#kubernetes (2019-03)

Archive: https://archive.sweetops.com/kubernetes/
2019-03-02
The registry for Kubernetes Operators
2019-03-04
Use K8s to Run Terraform. Contribute to rancher/terraform-operator development by creating an account on GitHub.
2019-03-05
anyone have an opinion on kops vs eks? Do you think $144 per stage a month is worth it for eks?
I guess it just depends on what the aggregate spend will be
If a company is spending 30k/mo on amazon, then the 144/mo is a nominal amount :-)
@Erik Osterman (Cloud Posse) Do you have any benefits/drawbacks of using kops or eks in your experience?
An automated drain/cordon strategy of rolling updates for EKS is lacking. As such, we have preferred working with kops. Until such a strategy exists, EKS+terraform we prefer to stick with kops
Even eksctl does not support rolling updates yet
running into this error with external dns and unlimited staging environments. are there any strategies for dealing with this besides being more restrictive with naming? in this case I’m using the git branch name.
"InvalidChangeBatch: [FATAL problem: DomainLabelTooLong (Domain label is too long) encountered with '14bd77e7-db57-4000-8250-d89cd97cef51-staging-db-myapplication-backend']\n\tstatus code: 400, request id: c7a58d7e-3fa5-11e9-9ea2-799474e23419"
Aha, yea need normalization
What works well is to use slashes as a delimiter in your branch names
in this case, the branch is actually staging-db and the repo is myapplication…
${{CF_BRANCH}}-${{CF_REPO_NAME}}-backend.${{BASE_HOST}}
ohhhhhhhhhh
yes, in that case you have too much information to pack into the hostname
need zones
(dots)
ah.. so this would work? [14BD77E7-DB57-4000-8250-D89CD97CEF51-staging-db.myapplication-backend.us-west-2.staging.lootcrate.cc?](http://14BD77E7-DB57-4000-8250-D89CD97CEF51-staging-db.myapplication-backend.us-west-2.staging.lootcrate.cc?)
thanks for the tip
something like that
you’ll need to update your ACM certs
to support the wildcard for *.[myapplication-backend.us-west-2.staging.lootcrate.cc](http://myapplication-backend.us-west-2.staging.lootcrate.cc)
right. still getting by with LE certs for now
aha
E.g. epic123/my-fix
Use the first field for the service disambiguation
This also allows you to have multiple PRs deploy to the same namespace
2019-03-06
has anyone every tried out openshift origin? Any opinions on it?
helped a client once, i wouldn’t do it again but i don’t know how it compares to other managed k8s solutions
first impression is that it’s hard to get the initial configuration right if you’re not familiar with it, think we ran the installation playbook like 10 times before it worked successfully
I didn’t like that it requires modification of the host OS
I wish openshift operated entirely inside of k8s
the actual installation is handled by ansible and pretty straight forward
when shit hits the fan you have 3 layers to troubleshoot - plain docker, kubernetes and openshift
is there any way to print all the kubernetes resource objects?
I would like to see all resources in a namespace. Doing kubectl get all will, despite of the name, not list things like services and ingresses. If I know the the type I can explicitly ask for that
So, anyone running Jenkins get docker images to build without using docker.build commands from the plugin?
We need to run TF commands to get state, pass in build args, etc and our Makefile handles this. I’d rather not recreate that in a Jenkinsfile. Running 1 simple: make release ... is much easier.
Thoughts?
why not have terraform write to parameter store instead
then use chamber to read those settings
this will also let you downscope access to those parameters and not need to expose terraform state to jenkins
that’s the goal. we’re in the conversion of projects and they rely on env vars right now. we’re iterating to get to that place, though.
2019-03-07
does anyone here have a pattern to preload docker images into their cluster before deploys
scenario where you have a weekly cadence (i.e. release every tuesday) and you could preload all the worker nodes with the images the monday night before?
How large is the cluster? Is this something exasperated by the size of your cluster when pulling the images?
2019-03-08
@Erik Osterman (Cloud Posse) we can assume ~50 worker nodes
Did you see the Docker registry released by Uber this week that uses a p2p/torrent model for image distribution to address the problem of slow pulls?

Developed by Uber, Kraken is an open source peer-to-peer Docker registry capable of distributing terabytes of data in seconds.
With a focus on scalability and availability, Kraken was designed for Docker image management, replication, and distribution in a hybrid cloud environment. With pluggable back-end support, Kraken can also be plugged into existing Docker registry setups as the distribution layer.
ah i heard about it, but i didnt realize they had created a more efficient way of distributing images
ill have to check it out. i guess it works as a layer above your docker registry?
