#kubernetes (2019-02)

Archive: https://archive.sweetops.com/kubernetes/
2019-02-01
Hi everyone, which is the best way to manage kubernetes deployments using terraform? We are using atlantis to CI/CD infrastructure
There is the terraform kubernetes provider, but i don’t know if is good for production use
Personal opinion is that terraform is not a tool well suited for deployments on top of Kubernetes because it is only really good at creating and destroying resources. But updating resources less so.
fyi, I took the road with helm charts + terraform helm provider
the helm provider is okay
in our experience, we couldn’t do half of what we do with helmfiles
terraform template files don’t support conditionals
so writing flexible values via terraform is difficult
our use-case is slightly different since we need to support multiple companies/organizations, which leads to more conditionals
atm I’m using helm charts to differentiate between prod, qa, dev stage
it’s so good applying changes with the helm provider, I was afraid it had a lot of bugs being still at version 0.x
2019-02-05
2019-02-06
do you guys blue/green your k8s clusters when you want to upgrade or do you utilize rolling updates?
with kops we usually do rolling updates https://docs.cloudposse.com/geodesic/kops/upgrade-cluster/
You dont manage the cluster with terra right?
with TF we create other resources like kops backend etc.
yeah, but I was curious if you also did kops > terraf > atlantis or similar
Example Terraform service catalog of “root module” invocations for provisioning reference architectures - cloudposse/terraform-root-modules
Example Terraform service catalog of “root module” invocations for provisioning reference architectures - cloudposse/terraform-root-modules
no, we just provision the resources above with TF, but the cluster using kops commands from a template https://github.com/cloudposse/geodesic/blob/master/rootfs/templates/kops/default.yaml
Geodesic is the fastest way to get up and running with a rock solid, production grade cloud platform built on top of strictly Open Source tools. ★ this repo! https://slack.cloudposse.com/ - clou…
thanks
I guess you run kops commands out of band? not in CI
slow isnt it?
yea, takes some time
this is more of a terraform question, but if i had my k8s cluster deployed in its own VPC and I had the database in a seperate VPC. (they are provisioned seperately because I blue/green my k8s clusters when I want to upgrade) If I were to VPC peer, is it possible to not have to upgrade the security group of the database?
basically allow full access to the db if there is a vpc peering connection?
when you upgrade the cluster, is it still the same VPC?
nope
new k8s cluster, new vpc
can you make two of them in advance and just add the two SGs to the database’s SG?
yes
i can do that
that would require an extra step but i think thats the best approach
1. spin up new k8s cluster/VPC
2. update database terraform with new SG
3. cutover
4. spin down old k8s cluster
5. update database terraform remove old SG
actually @Andriy Knysh (Cloud Posse), if i provide the db security group to my cluster terraform I could use this
resource "aws_security_group_rule" "allow_all" {
type = "ingress"
from_port = 0
to_port = 65535
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
prefix_list_ids = ["pl-12c4e678"]
security_group_id = "sg-123456"
}
that would automatically do step 2 & 5 for me during cluster spin up and spin down
hmm… what about ingress rules for the db SG? (you need to update them as well)
when you create a new VPC and VPC peering, you can update the db SG with new ingress rules (unless you always have just the two VPCs and they never change, in which case you can add the SGs to the db ingress just once)
or, if you create the two VPCs with the same CIDRs and they never change, you can add the CIDRs to the db SG (after peering, the db will see those CIDRs)
I cant create two vpcs with the same cidr because its in the same account
that aws_security_group_rule will update the db SG with the new vpc_id to allow ingress
by the same I meant they could be different for the two VPCs, but they never change so you know the CIDRs in advance
ah yeah
that could work, but risk the chances someone spins up a different service using the same unused CIDR
(theres only 2 of us at my company that works on this stuff so very unlikely)
yes
so it’s better to just update the db SG with the new rule after you spin a new VPC
yep
At Tumblr, we are avid fans of Kubernetes. We have been using Kubernetes for all manner of workloads, like critical-path web requests handling for tumblr.com, background task executions like sending…
how are you guys monitoring your kubernetes nodes?
