
yes, I can in my case. I was just saying my only concern about using a lambda is that the database is so big that it couldn’t be dumped and uploaded to s3 within 15 minutes.
generally the runs I’ve been doing in a fairly small database were getting done in just a few minutes (with an 800mb dump file) so we’ll probably be fine. But if you’re trying to do this for some 3 tb database, you’re going to have a bad time with Lambdas
Did you notice much size difference between a MySQL dump to S3 and just taking a snapshot @Matthew Bonig ? My boss seems to think a dump is over engineering it for some reason
I’ll paste you his points here when I’m at my laptop in about 15 mins if you’re still around
We wont be retaining the shapshots. The RDS snapshot we should use is the automated ones, which we have to keep for contractual and compliance reasons anyway, so there is no additional cost.
Moving this into a sqldump would be over engineering in my view, RDS has the ability to export a snapshot directly to S3 so why reinvent the wheel? Lets face it AWS are pretty good at this stuff, so we should leverage their backup tooling where possible.
The snapshots moved into S3 will need to be retained indefinitely due to the contractual wording…this is being worked on, but wont change any time soon.
I also dont want to have a split between HelmReleases and TF. If we can manage this all in one place (which we can) it feels better than splitting it out. As a consumer having to deploy the infra, then also deploy a HelmRelease feels clunky. Where as deploying just the RDS instance and its backup strategy as a single unit would be more intuitive.
I proposed using a CronJob in our EKS clusters to facilitate the backup
In my base, postgres, so pg_dump. But, that was pretty large since totally uncompressed SQL.
I had looked into using snapshot sharing, but since the db was encrypted with a KMS I couldn’t share with the other account, I couldn’t ship it that way.
Should have looked more for the native s3 integration, but didn’t. Will look now. I don’t know how the encryption would work though. I would assume shipping it to s3 keeps the data encrypted (and needing the same key as the RDS instance)
I use cronjobs in a cluster to backup a mysql and mongodb. Works great.
oh man, totally should have done this s3 export.
I wrote one for Elasticache, to ship elasticache snapshot to another account and restore it. I’ll put together a gist for you. It’s not RDS, but there may be similar semantics.
Actually, scratch that. I haven’t completed open sourcing it, apologies about the false start.
RDS Q: I made a storage modification, but accidentally set to apply-in-maintenance window. How can I turn around and force it to apply-immediately? I’m in storage-full status.
Make another change and tell it to apply immediately
thanks @Alex Jurkiewicz , aws support pretty much told me the same thing. they said to do it via CLI, not console.
aws rds modify-db-instance \
--db-instance-identifier my-db-instance-01 \
--allocated-storage 200 \
--max-allocated-storage 500 \
--apply-immediately;
hwy, not sure to post here or terraform… anyone been ale to create a rds read replica in a different vpc via terraform…i have been stuck on this for a fewdays… getting the error:
Error creating DB Instance: InvalidParameterCombination: The DB instance and EC2 security group are in different VPCs.
i am able to apply the desired config through the console but no through Terraform sadly
maybe this will help https://stackoverflow.com/questions/53386811/terraform-the-db-instance-and-ec2-security-group-are-in-different-vpcs
i am trying to create a vpc with public and private subnet along with Aurora mysql cluster and instance in same vpc with custom security group for RDS. i’ve created vpc (public/private subnet, cus…
looks like one of them is using the default VPC
2021-09-10
Hi People, Wanted to ask about experiences upgrading kubernetes eks versions. I recently did an upgrade from 1.19 to 1.20. After the upgrade some of my workloads are experiencing weird high cpu spikes. But correlation does not equal causation so I wanted to ask if anyone here experienced something similar.
The only change I can think of, that can cause this is docker deprecation: https://kubernetes.io/blog/2020/12/02/dockershim-faq/
But that’s not included to the 1.20 by default, you should do it separately in a node group. So if you followed the release notes and did it - must be it.
