#aws (2022-04)
 Discussion related to Amazon Web Services (AWS)
Discussion related to Amazon Web Services (AWS)
Discussion related to Amazon Web Services (AWS)
Archive: https://archive.sweetops.com/aws/
2022-04-01
Hey all, how does everyone manage the initial IAM Role creation at your organizations?
Specifically we’ve got a multi-account structure and looking to setup some Organization Access Roles that we can use to create other IAM Roles with more restrictive permissions. It seems like this will need to be run from a developer/administrator laptop using IAM User credentials, but curious how others approach initial IAM Role setup to enable developers in new AWS Accounts.
lambda that triggers on the CreateAccount event, assumes the role created by Organizations in the new account, and creates an initial role
AWS Organizations + SSO
initally we need to create the roles but then is automatic thru third party integration
@loren where do you run that Lambda? For us, I think we had a one-time setup done with a partner who helped us design our AWS org. They set this kind of stuff up initially from their laptop, and then tore down the over-privileged users. We still have the IAC for it, but it’s not in a point where it could run in a pipeline. The problem for us now is figuring out how we maintain some of these more foundational pieces. We don’t have changes very often, but it does change.
it runs in the Organizations account
That’s what I thought just didn’t want to assume
it kinda has to, because the role that Organizations creates in the new account only trusts the Organizations account…
Right — it’s a good idea - do you follow this approach yourself or is it just an idea you had to address the question?
we actually use it https://github.com/plus3it/terraform-aws-org-new-account-iam-role
 1
1we also have a simple “prereq” iam role config in terraform where we follow up and import the role that gets created that way, to maintain positive control over it
2022-04-04
2022-04-05
Follow up question to the above. We also use AWS Org+SSO. When we create a new account we obviously get a root account created in the new account. To be CIS compliant we need to enable MFA ideally hardware MFA for that account, has anyone managed to automate that? Ideally with terraform
just silence that CIS alert
Does this module meet your requirements? (fair warning I’ve never used it) https://github.com/terraform-module/terraform-aws-enforce-mfa
Enforce MFA policy creation and enforcing on groups.
I haven’t seen any module or automation that does this (but haven’t looked far). That said… Doesn’t look like it would be impossible though?
https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/iam_virtual_mfa_device
cc @matt as he would likely know and I’m sure he’s run into this before.
Thanks
@Soren Jensen if you come up with a solution using Terraform — I’d love to hear about it!
@Erik Osterman (Cloud Posse) Do you have any experience with this?
I believe we use our terraform-provider-awsutils to silence the hardware requirement since it’s not our best practice. our best practice is putting the MFA into 1password for business continuity.
package securityhub
import (
"fmt"
"log"
"github.com/aws/aws-sdk-go/aws"
"github.com/aws/aws-sdk-go/service/securityhub"
"github.com/cloudposse/terraform-provider-awsutils/internal/conns"
"github.com/hashicorp/terraform-plugin-sdk/v2/helper/schema"
)
func ResourceSecurityHubControlDisablement() *schema.Resource {
return &schema.Resource{
Description: `Disables a Security Hub control in the configured region.
It can be useful to turn off security checks for controls that are not relevant to your environment. For example, you
might use a single Amazon S3 bucket to log your CloudTrail logs. If so, you can turn off controls related to CloudTrail
logging in all accounts and Regions except for the account and Region where the centralized S3 bucket is located.