Prometheus & grafana
2019-02-07
How to enable Kubernetes Pod Security policy using kube-psp-advisor to address the practical challenges of building a security policy on Kubernetes.
@Erik Osterman (Cloud Posse) are you guys catching nodes that are going to have issues ahead of time?
i had a k8s node yesterday that spiked to 100% CPU randomly that had to be cordon & drained
This is a place for various problem detectors running on the Kubernetes nodes. - kubernetes/node-problem-detector
@btai this look good?
interesting
i will try it out
the daemon.log was showing some interesting stuff
on that node that started having issues
This is a place for various problem detectors running on the Kubernetes nodes. - kubernetes/node-problem-detector
If you can generate a check, you can do a custom plugin like this
whats a custom plugin?
See example
Basically as simple as writing a a script that exits non zero
ah i see
Kubernetes custom controller for operating terraform - danisla/terraform-operator
Kubernetes custom controller for operating terraform - danisla/terraform-operator
I was at cfgmgmtcamp 2019 in Ghent, and did a talk which I think was well received about the need for some Kubernetes configuration management as well as the…
2019-02-08
Hi everyone, there is a project that manage EKS workers scale in using lifecycle hooks and lambda?
That is what the cluster autoscaler is used for
In other words, using a lambda to scale the cluster node pools could work, but it’s not the prescribed way in Kubernetes
Autoscaling components for Kubernetes. Contribute to kubernetes/autoscaler development by creating an account on GitHub.
Thank you Erik
but i need only to manage the scale in, when a node is removed by asg
i’m writing a new lambda that does kubectl drain on the node via SNS topic
i’m using plain asg with eks
plain asg’s as opposed to?
https://medium.com/@alejandro.millan.frias/cluster-autoscaler-in-amazon-eks-d9f787176519 looks like what I’d expect
Cluster Autoscaler automatically adjusts the number of nodes in a Kubernetes cluster when there are insufficient capacity errors to launch…
2019-02-10
@dryack has joined the channel
2019-02-12
hi all, wondering how can we retain the NATIP when recreating a cluster using kops.
there is an open issue https://github.com/kubernetes/kops/issues/3182 but couldn’t find a better solution
We currently have a kops cluster with a private topology. If we need to re-create this cluster, the elastic IPs associated with the NAT gateways are deleted, and new EIPs are allocated when the rep…
all solutions are more about deleting the cluster manually
2019-02-13
@rohit.verma haven’t had to do that
though I have had to do other things related to networking in kops and it’s always led to that I destroy/recreate =(
@ryangolfs
Have you ran <https://github.com/mumoshu/aws-secret-operator>
Because for the life of me I can’t get it to create secrets
<https://github.com/mumoshu/aws-secret-operator/issues/1>
Is my issuse as well .. just curious if you ran into this
@mumoshu
@ryangolfs has joined the channel
have you guys used envoy?
thoughts on it?
we have a basic example……
Example application for CI/CD demonstrations of Codefresh - cloudposse/example-app
with istio (envoy sidecar injection)
TL;DR: was impressed how it works and want to do more with it
Example application for CI/CD demonstrations of Codefresh - cloudposse/example-app
i dont really need service mesh/service discovery
is it worth it just for proxying/traffic mgmt
yea
traffic mgmt / shapping is what i like
circuit breakers, rate limiting, auth, etc
whats shapping?
how the traffic flows across deployments (canary releases)
ahh
sorry im not super familiar with istio, is it recommended to run envoy w/istio?
i haven’t used it yet, but i like the promise of standardized request logging also
can i just run envoy as my proxy layer?
so istio is a way to manage envoy sidecars
linkerd does the same thing
and there are other ways too
ah so i deploy istio and it deploys envoy sidecars for me in my pods
yup
so i currently use traefik as my reverse proxy
deployed as daemon set (pod on each node)
is envoy considered an optimization?
basically isitio helps you deploy envoy on k8s
i like traefik too, but we haven’t used it in the same context
not sure if the feature set overlaps
have you guys used istio with EKS?