This document goes over some frequently asked questions regarding the Dockershim deprecation announced as a part of the Kubernetes v1.20 release. For more detail on the deprecation of Docker as a container runtime for Kubernetes kubelets, and what that means, check out the blog post Don’t Panic: Kubernetes and Docker. Why is dockershim being deprecated? Maintaining dockershim has become a heavy burden on the Kubernetes maintainers. The CRI standard was created to reduce this burden and allow smooth interoperability of different container runtimes.
Other than that the k8s version itself (the control plane) has no effect on workload resource consumption, it’s involved only during CRUD of the yamls.
It must be something else - the AMI version of a worker, the runtime, instance type of a worker, and so on
2021-09-11
2021-09-13
Hi all right with you? Do you know if there is any web application to make it easier to navigate AWS S3?
easier in regards to what, you mean like for a public bucket?
Yes! I need to release AWS S3 to people in the marketing department
These are people who have no technical knowledge and they need to have the option to download a full AWS s3 folder
theres this which lets you browse a bucket https://github.com/awslabs/aws-js-s3-explorer
AWS JavaScript S3 Explorer is a JavaScript application that uses AWS's JavaScript SDK and S3 APIs to make the contents of an S3 bucket easy to browse via a web browser. - GitHub - awslabs/aws-…
I recently tested AWS s3 explorer, but it doesn’t have the option to download a full folder.
this guy seems to have a fork where you can select multiple files https://github.com/awslabs/aws-js-s3-explorer/pull/86
Issue #, if available: Description of changes: Add download button to header (only shows when items are selected) Enable download of multiple files at once in a ZIP folder - select items and click…
2021-09-14
Try to describe instances /usr/local/bin/aws ec2 describe-instances –instance-ids i-sssf –region –output text –debug and got that
nmkDIykR/VMOgP+bBmVRcm/QWkCbquedU53R9SAv9deDrjkWkLKuPEnHgu57eGq55K1nFTAVhJ2IG5u5C2IuNKCskgAqz6+JH5fMdlAhYtAzw6FTv+YTi9DFhJaBA9niDk+n2lNhtx/iIbDRNGGCrMXuQbU5hPeHy8ijY6g==', 'Authorization': b'AWS4-HMAC-SHA256 Credential=ASIAUXKPUFZ7UOBXM3GN/20210914/eu-west-1/ec2/aws4_request, SignedHeaders=content-type;host;x-amz-date;x-amz-security-token, Signature=a8d69a78cbf6ac49ba9cc7774d5e9625ec8a2843e7eedeaba2630da7a4a41e1f', 'Content-Length': '76'}>
2021-09-14 14:34:51,592 - MainThread - urllib3.connectionpool - DEBUG - Starting new HTTPS connection (1): ec2.eu-west-1.amazonaws.com:443
it’s private EC2 instance, why can’t get the output?
netstat -tnlp | grep :443
tcp 0 0 0.0.0.0:443 0.0.0.0:* LISTEN 1013/nginx: maste
output? what do you mean?
I mean when I run aws ec2 describe instance command, I would like to get result
do you have a firewall or something that could be blocking connections?
I think the problem is that it’s private ec2 instance right? Doesn’t have public IP address. Instance metadata received
<http://169.254.169.254/latest/meta-data/>
By using curl command got result
the instance should have internet and it should be able to hit the api
it has nothing to do with the public ip
but usually to get metadata from within an instance you use this address http://169.254.169.254/latest/meta-data/
no need to run the cli for that
2021-09-15
does anyone have a clean way of authenticating (via kubectl) to EKS when using Azure AD as the OIDC identity provider? not sure if people have hooked up Dex with Gangway to provide a UI for obtaining them?
We have an open enhancement in Leapp. maybe it can help you: https://github.com/Noovolari/leapp/issues/170
Is your feature request related to a problem? Please describe. I am a user of kubernetes and of kubectl and eks. At present, kubectl references the aws binary for authentication, which expects cert…
Odd, I’m using kubectl and leapp just fine right now oh, this is to have kubectl ask leapp directly. Huh.
Hi @Steve Wade (swade1987)! May I ask you how you have federated Azure AD to AWS?
@Eric Villa I have a blogpost on it https://medium.com/p/how-to-configure-azure-ad-as-an-oidc-identity-provider-for-eks-53337203e5cd?source=social.tw&_referrer=twitter&_branch_match_id=967466935918883996

Ok thank you! I’ll check it out
does anyone know if there is a recommended approach to alert on failed RDS snapshot to s3 exports?
