#aws (2022-02)
 Discussion related to Amazon Web Services (AWS)
Discussion related to Amazon Web Services (AWS)
Discussion related to Amazon Web Services (AWS)
Archive: https://archive.sweetops.com/aws/
2022-02-01
@Maxim Mironenko (Cloud Posse) has joined the channel
Anyone have advice on setting up a windows EC2 where the server name is changed and then the real bootstrap script is run. Windows needs a restart after changing the server name which is a pain.
Good advice? No… Switch to Linux…
2022-02-02
i checked online on how i can updated an os on my own when it is marked as required on the maintenance tab tried doing this but it fails to start the update. I dont know if anyone can help if they have done a New Operating System update for RDS manually before the maintenance_window ?
@emem you can upgrade it outside of the maintenance window by modifying the rds cluster/instance, set it to the desired version, and click apply immediately
Thanks
this OS upgrade
hi folks, anyone knows how i can continue troubleshooting an error i get with sts decode
An error occurred (InvalidAuthorizationMessageException) when calling the DecodeAuthorizationMessage operation: Message is not valid
given by aws sts decode-authorization-message --encoded-message ?
I’m only trying to copy an AMI from one region to another (it works except when copy to Bahrain). Open a ticket with AWS support but no progress, “it works for me” And sadly i don’t see it in Cloudtrail either hence … stuck … note i’m Admin so i shouldn’t have any issues, no SCP either
hi there. please has anyone seen this error after adding datadog as a sidecar to eks fargate
Your pod's cpu/memory requirements exceed the max Fargate configuration
fargate has a limit of 16gb of ram
so i using fargate in eks
not sure if EKS fargate have the same
do i need to increase this memory
This section describes some of the unique pod configuration details for running Kubernetes pods on AWS Fargate.
Since Amazon EKS Fargate runs only one pod per node, the scenario of evicting pods in case of fewer resources doesn’t occur. All Amazon EKS Fargate pods run with guaranteed priority, so the requested CPU and memory must be equal to the limit for all of the containers. For more information, see Configure Quality of Service for Pods in the Kubernetes documentation.
oh ok thanks alot.
so in my case i have two containers in the pod one for my app and one for datadog and they node cannot manage them both. Not sure if there is a way to request more cpu on fargate
what if you set both containers to a lower setting to the maximum Node setting?
you always need to account for OS mem usage, EKS api controller running, other networking virtualization memory usa etc and what is left is what you can use
there is always and overhead on any type of virtualization
so you can’t just overcommit
true.
what i did as a stop gap was to remove the config for cpu and memory from the both containers configuration so it can provision the amount it needs for itself, until i can fix the issue
2022-02-04
Hi there, do you know what’s OCB Cloudfront in Cost Explorer? The usage type is UE-OCB and the Service is OCBCloudfront.
That’s an odd one. I am not sure what OCB stands for and googling for it didn’t haven’t lucky either. Others have asked about it too, but no answer. I would ask your AWS account manager.
Is that the name of your distribution ?
I found a document (written mostly in Chinese) that seems to indicate that this is Out of Cycle Billing. I noticed here that they refer to “out-of-cycle” charges which are any subscription charges that aren’t upfront reservation charges or support charges.
With Cost Explorer, you can filter how you view your AWS costs by one or more of the following values:
Thanks, I’m still waiting for a reply from the AWS Account Manager. Inside the bill it’s described as “Missed CloudFront Term Commit Charge - April 2020 - March 2021”. I’ll let you know when I have more info
Anybody using Leapp and in-browser? I started SSO using Brave, switched my default browser to Firefox and Leapp keeps sending me thru Brave to re-authenticate
i use leapp and in browser i login to my identity account using saml login via gsuite idp
then i switch roles using aws extend iam roles switcher firefox addon
2022-02-05
I’m on AWS and using a bunch of cloudposse modules. I have gotten CodePipeline working with ecs-web-app and Fargate, but it only has 3 stages. I want a fourth stage where I can use the new code before approving and sending it live.
I see several threads here from the past pointing users toward Codefresh instead of CodePipeline for anything beyond the standard 3-stage pipeline, but nothing for the past few years. It being 2022 now, I wanted to check and see if that’s still the recommended approach. It looks like this is an example app using this setup.
Example application for CI/CD demonstrations of Codefresh - GitHub - cloudposse/example-app: Example application for CI/CD demonstrations of Codefresh
FTR, I did end up switching to Codefresh. It’s got several nice features, including the “wait for approval” step I wanted. If anyone else wants to use it, I recommend starting here:
NB: the “ecs-deploy” step from the marketplace doesn’t let you provide an image tag! So use the step provided in the link above instead.