Install Istio with the included Helm chart.
not sure if its outdated, but if you look under prereqs it doesn’t mention EKS
no
@johncblandii might also have done some research into that

Service Meshes enable service-to-service communication in a secure, reliable, and observable way. In this multi-part blog series, Matt Turner, founding engineer at Tetrate, will explain the concept of a Service Mesh, shows how Istio can be installed as a Service Mesh on a Kubernetes cluster running on AWS using Amazon EKS, and then explain some […]
sweet
ohhh
i misread EKS (!= ECS)
yeah no, eks
after using k8s, no point in using ecs
lol
yes
I didn’t actually use Istio. I started to mess with it but hadn’t. We are using EKS and ECS (Fargate), though.
Does anyone faced CoreDNS pods are getting stuck at “ContainerCreating” issue?
What do you see when you describe pod?
kubelet, ip-10-225-0-236.ec2.internal Failed create pod sandbox: rpc error: code = Unknown desc = failed to set up sandbox container “2c2fa70a9231264ea9e67bd058126b67fee7409691c74165590a75bfecf29d1f” network for pod “coredns-7bcbfc4774-kxqmd”: NetworkPlugin cni failed to set up pod “coredns-7bcbfc4774-kxqmd_kube-system” network: add cmd: failed to assign an IP address to container
something like that
cni plugin version is 1.2.1
i have checked, its not related to EC2 instance or networking or IP addresses in subnet
Haven’t had that, but that error looks to be a pretty good hint
my subnet has lot of free IP ‘s and instance has only 3 ENI’s used and it can attach up to 10
2019-02-14
what instance sizes are your master/worker nodes @ramesh.mimit
i was reading abut some issues with t3, m5, c5 or basically the new hypervisor (nitro) instances having this problem
i am using r5 instances, @sarkis and checked they are supported
@sarkis can you link where you were reading that?
On a node that is only 3 days old all containers scheduled to be created on this node get stuck in ContainerCreating. This is on an m4.large node. The AWS console shows that it has the maximum numb…
multiple reports of t3, m5, r5 ^ which are all the new nitro instances
oo thanks, looks like its happening as much as 3 days ago. I guess i will revert to r4 instances
nw! curious were you also seeing these issues? and doubly curious if it fixes the problem
set the channel description: Archive: https://archive.sweetops.com/kubernetes/
2019-02-15
Gatekeeper - Policy Controller for Kubernetes. Contribute to open-policy-agent/gatekeeper development by creating an account on GitHub.
What container registry do u guys use
Just stood up JFrog. We’re actively moving there.
ECR is the current option we use.
You?
Are you also using other parts of Artifactory?
As in Xray? If so, about to. As in other registries, definitely will be using it for npm and potentially some maven/etc packages.
we use quay, but im getting very frustrated with their support cause I havent been able to upgrade our plan for more private repos
how is ECR @johncblandii
ECR is ok but can be a pain. you do 1 registry per image (can tag separately) so you don’t say “mydockerreg/image:tag” to reference multiple tags. You create a registry per image and reference the whole thing like: [registryid].dkr.ecr.[region].[amazonaws.com/[image]:[tag]](http://amazonaws.com/[image]:[tag]). Up to the [tag] part is locked in as the image URI.
I guess you could get fancy with a generic image name and customize per tag for the rest but layers would prob be an issue at that point.
but it is decent. it definitely wouldn’t be something I’d recommend for someone with a lot of images
would you guys say if we were to use Istio for traffic management, we could just stay with classic AWS ELBs?
Yes
I’m still not jazzed on ALBs + k8s
current implementation creates one ALB per Ingress
also, enabling NLBs on classic ELBs is trivial
annotations:
# by default the type is elb (classic load balancer).
service.beta.kubernetes.io/aws-load-balancer-type: nlb
the downside with ELB classic is you lose the client IP
this can be hacked with Proxy Protocol
but nginx-ingress doesn’t report the target port with Proxy Protocol correctly, so you don’t know if the user is using TLS or not
do ALBs still take forever to create?
