#kubernetes (2021-02)

Archive: https://archive.sweetops.com/kubernetes/
2021-02-01
Hey everyone, does anyone know an alternative tool for k9s? I started using 1 month ago but somehow I cannot attach to containers…
I’m always with love with cli tools, but this desktop one is awesome https://k8slens.dev/

Lens IDE for Kubernetes. The only system you’ll ever need to take control of your Kubernetes clusters. It’s open source and free. Download it today!
An alternative from IBM https://kui.tools/
Kui is an open-source, graphical terminal designed for developers.
A hybrid command-line/UI development experience for cloud-native development - IBM/kui
Hi, for testing k8s on a mac do people recommend: microk8s on multipassd minikube via VirtualBox
In addition to this, if you’re learning/experimenting do you tend to try these things locally or spin up small clusters in the cloud as and when you need?
I’m currently training to do the CKA, and have been experimenting via a simple multi-node cluster in AWS. Just curious as to what people think is more useful. TIA
I don’t see a true advantage to use real nodes when just learning k8s. You can use your local environment, and when you want to step up and do some cloud integrations, move to the cloud
multipass + k3s (I can share my command)
@Issif yes please! BTW would you recommend k3s over microk8s for a newbie?
I never used microk8s but it seems simpler
I had really huge CPU consumption and slow IO with Docker 4 Mac
@Andy Docker for Mac (aka “docker-desktop”) also shares image repos, which means you can “docker build” your image and it’s immediately available on the Kubernetes side. No more push/pull! I’m working on screencasts showing editing (IaC) YAML to it being applied in < 10 sec, and the same with (application) code -> image -> update.
Good luck on the CKA! I just took the CKAD but I’ll have to take it again :)
I expect that for CKA minikube just wouldn’t cut it, so I’m working on building the clusters both manually and with kubeadm. For developers learning k8s that would probably be an overkill. Heard interesting things about k0s FWIW, but haven’t actually played with it.

Version 2.0 of the Kubernetes and Helm providers includes a more declarative authentication flow, alignment of resource behaviors and attributes with upstream APIs, normalized wait conditions across several resources, and removes support for Helm v2.
Anyone here using Linkerd w/ the new aws-load-balancer-controller? Concerned about this issue and wondering if aws-load-balancer-controller ends up throwing a huge wrench into using Linkerd or service meshes generally. Would be interested to hear if anyone is using this today and if there were any challenges in making it work.
I am not sure where exactly the responsibility of something like this would sit, but it would be great if a Linkerd integration was supported by the ALB ingress controller. Linkerd discovers servic…
2021-02-02
For those interested in the CKA, CKAD, CKS you can get a 50% discount if you register for KubeCon for $10. https://events.linuxfoundation.org/kubecon-cloudnativecon-euarope/register/

Automotive Grade Linux All Member Meeting Summer 2020 is now a virtual summit, happening July 15 – 16 due to COVID-19 safety concerns. All session times are in Central European Summer Time (CEST)…
thanks for sharing this!!
Automotive Grade Linux All Member Meeting Summer 2020 is now a virtual summit, happening July 15 – 16 due to COVID-19 safety concerns. All session times are in Central European Summer Time (CEST)…
2021-02-03
Securing Kubernetes access with Hashicorp Boundary is happening now on AWS’ Twitch//www.twitch.tv/aws>
Telepresence v2 has been released alongside with launching Ambassador Cloud. Telepresence now consists of functionality that previously was related to Service Preview.

Powered by Telepresence, Ambassador Cloud enables developers to iterate rapidly on Kubernetes microservices by arming them with infinite-scale development environments, access to instantaneous feedback loops, and highly customizable development environments.