You can begin by coding your pipeline yaml in their inline editor, and then switch to a file checked into your Git repo.
How to Pause Pipelines for Manual Approval
How to use Codefresh to deploy Docker containers to ECS/Fargate
How to define Pipelines in Codefresh
One thing to be aware of: Codefresh does some behind-the-scenes ECR integration for you. If you change your access key credentials, this can be a problem. Read up on it in their docs.
Learn how to use the Amazon Docker Registry in Codefresh
I am now using Codefresh along with ecs-web-app for deployment. codepipeline_enabled is set to false. Codefresh works well, and my task definition gets updated and service re-deployed when I push to GitHub.
However, now when I make a change to Terraform and then plan and apply, the task definition gets changed. The new TD assumes that the image will be tagged with its sha, which is different from the tag I’m using on Codefresh (the short commit rev).
I haven’t set ignore_changes_task_definition, but that’s true by default. Shouldn’t this prevent the task definition from changing? If not, how do I achieve that? I am happy for the service to be managed by ecs-web-app, but I need Codefresh to be in charge of ECR and the task definition.
I suppose an alternative approach would be to have Codefresh tag the images with the sha256 as well. Feels pretty hacky, though.
I did a search and discovered another thread from a few months back on this same issue. The advice was succinct. https://sweetops.slack.com/archives/CB6GHNLG0/p1631503151175000?thread_ts=1631287236.173300&cid=CB6GHNLG0
I would use the web app module more as a reference for how to tie all the other modules together
2022-02-06
Hi there. Does anyone have any experience yet with deploying AWS KMS “multi-region kms key” with EKS clusters? In other words could a multi-region kms key be used for a cluster in us-east-1 and also for another cluster in us-west-2? I am tasked with some research into whether or not this a) even works and b) is an attractive solution. We are currently running a “live” cluster in us-east-1 and a “backup” cluster in us-west-2. Could we run both using the multi-region kms key as the cluster encryption key? Has CP covered this yet with a module, by chance?
My answer will be not EKS nor Cloud Posse-specific: the multi-region KMS key works in a way that
• you create a “master” key (aws_kms_key) in us-east-1 and set “multi_region” parameter to “true”.
• you then create a KMS key replica (aws_kms_key_replica) in another region and point it to master_key_arn (or id, please check terraform docs). Master key’s key material will be copied from the master key to the replica, and you could use master in the first region and the replica in the second region. The advantage is that data encrypted by one key may be decrypted by another because they are using the same key material. If that is what you need, then master/replica is your solution. There’s no other way of my knowing to use the same key across regions. But I may be wrong.
Thanks Contantine. All your background info is totallly correct from my additonal research. In our case it turned out that MRK don’t make sense at this point becuase we have a very predictable “active/passive” design with respect to Regions. MRK it seems would have much greater appeal if we had live applications in both regions with data and client apps present in both Regions. In our case we replicate data to the non-active region , but the client apps only ever failover when we are reacting to AWS outages or other DR/BC activities.
2022-02-07
Hi colleagues, does anyone know how we can configure our s3 buckets so we can avoid the rate exceeded error?
ThrottlingException: Rate exceeded
status code: 400, request id
S3 throttles based on prefix, so you can restructure your bucket storage to distribute the objects across smaller prefixes.
Thank you for your response, i am afraid i cant do that easily - i am actually using driftctl to scan terraform states that reside in these s3 buckets
uhhhh
you may have an application issue in that case
you’re allowed 3500 PUT and 5000 GET per second, per prefix
might be a KMS error instead? That’s still like 1000 per second
can you configure driftctl to skip iterating the bucket? with that many objects there’s a 99.9% chance that you will have 99.9% drift
2022-02-08
Hi colleagues, we got an issue with two REST APIs services can not create connection. Our REST API has deployed in AWS gateway, it was created as HTTPS page with API key. When I try to connect via postman software (only https address and x-api-key are set) from company’s intranet (but also tested by tethering with our mobile’s 4g internet), it works. But, when NB-IoT supplier try to connect they receive “403 Forbidden”. Cloud watch logs shows only our connection, whether that are correct or not correct (e.g. if we try to connect without key). We dont have any waf configured to protect the api aws gateway, can someone point me to the proper troubleshooting steps please?
@matt
btw, are you using https://github.com/cloudposse/terraform-aws-api-gateway?
Contribute to cloudposse/terraform-aws-api-gateway development by creating an account on GitHub.
if the logs of api gateway show only your connection try to see if your your supplier is in the same area of you or try using a vpn to see if it’s not something else.