Yes that’s one mode of operation
@Erik Osterman (Cloud Posse) talked to the folks maintaining kraken, sounds like it will help with the problem i have
they said they were running into the same issue
theyre also looking for help on the helm chart
@btai please post back later on how it works out for you
maybe something we should add support for in cloudposse/helmfiles
these guys @ uber on the container team have a super fast feedback loop
i asked about the helm chart earlier today for kraken, and they decided to take a first pass at it already
End result of helm install looks like this: $ kubectl get pods NAME READY STATUS RESTARTS AGE demo-6568968d44-g4nzw 1/1 Running 0 …
wow, impressive
anyone know anyone for an invite to slack.k8s.io ?
You have filled out the form?
they had an issue where bots were spamming channels with NSFW stuff so they had to shut down slack registration
2019-03-09
I don’t know any contributors or anyone to mention as sponsor
2019-03-12
Hi, is there anyone who used https://www.telepresence.io/ ? I’d like to gather experiences and/or possible alternatives.
Telepresence: a local development environment for a remote Kubernetes cluster
I haven’t used telepresence, but I was also researching tools for local dev. This one looks really interesting: https://github.com/windmilleng/tilt
Local Kubernetes development with no stress. Contribute to windmilleng/tilt development by creating an account on GitHub.
Any one uses helm plugins? Curious of your experiences with them. Came across this and it was interesting: https://github.com/totango/helm-ssm
Retrieves and injects secrets from AWS SSM. Contribute to totango/helm-ssm development by creating an account on GitHub.
Love the helm-git and helm-s3 plug-ins
Also helm-diff
2019-03-14
Anyone using makisu or kaniko for Docker builds?
Build Container Images In Kubernetes. Contribute to GoogleContainerTools/kaniko development by creating an account on GitHub.
Fast and flexible Docker image building tool, works in unprivileged containerized environments like Mesos and Kubernetes. - uber/makisu
2019-03-18
Hello everyone, it is safe to update worker nodes to the latest minor kubernetes ami version? I got EKS master plane on version 1.11.8 and worker nodes on 1.11.5 and 5 autoscaling group attached to the cluster
nevermind, i updated ami id, the minor version is still the same, 1.11.5
2019-03-20
any one here familair with alb ingress controlers?
a tiny bit. is this in regards to your post in #sig-aws on the kubernetes Slack?
we have a TF module to provision roles for alb ingress controller https://github.com/cloudposse/terraform-aws-kops-aws-alb-ingress
Terraform module to provision an IAM role for aws-alb-ingress-controller running in a Kops cluster, and attach an IAM policy to the role with permissions to manage Application Load Balancers. - clo…
and a helmfile to deploy alb ingress chart on k8s https://github.com/cloudposse/helmfiles/blob/master/releases/aws-alb-ingress-controller.yaml
Comprehensive Distribution of Helmfiles. Works with helmfile.d - cloudposse/helmfiles
I do. What is the question?
I followed all the steps from the echoserver tutorial for my app deployment/service/ingress. I can see the alb, target group, and security groups are created. But I’m still getting a 502 and healthcheck failing on the alb
@Igor Rodionov
@Tim Malone yeah it is
Is the alb permitted on the workers security group?
Did you make the service ( that is backend for ingress) type of NodeIP ?
@nutellinoit yeah the alb ingress controller added the security group to the workers. @Igor Rodionov I’m using NodePort
I do not know based on provided information
@Igor Rodionov i can provide my configs
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: galaxy-ingress
namespace: galaxy
annotations:
kubernetes.io/ingress.class: alb
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/tags: Environment=dev
alb.ingress.kubernetes.io/healthcheck-path: /health/
spec:
rules:
- host: blah.example.com
http:
paths:
- path: /*
backend:
serviceName: galaxy
servicePort: 80
kind: Service
apiVersion: v1
metadata:
name: galaxy
namespace: galaxy
labels:
service: galaxy
spec:
ports:
- protocol: TCP
port: 80
targetPort: 8000
type: NodePort
selector:
app: galaxy
kind: Deployment
apiVersion: extensions/v1beta1
metadata:
name: galaxy
namespace: galaxy
spec:
selector:
matchLabels:
app: galaxy
replicas: {{.Values.galaxyReplicaCount | default 3}}
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 100%
maxUnavailable: 50%
template:
metadata:
labels:
app: galaxy
spec:
containers:
- name: galaxy
ports:
- containerPort:8000
...