CloudWatch Events?
Lambda functions to send sns notification to communication channel like teams or slack?
2021-09-16
I’m trying to try out Kinesis using CloudFormation. I’m getting failed invocations when my scheduler invokes the Lamba. But nothing is showing up in Cloudwatch logs. Any ideas how to handle/fix this?
AWSTemplateFormatVersion: "2010-09-09"
Description: "Template for AWS Kinesis resources"
Resources:
DataStream:
Type: AWS::Kinesis::Stream
Properties:
ShardCount: 1
RetentionPeriodHours: 24
Name: !Sub ${AWS::StackName}
Lambda:
Type: AWS::Lambda::Function
Properties:
Role: !Sub arn:aws:iam::${AWS::AccountId}:role/service-role/lambda_basic_execution
Runtime: python3.6
FunctionName: !Sub ${AWS::StackName}-lambda
Handler: index.lambda_handler
Code:
ZipFile: |
import requests
import boto3
import uuid
import time
import json
import random
def lambda_handler(event, context):
client = boto3.client('kinesis', region_name='${AWS::Region}')
partition_key = str(uuid.uuid4())
response = requests.get('<https://randomuser.me/api/?exc=login>')
if response.status_code == 200:
data = json.dumps(response.json())
client.put_record(
StreamName='{AWS::StackName}',
Data=data,
PartitionKey=partition_key
)
print ("Data sent to Kinesis")
else:
print('Error: {}'.format(response.status_code))
Schedule:
Type: AWS::Events::Rule
Properties:
ScheduleExpression: "rate(1 minute)"
State: ENABLED
Targets:
- Arn: !GetAtt Lambda.Arn
Id: "TargetFunctionV1"
Input: '{}'
LogGroup:
Type: AWS::Logs::LogGroup
Properties:
LogGroupName: !Sub /aws/lambda/${AWS::StackName}-lambda
RetentionInDays: 7
LogStream:
Type: AWS::Logs::LogStream
Properties:
LogGroupName: !Ref LogGroup
LogStreamName: !Sub /aws/lambda/${AWS::StackName}-lambda
PermissionsForEventsToInvokeLambda:
Type: AWS::Lambda::Permission
Properties:
FunctionName: !GetAtt Lambda.Arn
Action: lambda:InvokeFunction
Principal: events.amazonaws.com
SourceArn: !GetAtt DataStream.Arn
You checking the whole log group?
You are creating a lot stream but Lambda won’t use that
2021-09-17
Hi,
Is it possible to add custom endpoint to AWS Kinesis Signalling Stream endpoint(kinesis.us-east-1.amazonaws.com),
Tried installing a nginx in an ec2 instance and tried to reverse proxy pointing (customendpoint -> kinesis.us-east-1.amazonaws.com) and used certbot to issue certificate to my custom endpoint but the app is giving https://<custom-domain>/describeSignalingChannel 404 (Not Found)
Thanks
2021-09-19
Hi All, anyone know why my targets are stuck?
Target registration is in progress
it’s been trying to register for over and hour now.
any fix/solution will be appreciated.
Are the health checks passing?
Have you spot checked the health checks as being valid/working?
currently what it looks like
it was failing earlier.
now it is stuck on registering
I would suggest reaching out to their support if you haven’t already. Likely they will be able to spot the problem easily. Could very well be on their end too.
does your exec role have permissions to pull the image?
@Darren Cunningham sorry what exec role?
The task execution role grants the Amazon ECS container and Fargate agents permission to make AWS API calls on your behalf. The task execution IAM role is required depending on the requirements of your task. You can have multiple task execution roles for different purposes and services associated with your account.
additionally, if you’re pulling from a private ECR – double check the policy on the ECR
2021-09-20
Hi has anyone ran tfstate backend module with 1.0.7 version of terraform?
│ Error: Unsupported argument
│
│ on main.tf line 8, in module "tfstate_backend":
│ 8: force_destroy = true
│
│ An argument named "force_destroy" is not expected here.