Disabling irrelevant controls reduces the number of irrelevant findings. It also removes the failed check from the
readiness score for the associated standard.`,
Create: resourceAwsSecurityHubControlDisablementCreate,
Read: resourceAwsSecurityHubControlDisablementRead,
Update: resourceAwsSecurityHubControlDisablementUpdate,
Delete: resourceAwsSecurityHubControlDisablementDelete,
SchemaVersion: 1,
Schema: map[string]*schema.Schema{
"id": {
Description: "The ID of this resource.",
Type: schema.TypeString,
Computed: true,
},
"control_arn": {
Description: "The ARN of the Security Hub Standards Control to disable.",
Type: schema.TypeString,
ForceNew: true,
Required: true,
},
"reason": {
Description: "The reason the control is being disabed.",
Type: schema.TypeString,
Optional: true,
Default: "",
},
},
}
}
func resourceAwsSecurityHubControlDisablementCreate(d *schema.ResourceData, meta interface{}) error {
conn := meta.(*conns.AWSClient).SecurityHubConn
controlArn := d.Get("control_arn").(string)
reason := d.Get("reason").(string)
input := &securityhub.UpdateStandardsControlInput{
StandardsControlArn: &controlArn,
ControlStatus: aws.String("DISABLED"),
}
if reason != "" {
input.DisabledReason = &reason
}
if _, err := conn.UpdateStandardsControl(input); err != nil {
return fmt.Errorf("error disabling security hub control %s: %s", controlArn, err)
}
d.SetId(controlArn)
return resourceAwsSecurityHubControlDisablementRead(d, meta)
}
func resourceAwsSecurityHubControlDisablementRead(d *schema.ResourceData, meta interface{}) error {
conn := meta.(*conns.AWSClient).SecurityHubConn
controlArn := d.Get("control_arn").(string)
control, err := FindSecurityHubControl(conn, controlArn)
if err != nil {
return fmt.Errorf("error reading security hub control %s: %s", controlArn, err)
}
log.Printf("[DEBUG] Received Security Hub Control: %s", control)
if !d.IsNewResource() && *control.ControlStatus != "DISABLED" {
log.Printf("[WARN] Security Hub Control (%s) no longer disabled, removing from state", d.Id())
d.SetId("")
return nil
}
if err := d.Set("reason", control.DisabledReason); err != nil {
return err
}
return nil
}
func resourceAwsSecurityHubControlDisablementUpdate(d *schema.ResourceData, meta interface{}) error {
if d.HasChanges("reason") {
conn := meta.(*conns.AWSClient).SecurityHubConn
controlArn := d.Get("control_arn").(string)
_, new := d.GetChange("reason")
reason := new.(string)
input := &securityhub.UpdateStandardsControlInput{
StandardsControlArn: &controlArn,
ControlStatus: aws.String("DISABLED"),
DisabledReason: aws.String(reason),
}
if _, err := conn.UpdateStandardsControl(input); err != nil {
return fmt.Errorf("error disabling security hub control %s: %s", controlArn, err)
}
}
return nil
}
func resourceAwsSecurityHubControlDisablementDelete(d *schema.ResourceData, meta interface{}) error {
conn := meta.(*conns.AWSClient).SecurityHubConn
controlArn := d.Get("control_arn").(string)
input := &securityhub.UpdateStandardsControlInput{
StandardsControlArn: &controlArn,
ControlStatus: aws.String("ENABLED"),
DisabledReason: nil,
}
if _, err := conn.UpdateStandardsControl(input); err != nil {
return fmt.Errorf("error updating security hub control %s: %s", controlArn, err)
}
return nil
}
Very good, thanks a million.. Happy to know it’s not a unique problem we got, and we are following best practice with 1password.
hi everyone! i just join your slack, i am using your module and new to Terraform, can someone please give a hint, can i use rate / cron expression with the module you provider ? https://github.com/cloudposse/terraform-aws-cloudwatch-events/tree/0.5.0 thank you very much
I’d post this over in #terraform and try to explain your problem more e.g. What are you trying to accomplish? Where do you want to use rate, etc.
Has anyone had any issues trying to EXEC into a Fargate instance? I’m getting the following error and our team is pretty stumped with this one.
An error occurred (TargetNotConnectedException) when calling the ExecuteCommand operation: The execute command failed due to an internal error. Try again later.
Of the 6/7 ECS clusters we have, we are able to exec in. The only material difference this cluster has is that we are using a NLB instead of an ALB … This is a recent issue for us without any changes to our infrastructure
I’ve never seen that. I would imagine it’s an issue with the Fargate host — Old version or something along those lines.
