#kubernetes (2019-01)

Archive: https://archive.sweetops.com/kubernetes/
2019-01-08
Hello. I’m curious if anyone has had performance issues running kubectl against an EKS cluster? kubectl get po takes 5 seconds to complete. FWIW, when I used kops to create the cluster, kubectl get po would return quickly.
hrmmmmm
same size nodes, and same number of pods?
(roughly)
…are you using IAM authenticator with both?
actually, worker nodes are bigger.
let me confirm IAM authenticator
yep. uses aws-iam-authenticator.
so kops uses aws-iam-authenticator as well…
hrm…
@Andriy Knysh (Cloud Posse) have you noticed this?
(btw, are you using our terraform modules for EKS?)
sorry, no, at least not yet.
i wanted to find out if this is an EKS thing in general.
When I was testing EKS, I didn’t notice any delay
okay, that’s a good data point. thanks.
(@Andriy Knysh (Cloud Posse) wrote all of our EKS terraform modules)
Terraform module for provisioning an EKS cluster. Contribute to cloudposse/terraform-aws-eks-cluster development by creating an account on GitHub.
Maybe the Authenticator is slow to connect to AWS
i’ll investigate that. thanks.
Also, how do you access the kubeconfig file?
default ~/.kube/config
something must not be configured properly. i’m investigating. i’ll let you know what i discover.
sometimes using strace helps me figure out what the process is doing
enough to dig deeper
2019-01-09
@webb has joined the channel
Months ago, I shared a link to this awesome write up: https://medium.com/kubecost/effectively-managing-kubernetes-with-cost-monitoring-96b54464e419
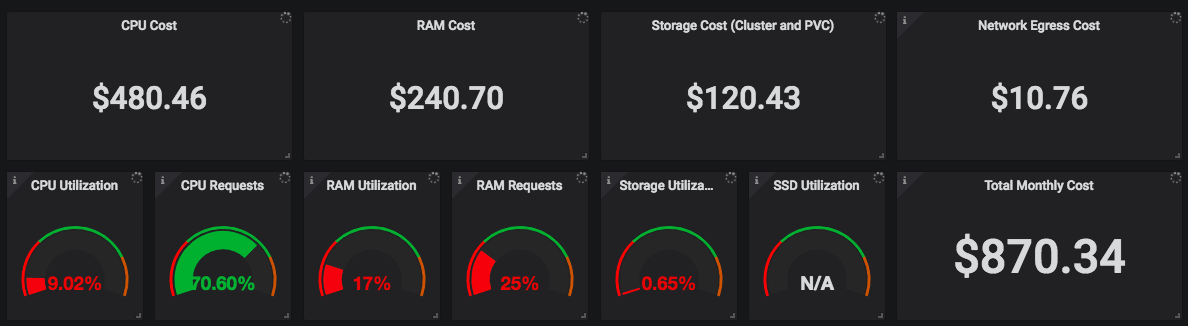
This is the first in a series of posts for managing Kubernetes costs. Article shows how to quickly setup monitoring for basic cost metrics.
I saw a demo of this yesterday and am super impressed.
I’ve invited @webb to #kubecost, so if you have any questions ping him.
Thanks for the kind words, @Erik Osterman (Cloud Posse)! We’re ready & available to help with tuning kube infrastructure!
2019-01-10
@Erik Osterman (Cloud Posse) Check this out. New Year it the time to imagine it. https://blog.giantswarm.io/the-state-of-kubernetes-2019/

Last year I wrote a post entitled A Trip From the Past to the Future of Kubernetes. In it, I talked about the KVM and AWS versions of our stack and the imminent availability of our Azure release. I also…
Just got access to the GKE Serverless Add-on beta: https://cloud.google.com/knative/
Knative is a Google-sponsored industry-wide project to establish the best building blocks for creating modern, Kubernetes-native cloud-based software
wow thats slick
i’m going to give it a spin… looks interesting!
feels a little bit like fargate is to ECS
yea, that’s how interpreted it
hah, we’ve all heard of dind (docker in docker)
first time hearing kind: https://github.com/kubernetes-sigs/kind
Kubernetes IN Docker - local clusters for testing Kubernetes - kubernetes-sigs/kind
 2
2 2
2I think this is pretty cool. We could leverage this for testing with geodesic.