Introducing Ambassador Cloud for fast, efficient local development on Kubernetes powered by Telepresence
Here are the changes from Service Preview https://www.getambassador.io/docs/latest/telepresence/reference/#changes-from-service-preview
How Telepresence works under the hood to help with your Kubernetes development.
2021-02-04
@roth.andy my buddy @Alex Siegman is curious about rancher - has some high-level questions for you
Mostly just having trouble cutting through the marketing on their website. Is late for me, my brain is mush, probably need to stop work for the day.
Basically, what’s the elevator pitch for rancher, and what kinds of problems is it aiming to solve?
Seems like it’s positioned for pretty large, many cluster deployment management
Rancher is actually several products, that unfortunately get mashed together too often
• The product called Rancher is a K8s management platform that gets deployed to an existing K8s cluster. It provides things like User mgmt and RBAC, the ability to provision new clusters in several different ways, and then manage the new clusters centrally from Rancher, and several other nice-to-haves
• The product called RKE is Rancher Inc’s K8s distribution. It’s “thing” is that it is very easy to use. It uses a single configuration file that is powerful without having a huge learning curve. To bring up a cluster all you need is rke up.
There are also terraform providers for both
Actually, they have 2 k8s distros, RKE and k3s
I like them because it is (IMO) the easiest way to get real centralized management of kubernetes clusters. If I am managing 10 clusters I can centrally give granular access to users/groups via either SSO or user/password management managed by Rancher.
They also have a new product coming out soon called Fleet that lets you centralize common deployments to all k8s clusters for common services like cert-manager or istio or nginx-ingress
My company is working on an open source project for an “EVTR” (Ephemeral Virtual Training Range) that uses rancher. It is composed of 4 Terraform modules.
- Rancher “master” cluster
- Rancher “worker” cluster
- “DevSecOps Sandbox” (GitLab, Jenkins, etc)
- “Sandbox Config” (configuration of the sandbox for a turn-key training env)
Complete example for standing up an Ephemeral Virtual Training Range (EVTR) on AWS - saic-oss/evtr-complete-example
Neat, I appreciate the explanation. I may try to play with EVTR just to learn a bit more about rancher.
If you use the example in module #2 it will create a master cluster, create a worker cluster, and provide everything as terraform outputs where you can play to your heart’s content!
Warnings: The project is still MVP. Lots of things that should be input variables are hard coded, and it is lax on security
2021-02-05
Anyone here accomplish Canary / B/G using the aws-load-balancer-controller?
i think i did this with argo-rollouts back in november/december but i don’t use it in prod every day
Ah interesting. Argo is on my list to investigate. Does it have a special integration with AWS ALBs/NLBs to manage Target Groups?
Ah found docs on that — https://argoproj.github.io/argo-rollouts/features/traffic-management/alb/
@joey thanks I think this helps a lot in terms of what I’m looking to do.
Because it does have a special integration with the aws-lb-controller, which is great.
2021-02-08
2021-02-09
Hi
Sorry to bother here too (I’ve asked the same into #terraform), but this time I will be a good boy and I will start a thread :wink: I’ve deployed an EKS cluster with cloudposse eks-cluster and node-groups modules. It works and deploys the cluster along the nodes but, if I run it a second time or I just run terraform refresh, it throws out an error stating Error: the server is currently unable to handle the request (get configmaps aws-auth). Everything works, I can even kubectlget pods so I really don’t know what terraform is doing to fail like that. Anyone has seen that and knows how to solve it?
This seems to be related map_additional_iam_roles and also map_additional_iam_users (tried both)
Because if I destroy the cluster, the last thing that it cannot destroy is module.eks_cluster.kubernetes_config_map.aws_auth[0] if I set kubernetes_config_map_ignore_role_changes to false, if I set it to true it’s module.eks_cluster.kubernetes_config_map.aws_auth_ignore_changes instead
Found other 3 people with the same issue, I have the feeling the solution isn’t that simple..
@nnsense I think those issues you see are b/c of some breaking changes from https://github.com/cloudposse/terraform-aws-eks-cluster/releases/tag/0.32.0
Update to support kubernetes provider v2 @woz5999 (#93) Breaking Changes This module requires kubernetes Terraform provider >= 2.0, which introduced breaking changes to the provider. This module h…
although we have an automated test and everything is working, prob in some cases it breaks
you can try to use a release before 0.32.0
until we could look into it (again, the new version is used in production and the tests pass, so it could be not an easy fix)
Hi Andriy, I’m sure it is and I’m missing something obvious :slightly_smiling_face: My concern is the use of additional groups/roles, as that part isn’t into the complete examples (actually I don’t know if the tests are based on). The questions I’ve found searching slack for aws_auth are from yesterday
I also have this issue, is there any solution for this? thanks!
I mean, I’m not sure, but it sounds the same issue
2021-02-10
2021-02-11
Hey are there any alternatives to OPA/gatekeeper, I think I remember from an office hours some mention of a better tool
There are alternatives… not necessarily better
For what specific use-case?
We would like place pods into nodes depending on what created them, specifically we want long runnings apps on one some nodes and 1 time/cron jobs on other nodes
2021-02-12