Do you have business support? I’d open a ticket with AWS.
I deal with this problem with System Manager Session manager, it happens to me whenever the instance (ec2 in my case) was not ready, like in a initializing status
2022-04-06
 Hello, team!
Hello, team!
Howdy y’all… question. I’m using the terraform-aws-ec2-instance module and want to add some lifecycle –> ignore_changes options so boxes don’t rebuild.
I went and created these options and was going to do a pull request and found that you cannot add variables inside the lifecycle stanza. So… how are people getting around this?
creating two resources with count - one for ignore_changes enabled, the other for ignore_changes disabled
That’s ugly. sigh
yes, not fun
been open for 2 1/2 years too!
Terraform Version
Terraform v0.12.6
Terraform Configuration Files
locals {
test = true
}
resource "null_resource" "res" {
lifecycle {
prevent_destroy = locals.test
}
}
terraform {
required_version = "~> 0.12.6"
}
Steps to Reproduce
terraform init
Description
The documentation notes that
[…] only literal values can be used because the processing happens too early for arbitrary expression evaluation.
so while I’m bummed that this doesn’t work, I understand that I shouldn’t expect it to.
However, we discovered this behavior because running terraform init failed where it had once worked. And indeed, if you comment out the variable reference in the snippet above, and replace it with prevent_destroy = false, it works - and if you then change it back it keeps working.
Is that intended behavior? And will it, if I do this workaround, keep working?
Debug Output
λ terraform init
2019/08/21 15:48:54 [INFO] Terraform version: 0.12.6
2019/08/21 15:48:54 [INFO] Go runtime version: go1.12.4
2019/08/21 15:48:54 [INFO] CLI args: []string{"C:\\Users\\Tomas Aschan\\scoop\\apps\\terraform\\current\\terraform.exe", "init"}
2019/08/21 15:48:54 [DEBUG] Attempting to open CLI config file: C:\Users\Tomas Aschan\AppData\Roaming\terraform.rc
2019/08/21 15:48:54 [DEBUG] File doesn't exist, but doesn't need to. Ignoring.
2019/08/21 15:48:54 [INFO] CLI command args: []string{"init"}
There are some problems with the configuration, described below.
The Terraform configuration must be valid before initialization so that
Terraform can determine which modules and providers need to be installed.
Error: Variables not allowed
on main.tf line 7, in resource "null_resource" "res":
7: prevent_destroy = locals.test
Variables may not be used here.
Error: Unsuitable value type
on main.tf line 7, in resource "null_resource" "res":
7: prevent_destroy = locals.test
Unsuitable value: value must be known
Thank you.
this is an example of how we did it
# Because create_before_destroy is such a dramatic change, we want to make it optional.
# WARNING TO MAINTAINERS: both node groups should be kept exactly in sync
see the comments
good technique, i’ll have to stir on it a bit
appreciate the quick and detailed response
Does anyone help me to setup airflow in EKS using terraform?

