#kubernetes (2020-06)

Archive: https://archive.sweetops.com/kubernetes/
2020-06-03
any suggestion for the “mailtrap” self-hosted on k8s app? (mailhog?)
I am using mailhog
2020-06-05
Hi, I am planning to install namespace isolation for my k8s cluster. I normally use ALB Ingress and External-Dns but each of them can only be scoped per namespace. What do you do or have done to make multi namespaced environment? I was planning to install a seperate Ingress ALB (though controller can span multiple namespace an ingress alb can only scope on namespace) and seperate External-DNS (https://github.com/kubernetes-sigs/external-dns/issues/1454 )
Is possible to use multiple namespace arguments to external-dns ? Something like: spec: containers: - name: externaldns image: [registry.opensource.zalan.do/teapot/external-dns//registry.opensource.zalan.do/teapot/external-dns:latest) args: - –sour…
and for ALB Ingress : https://github.com/kubernetes-sigs/aws-alb-ingress-controller/issues/329
After reading this issue I thought it would be possible to: have one ingress controller for the cluster have one ingress resource per namespace Have a single AWS ALB that can serve traffic into mul…
2020-06-09
I am forced to use statefulsets because I need to allocate relatively large volumes as I scale. I don’t need any other feature of statefulsets, like statefulness. podManagementPolicy: Parallel makes it slightly less bad.
So I’m trying to remove statefulset volumes on downscale… It’s a horror.
The cleanest way is racy: https://github.com/kubernetes/kubernetes/issues/74374
I’m trying to do that with a cronjob, where I apply a certain safety margin between the current replica size and the minimum pvc number I delete but targeting becomes really tricky… To combat the idiotic limitation of not being able to alter initContainers between releases (AHHHHHHHHHHHHHH!!!! What if some rollouts have online and some - offline migrations? A conditionally inserted init container to wait for migrations works for deployments!), I now create a separate statefulset per release. Now I also have to clean up volumes from the previous releases… what if there’s a rollback (because Helm is dumb as well and whines about “failed” releases, somehow Terraform has no such problems)…
Is there ANY way to autoscale volume claims along with a deployment? hostPath is a no-go.
What happened: The storage protection feature prevents PVC deletion until all Pods referencing it are deleted. This doesn't work well with Statefulsets when you want to delete the PVC and have …
:hiding: I assume persistentVolumeReclaimPolicy: delete doesn’t kick in?
What happened: The storage protection feature prevents PVC deletion until all Pods referencing it are deleted. This doesn't work well with Statefulsets when you want to delete the PVC and have …
I remember trying it, don’t remember why it didn’t work
persistentvolumereclaimpolicy is for pv not pvc, as long as the pvc exists, pv will too
also gp2 sc on aws has reclaimPolicy: Delete by default
Since you don’t need the statefulness can you just remove the storage protection finalizers?
I think it’s the finalizer that prevents deletion as long as the pvc is in use, and the original idea was to delete the PVC and rely on the finalizer to safely delete it - but there’s the linked race condition.
I don’t know about the behaviour without finalizers
I’m quite curious of it
I would be as well, finalizers are useful I’m certain but they sure do cause a headache when trying to remove/re-add resources….
I don’t think it’s possible to remove the pvc-protection finalizer, looks like there’s an admission controller that reinstates it.
Also, i believe it is the finalizer that’s responsible for cleaning up the volume
moreover, i don’t think there is ANY way to delete a pvc without triggering a race condition if pods decide to start at the same moment and see the pvc still existing but the volume is being deleted
you can remove the finalizers, not saying that you should or anything, but I have done so to force pvc deletion when I was in a pickle.