╵
╷
│ Error: Unsupported argument
│
│ on main.tf line 10, in module "tfstate_backend":
│ 10: bucket_enabled = var.bucket_enabled
│
│ An argument named "bucket_enabled" is not expected here.
╵
╷
│ Error: Unsupported argument
│
│ on main.tf line 11, in module "tfstate_backend":
│ 11: dynamodb_enabled = var.dynamodb_enabled
│
│ An argument named "dynamodb_enabled" is not expected here.
╵
╷
│ Error: Unsupported argument
│
│ on main.tf line 13, in module "tfstate_backend":
│ 13: context = module.this.context
│
│ An argument named "context" is not expected here.
hrmmm not following. master should be compatible too
Sorry it was not about master/main
You are correct
was using master
that is why
2021-09-21
JQ question: I want to get just the environment tag out of a set of RDS instance’s tags (pulled from AWS Config advanced queries). Does anybody know how to pull out just the value of the “env” tag for each instance?
aws configservice select-aggregate-resource-config \
--expression "
SELECT tags
WHERE resourceType = 'AWS::RDS::DBInstance'
" | jq -r '.Results[]' | jq -r .tags
[
{
"value": "MON/01:00",
"key": "auto-schedule-start"
},
{
"value": "prod", <==== I ONLY WANT THIS
"key": "env"
}
]
[
{
"value": "dev",
"key": "env"
},
{
"value": "daily", <==== I ONLY WANT THIS
"key": "backup"
}
]
my jq attempt:
| jq 'select(.key="env").value'
.. but it’s returning all values, not just for the “env” tags. Any JQ folks here can assist? =]
I used to use jq with awscli a lot but then i switched to their native jmespath using the --query method.
See if something like this works for you
https://github.com/aws/aws-cli/issues/621#issuecomment-36314975
Trying to output only specific tag values from describe-instances using the –query for example aws idis-eu-west-1 ec2 describe-instances –query "Reservations[].Instances[].{ID:InstanceId, TA…
i saw that syntax and thought about it, but the awsconfig advanced query uses simplified SQL syntax and HAS to dump an entire tags object. I have to then filter using jq. thank you for the link tho! super useful in other ways.
Anyone here have any experience with setting up privatelink for fargate instances to pull images from ecr?
Yes what’s the issue your running into
Ecr has two endpoints you need to add, api and dkr once you create the endpoints you just need to add a security group for 443 and make sure fargate can access it
hmm ive done exactly that but it seems the iamges are still being pulled through my public NAT
You’ll probably also need to add s3 that can be a gateway endpoint
so ive got 2 interfaces and a gateway
Did you add the private subnets on the ecr interface endpoints
yeah, all my private subnets are on both of the ecr interface endpoints
same SG’s too
Did you enable private hosted zone on the interface endpoint
used the same policy as recommended by the docs, and my private DNS looks to be correct too (*.dkr.ecr.ap-southeast-2.amazonaws.com)
Is this a dev env
yeah
Like can you temporarily remove the route to the nat and see if the ecr image still pulls for container