2022-02-09
Is it possible that these metrics should be different for ECS Fargate tasks, ie. ECS/ContainerInsights vs AWS/ECS namespace ?
https://github.com/cloudposse/terraform-aws-ecs-cloudwatch-sns-alarms/blob/master/main.tf#L57-L58
~ resource "aws_cloudwatch_metric_alarm" "cpu_utilization_high" {
- datapoints_to_alarm = 2 -> null
id = "linius-services-qa-assembly-cpu-utilization-high"
~ metric_name = "CpuUtilized" -> "CPUUtilization"
~ namespace = "ECS/ContainerInsights" -> "AWS/ECS"
tags = {}
# (15 unchanged attributes hidden)
}
I’m having a hard time finding / making sense of the difference but alarms aren’t firing as I might have expected with AWS/ECS?
Terraform module to create CloudWatch Alarms on ECS Service level metrics. - terraform-aws-ecs-cloudwatch-sns-alarms/main.tf at master · cloudposse/terraform-aws-ecs-cloudwatch-sns-alarms
hello all. we have a blackbox exporter to monitor our apps behind aws elb (classic currently). Sometimes I see i/o timeout on remote app side and no logs on our ELB side. Any idea?
2022-02-10
I am seeing quite a bit of InsufficientInstanceCapacity when I try to launch EC2s into a randomly chosen subnet from a VPC. Is there a way I can tell AWS during a RunInstancesCommand or similar command that I want to allow AWS to use any subnet within a VPC? It seems like my only option to put the EC2 into a VPC is to specify the SubnetId param, but ideally I’d like to pass in a list of acceptable subnets, not just one
I’d recommend to run instances via Autoscale Groups, so available capacity fishing will happen automatically.
Also additional handling is requited, maybe you just hit account limit and need to raise via support.
+1 for ASG. I also recommend you enable more than a single instance type.
That makes sense, thank you both. These are single-use CI runners, but I guess I can try launching an autoscaling group with 1 max instance just for the better support
Has anyone found a tool that can facilitate mass migration of data from one tier of Glacier to the other?
Sort of. We have some files in legacy Glacier (now known as Flex) and we want to move to the new Glacier tier called Instant Retrieval. They were/are being sent to Glacier via those policies now, but in this case we are looking to move existing files between glacier tiers.
Our AWS contacts have explained that it isn’t as easy as a simple transition. But I figured with the new Glacier tiers, we were probably not the only ones who want to move out of flex.
I remember looking into this a while back and at the time there was not way to move between tiers
what I was supposed to do was to pull EVERYTHING from glacier and start over but pushing it the right tier
Geez, it is really difficult to completely block public ingress! Any instance with a public IP is reachable, even with no IGW, but if that instance does have a route out a IGW/natgw, the return traffic will succeed also… https://twitter.com/__steele/status/1490566494517825547?t=WAlMvmEq8zOXSdRL8HCiAQ&s=19
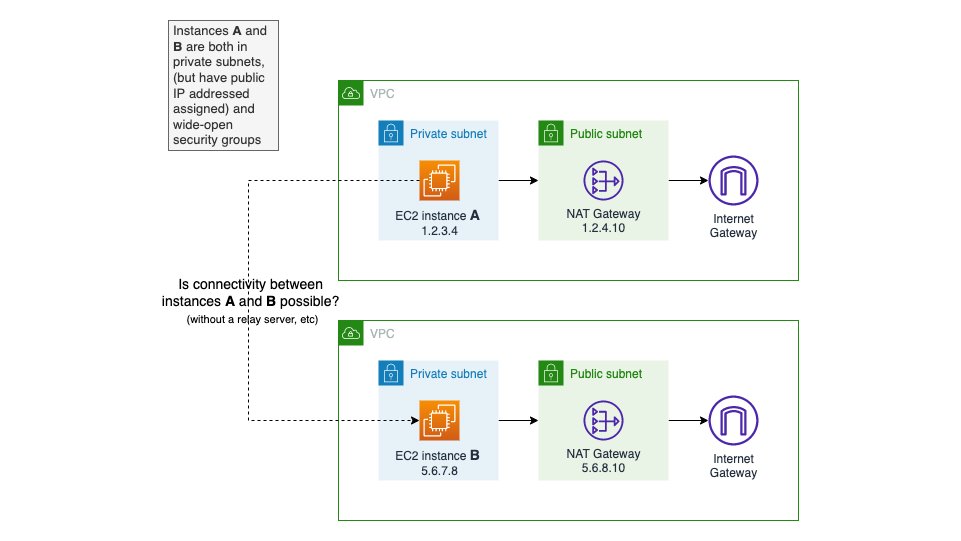
In the following AWS VPC architectures, can you send data from:
A -> B? B -> A?