kubectl get pvc -n $NAMESPACE | tail -n+2 | awk '{print $1}' | xargs -I{} kubectl -n $NAMESPACE patch pvc {} -p '{"metadata":{"finalizers": null}}'
perhaps the version of kube I was on or the scenario was different enough for this not to be of any use to you though, sounds like you are in a semi-complicated situation
(removing finalizers on namespaces is even harder for what its worth…)
For the record, namespace finalizers need to be updated from within the cluster via 127.0.0.1 it seems. This wild script will do just that
#!/bin/bash
NAMESPACE=${NAMESPACE}
kubectl proxy &
kubectl get namespace ${NAMESPACE} -o json | jq '.spec = {"finalizers":[]}' >/tmp/temp.json
curl -k -H "Content-Type: application/json" -X PUT --data-binary @/tmp/temp.json 127.0.0.1:8001/api/v1/namespaces/${NAMESPACE}/finalize
I only did this on dev clusters as well, I’m no fool
well, I am a fool but not foolish rather.
interesting
the thing is, the race condition I want to avoid comes from pods starting when pvcs still exist so I don’t believe there’s a way to address it from the PVC side
i think i should just screw it, wait for stuck pods to appear and use that opportunity to write a cronjob to detect and delete them
on EKS 1.15 even if i patch them with null, rather than [], pvc-protection still gets reinstantiated
after a period of time?
what a pain
immediately
it’s an admission webhook i’m guessing
maybe you need to update the pv as well?
but it’s fine
since it’s upscaling and downscaling in cycles, it will largely take care of https://github.com/kubernetes/kubernetes/issues/74374
What happened: The storage protection feature prevents PVC deletion until all Pods referencing it are deleted. This doesn't work well with Statefulsets when you want to delete the PVC and have …
yeah, sorry I’m recommending hacks anyway, a cronjob is easy enough to setup ‘
yeah, sorry I’m recommending hacks anyway, a cronjob is easy enough to setup ‘
i do everything in kubernetes with CronJob
Kubernetes working group: here’s how to write an admission webhook to frobbocinattiete persistent fphagrum ghrooks. A Go project scaffolding is available at github.com/bla/bla/bla me: cronjob “*/5 * * * *” bash -euxo piepfail -c kubectl get something | xargs –no-run-if-empty kubectl delete ….
haha, so true
I converted an entire airflow deployment into kube into like 3 cronjobs once
running schedulers on schedulers to run simple curl commands is overengineering at its best….
and for the life of me I cannot remove pvc finalizers on resources now (home kube cluster running 1.18.2) I’ll have to dig into this one further