Organizations are adopting microservices architectures to build resilient and scalable applications using AWS Lambda. These applications are composed of multiple serverless functions that implement the business logic. Each function is mapped to API endpoints, methods, and resources using services such as Amazon API Gateway and Application Load Balancer. But sometimes all you need is a […]
excited
Organizations are adopting microservices architectures to build resilient and scalable applications using AWS Lambda. These applications are composed of multiple serverless functions that implement the business logic. Each function is mapped to API endpoints, methods, and resources using services such as Amazon API Gateway and Application Load Balancer. But sometimes all you need is a […]
loving it
2022-04-07
Dotnet lambda runtime version error Hi All, We are running a serverless lambda application running dotnet core 2.1 runtime(deployed through dotnet lambda deploy-serverless). Couple of days back, a person in our team accidentally tried to delete the cloud formation stack used to deploy this application. But as he did not have the required permissions, the stack status changed to DELETE_FAILED. As the status of stack became DELETE_FAILED, we were not able to update the application through cloud formation. Our deployment failed. So we deleted the stack manually and redeployed using dotnet lambda deploy-serverless command. But we got the following error: Resource handler returned message: “The runtime parameter of dotnetcore2.1 is no longer supported for creating or updating AWS Lambda functions. We recommend you use the new runtime (dotnet6 while creating or updating functions.) As aws was not allowing us to create a lambda with donetcore2.1, we changed the code to dotnetcore3.1 in seperate git branch and deployed again, which worked. There were still some bugs in 3.1 code, so we were still debugging. But yesterday on of our developer deployed the code in different branch, which had the stack runtime as 2.1. Now the runtime changed from 3.1 back to 2.1. We became confused, AWS says after end of support its not possible to create, update or rollback to unsupported runtime(https://docs.aws.amazon.com/lambda/latest/dg/runtime-support-policy.html). Even though cloudformation did not allow us to create the application in runtime dotnetcore2.1 but allowed us to change the running dotnetcore3.1 application to dotnetcore2.1. We tested the same in python also, Deployed the application running python3.9 and changed the runtime to unsupported version 2.7 It did not allow us to create in 2.7 but change the application runtime from 3.9 to 2.7. Now our question is as we are back to running our application in dotnetcore2.1, is it fine to continue with it for some time, as the code update is working. Or will AWS one day suddenly stops allowing code updates and its to better to move our application to dotnetcore3.1 now itself?
Learn how Lambda deprecates runtimes and which runtimes are reaching end of support.
Hey Question.. Are You using custom NAT instances for private subnets ? We have quite big spending for outbound traffic via NAT gateway, so wondering if custom NAT instances could do the work too. Ofc its possible, but is there any “cloud-native” way ? Routing via Squid deployed in Kubernetes with observability support, or some VyOS auto scaling group ? Ideas? Thanks
This is promising… https://github.com/AndrewGuenther/fck-nat/issues/8
If you’re interested in high availability support for fck-nat, follow this issue. All PRs and subtasks will be linked here. This issue will not be closed until the 1.2 release of fck-nat launches.
Nat instance would do just fine… I’m using it in my apps, so far no problem
Our subnet modules support a feature flag which can toggle between gateways/instances
2022-04-10
2022-04-11
2022-04-13
“Scaling containers on AWS in 2022” is out and may be of interest to y’all!
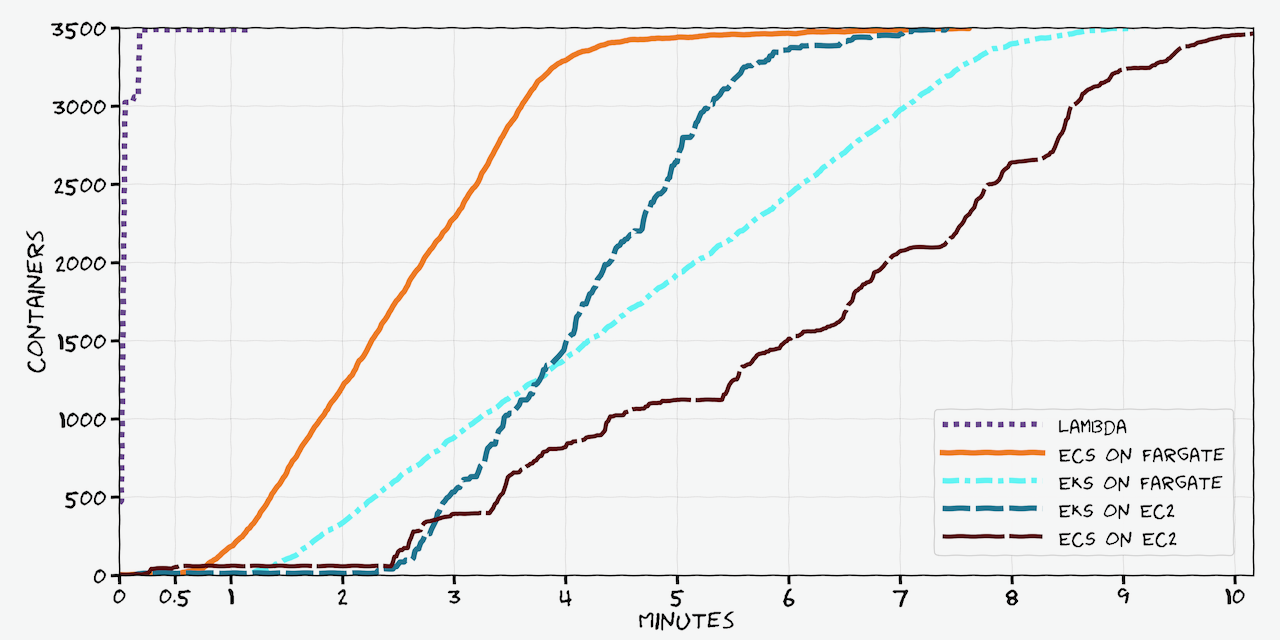
Comparing how fast containers scale up in 2022 using different orchestrators on AWS
This is a must read!