I’ll give that a go now
Yea I’m curious, it should be working from what you’ve setup
One of these blog posts may or may not help
https://aws.amazon.com/blogs/compute/setting-up-aws-privatelink-for-amazon-ecs-and-amazon-ecr/
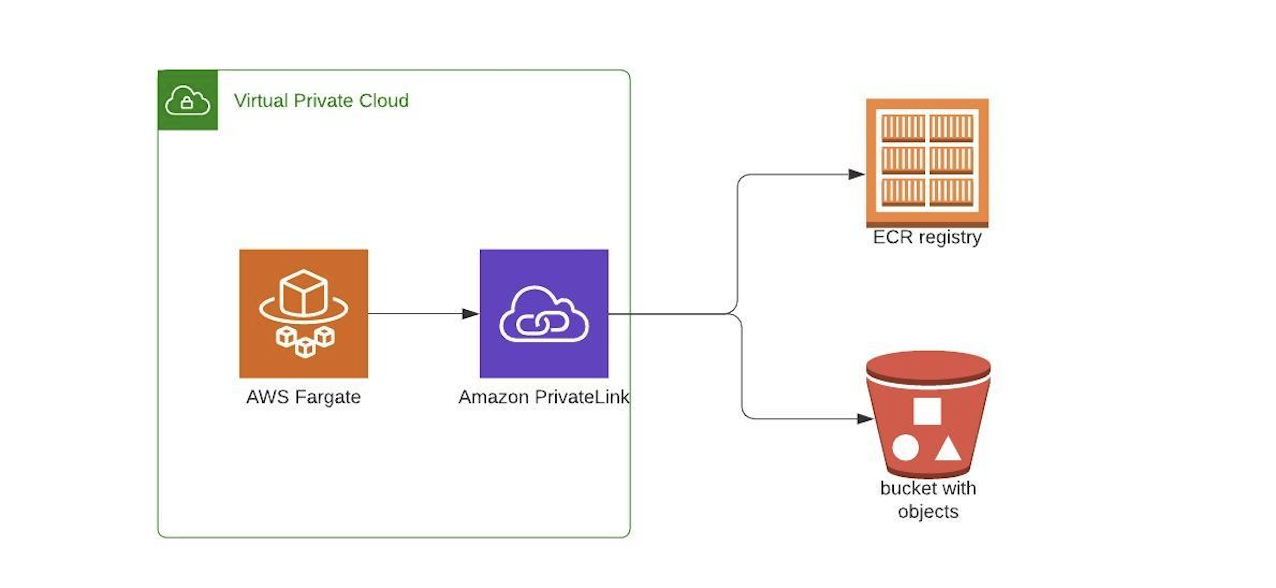
How to reduce NAT gateway charges on by creating Private link between ECR and ECS containers.

Amazon ECS and Amazon ECR now have support for AWS PrivateLink. AWS PrivateLink is a networking technology designed to enable access to AWS services in a highly available and scalable manner. It keeps all the network traffic within the AWS network. When you create AWS PrivateLink endpoints for ECR and ECS, these service endpoints appear […]
What platform version are you using for fargate
3 or 4
1.4
ive checked out both of those blog links haha, there must be a misconfiguration somewhere else that im not seeing
Yea I’m trying to think of any gotchas, I’m not at my computer right now so can’t visually run through my setups
sitting here waiting for terraform cloud to see the commit, not realising i didnt push yet
alroghty, did some stuff
turned off route for private subnets, added the cloudwatch private endpoint,and got it to seemingly pull from the private endpoint
Nice
2021-09-22
Hi folks, is it possible on EKS to set by default desired capacity in node groups to zero and increase it “automatically” as soon a new service is deployed?
Currently I have a service(DWH) which runs daily for around 2 hours in a m5d.8xlarge instance and then becomes idle. I would like to avoid having that instance running for many hours without using it (currently trying to reduce costs).
Cluster AutoScaler can do that!
EKS-specific docs are at https://docs.aws.amazon.com/eks/latest/userguide/cluster-autoscaler.html and https://www.eksworkshop.com/beginner/080_scaling/
Autoscaling components for Kubernetes. Contribute to kubernetes/autoscaler development by creating an account on GitHub.
The Kubernetes Cluster Autoscaler automatically adjusts the number of nodes in your cluster when pods fail or are rescheduled onto other nodes. The Cluster Autoscaler is typically installed as a Deployment in your cluster. It uses leader election

Thanks @Vlad Ionescu (he/him)!
hi guys i want to enable iam authentication in mariaDB but i have the feeling that its not supported. am i right? or is it because the db is not publicly accesible? as you can see in the screenshot the right one, is mysql and iam auth is enabled, but left one is mariaDB and i dont even see the option to enable it…
Reading https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/UsingWithRDS.IAMDBAuth.html, it only lists MySQL an postgres support, not Mariadb. Im sure aws support can confirm it, but that’s likely why. Don’t think the public IP has to do w it
Thank you for confirming Michael
Cloudwatch Alarm SNS Question: I want to send Cloudwatch alarms to multiple destinations (2 MS teams channels & pager duty). All use a webhook.