2020-06-10
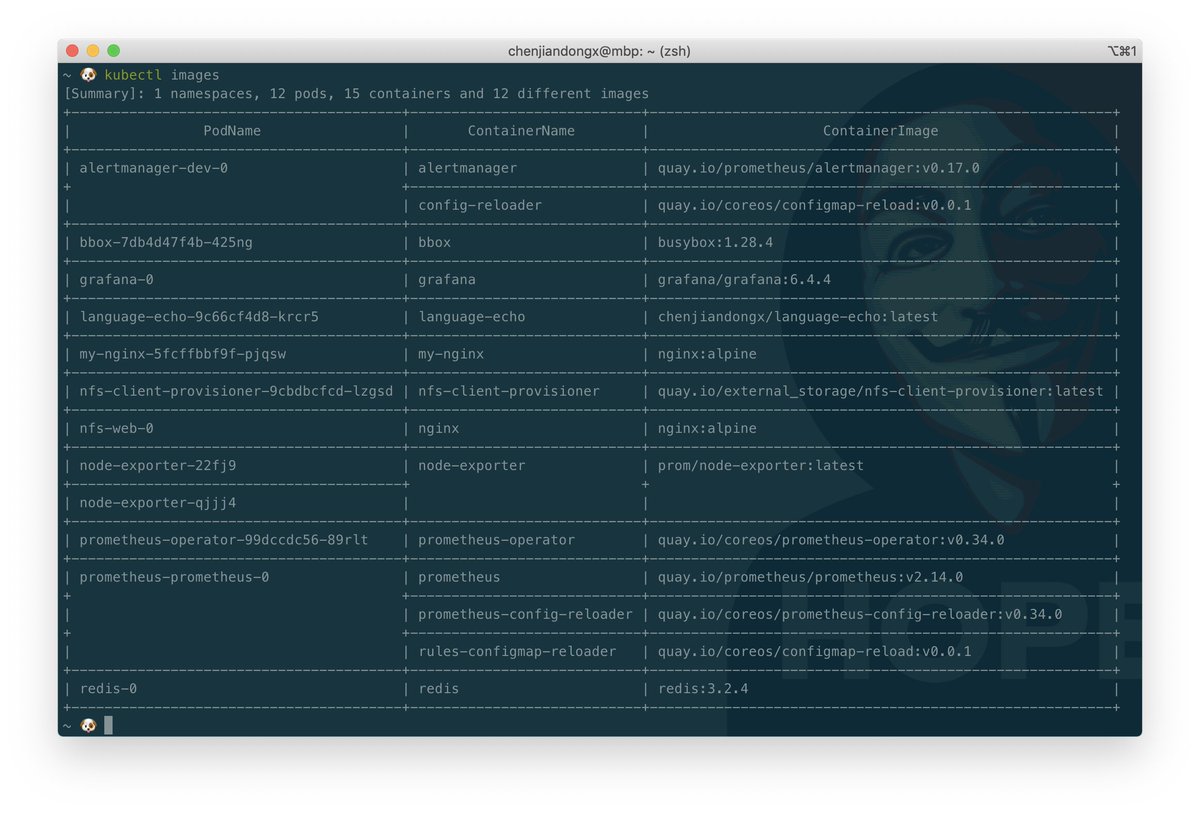
kubectl-images is a kubectl plugin that shows the container images used in the cluster.
It first calls kubectl get pods to retrieve pods details and filters out the container image information of each pod then prints out the final result in a table view.
https://bit.ly/2A4NCdD https://pbs.twimg.com/media/EaFsOBzXQAEiXQz.jpg
digging into k8s RBAC a little more, want to create a “read only” role for users - anyone know of any pre-defined helm charts that have different permission groups in them?
IIRC i did that with terraform
it’s EKS, the resulting resources are:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: companyname-view-only
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: view
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: Group
name: companyname:view
namespace: default
then in aws-auth:
apiVersion: v1
kind: ConfigMap
data:
mapUsers: |
- "groups":
- "companyname:view"
"userarn": "arn:aws:iam::1111111111:user/[email protected]"
"username": "[email protected]"
- "groups":
- "companyname:view"
"userarn": "arn:aws:iam::1111111111:user/[email protected]"
"username": "[email protected]"
helm is an overkill
it’s literally 2 resources on AWS, i don’t understand the need for extra tools, see above
Thanks - I did end up with something very similar, I agree helm feels like overkill but I’m also in a position where nothing on my cluster exists that isn’t deployed through helm and I think theres some value in that
I’ve done both routes. I think they are equally as valuable as long as you have multi-target capable declarative code for redeployment of your cluster settings
if you go with terraform then reduce your CRDs as much as possible (though the beta terraform provider seems like it should be able to support them)
for now i have both, but when it comes to resources like users (linked to people’s AWS users) and service accounts (linked to other AWS users) I keep that in terraform because Helm is completely separate and there’s no automation between the 2, other tan Terraform rendering kubeconfigs and value files for the “system” Helm chart that has the ingress controller, datadog, external dns, metrics-server, etc
Or, since it’s not an “app” would a helm chart be the wrong way to deploy it? Just thinking to reuse existing deployment patterns
maybe look at the rbacmanager chart, it will simplify role creation and binding a bit (creates some CRDs for you to use). But if you were just going to use straight k8s manifests you could use the raw chart in your helmfile to define your permissions as well.
