#kubernetes (2022-05)

Archive: https://archive.sweetops.com/kubernetes/
2022-05-03
2022-05-04
I remember a tool that would check a cluster for usage of deprecated manifests and spit them out. I know there is pluto but I believe there to be a 2nd one but I am not sure. Anyone an idea?
@Pierre Humberdroz - you might be thinking of https://github.com/FairwindsOps/pluto
A cli tool to help discover deprecated apiVersions in Kubernetes
Kubent
2022-05-05
2022-05-09
2022-05-11
Hi there are any teams using API Gateways within their kubernetes clusters? Just curious as to what current solutions people have good experience with. Searching through the slack history here I see:
• Kong
• Ambassador Edge Stack - (looks like you have to pay for JWT use though)
• Amazon API Gateway (we use EKS)
I’m deploying Validating Webhook with the operation rule “create” (and it’s working fine) but when I’m adding “update” property - it doesn’t work. I’m getting this error: Failed to update endpoint default/webhook-server: Internal error occurred: failed calling webhook "webhook-server.default.svc": failed to call webhook: Post "<https://webhook-server.default.svc:443/validate?timeout=5s>": dial tcp ip.ip.ip.ip: connect: connection refused
Any help please?
This is my yaml files:
apiVersion: apps/v1
kind: Deployment
metadata:
name: webhook-server
namespace: default
labels:
app: webhook-server
spec:
replicas: 1
selector:
matchLabels:
app: webhook-server
template:
metadata:
labels:
app: webhook-server
spec:
containers:
- name: server
image: webhook-server
imagePullPolicy: Never
env:
- name: FAIL
value: "false"
ports:
- containerPort: 8443
name: webhook-api
volumeMounts:
- name: webhook-tls-certs
mountPath: /run/secrets/tls
readOnly: true
volumes:
- name: webhook-tls-certs
secret:
secretName: webhook-server-tls
---
apiVersion: v1
kind: Service
metadata:
name: webhook-server
namespace: default
spec:
selector:
app: webhook-server
ports:
- port: 443
targetPort: webhook-api
---
apiVersion: admissionregistration.k8s.io/v1
kind: ValidatingWebhookConfiguration
metadata:
name: demo-webhook
webhooks:
- name: webhook-server.default.svc
namespaceSelector:
matchExpressions:
- key: validate
operator: NotIn
values: [ "skip" ]
rules:
- apiGroups: [""]
apiVersions: ["v1"]
operations: ["CREATE", "UPDATE"]
resources: ["*"]
clientConfig:
service:
namespace: "default"
name: "webhook-server"
path: "/validate"
caBundle: ${CA_PEM_B64}
admissionReviewVersions: ["v1", "v1beta1"]
sideEffects: None
timeoutSeconds: 5
# failurePolicy: Ignore
2022-05-12
Hello everyone ! We’ve been facing an issue with some latency-sensitive services that we deployed to EKS and are being exposed using Nginx Ingress Controller. The issue is related with the Conntrack table (used by iptables) filling up and then it starts dropping packages. The solution to this problem is simply increasing the Kernel parameter net.ipv4.netfilter.ip_conntrack_max to a higher value, piece of cake. As we are using the EKS/AWS maintained AMI for the worker nodes, this value comes predefined with a relatively small value (our services/apps handle several thousands of reqs per sec). We’ve been exploring different ways of properly setting this value, and the most preferred way would be modifying the kube-proxy-config Config Map, which contains Conntrack specific config
conntrack:
maxPerCore: 32768
min: 131072
tcpCloseWaitTimeout: 1h0m0s
tcpEstablishedTimeout: 24h0m0s
The problem is that kube-proxy is being managed as an EKS add-on, so, if we modify this config, by, let’s say, Terraform, it will be overridden by the EKS add-on. But we don’t want to self-manage Kube Proxy, as that would slow down our fully automatic EKS upgrades that we handle with Terraform.
Any ideas or suggestions ?
2022-05-13
Hello, can somebody tell me the conceptual difference between a controller and a mutating webhook?
https://kubernetes.io/docs/concepts/architecture/controller/#controller-pattern
A controller tracks at least one Kubernetes resource type. These objects have a spec field that represents the desired state. The controller(s) for that resource are responsible for making the current state come closer to that desired state.