A -> C? C -> A?
What path do the packets (attempt to) take? What about the return path?
The answers genuinely surprised me and has got me questioning my mental model of VPCs. https://pbs.twimg.com/media/FK-FhvmVgAAk56q.jpg
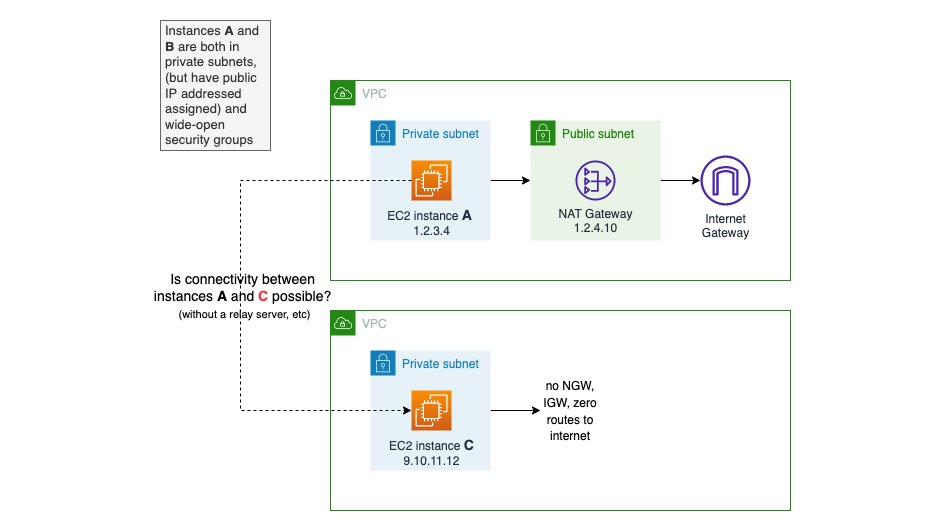
well if you have a SCP that does not allow public IPs and you deploy only private subnets without the 0.0.0.0 route it should work no?
In the following AWS VPC architectures, can you send data from:
A -> B? B -> A?
A -> C? C -> A?
What path do the packets (attempt to) take? What about the return path?
The answers genuinely surprised me and has got me questioning my mental model of VPCs. https://pbs.twimg.com/media/FK-FhvmVgAAk56q.jpg
And what is that SCP, please tell?!?
Can an AWS organization account stop or block child AWS accounts from launching public AWS EC2 instances having elastic ip? Would like those users within those accounts to launch only private ec2(s…
Examples in this category This SCP prevents users or roles in any affected account from deleting Amazon Elastic Compute Cloud (Amazon EC2) flow logs or CloudWatch log groups or log streams. This SCP prevents users or roles in any affected account from changing the configuration of your Amazon EC2 virtual private clouds (VPCs) to grant them direct access to the internet. It doesn’t block existing direct access or any access that routes through your on-premises network environment.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Deny",
"Action": [
"ec2:AttachInternetGateway",
"ec2:CreateInternetGateway",
"ec2:CreateEgressOnlyInternetGateway",
"ec2:CreateVpcPeeringConnection",
"ec2:AcceptVpcPeeringConnection",
"globalaccelerator:Create*",
"globalaccelerator:Update*"
],
"Resource": "*"
}
]
}
that will apply to new resources
Is the first answer in that stackoverflow a joke? What is an aws config SCP?
but if is a new account it will work
yes I think that is a new product that person invented
it is an alpha
lol
The second answer gets closer. I’ll try it tomorrow. Previously I had only seen that condition on ec2:RunInstances, but that’s not nearly enough
I’m working on an environment that it is exactly like that
no internet at all
vpc endpoints for everything
Yeah, same. Just not greenfield. And when you miss something like this, and think it’s ok cuz there is no IGW anyway, going back through hundreds of accounts and reviewing network captures to understand what may or may not have transpired is really not fun
I was really hoping the ingress nacl option on the subnets would work, but that broke all sorts of things in really fun and exciting and ticket-creating ways
some people use https://tugboatlogic.com/integrations/aws-integration/
Tugboat Logic integrates with AWS to automatically collect security evidence for your security audits like SOC 2, ISO 27001 and more!