Thanks, rbacmanager looks useful
rbacmanager is great, using it along with https://github.com/kubernetes-sigs/aws-iam-authenticator makes rbac so much easier to manage
A tool to use AWS IAM credentials to authenticate to a Kubernetes cluster - kubernetes-sigs/aws-iam-authenticator
2020-06-11
Anyone care to share their lessons-learned from running k8s on bare-metal? I’m looking for best practices and potential war stories.
n-fuse ‒ we facilitate digital transformation
My previous boss presenting my work
AFAIK - due to that CoreOS is dead now they did upgraded to FlatCar Linux that was fork from CoreOS
Thank you @Reinholds Zviedris - appreciate it very much. Looks like a good intro to all the related topics.
2020-06-12
I’m writing a k8s controller which monitors a CRD. I want the CRD definition to wrap the built-in Deployment spec schema without me having to redefine it. Is it possible? I want to be able to do something like this:
apiVersion: example.com/v1alpha1
kind: MyResource
metadata:
name: myresource
spec:
deployment:
replicas: 3
template:
metadata:
...
(Just like a normal deployment definition)

Misconfigured dashboards are at the heart of a widespread XMRIG Monero-mining campaign.
Unsecured dashboard on a public ingress… When will people learn
Misconfigured dashboards are at the heart of a widespread XMRIG Monero-mining campaign.
2020-06-15
i’m curious.. what do you guys use for continuous delivery/continuous integration/continuous release? i work at a smallish (~100 people) company and we’re generally jamming pretty hard on delivering product features instead of focusing on infrastructure. we use kubernetes and some folks use a service mesh, but not all, and we don’t always use the same clusters for various reasons.
some of the options i’ve considered (from cncf landscape) are flagger (requires service mesh) and spinnaker (gold standard? heavy weight). i suspect armory is above what i’m able to pay for a saas-type solution, and with limited time to focus on this specifically, flagger (service mesh) and spinnaker (learning curve/setup/maintenance?) i suspect is just overkill.
the other option i think i’m most likely to implement because it’s fast and easy is just using a separate deployment in the same cluster and weighted dns to serve some small percentage of traffic to a canary deployment and continuously deploy there first.
any thoughts/feedback appreciated.
this would be a great question for this week’s #office-hours
are you able to make it?
i haven’t been to one yet but i think i could probably make it.
unfortunately i have a follow up call with my manager and 2 teammates today at 4:30pm so i’m hoping to at least get some general “are we missing something obvious or making terrible decisions by not doing the right thing” feedback before wednesday, if at all possible.
I like the cncf landscape link. I’m curious if you have looked at GitHub Actions, CircleCI, or Jenkins - they’re pretty general pipeline tools that work well for CI/CD but don’t necessarily manage the infrastructure on your behalf
@joey it’s not clear if blue/green/canary is a requirement? is a mesh a requirement and if so, what’s driving it? if you can stick with rolling+helm releases, it’s all quite easy regardless of the platform.
if you need blue/green/canary and have some budget for saas, look into harness.io (at least get a demo so you can see what it looks like - it will shape your vision of it)
I’ve not used spinnaker, but I assume there is a decently steep learning curve to provisioning and maintaining spinnaker (on top of the ci/cd work to deploy your applications). Also netflix (the company that produced spinnaker) runs their own container orchestration product (not k8s) so I would check if the community that uses spinnaker have built tooling around it for easy integration with kubernetes (likely?). If I’m working on a small team, I would suggest GitHub Actions as the cheap/free solution. I’ve also felt the configuration for GH Actions is the best of the yaml-based configs I’ve seen out there for git based events. GH Actions + GH Repo templates have worked extremely well for us.
Harness sends me an email once a week, but I haven’t looked into it much :-). We’re using GitHub Actions + ArgoCD and are pretty happy with things.
i’d actually seen harness’ name before but it hadn’t occurred to me to look deeply. i took a gander today and it does look interesting but it’s not clear to me how harness controls what percentage of traffic gets to the canary.