@tamsky @Igor Rodionov
@tamsky has joined the channel
2019-03-21
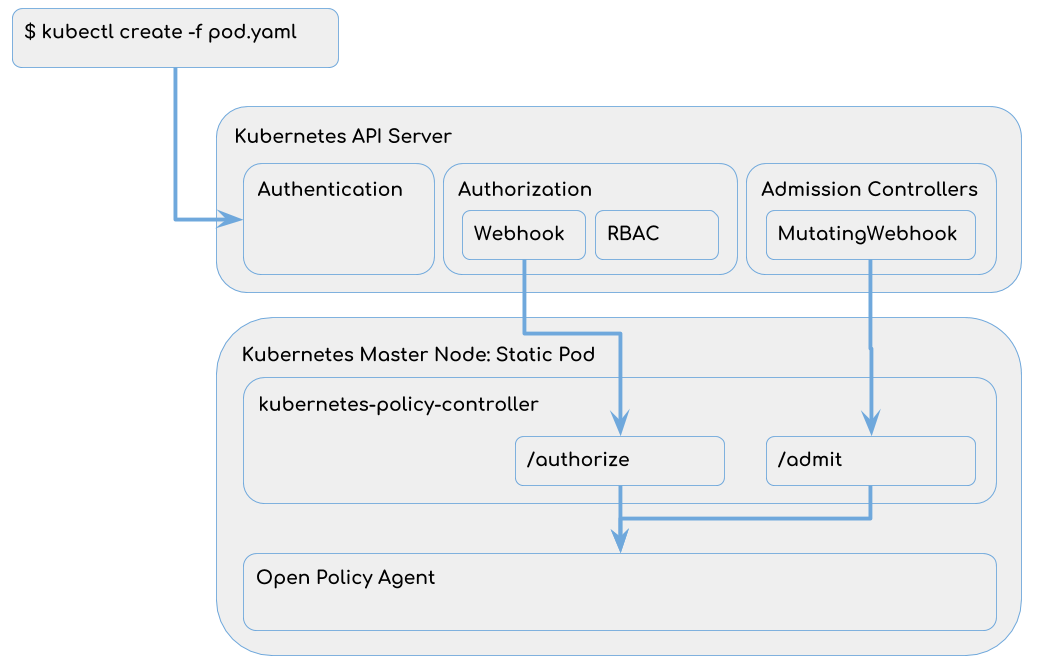
In a best-practice Kubernetes cluster every request to the Kubernetes APIServer is authenticated and authorized. Authorization is usually…
 1
12019-03-22
Hey there guys! Are you still using helmfile? Had some questions regarding the same
Sadly, couldn’t find any official community / channel for helmfile elsewhere
Yes! We use it extensively
Comprehensive Distribution of Helmfiles. Works with helmfile.d - cloudposse/helmfiles
Welcome @Abhsihek Jaisingh ! You’ve come to the right place as @mmuehlberger points out. Looks like @mumoshu is going to update the README for Helmfile so it will be easier for others to find.
2019-03-24
Check this up @Erik Osterman (Cloud Posse)
That’s awesome!
@Jeremy G (Cloud Posse)
2019-03-25
can we have an internet facing ALB that routes traffic to k8s worker nodes in private subnets?
Yes
That’s what we are doing
Comprehensive Distribution of Helmfiles. Works with helmfile.d - cloudposse/helmfiles
man i am having lots of trouble getting alb ingress controller to work on my cluster
i know you guys are using kops though (not eks)
and i just read this: https://docs.aws.amazon.com/eks/latest/userguide/network_reqs.html
When you create an Amazon EKS cluster, you specify the Amazon VPC subnets for your cluster to use. Amazon EKS requires subnets in at least two Availability Zones. We recommend a network architecture that uses private subnets for your worker nodes and public subnets for Kubernetes to create internet-facing load balancers within. When you create your cluster, specify all of the subnets that will host resources for your cluster (such as worker nodes and load balancers).
Note
Internet-facing load balancers require a public subnet in your cluster. Worker nodes also require outbound internet access to the Amazon EKS APIs for cluster introspection and node registration at launch time.
how did you set up your VPC? with the cloudformation template referenced in the EKS getting started docs?
(although i think that only creates public subnets… so might need some additional set up for private subnets for workers, but ALB ingress should still work once you’ve done that…)
with terraform
and it’s got the relevant config mentioned in the eks getting started docs? (subnet tags and such)
yeah it does
i wrote a blurb in #sig-network I can copy/paste here
I’m trying to debug why I cannot access my service on my cluster. I went through these debugging steps and I am stuck here where I cannot curl my service by ip: https://kubernetes.io/docs/tasks/debug-application-cluster/debug-service/#does-the-service-work-by-ip
The service is a NodePort service:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
galaxy NodePort 172.20.38.130 <none> 80:32697/TCP 3d
And when I try to curl the service IP from the k8s worker node, I get this:
node$ curl -v 172.20.38.130:80
* Rebuilt URL to: 172.20.38.130:80/
* Trying 172.20.38.130...