Played with this some more, and still cannot find a good IAM policy (or SCP)… the second stackoverflow answer suggested a statement on the actions:
ec2:AllocateAddress
ec2:AssociateAddress
ec2:CreateNetworkInterface
using the condition key:
ec2:AssociatePublicIpAddress
but! none of those actions support that condition key. these are the actions that support the condition key:
CreateFleet
CreateNetworkInsightsPath
CreateTags (???)
DeleteNetworkInterfacePermission
ModifyFleet
ReplaceRoute
RequestSpotInstances
RunInstances
RunScheduledInstances
but you can’t use it on:
StartInstances
CreateLaunchTemplate
CreateLaunchTemplateVersion
and this is just ec2. there are plenty of other services you can deploy into a vpc and that could get a public IP…
2022-02-11
Hi All, I’m trying to use https://github.com/cloudposse/terraform-aws-s3-bucket/releases/tag/0.47.0 but when I run terraform with s3_replication_enabled = false , I get the following error: 168: for_each = local.s3_replication_rules == null ? [] : local.s3_replication_rules , I don’t understand what the module is expecting
Enhancements Feat: Enable Replication Metrics @max-lobur (#116) what Enable replication metrics by default Allow override via variables AWS provider requirements update due to: hashicorp/ter…
this is due to the 4.x provider
Enhancements Feat: Enable Replication Metrics @max-lobur (#116) what Enable replication metrics by default Allow override via variables AWS provider requirements update due to: hashicorp/ter…
add a new file locally to pin it
You can pin the provider version by updating [versions.tf](http://versions.tf) in the component to:
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 3.0"
}
}
}
anyone here has switched from the default 1:1 lambda <> cw log group mapping to N lambdas -> 1 single CW log group -> 1 subscription filter ?
the use case is v simple: consolidate all the logs in one place and then ship them out to 3rd party aggregation instead of having 1 filter per CW group (which goes messy if you have loads of lambdas, not to mention $$)
Hi All, what is the recommended way for EKS pods to CRUD on S3 buckets ? Is this https://github.com/cloudposse/terraform-aws-iam-chamber-s3-role/tree/0.7.5 still being supported ?
2022-02-12
AWS is generous to offer credits to cloud engineers and startups. Experiement or bootstrap your startup with AWS credits.
2022-02-14
Hi colleagues, has anyone applied the Fail2ban plugin for traefik on EKS? any issues with it? is it production ready? something that we need to have in mind during its implementation? thanks!
Hi all, we have a ElasticBean Stack instance platform is tomcat 8.5 with java8 running on 64 bit Amazon Linux.
everything was working fine, but recently. if we try to access the endpoint rand only we get Service Unavailable.
when i downloaded the logs by clicking on requist logs under elasticbeanstack_error_logs i cloud see following logs-
[Mon Feb 14 10:00:58.338035 2022] [proxy:error] [pid 14882:tid 139757313533696] (13)Permission denied: AH02454: HTTP: attempt to connect to Unix domain socket /var/run/httpd/ (localhost) failed
[Mon Feb 14 10:00:58.338078 2022] [proxy_http:error] [pid 14882:tid 139757313533696] [client <private-ip-here>:12566] AH01114: HTTP: failed to make connection to backend: httpd-UDS, referer: http://<custom-end-point>/1/<name.jsp>?s=sec$$4P!&refresh=300
[Mon Feb 14 10:43:40.663468 2022] [proxy:error] [pid 14882:tid 139757120071424] (13)Permission denied: AH02454: HTTP: attempt to connect to Unix domain socket /var/run/httpd/ (localhost) failed
[Mon Feb 14 10:43:40.663518 2022] [proxy_http:error] [pid 14882:tid 139757120071424] [client <private-ip-here>:21136] AH01114: HTTP: failed to make connection to backend: httpd-UDS
what more I can check to understand what is the issue to solve it. any help is appreciated thank you.
atmos terraform apply account –stack gbl-root
atmos terraform deploy account-map –stack gbl-root
at terraform-aws-components, it looks like we should declare ‘stage’ in account, which is needed by account-map.
maybe, when we didn’t declare ‘stage’ in account, it should be equal to account name.
2022-02-15
2022-02-16
Hi, im trying to use the cloudposse modules to deploy cloudtrail (with org enabled) but getting errors, having issues.
when i use a custom kms (also deployed via the cloudposse module). It looks to be an issue with IAM needing extra permissions. am i missing something in the module to resolve this or do i need to create a custom IAM and attach it?