I think the go to is Istio, but I assume you can use other things as well: https://harness.io/2019/10/service-mesh-series-part-3-3-istio-and-harness/
Time to get to shipping with your new fangled Istio Service Mesh. Supercharge your experience with Harness! Don’t be afraid to take the dip.
i think the simplest solution for me is actually going to be to use 3 different deployments, a canary with min/maxReplicas:N, an two deployments (a and b) that have hpa’s and represent the rest of traffic. i don’t necessarily get the fine-grained control of what percentage of traffic to send to canary, but it’s close enough my purposes short term.
yeah that’s the downside for me. istio is overkill for what i’m doing.
that’s a great simple approach. you could also look into doing it at the ingress controller level
i was thinking about that as an option but i’m actually going to move from aws-alb-ingress-controller to nlb soon and it’s not supported on nlb
flagger can be used with just nginx ingress https://docs.flagger.app/tutorials/nginx-progressive-delivery
2020-06-16
anyone have tradeoffs of using EKS managed node groups vs self managed?
i use spotinst with eks
You cannot alter the args to any of the kube services (which makes running jenkins with docker in docker) @johncblandii remember the flag?
spotinst is a nice alternative too
they basically do managed node pools too (and save you money at the same time!)
Yeah, I hate eks nodegroup because it doesnt allow target group attachment
I am still on classic autoscaling groups
I guess I will stick with classic autoscaling group for now
@btai you’re using ALBs?
@Erik Osterman (Cloud Posse) yep
is because you’re using WAF?
ALBs…
(pre-warming, cost, ..)
Yep, pretty happy with NLBs and with nginx. Can understand using ALBs if needing to manage lambda, waf, etc under one load balancer.
are u wondering why we are using ALB vs CLB or ALB vs NLB?
we were using AWS WAF for a while
but have since switched to using signal sciences
i’m curious why you’re using alb vs. nlb
have been using ALB for awhile now, tls termination wasn’t available for NLB at the time we did initial work on this. hasn’t been an issue for us to use ALB, but whats are the benefit for us switching to NLB?
(we have a ton of different subdomains under a wildcard cert — using something like cert-manager doesn’t work for us because of the certificate rate limits)
we are also generally all HTTP traffic as well. although I am not opposed to using an NLB if it makes sense (performance would be the biggest factor in making the switch) as we don’t actually utilize any of the HTTP based features of ALB (path based routing)
alb suffers from the “pre-warming” phenomenon - essentially aws starts you on a t2.medium or similar type machine for your alb and as you scale up requests/throughput they’ll move you to larger machines that offer (somewhat significantly) better performance
nlb does not suffer from pre-warming phenomenon. performance is more-or-less static regardless of throughput/requests, etc. and nlb performance should be on-par with largest scale alb
alb is also $.08 per LCU while nlb is $.06 per LCU, so 25% savings
i was in a similar boat that eks at the time didn’t support tls termination but now with 1.15 it’s trivial so it was a no-brainer to move
i haven’t actually gone back to check doing nlb with ssl termination, but i think one of the potentially large differences could be that nlb will expose your nodes’ tcp rmem buffers whereas alb does termination and at t2 size instances the buffers are pretty small and thus tcp performance is garbage
@joey thanks, we’re not quite at the scale that needs pre-warmed elbs but the cost savings + probable tcp perf improvements do pique my interest
2020-06-17
Hey :wave: - Is anyone using istio with Ingress resources? My problem is that many helm charts come with Ingress resource definitions and we’re using istio-ingressgateway as, well, our ingress gateway. Just can’t seem to get it to work as it should at the moment. Any gotchas that others might have encountered would be useful
Make sure you have the annotation [kubernetes.io/ingress.class](http://kubernetes.io/ingress.class): istio
default for most projects is nginx
And I would go as far as to say it is best practice to always deploy ingress as a separate chart/release from the origin chart (so don’t use baked in ingress that comes with most charts in favor of using a monochart or something similar)
The annotation is set :disappointed:, I think there’s something funky going on with the meshConfig and ingressgateway(s) being deployed in their own name space, I’ve tried a few things…
I’ve heard the term monochart a few times and believe it came up in an Office hours a while ago… but what is it? Any references to articles that I can look at?