Yea they slow the create too
2019-02-18
 Anyone using Vault instead of Kiam, I’m new to k8s, and wondering what advantages&drawbacks are over using vault like this.
Anyone using Vault instead of Kiam, I’m new to k8s, and wondering what advantages&drawbacks are over using vault like this.
For AWS authentication? You have to manage Vault for a start
Vault could allow more flexibility than Kiam
Figured the kiam server needs to be managed as well, was hoping for it to be more elegant like the ecs-agent in that respect.
Yeah, you need to manage that too, agents and server
Has proved interesting in the past but I think mostly OK now
Vault does a lot more than Kiam though
How much do you want those other features?
I think Vault was chosen for the application secrets, so the logical step here would be adding the iam sessions
kiam is strictly around AWS services
If already using Vault, I’d stick with it over Kiam for IAM stuff
if not, kiam maybe a lower hanging fruit
thanks Josh!
IMO anyway, others will have other views
for sure, no worries
vault is not easy to setup https://aws-quickstart.s3.amazonaws.com/quickstart-hashicorp-vault/doc/hashicorp-vault-on-the-aws-cloud.pdf
( Still liking ECS even more, knowing all this )
Nope ^^ , but if you are already running it and have gone through that pain…
If you are AWS, SSM and Kiam may get you what you want easier
but I guess what vault can also do, is probably combining GCP with AWS, for the ones thinking about that ..
Sure….
but I don’t know of many folks actually doing that 
Multi provider is hard.
Vendor lock in is a thing
It’s all a tradeoff
I also don’t really care about being locked into AWS
A Vault swiss-army knife: A K8s operator. Go client with automatic token renewal, Kubernetes support, dynamic secrets, multiple unseal options and more. A CLI tool to init, unseal and configure Vau…
saw that the other day
looks interesting and is related
Ah nice
I’ve used https://github.com/UKHomeOffice/vault-sidekick before
Vault sidekick. Contribute to UKHomeOffice/vault-sidekick development by creating an account on GitHub.
bank-vaults looks fuller featured
Certainly more complex than Kiam to manage
haha yea
seriously
what I’d like to see (and there probably exists), is something that implements the AWS IAM metadata proxy pattern of kube2iam, kiam but uses vault as the mediator
then uses the [iam.amazonaws.com/role](http://iam.amazonaws.com/role) annotation just like kube2iam and kiam
that way the interface is interchangable
Annotations is a super nice way to drive those things in k8s
Declarative way of managing machines for Kubernetes cluster - gardener/machine-controller-manager
looks sweet
apparently 100% open source
2019-02-19
do you guys have an example using alb-ingress-controller with istio?
not together
2019-02-21
hello, does anyone know, how can i limit inbound traffic using AWS EKS nodes?
Close your security groups
for helm, do you guys do multiple helm installs for dependent helm packages or do you nest them in your helm package for the application being deployed?
I avoid chart dependencies and use mostly helmfiles; makes it easier to swap out pieces and target individual services for upgrades
im trying to use this helm package: https://github.com/helm/charts/tree/master/incubator/aws-alb-ingress-controller
Curated applications for Kubernetes. Contribute to helm/charts development by creating an account on GitHub.
and im curious how I should use it because it sets the namespace to be the namespace of the helm release but what if I don’t necessarily want to do that? Should I just modify the helm package files after I fetch them or is it bad practice
are you passing --namespace?
i wanted to avoid passing –namespace
2019-02-22
@btai You can set a value for namespace in values.yaml eg “custom_namespace” and then you reference it the templates {{ .Values.custom_namespace }}
Hi everyone ! Does somebody know the simplest way to enable hpa’s on a fresh new kops cluster ? metrics-server cannot connect (401 forbidden) and I can’t find the solution to retrieve metrics… maybe another solution ?
check this => https://github.com/kubernetes-incubator/metrics-server/issues/212#issuecomment-459321884 i’m sure this will solve your issue
Thanks @amaury.ravanel but I already saw it and It didn’t help to solve it
I’m still having same issue… it works on kube-system but not on the other namespaces
If ever somebody reads… It’s very strange I had to rolling-out nodes & master and it works everywhere…
Did you do the steps defined in the issue ? If so those requires a rolling-update to work because kops installs kubelet on both instances and master and kubelet should be restarted.