Comparing how fast containers scale up in 2022 using different orchestrators on AWS
The Lambda scaling up to 3k only seems like it hits the account limit for burst concurrency: https://docs.aws.amazon.com/lambda/latest/dg/invocation-scaling.html
If you pay enough, this limit can be changed
nice write up @Vlad Ionescu (he/him)
As requested, here’s the link to the Containers from the Couch livestream I’ll be doing later: https://twitter.com/rothgar/status/1514627176804470787
Today on #ContainerFromTheCouch @realadamjkeller and I will be talking with @iamvlaaaaaaad about his awesome post about scaling containers
1200PT/1500ET
http://twitch.tv/aws or https://youtu.be/WmdauESk5JA
https://www.vladionescu.me/posts/scaling-containers-on-aws-in-2022
2022-04-14
EventBridge vs SQS vs SNS can someone please tell me why EventBridge is "better" than SQS from the Architectural pint of view and maybe development code of view? I got asked some questions yesterday about details about messages/events per second etc
I knew I should have saved that flowchart I saw within the past day that covered this… I’m trying to find it now
Took a bit if hunting but found it.
is that from a blog? something I can read the reasons why?
I had found it posted on LinkedIn within the AWS certification community
I looked back and the post didn’t link to a blog post, it was just the image shared by another Cloud/DevOps Engineer
no problem
I had just come acrossed it last night and thought it was interesting then you asked about it… kismet
What do folks use as an observability platform when you are in a situation with multiple arch patterns?
• containers running in a single EC2
• serverless pattern ( high number of invocations)
• rds/ AMQ/ Elasticache/ DDB We have tried NewRelic but that was too expensive. WE are not on Datadog and is okay for now (it fixed a huge prob with devs having access to prod for troubleshooting etc), especially profiling but is getting very expensive: each EC2 + container hours + log ingested (not too bad) + log indexed ( scream! also cause we have garbage and log every single line )
Going in house with maybe APM/ AMG could be an option but having 2 different UIs and then correlate things …
I feel like any SaaS solution: be honeycomb.io / dynatrace/ logz.io etc won’t cut it unless we sort out the garbage in….
i know @Vlad Ionescu (he/him) has experience with honeycomb and might be able to speak to the pricing some…
Does Datadog allow you to drop logs before they get indexed? I know new relic and papertrail (I think logz.io too) allow you to do that for free so you don’t have to update your apps but you can still drop useless stuff without being charged for it.
Does Datadog allow you to drop logs before they get indexed?
yes and that is what we do today. However in order to be successful on that imo you need a consistent data coming in - i.e good quality log severity but is getting hard to manage it in the long run
There are 2 providers that ~don’t shit on their customers~ctively help customers send them less data: Honeycomb and Lightstep. That’s it! It’s… a strong signal.