Error: Error creating CloudTrail: InsufficientEncryptionPolicyException: Insufficient permissions to access S3 bucket organizationalcloudtrail or KMS key
Id like to log to cloudwatch as well, but again not sure if i should be creating my own IAM and attach for the cloud_watch_logs_role_arn
Thanks for any help
2022-02-17
Does anyone know whether it is possible to use a central OIDC provider within member accounts? The aws sts assume-role-with-web-identity call supports a --provider-id flag seems only to be for OAuth2 .. Or should each member account have their own OIDC provider configured?
2022-02-22
Hi all, We are using a webserver with ElasticBeanstalk from 2019., the platform is tomcat 8.5 with java8 running on 64 bit Amazon Linux. Apache as proxy recently (from Jan 30th) we started getting Service Unavailable issues if go to the endpoint from time to time. and if we refresh 2-3 times it will get resolved on its own.
then I download full logs. under elasticbeanstalk-error_log I can see
[Mon Feb 21 10:00:58.338035 2022] [proxy:error] [pid 14882:tid 139757313533696] (13)Permission denied: AH02454: HTTP: attempt to connect to Unix domain socket /var/run/httpd/ (localhost) failed
[Mon Feb 21 10:00:58.338078 2022] [proxy_http:error] [pid 14882:tid 139757313533696] [client <private-ip-here
:12566] AH01114: HTTP: failed to make connection to backend: httpd-UDS, referer: http://<custom-end-point
/1/<name.jsp
?s=sec$$4P!&refresh=300
[Mon Feb 21 10:43:40.663468 2022] [proxy:error] [pid 14882:tid 139757120071424] (13)Permission denied: AH02454: HTTP: attempt to connect to Unix domain socket /var/run/httpd/ (localhost) failed
[Mon Feb 21 10:43:40.663518 2022] [proxy_http:error] [pid 14882:tid 139757120071424] [client <private-ip-here
:21136] AH01114: HTTP: failed to make connection to backend: httpd-UDS
repeated multiple times from Jan30th.
and when I look at access.log
I can see 503 error log exactly at the same time when permission denied error logs in elasticbeanstalk-error_log
And I looked at the running process using ps -aux | grep httpd and ps -aux | grep tomcat
both are running from 2019 and have no restarts.
what more I can do to troubleshoot these issues
thanks
Has the application version changed or anything else about the environment?
It sounds like the app is crashing periodically and since the app is crashing the health check may be failing and then the load balancer returns a 503 since you have no healthy nodes.
Thanks for the reply @venkata.mutyala, if I run ps -aux both httpd and tomcat processes shows its START as 2019 only
Any recent changes to the environment? New code? New settings?
No changes to environment.
I assume you went through all the log files that beanstalk provided in the console?
Have you considered replacing a node and seeing if that resolves the issue? Not saying it prevents it from happening again but given the immutable nature of beanstalk I would be curious to know if it helps.
see your HD usage
df -h
see your Free Memory
free -m
see your CPU usage:
htop or top
We all know AWS regions have disparity in service hosting. As of today, us-east-1 (N. Virginia) hosts a max of 306 services while ap-northeast-3 (Osaka) has only 127 services hosted. I needed to answer, for any given AWS service which regions host the service, what services are hosted in a given region. Found a few ways. https://www.cloudyali.io/blogs/how-to-find-all-regions-an-aws-service-is-available
Not all AWS Services are available in all AWS regions. Simple ways you can find all AWS regions AWS services are available.
Is anyone using AWS SSM Session manager to enable devs to connect to a staging RDS instance, and NOT using ssh keys/connections managed through SSM?
Every blog post I see recommends using ec2-instance-connect to put SSH keys onto the instance, then opening an SSH tunnel to the instance to access RDS
I would ideally like to just use Session Manager to establish the tunnel if that’s possible
Yes, we do. You use SSM but it still is an SSH document being executed, temporarily, to upload your public SSH key into the remote host. Then establish the connection with SSM
Hrmm… the whole point IMO with session manager is not to use SSH keys, but IAM.
I think this pretty much describes it https://www.element7.io/2021/01/aws-ssm-session-manager-port-forwarding-to-rds-without-ssh/

How-to use Session Manager to establish a secure connection to an RDS running in a private subnet
There are cli’s that make it even easier
Easy connect on EC2 instances thanks to AWS System Manager Agent. Just use your ~/.aws/profile to easily select the instance you want to connect on.
Search slack for “sshm” and you’ll find related conversations
Hi, I have a question about VPC peering using multiple state files. We have two VPCs (vpc1 and vpc2) that we want to create peering. The peering was created successfully from vpc2 and I can resolve R53, connect to instances on both VPCs, etc. The problem is that when I run terraform plan from vpc1 directory, it doesn’t recognize the route tables added by vpc2 and wants to remove them. How can I get this to work? thanks!