It is a helm chart that allows you to create whatever you want, but in opinionated ways
Deploying as a separate chart / release would be helpful as we could use the preferable VirtualService resource which works perfectly.
You could also swap out your ingress definitions if you ever wanted to change then in a very systematic manner
So, a local or org specific helm chart. Ah… okay, I use the same Helm chart for deploying Java microservices for ~ 40 teams. I guess that Helm chart is a monochart. One chart used by different things (with different values). I didn’t know we’d given that pattern a name.
(I used this very technique to change from nginx-ingress to traefik at one point, but switching to a custom crd for any ingress is just as easy to do then)
I like to call it the archetype pattern but that’s lofty sounding wording….
CloudPosse has an excellent monochart for this kind of pattern
archetype pattern
Java devs will be very happy with that terminology.
Haha, that’s where I got it from, or close to it at least (oop programming land)
I’ve seen other’s recommend wrapping the upstream chart as a dependency in your own chart with the extra resources templated in it - What’s the opinion around that?
Anybody using Lens and sourcing creds via aws-vault? Found https://github.com/99designs/aws-vault/issues/561 but that isn’t doing the trick for me. Wonder if somebody else has stumbled upon trying to make that work.
When using desktop apps like Lens: https://github.com/lensapp/lens or Infra.app: https://infra.app/ They seem to have connection failures on a system that uses aws-vault. For example, I see errors …
I’m just using Lens with a Digital Ocean sandbox cluster
When using desktop apps like Lens: https://github.com/lensapp/lens or Infra.app: https://infra.app/ They seem to have connection failures on a system that uses aws-vault. For example, I see errors …
yeh let me grab you a snippet of my aws profile and kube config
aws profile
[profile my-profile]
region=ap-southeast-2
credential_process=aws-vault exec my-profile --json
mfa_serial=arn:aws:iam::9876543210:mfa/[email protected]
[profile my-eks-cluster]
region=ap-southeast-2
source_profile=my-profile
role_arn=arn:aws:iam::0123456789:role/CrossAccount-EKS-ClusterAdmin
external_id=chris.fowles
kube config:
...
users:
- name: my-eks-cluster
user:
exec:
apiVersion: client.authentication.k8s.io/v1alpha1
args:
- eks
- get-token
- --cluster-name
- my-eks-cluster
- --profile
- my-eks-cluster
command: aws
env:
- name: AWS_PROFILE
value: my-eks-cluster
the only bit that stuffs up my process is MFA
so i just need to make sure aws-vault has a session running already with mfa
i usually just do a kubectl get nodes and i can put in an mfa token then
@Chris Fowles Awesome! I’ll give that a shot. I forgot about the new credential_process config entry honestly. That landed recently, right? I use it for one of my profiles… just forgot about it.
yeh it’s relatively new
@Chris Fowles I experienced that very same issue; I just tried aws-vault exec PROFILE — open /Applications/Lens.app and it worked for me. I was prompted for the MFA
ah nice hack!
Did that work for you?
i’ll have to take a look later
I have a k8s role with the same name that gets created in every namespace on during cluster provision time (not maintained by helm) that I need to update. Is there a quick / easy way to update the role for all namespaces (without having to go through every namespace)
imperatively via kubectl and bash?
i was hoping for an easier way other than loop through all namespaces as i have ~1000
2020-06-18
Has anyone tried this? https://akomljen.com/meet-a-kubernetes-descheduler/

Sometimes pods can end up on the wrong node due to Kubernetes dynamic nature. Descheduler checks for pods and evicts them based on defined policies.