@Vlad Ionescu (he/him) thanks for taking the time to chime in.
Honeycomb
~do you have any exp with them? I’ve looked and while it look impressive it doesn’t look like i can get the basic infra monitoring out - i.e disk usage/ cpu/ mem of the host (be that K8s or just a vanilla EC2) etc~ith OTEL collector it looks like i can achieve the above
Lightstep
i have tried them before ServiceNow bought them; my understanding is that SNOW will try to integrate it and sell it as part of the SNOW platform, in which case won’t work for us who use JIRA (is cheaper and is good enough)
Hey there, I am using the CloudPosse terraform modules for cloudposse/vpc/aws and cloudposse/multi-az-subnets/aws . I have two CIDR ranges in the VPC 10.20.0.0/22 and 10.21.0.0/18. The /22 is for public subnets in the VPC and the /18 is for private subnets. When I run the terraform the private subnets fail to create. I am able to create them manually in AWS however. What is the limitation here?
Can you post your config?
Hey there, I am using the CloudPosse terraform modules for cloudposse/vpc/aws and cloudposse/multi-az-subnets/aws . I have two CIDR ranges in the VPC 10.20.0.0/22 and 10.21.0.0/18. The /22 is for public subnets in the VPC and the /18 is for private subnets. When I run the terraform the private subnets fail to create. I am able to create them manually in AWS however. What is the limitation here?
@David Spedzia - You need to create subnets from your VPC CIDR range: 10.21.0.0/18 . Assigning CIDR ranges 10.21.0.0/18 , 10.21.64.0/18 , 10.21.128.0/18 and 10.21.192.0/18 to AWS subnets will fail as they are not subnets of 10.21.0.0/18 , they are subnets of 10.21.0.0/16 - I think what you want is /20 CIDR ranges for the four AWS subnets: 10.21.0.0/20, 10.21.16.0/21, 10.21.32.0/20 and 10.21.48.0/20 .
Thanks @tim.j.birkett, we use two CIDR ranges in the VPC as per the module which allows for that, also it works in a test deploy, so looks like an issue with my code. I have to refactor the whole thing anyways because we are changing how we deploy this resource anyways.
2022-04-15
2022-04-16
Hi All. Anyone know an easy was to make an S3 bucket policy there allow access to the bucket from any account in the AWS Organisation but no one outside the Org. As far as I can see it’s only possible by listing all the account ids.
AWS Identity and Access Management (IAM) now makes it easier for you to control access to your AWS resources by using the AWS organization of IAM principals (users and roles). For some services, you grant permissions using resource-based policies to specify the accounts and principals that can access the resource and what actions they can […]
Fantastic, thanks a million.. Not sure what I did wrong in my google search not to find that on my own..
Okay, so just a quick follow up as I learnt a lot the last few days.. First of all it’s not possible to create a central S3 bucket for the S3 Server Access logs. Every account need its own logging bucket. I opened a ticket with AWS Support and spoke with some S3 SMEs, only way to do a centralised logging is by logging in the account and replicate the logging bucket to the central logging bucket.
I opened a feature request, so maybe some day it will be possible.
ooooh true statement. i ran into that problem before once. good times.
It sure was an interesting experience..
encrypting buckets with centralized kms keys is another fun one. cloudtrail, config, guardduty, etc, etc. all slightly different configs. such a lovely experience.
Oh yes..
2022-04-18
2022-04-21
question.. we are using spot instances and sometimes termination handler cordons node incorrectly… with warning WRN All retries failed, unable to complete the uncordon after reboot workflow error=”timed out waiting for the condition”
If I ssh to the node I can get the metadata… what can be the issue ?
It is possible that it was rate limited
Because your instance metadata is available from your running instance, you do not need to use the Amazon EC2 console or the AWS CLI. This can be helpful when you’re writing scripts to run from your instance. For example, you can access the local IP address of your instance from instance metadata to manage a connection to an external application.