* TCP_NODELAY set
* connect to 172.20.38.130 port 80 failed: Connection refused
* Failed to connect to 172.20.38.130 port 80: Connection refused
* Closing connection 0
curl: (7) Failed to connect to 172.20.38.130 port 80: Connection refused
nslookup from the pod:
pod$ nslookup galaxy.galaxy.svc.cluster.local
Server: 172.20.0.10
Address: 172.20.0.10#53
Name: galaxy.galaxy.svc.cluster.local
Address: 172.20.38.130
I have this error message that I think is part of the problem in kube-proxy, but I cant find any remediation steps for it:
I0326 00:11:09.536462 7 healthcheck.go:235] Not saving endpoints for unknown healthcheck "galaxy/galaxy"
this returns nothing:
node$ sudo ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn

@Tim Malone
@Daren @Ram https://github.com/cloudposse/helmfiles/pull/107
what Update cert-manager chart to install version 0.7.0 Update kiam to version 3.0 (helm chart version 2.1.0) and use cert-manager to automatically provision its TLS certificates why Current ver…
@Max Moon @daveyu
shout out to @Jeremy G (Cloud Posse) for whipping this up
2019-03-26
Hi all, is anyone of you using https://registry.terraform.io/modules/terraform-aws-modules/eks/aws/2.3.0 to provision EKS cluster? I am experiencing an issue in the service type LoadBalancer. the cluster is not creating the balancer
Let’s move to #terraform-aws-modules . Ping @antonbabenko , he is the creator of the module
Then…
If, like me, you’re over 40 and work in IT, you’ll probably remember a time when everyone used Windows, and a small but growing proportion of people were wasting their lives compiling Linux in their spare time.
The Windows users would look on, baffled: ‘Why would you do that, when Windows has everything you need, is supported, and is so easy to use?!’
Answers to this question varied. Some liked to tinker, some wanted an OS to be ‘free’, some wanted more control over their software, some wanted a faster system, but all had some niche reason to justify the effort.
Now…
As I stayed up for another late night trying to get some new Kubernetes add-on to work as documented, it struck me that I’m in a similar place to those days. Until a couple of years ago, Kubernetes itself was a messy horror-show for the uninitiated, with regularly-changing APIs, poor documentation if you tried to build yourself, and all the characteristics you might expect of an immature large-scale software project.
That said, Kubernetes’ governance was and is far and away ahead of most open source software projects, but the feeling then was similar to compiling Linux at the turn of the century, or dealing with your laptop crashing 50% of the time you unplugged a USB cable (yes, kids, this used to happen).
It’s not like confusion and rate of change has come down to a low level. Even those motivated to keep up struggle with the rate of change in the ecosystem, and new well-funded technologies pop up every few months that are hard to explain to others.
Take knative for example:
The first rule of the knative club is you cannot explain what knative is— Ivan Pedrazas (@ipedrazas) March 18, 2019 So my AWS-using comrades see me breaking sweat on the regular and ask ‘why would you do that, when AWS has everything you need, is supported and used by everyone, and is so easy to use!?’
AWS is Windows
Like Windows, AWS is a product. It’s not flexible, its behaviour is reliable. The APIs are well defined, the KPIs are good enough to be useful for most ‘real’ workloads. There are limits on all sorts of resources that help define what you can and can’t achieve.
Most people want this, like most people want a car that runs and doesn’t need to be fixed often. Some people like to maintain cars. Some companies retain mechanics to maintain a fleet of cars, because it’s cheaper at scale. In the same way, some orgs get to the point where they could see benefits from building their own data centres again. Think Facebook, or for a full switcher, Dropbox. (We’ll get back to this).
Like Microsoft, (and now Google) AWS embraces and extends, throwing more and more products out there as soon as they become perceived as profitable.
AWS and Kubernetes
Which brings us to AWS’s relationship with Kubernetes. It’s no secret that AWS doesn’t see the point of it. They already have ECS, which is an ugly hulking brute of a product that makes perfect sense if you are heavily bought into AWS in the first place.
But there’s EKS, I hear you say. Yes, there is. I haven’t looked at it lately, but it took a long time to come, and when it did come it was not exactly feature rich. It felt like one cloud framework (AWS) had mated with another (K8s) and a difficult adolescent dropped out. Complaints continue of deployment ‘taking too long’, for example.