Haven’t tried it, but it sounds interesting
Sometimes pods can end up on the wrong node due to Kubernetes dynamic nature. Descheduler checks for pods and evicts them based on defined policies.
2020-06-19
Guys any recommendation of a terraform plugin that can get me started with Kubernetes Nodes on EC2?
I decided to contribute 32 nodes to a community cluster.
And I need to provide them nodes that can join a community Kube Master in about 2 hours.
I really appreciate any suggestions.
Thanks!
You could have a look at: https://github.com/cloudposse/terraform-aws-eks-workers
Terraform module to provision an AWS AutoScaling Group, IAM Role, and Security Group for EKS Workers - cloudposse/terraform-aws-eks-workers
Thanks.
We aren’t using EKS.
The Master is in another CLoud.
THe Nodes are being contributed from many AWS accounts by volunteers.
And we are currently stuck at this error:
error execution phase preflight: unable to fetch the kubeadm-config ConfigMap: failed to get config map: Get <https://xxx.xxx.xxx.xxx:6443/api/v1/namespaces/kube-system/configmaps/kubeadm-config?timeout=10s>: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
i’m guessing, but do your inbound NACL’s and security groups allow the traffic? is that coming from the master or the workers?
Not sure whats causign the timeout.

2020-06-23
i’ve never got to the point of actually implementing a pull through cache for docker
limiting egress traffic to the internet (cost, security), registry whitelisting and keeping things internal are the main reasons ive seen
has anyone here done so and have lessons to share?
playing with harbor has been on top of my list of things to do for a little while now
maybe i’ll do that today
2020-06-24
Fellas, I am looking for industry recommendations of handling the alerts in Prometheus Server on EKS.
Currently, I am managing the alerts by editing the configmaps of the specific Prometheus pod and adding the alerts over there.
Is there a simpler way of dealing this type of requests (managing the Prometheus alerts)? Like API or exposing the configmaps through a different channel?
2020-06-25
any pgpooler/pgbouncer implementation people recommend for kubernetes?
i had recently been looking into options for essentially doing a poor man’s canary as i don’t want to add a service mesh or yet-another ingress controller that supports weighting in front of my service. today someone pointed out https://argoproj.github.io/argo-rollouts/getting-started/ that “argo rollouts” is independent of argo cd, and that it does exactly what i want. in at least one case i have to use an alb-ingress-controller despite my distaste for alb’s, and it has nifty integration there as well, https://argoproj.github.io/argo-rollouts/features/traffic-management/alb/#aws-application-load-balancer-alb.
what are you using for ingress @joey?
aws-alb-ingress-controller … alb directly to my pods
ah - i was going to say, flagger supports nginx https://docs.flagger.app/tutorials/nginx-progressive-delivery
if it were my choice i’d be doing many things differently but i don’t pay the bills i’m just jazzed to have learned that argo-rollouts does exactly what i want in the scenario i’ve been handed.
2020-06-26
Hey, all. The k8s set-up that I inherited uses node-level AWS IAM roles. I’d like to set that up, so I can assign different roles to different applications (i.e., deployments/namespaces). Can anyone point me to some docs that will tell me just what that looks like? I’ve got the policies I need, for the most part. I’m just looking for some helm/k8s config that will apply roles at the service/namespace level. Thanks.
Check out IAM Roles for Service Accounts. I’m not sure how hard it is to implement if you’re not running EKS.