Kubernetes IN Docker - local clusters for testing Kubernetes - kubernetes-sigs/kind
what Add support for Docker for Mac (DFM) Kubernetes or Minikube why Faster LDE, protyping Testing Helm Charts, Helmfiles howto I got it working very easily. Here's what I did (manually): Enabl…
2019-01-15
hi everyone ! I’m struggling to implement a CI/CD with Gitlab… I do have several different k8s cluster (one per stage “test”, “dev”, “stg” and “prd”) on different aws accounts (one per stage as before). I cannot find help on 2 things: how to target a specific cluster depending the branch ? and since we’re working with micro-services: how to keep a running version of my deployments on each cluster with a generic name not depending the branches names; but allowing an auto-deploy with uniques names in only one stage ? Could someone help me or link me to a good read/video about it ? right now, I just have my fresh new cluster; I still have to install/config everything (using helm).
hahaha there’s your problem.
I’m struggling to implement a CI/CD with Gitlab…
We highly recommend #codefresh.
Gitlab is one of the supported GIT providers in Codefresh. In this article, we will look at the advantages of Codefresh compared to the GitlabCI platform.
Codefresh makes it trivial to select the cluster.
We’ve used different strategies.
e.g. for release tags
1.2.3-prod or 1.2.3-staging
for branches, I suggest using a convention.
e.g.
a branch called staging/fix-widgets would go to the staging cluster
how to keep a running version of my deployments on each cluster with a generic name not depending the branches names;
Oops. Missed that.
So, the meta data needs to come from somewhere.
It can be ENVs in the pipeline configuration.
It can be branch or tag names. Note, you can use tags for non-production releases.
It can be manual when you trigger the deployments
@frednotet
cause Codefresh designed for using within Kubernetes, when Gitlab more general purpose
yes, exactly..
built from the ground up with support for docker, compose, swam, kubernetes, and helm.
Thanks I’m reading
(I just achieved my integration of gitlab but indeed I still have this multiple cluster that requires me to take the gitlab EE)
2019-01-17
@Ajay Tripathy has joined the channel
2019-01-18
anyone have authentication problems using metrics-server with a kops cluster? Also wondering if anyones run into heapster continuously in a CrashLoopBackOff because of OOMKilled
I’ve tried increasing the mem limit on the heapster pod but it doesn’t seem to increase
I have seen that. I recall not being able to figure it out. We don’t have it happening any more. This was also on an older 1.9 kops cluster.
it was driving me mad
no matter how much memory I gave it, it had no effect
@Erik Osterman (Cloud Posse) how’d you fix it? im on 1.11.6 kops
also have you switched to metrics-server
all our configurations are here:
Comprehensive Distribution of Helmfiles. Works with helmfile.d - cloudposse/helmfiles
i never ended up fixing it on that cluster. it was a throw away.
we do
oh wait
and heapster
you dont use heapster-nanny?
i don’t know the details
@Igor Rodionov would probably
the OOMKilled is also driving me mad
yea, sorry man!
i literally spent days on it
and didn’t figure it out
@Daren I forgot who is doing your prometheus stuff
I was having this problem on one of your clusters.
do you guys know why when I try to edit a deployment with kubectl edit the changes I make don’t stick?
usually it will emit an error when you exit kubectl edit
if it doesn’t check $?
kubectl edit ....; echo $?
weird
even if I increase the heapster deployment resource memory limit, it keeps dropping back down to 284Mi
no error btw @Erik Osterman (Cloud Posse)
$ k edit deployment heapster -n kube-system
deployment.extensions/heapster edited
@Erik Osterman (Cloud Posse) @btai we did have the heapster issue. I believe it was traced to having too many old pods for it to handle
It tried to load the state of every pod include dead ones
OH!! That makes sense
too many pods?
we do have alot of pods
were u able to fix it daren via configuration?
We switched to kube-state-metrics
so heapster just flat out stopped working for you guys
I believe we increased its memory limit to 4GB for a while then had to ditch it
so I’m unable to increase the mem limit for some reason. ill update the deployment spec resource limit for memory to 1000Mi and it will continue to stay at 284Mi
ever run into that?