Based on tutorials , it seems I make an SNS topic, make a lambda to translate/send a message to the webhook.
My question: do I need 3 separate lambdas to handle each destination? Or is there some other best practice / tool I should be doing ?
You don’t need separate Lambdas, but I would typically encourage it. Being that the intent of Lambda is Function as a Service, it’s ideal when a Lambda does not have too much baked into it. The more you pack into a single Lambda (1) it’s inherently going to run slower, which then has cost implications as you scale (2) increases code complexity, which makes testing all scenarios harder (3) depending on the runtime, can make bundling the Lambda a PITA.
If I was going to implement something like this, I would create two Lambdas: 1 for PagerDuty & 1 for MS Teams and then determine the best way to filter SNS Messages accordingly.
However, your use case sounds like one that others should have solved so I’m betting there is a tool or OSS project out there. Typically the teams that I’ve worked on have solved similar use cases with Datadog or New Relic. Those platforms are great, however they come with a significant investment…both time and money. Each of the platforms will have “Get started in 10 minutes” but that’s about as honest as 6 minute abs.
Thanks. I AM now bundling 2 teams lambda’s (multiple webhook Environment variables, and the core function doing the notification for each). thanks, so my function names basically should be
• cloudwatch-alarms-to-sns-to-teams
• cloudwatch-alarms-to-sns-to-pagerduty
We also have prometheus, but it’s a bit of black box to me as a practitioner (ie. how to use requires involvement from my platform/monitoring team) , I need a point solution and honestly want to know the “AWS way” of doing things.
Pagerduty does not require json payload handling, I have usually recommended customer (who have PagerDuty) to funnel all alerts from PagerDuty, you can make rules and push the data to MS Teams or Slack.
MS Teams and Slack use web hooks so the data needs to be structured which is what the lambda does.
Whereas, Pagerduty has CloudWatch integrations, so it can injest the json output from CloudWatch as is.
ah – so what you’re saying is
- Cloudwatch alarms to SNS topics
- SNS topics to PAGERDUTY (easier integration)
- PAGERDUTY to Teams (integration guide)
Yup, spot on. So there’s no needs for lambdas to manage and you can create event rules in PagerDuty.
2021-09-23
2021-09-24
Hi anyone have an idea how long it’ll take to restore Automatic Backups for Postgres RDS? I have 4 running for a while. I’ve also restored Snapshots which are already running.
how big is it?
inserts are not in parallel in Postgres AFAIK
and there is no S3 import in RDS for postgres
to give you an idea 500 gb will take like 10 hours or more
but depends on size , IO etc
@Fabian: trying to dissect your statement. yyou’ve already restored (manual) snapshots successfully, but here you’re trying to restore automatic snapshots (ie. those that are taken by AWS nightly)? there typically should be no difference. what i’ve seen is that you’re supposed toopen up a ticket to aws support and they can probably see what’s going on in the backgrund using their API calls
depends on the size of the backup (maybe storage class - probably not though as I don’t think you can change this with automatics) and the size of the instance you’ve requested
Any rough idea?
I’ve been restoring for 1h now
What is the recommended approach for alerting to slack on a failed lambda invocation? I have written a rds snapshot to S3 lambda that fires from an event rule but want to know when it fails.
I feel like the lambda would need to do the error handling… Or maybe, create a metric from a log filter… https://docs.aws.amazon.com/AmazonCloudWatch/latest/logs/MonitoringLogData.html
Create metric filters with CloudWatch Logs and use them to create metrics and monitor log events using CloudWatch.
DLQ -> SNS -> SQS & Lambda. Lambda handles the notification and SQS becomes the “repo” of messages that need to be manually remediated. As you identify automatic remediation opportunities you could add a Lambda process the messages from the SQS queue. You should also then go and add a filter to the notifications Lambda since you don’t need to get alerted for events you can automatically remediate.
2021-09-25
2021-09-26
2021-09-27
Hey, How can I specify EBS storage for brokers in AWS MSK module https://github.com/cloudposse/terraform-aws-msk-apache-kafka-cluster
Terraform module to provision AWS MSK. Contribute to cloudposse/terraform-aws-msk-apache-kafka-cluster development by creating an account on GitHub.
got it https://github.com/cloudposse/terraform-aws-msk-apache-kafka-cluster/blob/master/variables.tf#L16
Terraform module to provision AWS MSK. Contribute to cloudposse/terraform-aws-msk-apache-kafka-cluster development by creating an account on GitHub.