Today, we introduced user authentication for Amazon EKS clusters from an OpenID Connect (OIDC) Identity Provider (IDP). This feature allows customers to integrate an OIDC identity provider with a new or existing Amazon EKS cluster running Kubernetes version 1.16 or later. The OIDC IDP can be used as an alternative to, or along with AWS […]
2021-02-13
2021-02-15
In deploying redis in eks, would it be best practice to have a separate node group for it? (with taints and tolerations) Because it’s stateful and it needs an EBS in the same availability zone?
Hi all, I am setting up Istio and CrunchyData PostgreSQL Operator. I was wondering wether to set up the postgres cluster with an Egress or set it up withing an Istio enabled namespace. Any advice?
2021-02-16
Hi everyone! I have a deployment on K8S of a pod which can be reached over http port 9090. If I comment the liveness probe, the pod comes up fine and I can curl 9090 without issues or display the content in the browser by port-forwarding from localhost to the pod at 9090. If I add the liveness probe though, the deployment via helm fails –>
Liveness probe failed: Get <http://10.153.82.49:9090/>: dial tcp 10.153.82.49:9090: connect: connection refused
This is the config
containers:
- name: {{ .Chart.Name }}
securityContext:
{{- toYaml .Values.securityContext | nindent 12 }}
image: "{{ .Values.image.repository }}:{{ .Values.image.tag | default .Chart.AppVersion }}"
imagePullPolicy: {{ .Values.image.pullPolicy }}
ports:
- name: http
containerPort: 9090
protocol: TCP
livenessProbe:
httpGet:
path: /
port: 9090
initialDelaySeconds: 5
readinessProbe:
httpGet:
path: /
port: 9090
Would you have an idea why that fails with the probe added to the deployment?
Is this initialDelaySeconds sufficient for your case? I guess it might be not enough therefore liveness probe fails
I already increased it for both the liveness and readiness to 240 seconds but that did not help
If I comment the probes though, the deployment works and I can access the deployed http service by curling on port 9090
You can try to get inside the pod (with probes disabled) and check the time when the port is open by your app (probably the ss command will help here)
If a Container does not provide a liveness probe, the default state is Success.
https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle/
Maybe that’s the issue?
Or rather, maybe something is wrong, but that’s why it works when you comment the probe.
I have ran into similar issues in the past, apps might have a different /status or some other endpoint. Check that (if not already done)
For those who might be interested, we’re hosting a free kubernetes for beginners event (admin lmk if this is not ok!) Come hang out https://app.experiencewelcome.com/events/MQ4uzz/stages/8DzfRY?preview=true