I have ~5000 pods currently in this cluster
I had that issue. there’s also some pod auto resizer component
i think that was fighting with me
@Erik Osterman (Cloud Posse) you had the issue where you couldnt increase the mem limit?
also, i think daren is talking about exited pods
Yes
2019-01-19
2019-01-22
@Daren since youre using kube-state-metrics, are you unable to use k top anymore
Honestly, Ive never used it, and it appears it does not work
# kubectl top pod
Error from server (NotFound): the server could not find the requested resource (get services http)
i see
2019-01-26
https://github.com/stakater/IngressMonitorController pretty cool add-on for k8s to automatically provision health checks in 3rd party apps, these folks make a lot great open source projects, worth checking out
A Kubernetes controller to watch ingresses and create liveness alerts for your apps/microservices in UptimeRobot, StatusCake, Pingdom, etc. – [✩Star] if you're using it! - stakater/IngressMoni…
Yes, stakater is cool
I’ve been following them too
I want to deploy https://github.com/stakater/Forecastle
Forecastle is a control panel which dynamically discovers and provides a launchpad to access applications deployed on Kubernetes – [✩Star] if you’re using it! - stakater/Forecastle
Same here, I’ve been working on a “getting started on kubernetes” blog and was looking for fun new projects to include
I’ve been trying new projects out on a Digital Ocean K8s cluster, it’s multi-master + 2 workers, 100gb storage, and a LB for $30 a month
that’s cool
not too shabby for development
@Igor Rodionov has been doing that too
It’s honestly a very nice experience, as you know, my setup at work is very smooth already
haha, that said, always want to make things smoother
I think the ease-of-use of GKE/digital ocean k8s is what we aspire to
while at the same time getting the IaC control
Yeah! It’s really nice to have the model to work off of
Especially for smaller teams that don’t need all the bells and whistles and ultimate control over every little thing
Agreed. My experience with GKE was so nice and smooth, very much so what I base a lot of our tools off of. Their cloud shell is very similar in function to Geodesic, as you’re probably aware
Yea, I saw that. I haven’t gone deep on it, but it validates the pattern.
Also, #geodesic is always positioned as a superset of other tools, which means the google cloudshell fits well inside
But you bring up a good point.
I think we can improve our messaging by comparing geodesic to the google cloud shell
yeah, at least as an introduction to the idea
@Max Moon @erik means I also use DO for my pet projects
Right! We should chat
2019-01-27
hi everyone, i am creating a deployment example of nginx on kubernetes using manifest file and I want add prometheus monitoring on it
do you have some github manifest t share?
Are you using prometheus operator?
We use helmfile + prometheus operator to deploy monitoring for nginx-ingress here: https://github.com/cloudposse/helmfiles/blob/master/releases/nginx-ingress.yaml#L156
Comprehensive Distribution of Helmfiles. Works with helmfile.d - cloudposse/helmfiles
@Erik Osterman (Cloud Posse) I see. I will analyse your code. I would like just to add monitoring on top a easy nginx deployment like https://raw.githubusercontent.com/kubernetes/website/master/content/en/examples/controllers/nginx-deployment.yaml
I suggest using helm for repeatable deployments rather than raw resources
(unless this is just a learning exercise)
We install the official nginx-ingress helm chart here: https://github.com/cloudposse/helmfiles/blob/master/releases/nginx-ingress.yaml
Comprehensive Distribution of Helmfiles. Works with helmfile.d - cloudposse/helmfiles
(helmfile is a declarative way of deploying helm charts)
@Erik Osterman (Cloud Posse) yes, I am using helm. I was just trying to arrange an example based on manifest
2019-01-28
if I want to ssh into my EKS worker node, the default username is ec2user right?
@btai sorry - @Andriy Knysh (Cloud Posse) is heads down today on another project for a deadline on friday
have you made some headway?
i figured out the ssh username, i just left my question in case someone else searches for it in the future
yep! that’s great.