Your case seems weird man ^^. Can you ellaborate on the issue a bit ? Is this a new cluster ? What version it is ? Did you do an update (if so which versions) ? Did you update your kops binary (if so which versions) ? How do you use kops ? (Gitops / tf / cf / nothing and prey)
well, I have another problem actually
maybe they’re related
so I did several tests on a fresh new cluster
(I have 3 clusters: “test”, “stg” and “prd”. those 3 are fresh new and are coded with terraform/kops)
I now realize that I have 6 masters instead of 3
if I force a rolling-update; it create new instances but they’re not healthy enough to join the cluster
I see in their kubeconfig that they’re still configured on 127.0.0.1 instead of the k8s’s api. If I manually change this (+ restart kubelet), it will join the cluster
but I have this error :
Unable to perform initial IP allocation check: unable to refresh the service IP block: client: etcd cluster is unavailable or misconfigured; error #0: dial tcp 127.0.0.1:4001: connect: connection refused
and the validation failed. I think that’s the reason why it ups new EC2 without releasing the old ones
I think I will delete the full cluster and re-init it ‘cause I’m really lost and all my google is purple instead of blue now ^^
even if I’d like to understand…
I just finish reading
what cni are you using ? if calico check that your nodes can reach the etcd cluster
it’s weird that you are using the 4001 port for etcd
what version of etcd / kubernetes are you using ? are you using etcd-manager (opt-in by default on kops w/ kube >= 1.11) ? if yes can you paste me the /etc/hosts of your masters please ?
can you type this command against your etcd cluster and paste the output => etcdctl cluster-health
was using weave but I changed, reinstall everything with Calico… and everything works fine
1.11.6 if I well remember (> 1.11 anyway since I integrate Spotinst and it needs 1.11)
thanks for your help, even if I reset everything…
I can reproduce actually… My cluster was working fine after a fresh installation… I edit the instancegroup to add more nodes and then I had to rolling-update the cluster
the new master comes up; the old is terminated… but the new ones has a /var/lib/kubelet/kubeconfig set on 127.0.0.1 instead of the API
kops rolling-update cluster k8s.stg.**********.io --state=s3://***********-stg-kops-state --yes
NAME STATUS NEEDUPDATE READY MIN MAX NODES
master-eu-west-1a NeedsUpdate 1 0 1 1 1
master-eu-west-1b NeedsUpdate 1 0 1 1 1
master-eu-west-1c NeedsUpdate 1 0 1 1 1
nodes NeedsUpdate 5 0 5 20 5
I0225 23:04:28.528274 63403 instancegroups.go:165] Draining the node: "ip-10-62-103-158.eu-west-1.compute.internal".
node/ip-10-62-103-158.eu-west-1.compute.internal cordoned
node/ip-10-62-103-158.eu-west-1.compute.internal cordoned
WARNING: Ignoring DaemonSet-managed pods: calico-node-4ql85
pod/calico-kube-controllers-77bb8588fc-qcb4h evicted
pod/dns-controller-5dc57b7c99-dtw8j evicted
I0225 23:04:42.275404 63403 instancegroups.go:358] Waiting for 1m30s for pods to stabilize after draining.
I0225 23:06:12.280987 63403 instancegroups.go:185] deleting node "ip-10-62-103-158.eu-west-1.compute.internal" from kubernetes
I0225 23:06:12.340897 63403 instancegroups.go:299] Stopping instance "i-07f15ebb7078aec08", node "ip-10-62-103-158.eu-west-1.compute.internal", in group "master-eu-west-1c.masters.k8s.stg.musimap.io" (this may take a while).
I0225 23:06:15.287836 63403 instancegroups.go:198] waiting for 5m0s after terminating instance
I0225 23:11:15.299756 63403 instancegroups.go:209] Validating the cluster.