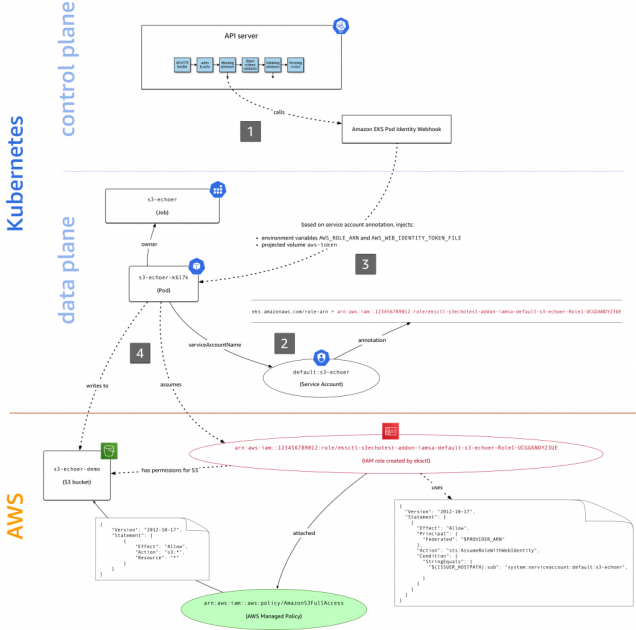
Here at AWS we focus first and foremost on customer needs. In the context of access control in Amazon EKS, you asked in issue #23 of our public container roadmap for fine-grained IAM roles in EKS. To address this need, the community came up with a number of open source solutions, such as kube2iam, kiam, […]
2020-06-27
Has anyone tried to update the kernel of a Centos7 server? The image available on AWS is 3.1 and need it to be at least 4.8 in order to use kubespray. When I tried to upgrade it to 5.6 using the ELrepo, it would not complete the status checks after reboot.
I didn’t understand the message I was seeing. The kernel requirment came from the network pluging, not kubespray. I switched to the default and the installation was fine.
2020-06-28
Hi Folks, One basic question on kubernetes Container resource allocation..what is the default CPU and memory (both request and limit) value if we dont provide any values?
I think that remains unlimited, i.e. used max what is available on node
Thanks for the reply..Assume if I brought up all defaults (quota) setup including for ns..i have only one worker node with 12 physical cpus…and 128GB RAM…is there way we can assume this is the default limit it is going to take for cpu n memory..
Reason for this question is - I see degraded performance if I go with default values but when I allocate resources I get better performance..thats y confused..
There can be a reason because there are multiple pods running on same node and each pod tries to squeeze as much as it can
maybe thats the case cos have only 3 pods but all of them have default resources..let me try to allocate for every pod running in that node..Thanks for the insight
you should always set a mem and cpu allocation for your pods IMHO, there is no predictable way I can think of to assume what the pods will consume if left unset
Got it @shamil.kashmeri that’s what I’m going to do. Set resources to each n every pod. Thanks for input.
2020-06-29
Hi guys When a container is killed, and his PV/PVC use a storageclass with Retain Policy “Delete”, usually the PV/PVC is destroyed from the cluster. I have a case where the PV and PVC resources are kept and still flagged as “Bound”. But the container is really gone. Any idea what could cause this ?
While destroying the module, the storageclass got destroyed too. Could it be because the storageclass has been removed before the PV/PVC and then there was no instruction anymore for the PVC to self-destroyed when the container got removed ? Still it should change status from Bound to Available or something like that
I don’t get why it keep it’s bound status
2020-06-30
Hi Everyone!
Please has anyone used Open Access Policy in Kubernetes for memory and cpu resource management and also to check for Readiness Probe?
https://jvns.ca/blog/2017/08/05/how-kubernetes-certificates-work/ is a fairly clear discussion of PKI certificates used by kubernetes. If you work with the CIS Benchmark, you’ll want to read this.
Today, let’s talk about Kubernetes private/public keys & certificate authorities! This blog post is about how to take your own requirements about how certificate authorities + private keys should be organized and set up your Kubernetes cluster the way you need to. The various Kubernetes components have a TON of different places where you can put in a certificate/certificate authority. When we were setting up a cluster I felt like there were like 10 billion different command line arguments for certificates and keys and certificate authorities and I didn’t understand how they all fit together.