Finally taking AWS’s EKS for a spin. While I’m bias for sure, this is not what I expect from a managed Kubernetes offering. It’s been 10 minutes and I’m still waiting for the control plane to come up before I can create nodes through a separate workflow. Kelsey Hightower (@kelseyhightower) January 30, 2019 Like Microsoft and Linux, AWS ignored Kubernetes for as long as it could, and like Microsoft, AWS has been forced to ’embrace and extend’ its rival to protect its market share. I’ve been in meetings with AWS folk who express mystification at why we’d want to use EKS when ECS is available.
EKS and Lock-in
Which brings us to one of the big reasons AWS was able to deliver EKS, thereby ’embracing’ Kubernetes: IAM.
EKS (like all AWS services) is heavily integrated with AWS IAM. As most people know, IAM is the true source of AWS lock-in (and Lambda is the lock-in technology par excellence. You can’t move a server if there are none you can see).
Shifting your identity management is pretty much the last thing any organisation wants to do. Asking your CTO to argue for a fundamental change to a core security system with less than zero benefit to the business in the near term and lots of risk is not a career-enhancing move.
On the other hand, similar arguments were put forward for why Linux would never threaten Windows, and while that’s true on the desktop, the advent of the phone and the Mac has reduced Windows to a secondary player in the consumer computing market. Just look at their failure to force their browsers onto people in the last 10 years.
So it only takes a few unexpected turns in the market for something else to gain momentum and knife the king of the hill. Microsoft know this, and AWS know this. It’s why Microsoft and AWS kept adding new products and features to their offering, and it’s why EKS had to come.
Microsoft eventually turned their oil tanker towards the cloud, going big on open source, and Linux and Docker, and all the things that would drag IT to their services. Oh, and you can use the same AD as your corporate network, and shift your Microsoft Windows licenses to the cloud. And the first one’s free. Microsoft don’t care about the OS anymore. Nobody does, not even RedHat, a business built around supporting a rival OS to Windows. The OS is dead, a commodity providing less and less surplus value.
Will Kubernetes force AWS to move their oil tanker towards Kubernetes? Can we expect to see them embrace Istio and Knative and whichever frameworks come after fully into their offering? (I don’t count how–to guides in their blogs).
AWS’ Competition and Cost
I don’t know. But here’s some more reasons why it might.
Like Microsoft in the heyday of Windows OS, AWS has only one competitor: the private data centre. And like Microsoft’s competitor then (Linux), adoption of that competitor is painful, expensive and risky to adopt.
But what is the OS of that data centre? Before Kubernetes the answer would have been OpenStack. OpenStack is widely regarded as a failure, but in my experience it’s alive (if not kicking) in larger organisations. I’m not an OpenStack expert, but as far as I can tell, it couldn’t cover all the ground required to become a stable product across all the infra it needed to run on and be a commodity product. Again, this is something Microsoft ruled at back in the day: you could run it on ‘any’ PC and ‘any’ hardware and it would ‘just work’. Apple fought this by limiting and controlling the hardware (and making a tidy profit in the process). Linux had such community support that it eventually covered the ground it needed to to be useful enough for its use case.
OpenStack hasn’t got there, and tried to do too much, but it’s embedded enough that it has become the default base of a Kubernetes installation for those organisations that don’t want to tie into a cloud provider.
Interestingly, the reasons AWS put forward for why private clouds fail will be just as true for themselves: enterprises can’t manage elastic demand properly, whether it’s in their own data centre or when they’re paying someone else. Command and control financial governance structures just aren’t changing overnight to suit an agile p…
2019-03-27
If you work with Kubernetes, then kubectl is probably one of your most-used tools. This article contains a series of tips and tricks to make your usage of kubectl more efficient.
hello guys
somebody already have a problem with metrics using eks ?
the problem is in the hpa addon. from kubernetes-incubator
Hi, I am trying to deploy on AWS EKS which now supports Kubernetes HPA AWS Blog. I successfulyy deployed Prometheus via helm but now when i try to deploy the adapter i get the following error `kube…
2019-03-29
anyone have suggestions on a good rate-limiting gateway for kubernetes? I have been looking at kong, ambassador, and express-gateway, not sure which one to go with or if there is a better choice
@casey istio provides rate limiting (envoy)
This task shows you how to use Istio to dynamically limit the traffic to a service.
plus with istio you get so much more than just that
2019-03-30
@Erik Osterman (Cloud Posse) I was watching one of Kelsey HT’s keynote speeches, when he whips out his phone & starts using Google Assistant to manage some network services (via Istio)!! I’d love to see a well formed write-up discussing similar implementations &/or pitfalls/concerns.
Kelsey is a master of live demos
(has me very excited to control everything by voice)!!