We’re about to release our public slack archives (hopefully EOW)

i do have a suggestion for https://github.com/cloudposse/terraform-root-modules/blob/master/aws/eks/eks.tf
Example Terraform service catalog of “root module” invocations for provisioning reference architectures - cloudposse/terraform-root-modules
I would change those subnet_ids to be private subnets and add a bastion module
yea, that’s a good suggestion.
haha
2019-01-29
@Erik Osterman (Cloud Posse) i remember u mentioning an aws iam auth provider that we should use for kubernetes
which one was it? kube2iam?
kiam
(avoid kube2iam)
we have an example of deploying it in our helmfiles distribution
@btai are you unblocked? what was the issue with worker nodes not able to access the cluster?
yes @Andriy Knysh (Cloud Posse) it was a stupid mistake, i had created the eks cluster security group but didn’t attach it to the cluster
@Erik Osterman (Cloud Posse) what was the reasoning to avoid kube2iam?
sec
thought we had a write up on it.
can’t find it
so kube2iam has a very primitive model. every node runs an a daemon.
when a pod needs an IAM session, it queries the metadata api which is intercepted by iptables rules and routed to the kube2iam daemon
that part is fine. that’s how kiam works more or less.
the problem is if you run a lot of pods, kube2iam will DoS AWS
AWS doesn’t like that and blocks you. so the pod gets rescheduled to another node (or re-re-scheduled) until starts
so we have this cascading problem, where one-by-one each node starts triggering rate limits
and then it doesn’t back off
so now we have 5000 pods request IAM credential in an an aggresive manner and basically the whole AWS account is hosed.
kiam has a client / server model
you run the servers on the masters. they are the only ones that need IAM permissions.
the clients request a session from the servers. the servers cache those sessions.
this reduces the number of instances hitting the AWS IAM APIs
and results in (a) faster assumed rules (b) less risk of tripping rate limits
@Erik Osterman (Cloud Posse) awesome that makes sense. thanks for the detailed answer!
hi everyone, I am deploying a prometheus operator to monitor my application. I probably misunderstood how it works
basically, for each application or servicemonitor you will have a prometheus instance
or you can share the cluster one with your application? what is the practice?
@deftunix when you deploy prometheus operator, it will scrape all pods including the app, so you don’t need to anything special about it
here’s how we deploy it with helmfile https://github.com/cloudposse/helmfiles/blob/master/releases/prometheus-operator.yaml
Comprehensive Distribution of Helmfiles. Works with helmfile.d - cloudposse/helmfiles
it will create these resources
Curated applications for Kubernetes. Contribute to helm/charts development by creating an account on GitHub.
yes, I have the prometheus operator running and monitoring my base infrastructure
I deployed it using the coreos helm chart in a monitoring namespace but my application service are not scraped
it’s scarpping just a set of servicemonitors “seems” predefined
does the app output any logs into stdout?
yes! I deployed an nginx with the exporter. when I created with the operator a servicemonitor and prometheus instance
dedicated to the app, it works
the target appear
Prometheus Operator creates/configures/manages Prometheus clusters atop Kubernetes - coreos/prometheus-operator
but I was expecting that adding the annotation to the services the scrape was automatic
and new target will be showed in my target list
did you also deploy kube-prometheus?
Prometheus Operator creates/configures/manages Prometheus clusters atop Kubernetes - coreos/prometheus-operator
Comprehensive Distribution of Helmfiles. Works with helmfile.d - cloudposse/helmfiles
in my “cluster-metrics” prometheus yes
so when you install kube-prometheus, it will install a bunch of resources including https://github.com/prometheus/node_exporter
Exporter for machine metrics. Contribute to prometheus/node_exporter development by creating an account on GitHub.
which will scrape metrics
yes, from node, apiserver, kubelets, kube-statistics
my problem are not the cluster-metrics, because them are fully supported by default by the helm chart but understand how the operator pattern work
2019-01-30
Is this a BUG REPORT or FEATURE REQUEST?: Feature request /kind feature What happened: As part of a development workflow, I intentionally killed a container in a pod with restartPolicy: Always. The…
Would have assumed the threshold off a CrashLoopBackoff be configurable
I am working on a demo where we deliberably kill pods
so I want to show resiliency. oh well.
have you guys checked out https://github.com/windmilleng/tilt
Local Kubernetes development with no stress. Contribute to windmilleng/tilt development by creating an account on GitHub.
I have it starred but haven’t gotten deeper than that
Local Kubernetes development with no stress. Contribute to windmilleng/tilt development by creating an account on GitHub.
Kubebuilder - SDK for building Kubernetes APIs using CRDs - kubernetes-sigs/kubebuilder
2019-01-31
Utilities to manage kubernetes cronjobs. Run a CronJob manually for test purposes. Suspend/unsuspend a CronJob - iJanki/kubecron
@Daren