Have you used remote states?
yes, I used remote state in vpc2 to create the peering.. do I need to use something similar in vpc1?
So the way I have done it in the past is create the VPCs first and then run the peering/route table creation. Basically have VPCs live in one or more of their own states and then do all the peering/route tables independent of any VPC creation… Does this make sense… VPC1/VPC2 first, then vpc peering/routes.
I am using the cloudposse vpc_peering module, which already creates the routes in both VPCs (both VPCs they are in the same AWS account).. Should I create the vpc_peering on VPC2 and then create the routes manually in VPC1?
(should I ask this in the terraform-aws-modules channel?)
Hello all! At risk of sounding obvious, why is it a best-practice from a compliance/ops standpoint to put all s3 buckets into their own AWS project? I ask because it sort of breaks the terraform mold of working with app-specific buckets (where normally you’d put them under the “dev” or “prod” account, as opposed to in “artifacts”)
We all know AWS regions have disparity in service hosting. As of today, us-east-1 (N. Virginia) hosts a max of 306 services while ap-northeast-3 (Osaka) has only 127 services hosted. I needed to answer, for any given AWS service which regions host the service, what services are hosted in a given region. Found a few ways. https://www.cloudyali.io/blogs/how-to-find-all-regions-an-aws-service-is-available
2022-02-23
2022-02-24
Hi Everyone! We just released the brand new UX/UI of Leapp, the local Desktop App that helps you in managing Aws credentials:
https://twitter.com/a_cava94/status/1496846237722632196
check it out and let me know what you think!
Define way #developers manage Cloud credentials locally.
This is why we create Leapp.
This is why we make it #opensource.
Today with a brand new UX/UI
A thread
Cool. I’ll check this out!
Define way #developers manage Cloud credentials locally.
This is why we create Leapp.
This is why we make it #opensource.
Today with a brand new UX/UI
A thread
Thanks awesome! let me know
like the fresh new look
Thank you! we tried to make it more a Desktop App like, with right click and double click actions
cool can’t wait to try it
I’ve got it setup for both IAM User and SSO for 10 accounts
the changelog for 0.9.0 looks promising https://www.leapp.cloud/releases
Leapp grants to the users the generation of temporary credentials only for accessing the Cloud programmatically.
has been making working with multiple AWS accounts so much easier
Thant’s great
hmm it now takes 2 clicks to login
also is dark mode on the roadmap for the UI ? it’s very white on my dark screen
but with a double click it start straight away agah
I’m a big fan of dark mode, I think theme will be added soon in a weekend of contributing
that weekend would be a month for me of contributing
i did create a dark mode ticket though for those weekend contributors
Great idea
does any know about when aurora serverless v2 will go live ?
2022-02-25
This may not the place to bring up the issue on https://registry.terraform.io/modules/cloudposse/kms-key/aws/latest where we see a yellow tag in:
most likely because enable rotation isnt true by default
see this comment by bridgecrew
https://github.com/cloudposse/terraform-aws-kms-key/pull/33#discussion_r798013920
hmm well it is enabled by default already https://github.com/cloudposse/terraform-aws-kms-key#input_enable_key_rotation
Terraform module to provision a KMS key with alias
cc: @Yonatan Koren i can never load bridgecrew properly. it shows up empty for me. can you see the error?
@RB no it’s blank for me as well. I’ve had some issues with the BC UI before.
Who should see the above?
better to ask this in #kubernetes
2022-02-26
Hi all i’m attempting to use eksctl within gitlab pipelines. Curerntly i’m using the alpine/k8s image but im running into the follow error:
Error: checking AWS STS access – cannot get role ARN for current session: RequestError: send request failed
caused by: Post "<https://sts.None.amazonaws.com/>": dial tcp: lookup sts.None.amazonaws.com on 172.20.0.10:53: no such host
Im just using regular IAM user keys as env vars in the project. I dont understand why its looking for a role ARN here? This post here details the problem, however the solutions all seem like one offs. https://github.com/weaveworks/eksctl/issues/1408
I’m getting started with EKS and I’m following Amazon guide
https://docs.aws.amazon.com/en_pv/eks/latest/userguide/getting-started-eksctl.html
I’ve defined an Administrator user under the Administrators group with the following policy
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "*",
"Resource": "*"
}
]
}
and with it I’ve set
$ cat ~/.aws/credentials
[default]
aws_access_key_id = ___
aws_secret_access_key = ___
$ cat ~/.aws/config
[default]
region = us-west-2
output = json
I’m able to
$ aws eks list-clusters
{
"clusters": []
}
$ aws sts get-caller-identity {
"UserId": "___",
"Account": "___",
"Arn": "arn:aws:iam::___:user/Administrator"
}
but the following fails
$ eksctl create cluster \ --name prod \
--version 1.14 \
--nodegroup-name standard-workers \
--node-type t3.medium \
--nodes 3 \
--nodes-min 1 \
--nodes-max 4 \
--node-ami auto
[ℹ] using region us-west-2
[✖] checking AWS STS access – cannot get role ARN for current session: RequestError: send request failed
caused by: Post <https://sts.amazonaws.com/>: net/http: TLS handshake timeout
$ eksctl get cluster
2019-10-06T22:58:51-07:00 [✖] checking AWS STS access – cannot get role ARN for current session: RequestError: send request failed
caused by: Post <https://sts.amazonaws.com/>: net/http: TLS handshake timeout
What am I missing?