(IMDS rate limit)
oh. thanks
2022-04-22
2022-04-23
Does anyone else here use AWS’s managed Prometheus offering? I currently have it setup (along with Grafana) to just run on my nodes, but have been wondering if it’s worth moving over from a cost-maintenance ROI perspective.
I use it, managed Prometheus with Grafana, I’ve this question too, don’t researched enough to tell u if it’s worth. UP.
It depends on how you use it. Some of our workload is on AMP and a large part isn’t due to cost (and it’s totally our fault)
Sorry for resurrecting an old thread. @msharma24 and I have been battling trying to get this to work for weeks now. We’ve spun up AMP. We have Grafana running in one of our own pods, and can see the metrics in AMP just fine. However, when we try to use the alert manager in AMP, nothing ever triggers. Even the deadman event isn’t emitted.
Has anyone successfully set this up or have any sage advice on what could be wrong? Testing the pipeline from injecting messages to SNS works just fine.
Attached the definition and rules files for reference
2022-04-25
Hi, any functional terraform example to create an Amazon Managed Workflows for Apache Airflow?
Terraform module to provision Amazon Managed Workflows for Apache Airflow (MWAA)
thank you @RB
2022-04-27
GM Folks, I am wondering if anyone had thoughts on attaching multiple services to a single alb using host based routing vs an alb per “app or service”. Also maybe what you do more often than not that works best? tyia
Hi - what might the app or service be? EC2 instances, Fargate? Something else?
2They are all fargate
I’ve implemented the same as path based and it works pretty well. the host based should work just as well
Yeah, I was looking at that lol.
Host / path based over ALB per service unless you’ve got a really good reason. ALBs are not cheap if you stack them, so keeping to one if you can is the right call.
Perfect! Thank you guys so much!
2022-04-28
do you have issues with rds ? currently we are facing with connection issues to aurora serverless v1
2022-04-29
anyone got any thoughts on this module? Has about a person year of effort from two AWS engineers. Seems reasonably flexible and well thought through based on the below video and is AWS’ response to the hell of managing EKS clusters. I’m aware that generally AWS’ terraform modules have had breaking changes, but it seems like they’re invested in maintaining this one.
https://www.youtube.com/watch?v=TXa-y-Uwh2w https://github.com/aws-ia/terraform-aws-eks-blueprints
Configure and deploy complete EKS clusters.
interesting. it uses anton babenkos terraform-aws-modules/eks/aws module
Configure and deploy complete EKS clusters.
some interesting patterns here.. thanks for sharing
2022-04-30
I’m trying to add multiple rules to a cloudposse security group with a rules block that looks like this:
rules = [
{
key = "HTTP"
type = "ingress"
from_port = 5050
to_port = 5050
protocol = "tcp"
cidr_blocks = module.subnets.public_subnet_cidrs
self = null
description = "Allow HTTP from IPs in our public subnets (which includes the ALB)"
},
{
key = "SSH"
type = "ingress"
from_port = 22
to_port = 22
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
self = null
description = "Allow SSH from all IPs"
}
]
This is failing with:
Error: Invalid value for module argument The given value is not suitable for child module variable “rules” defined at .terraform/modules/project_module.sg/variables.tf:60,1-17: element types must all match for conversion to list. And the problem is the
cidr_blocks. If I replace the first one with["0.0.0.0/0"]it works. I see that the output from theaws-dynamic-subnetsmodule isaws_subnet.public.*.cidr_block. The current value of thecidr_blocksvariable in the resource is["172.16.96.0/19", "172.16.128.0/19"], which sure looks like a list of strings to me. When I openterraform consoleand ask for the type ofpublic_subnet_cidrs, I just getdynamic. I’ve tried wrapping the output intolist()and adding an empty string to thecidr_blocksarray in the second ingress rule, but neither changes the error.
Anybody have any idea what am I doing wrong here?
I’m trying to add multiple rules to a cloudposse security group. Here is the relevant code: module "subnets" { source = "cloudposse/dynamic-subnets/aws" version = "0.39.8&