I0225 23:11:17.347229 63403 instancegroups.go:273] Cluster did not pass validation, will try again in "30s" until duration "5m0s" expires: machine "i-0567076920fedf435" has not yet joined cluster.
I0225 23:11:48.468847 63403 instancegroups.go:273] Cluster did not pass validation, will try again in "30s" until duration "5m0s" expires: machine "i-0567076920fedf435" has not yet joined cluster.
I0225 23:12:23.592726 63403 instancegroups.go:273] Cluster did not pass validation, will try again in "30s" until duration "5m0s" expires: machine "i-0567076920fedf435" has not yet joined cluster.
I0225 23:12:48.538343 63403 instancegroups.go:273] Cluster did not pass validation, will try again in "30s" until duration "5m0s" expires: machine "i-0567076920fedf435" has not yet joined cluster.
I0225 23:13:18.516763 63403 instancegroups.go:273] Cluster did not pass validation, will try again in "30s" until duration "5m0s" expires: machine "i-0567076920fedf435" has not yet joined cluster.
I0225 23:13:48.512016 63403 instancegroups.go:273] Cluster did not pass validation, will try again in "30s" until duration "5m0s" expires: machine "i-0567076920fedf435" has not yet joined cluster.
I0225 23:14:18.697398 63403 instancegroups.go:273] Cluster did not pass validation, will try again in "30s" until duration "5m0s" expires: machine "i-0567076920fedf435" has not yet joined cluster.
I0225 23:14:48.490544 63403 instancegroups.go:273] Cluster did not pass validation, will try again in "30s" until duration "5m0s" expires: machine "i-0567076920fedf435" has not yet joined cluster.
I0225 23:15:18.539400 63403 instancegroups.go:273] Cluster did not pass validation, will try again in "30s" until duration "5m0s" expires: machine "i-0567076920fedf435" has not yet joined cluster.
I0225 23:15:48.672146 63403 instancegroups.go:273] Cluster did not pass validation, will try again in "30s" until duration "5m0s" expires: master "ip-10-62-103-6.eu-west-1.compute.internal" is not ready.
E0225 23:16:17.352484 63403 instancegroups.go:214] Cluster did not validate within 5m0s
master not healthy after update, stopping rolling-update: "error validating cluster after removing a node: cluster did not validate within a duration of \"5m0s\""
are you saying that you are changing the number of nodes and it brings you new masters ?
2019-02-23
Has anyone seen this yet? I haven’t played with it, but it looks really cool.
Write a Tiltfile script that describes how your services fit together. Share it with your team so that any engineer can hack on any server. See a complete view of your system, from building to deploying to logging to crashing.
Local Kubernetes development with no stress
Anyone using Jaeger with K8’s here?
2019-02-24
@James D. Bohrman i’m using jaeger with k8s
How do you like it? I’ve been playing with it a bit and am having fun with it.
@amaury.ravanel are you using it together with Istio?
@Erik Osterman (Cloud Posse) yes and no
Let’s say not everywhere. I have tracing enabled by istio/envoy but some component are not injected by istio (lack of performances,…). So those just use the default jeager setup.
@James D. Bohrman it’s very nice and easy to implement if you use it with a service mesh. othw/ you shall implement it in yout code so k8s won’t help you with it
but I need to give a shot to the new elastic apm feature for opentracing
Has anyone looked into using AWS App Mesh (managed Envoy control plane ~ istio) with non-EKS kubernetes clusters? (e.g. #kops)
Is designed to pluggable and will support bringing your own Envoy images and Istio Mixer in the future.
Today, AWS App Mesh is available to use in preview
The Service Mesh Orchestration Platform. Contribute to solo-io/supergloo development by creating an account on GitHub.
@mumoshu have you seen this?