I will admit, I haven’t used eksctl nor have i followed the link to see proposed solutions. So take that as you will :sweat_smile:
with that said, when i see None in something like this:
<https://sts.None.amazonaws.com/>":
I start thinking that the AWS_DEFAULT_REGION environment variable is not set.
Most AWS services are tied to an regional endpoint and I would assume the CLIs build the URL based on the AWS_DEFAULT_REGION env var.
I would reccommend checking your configuration to make sure you are setting AWS_DEFAULT_REGION correctly for where your services are located.
I’m getting started with EKS and I’m following Amazon guide
https://docs.aws.amazon.com/en_pv/eks/latest/userguide/getting-started-eksctl.html
I’ve defined an Administrator user under the Administrators group with the following policy
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "*",
"Resource": "*"
}
]
}
and with it I’ve set
$ cat ~/.aws/credentials
[default]
aws_access_key_id = ___
aws_secret_access_key = ___
$ cat ~/.aws/config
[default]
region = us-west-2
output = json
I’m able to
$ aws eks list-clusters
{
"clusters": []
}
$ aws sts get-caller-identity {
"UserId": "___",
"Account": "___",
"Arn": "arn:aws:iam::___:user/Administrator"
}
but the following fails
$ eksctl create cluster \ --name prod \
--version 1.14 \
--nodegroup-name standard-workers \
--node-type t3.medium \
--nodes 3 \
--nodes-min 1 \
--nodes-max 4 \
--node-ami auto
[ℹ] using region us-west-2
[✖] checking AWS STS access – cannot get role ARN for current session: RequestError: send request failed
caused by: Post <https://sts.amazonaws.com/>: net/http: TLS handshake timeout
$ eksctl get cluster
2019-10-06T22:58:51-07:00 [✖] checking AWS STS access – cannot get role ARN for current session: RequestError: send request failed
caused by: Post <https://sts.amazonaws.com/>: net/http: TLS handshake timeout
What am I missing?
eksctl:create:
stage: deploy
script:
- aws configure set default.region us-east-1; aws configure set aws_access_key_id $AWS_ACCESS_KEY_ID ; aws configure set aws_secret_access_key $AWS_SECRET_ACCESS_KEY
- if ! eksctl get cluster -n $CLUSTER_NAME ;then eksctl create cluster -f config.yaml ; else eksctl update cluster -f config.yaml ; fi
variables:
CLUSTER_NAME: npd
AWS_DEFAULT_REGION: us-east-1
I have tried the default region - no luck
2022-02-28
Hi, does anyone know how to list the values of aws:PrincipalTag/* associated with an identity? I’m trying to debug a POC, non-load-bearing AWS SSO connection with JumpCloud and would love some more visibility into what’s going on.
i think they’re visible in CloudTrail events?
otherwise, i’ve also snagged the saml assertion using browser dev tools and decoded it to see what is sent…
(if you’re using saml!)
I am, and I do see my expected assertions in the SAML that JumpCloud’s sending. I also see the principalId in CloudTrail along with a list of sessionContext:{attributes:{...}} , but I don’t see the properties I was expecting.
Which may very well be as good as I’m going to get.
I second saml tracer (firefox) for viewing the attributes
i assume your trust policy on the iam role allows sts:TagSession? if not, i don’t think it would work at all… at least, not if the tags were set properly on the JumpCloud side…
That’s correct, the AWS SSO-managed role has sts:TagSession . Looking up the docs on sts:TagSession eventually got me to the hint I needed, which is to filter CloudTrail events to Event Name: AssumeRoleWithSaml which does have the list of principalTags written out.
Thanks for your help (and the tip on saml tracer)!
woot!