Curious about Kubernetes but don’t know where to start? Here’s the opportunity to ask questions and learn from industry experts. Hosted by Colin Chartier: CEO & Co-founder of LayerCI Daniel Pastusek: Co-founder of Kubesail Ramiro Berrelleza: CEO & Co-founder of Okteto
KubeHelper - simplifies many daily Kubernetes cluster tasks through a web interface. Search, analysis, run commands, cron jobs, reports, filters, git synchronization and many more. - KubeHelper/kub…
Any advantages in comparison with Lens?
KubeHelper - simplifies many daily Kubernetes cluster tasks through a web interface. Search, analysis, run commands, cron jobs, reports, filters, git synchronization and many more. - KubeHelper/kub…
web based vs Desktop, did not test it yet, but I love Lens
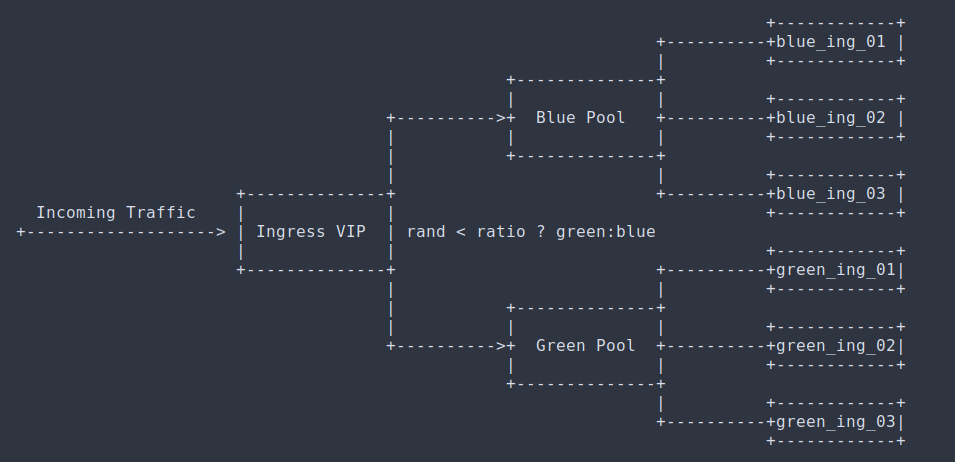
I am currently investigating the feasibility of upgrading EKS clusters using blue/green deployments rather than in-place upgrades. We use EKS but this is applicable to any kubernetes managed service. From a high level perspective the workflow would be something like:
- EKS 1.15 running some workload (green)
- Provision a new EKS 1.16 with all addons (blue)
- Switch a flag in our pipeline to deploy to blue cluster (deployed using terraform and helm, we can parameterise the cluster to deploy to)
- Migrate all workload from green to blue (using Velero or similar)
- Decommission green cluster Has anyone implemented something similar? The only relevant blog post I have fund is this one https://medium.com/makingtuenti/kubernetes-infrastructure-blue-green-deployments-fca831239c7d but dooes not give much details on the implementation. Thanks!
Upgrading Kubernetes is something that should not be taken lightly. Keeping up with the release pace is hard, there are issues fixed, new…
i’ve done something similar. most of my apps are stateless so i used route 53 weighted dns and gradually shifted traffic on my apps CNAME to the new cluster by adjusting the weighting pointing to specific cluster hostnames that are managed by external-dns
Upgrading Kubernetes is something that should not be taken lightly. Keeping up with the release pace is hard, there are issues fixed, new…
it’s about as easy as it sounds so i didn’t write an article about it
Thanks @joey. Did you first have to redeploy all applications onto the new cluster or was it a backup/restore approach? Our applications have a microservices architecture so re-deploying all application would be hard to implement
yeah, i deployed all applications to the new cluster so that i had 2 clusters running in parallel that were running the same versions of all applications
then i pushed ~10% of traffic to the new cluster by modifying DNS weighting, validated all my metrics were good, it started scaling, etc. and started shifting more traffic
Thanks!
but i generally go from whatever version i’m running -> latest stable version, e.g. i recently upgraded a couple clusters from 1.14 to eks 1.18 .. i used pluto to validate any changes that would need to be made to api references, etc
A cli tool to help discover deprecated apiVersions in Kubernetes - FairwindsOps/pluto
Nice approach, i always thought about doing this, but due to time constraints had to switch back to in-place upgrades.
Il try it this time around
What tools do you use to manage the clusters for blue/green and the workloads on-top?
Would you perform the blue/green switch via terraform, or is it rather a manual process currently?
Anyone got experience with migrating pvcs (i.e. aws ebs)?
i use helm to install the apps on top. i use terraform to change the weighting of dns records. no experience migrating pvcs.
2021-02-17
Pretty interesting OSS platform I hadn’t heard about before — https://dapr.io/
Dapr helps developers build event driven microservices on cloud and edge
2021-02-18
https://github.com/ContainerSolutions/kubernetes-examples <– this looks like a good learning resource for simple examples of k8s features
Minimal self-contained examples of standard Kubernetes features and patterns in YAML - ContainerSolutions/kubernetes-examples
that’s great
Minimal self-contained examples of standard Kubernetes features and patterns in YAML - ContainerSolutions/kubernetes-examples
i was tinkering with botkube.io tonight. it’s pretty neat and perhaps the most feature complete option i’ve seen of various options (my search was not exhaustive). once the slack app integration can be done on a per-workspace basis and doesn’t require adding the slack app from the author (is there really no good slack terraform module?) i think it becomes a lot more reasonable to propose at work.
quite often i have to go back to vendors with data that their network is broke in the form of mtr’s or tcpdumps. i think it’d be ‘relatively’ trivial to add some functionality to botkube to allow you to run a custom container in a specific zone or run a specific command in a sidecar container in a specific zone to do some more rapid troubleshooting. i use thousandeyes and datadog and prometheus for various similar things but this seems like a cool nice to have.
Looks cool. Will definitely investigate further in the future
Agreed on not having a solid Slack Terraform provider…. I looked up one the other week and of course it was unofficial and looked hacked together.
Looks real good, thanks for the post. Setting it up today, need to see how good it looks on teams
it’s pretty neat but the slack issue and lack of a slack terraform provider still gets under my skin
2021-02-19
2021-02-22
2021-02-24
has anyone successfully implemented ingress-nginx with SSL termination on AWS NLB ?
I’ve been having trouble getting the proper config right
2021-02-26

GKE Autopilot gives you a fully managed, hardened Kubernetes cluster out of the box, for true hands-free operations.
I’m wondering if there are already some solutions for disaster recovery active-active K8S clusters where traffic can be partially switched and security is as granular to a pod level. I saw this https://portworx.com/kubernetes-disaster-recovery/ but not sure. Maybe some used anything like and can share some insights

WHITEPAPER Get the Essential Capabilities of Disaster Recovery for Kubernetes ‣ The Challenge Building an enterprise grade Kubernetes platform entails more than simply deploying your applications. You need to protect them too. However, traditional DR solutions aren’t a fit for Kubernetes applications because they rely on machine-based backups and don’t speak the language of Kubernetes.learn more
Also interested in thoughts on a Portworx solution. We wanted to try it out but haven’t had time yet.
WHITEPAPER Get the Essential Capabilities of Disaster Recovery for Kubernetes ‣ The Challenge Building an enterprise grade Kubernetes platform entails more than simply deploying your applications. You need to protect them too. However, traditional DR solutions aren’t a fit for Kubernetes applications because they rely on machine-based backups and don’t speak the language of Kubernetes.learn more