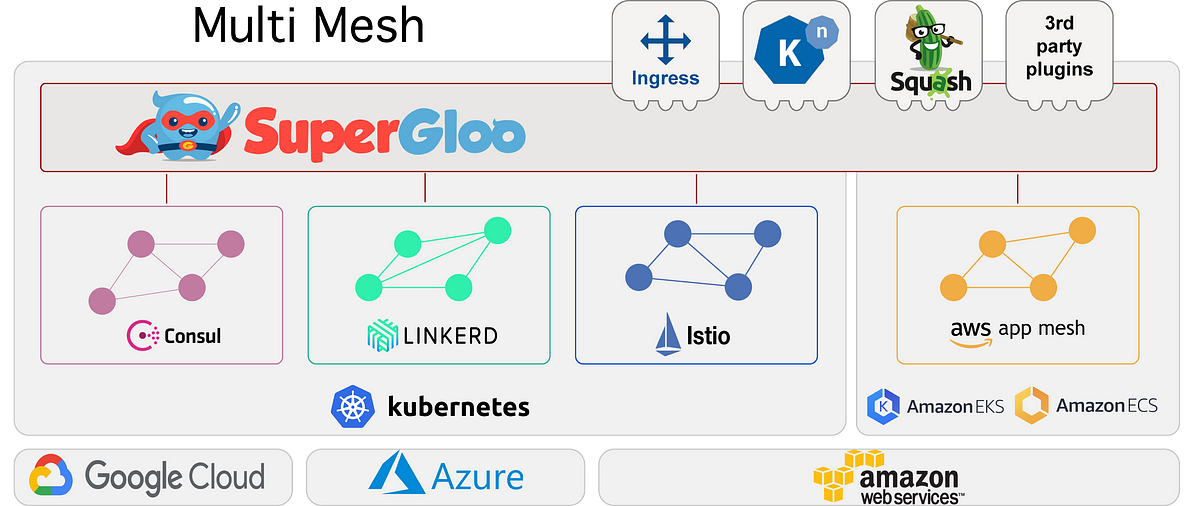
Today we are thrilled to announce the release of SuperGloo, an open-source project to manage and orchestrate service meshes at scale…
yep! i like the cli and their vision.
not yet sure if it worth another abstraction at this point of time
Today we are thrilled to announce the release of SuperGloo, an open-source project to manage and orchestrate service meshes at scale…
yea….
did you use it with AWS App Mesh?
not yet. just interestedf in istio + appmesh
2019-02-25
what do you guys use for SSL certs?
@btai which cert ? the one facing our apps ? or the one needed by kube to works ? (like api server, kubelet, …)
facing your apps
Anyone using Loki? https://github.com/grafana/loki
Like Prometheus, but for logs. Contribute to grafana/loki development by creating an account on GitHub.
I tried it and it looks great, well integrated with grafana explore and and even better now there is a fluentd output plugin to send logs from all fluend enabled slacks (https://github.com/grafana/loki/tree/master/fluentd/fluent-plugin-loki). still it’s still in alpha and not prod ready from now
Like Prometheus, but for logs. Contribute to grafana/loki development by creating an account on GitHub.
@endofcake I know that @zadkiel gave a try on this
Automatically provision and manage TLS certificates in Kubernetes - jetstack/cert-manager
this is what you need
nice im looking into that right now
whats the best way to generate some certs manually in the meantime?
openssl man
can i generate some with letsencrypt ?
CFSSL: Cloudflare’s PKI and TLS toolkit. Contribute to cloudflare/cfssl development by creating an account on GitHub.
yes you can
but man, certmanager is a maximum 1 hour setup for basic certificate generation
yeah?
yes !
there is an helm chart for that also in the github I linked to you
let me take a look I have some documentation for this in local
anyone going?
2019-02-27
2019-02-28
A Kubernetes operator for managing CloudFormation stacks via a CustomResource - linki/cloudformation-operator
Bringing cloud native to the enterprise, simplifying the transition to microservices on Kubernetes
Anyone using AWS Service Mesh?
I love Istio, but it’s k8s centric; we have a upcoming use-case to create a mesh across ECS and k8s
I personally dislike the aws policy regarding opensource stealing (app-mesh is istio) so maybe you can come with an in between using true opensource project that run on both ecs and kubernetes like linkerd for example (I’m not having this use case neither use linkerd)
I’ve read about it a bit, never used it. It seems interesting.
one day istio will be independent of k8s