Hi all, thanks for the amazing work. Does anyone have experience with vpn access to multiple regions using AWS transit gateway? cannot find an example of how to set this up. I am trying to wire up ec2_client_vpn with transit gateway in terraform.
- Create a VPC Call it “VPN Client VPC” - Can be a small VPC /28 - Do not deploy any workloads in this VPC.
- Deploy AWS Client VPN into o this VPC (1)
- Attach the VPN Client VPC to the TGW as a VPC Spoke - Set appliance mode enabled for symetric routing (Attach the Subnets (Multi AZ) where the client vpn is deployed) , Add 0.0.0.0/0 to the TGW-id in the VPC RTs
- Attach VPC B from another Region to the TGW - Modify its VPC RT to 0.0.0.0/0 TGW-id
- If youre only using Default TGW Route Domain with auto prop and auto association then any client originating from the Client VPN should be able to ping resources in another region Spoke attachment
Typing this top off my head
Thanks @msharma24 !
Sorry dont have a working example
@Eric Steen I have recently built a AWS network Firewall with Transit gateway - you could easily fork and replace the Firewall VPC with the VPN Client VPC and it should work https://github.com/msharma24/terraform-aws-network-firewall-deployment-models/tree/main/centralized
Deployment models for AWS Network Firewall with Terraform - terraform-aws-network-firewall-deployment-models/centralized at main · msharma24/terraform-aws-network-firewall-deployment-models
Thanks @msharma24
Hello what do you use to terminate/drain/remove nodes that is on Unready state on aws eks?
like the node termination handler?
Yes
Gracefully handle EC2 instance shutdown within Kubernetes - GitHub - aws/aws-node-termination-handler: Gracefully handle EC2 instance shutdown within Kubernetes
we deploy this fwiw
Yes i was looking for this ;)
Cause getting unready nodes on aws nowadays
2021-09-28
2021-09-29
My codebuild jobs suddenly stopped working. I’m using docker inside codebuilds and it was working well but suddenly now seeing ERROR: Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running? is anyone experiencing a similar issue ?
My buildspec.yml looks like so, its failing in the install phase:
version: 0.2
phases:
pre_build:
commands:
- echo prebuild commands
install:
commands:
- nohup /usr/bin/dockerd --host=unix:///var/run/docker.sock --host=<tcp://127.0.0.1:2375> --storage-driver=overlay2 &
- timeout 60 sh -c "until docker info; do echo .; sleep 1; done"
build:
commands:
- ls
- pwd
- docker login -u $DOCKERHUB_USER -p $DOCKERHUB_TOKEN
- git clone {repository_url} code
- cd code
- git checkout {branch}
- dg project generate --name {project_name}
I’m using custom image and I confirmed its running “previlliged” mode
huh, never seen that nohup call before. why you do that?
It’s based on https://docs.aws.amazon.com/codebuild/latest/userguide/sample-docker-custom-image.html
Provides information about the Docker in custom image sample that is designed to work with AWS CodeBuild.
UPD: So it turns out that I had to add VOLUME /var/lib/docker to the dockerfile because I am using a custom image and codebuild has moved from Alinux v1 to Alinux v2
Question on Event Subscriptions: I’m looking at RDS Event subscriptsion to try to connect to pagerduty. Are there event subscriptions for services OTHER than RDS? I see documentDB, DMS, but I don’t see things like EC2, ALB.. do they exist?
Potentially because they’re managed services, with the user having no/not much control over these services.
I think you can tap into aws.health as a provider in CloudTrail to get notifications for other services.
it depends on the service. Check the EventBridge AWS schema registry and you can figure out what sort of events are published
thanks. it was more that Iwas expecting to find a ton of other tutorials for “ec2 event subscription” “fargate event subscription” “eks event subscription” , only to find that it’s really just RDS, DMS, an DynamoDB