The controller might carry the action out itself; more commonly, in Kubernetes, a controller will send messages to the API server …
In robotics and automation, a control loop is a non-terminating loop that regulates the state of a system. Here is one example of a control loop: a thermostat in a room. When you set the temperature, that’s telling the thermostat about your desired state. The actual room temperature is the current state. The thermostat acts to bring the current state closer to the desired state, by turning equipment on or off.
Admission webhooks are HTTP callbacks that receive admission requests and do something with them. You can define two types of admission webhooks, validating admission webhook and mutating admission webhook. Mutating admission webhooks are invoked first, and can modify objects sent to the API server to enforce custom defaults. After all object modifications are complete, and after the incoming object is validated by the API server, validating admission webhooks are invoked and can reject requests to enforce custom policies.
In addition to compiled-in admission plugins, admission plugins can be developed as extensions and run as webhooks configured at runtime. This page describes how to build, configure, use, and monitor admission webhooks. What are admission webhooks? Admission webhooks are HTTP callbacks that receive admission requests and do something with them. You can define two types of admission webhooks, validating admission webhook and mutating admission webhook. Mutating admission webhooks are invoked first, and can modify objects sent to the API server to enforce custom defaults.
So…
Mutating webhooks can influence what a controller is trying to do … because it “sits” as one of the final “filters” before admission to the API server.
As far as I understand a ‘webhook’ (lets say mutating) receives events upon a resource creation/update/delete and can act upon them (by applying further modifications in the resource)
A controller on the other side is simply an application living inside kubernetes that can use the kubernetes api to create/update/delete resources too i think?
In this case why prefer one over the other?
2022-05-18
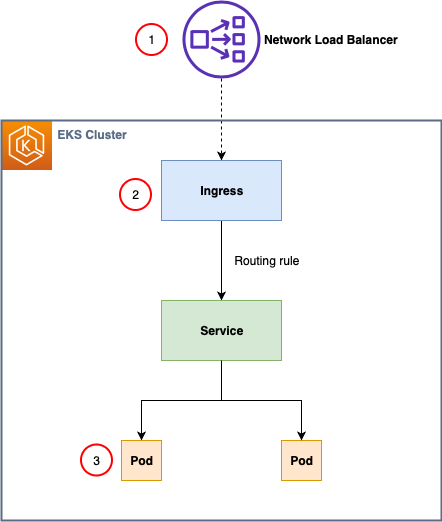
What does cloudposse use for ingress controller?
We have used ingress-nginx (open source) (and still use it for some clients) and we mostly use the aws-load-balancer controller
I didn’t know aws lb controller was an ingress controller. What do you recommend if customers need pervasive network encryption for compliance?
network encryption such as ALB + ACM ? Would that not suffice ?
I think that will terminate HTTPS on the ALB then plaintext in the private network, right?
I mean like network encryption for all node-to-node traffic too
and also ALB to node
In this blog post, I’ll show you how to set up end-to-end encryption on Amazon Elastic Kubernetes Service(Amazon EKS). End-to-end encryption in this case refers to traffic that originates from your client and terminates at an NGINX server running inside a sample app. I work with regulated customers who need to satisfy regulatory requirements like […]
you’d need at least 2 CAs, one root unshared and one subordinate shared across the org to create the certs.
Ok I see, in this approach each pod with a sidecar that terminates SSL, so basically just using HTTPS services in each app then route to them
I think it would meet compliance to just use normal ACM cert on the LB, then self-signed the rest of the way and configured ALB to trust self signed cert. since we would only care about encryption but not authentication in the case of in cluster networking
You should be able to use a custom signed cert with cert-manager to do this instead of using PCA
Shot in the dark but does anyone have experience securing API Keys with Istio directly? The AuthorizationPolicy CR does not support reading request header values from a secret. In previous implementations I have used Kong to secure the API keys downstream from Istio but would prefer not to support Kong and the additional overhead for this specific use case.
2022-05-19
@Erik Osterman (Cloud Posse), where can I find that K8S ingress controllers comparison sheet ? I opened it from one of your posts another day and I need it now, but can’t find it …

Comparison of Kubernetes Ingress controllers . Someone has painstakingly compared…
2022-05-20
What would you do if you had a requirement to redirect traffic from one app to different app based on the route existing or not existing in the first app?
• all requests always first go to the primary app
• if the primary app knows the request (non 404 http response code) it answers with a appropriate response
• if the primary app does not know the request (404) it redirects the request to a different fallback secondary app
• the solution should work across multiple clusters so even if the fallback secondary app is on another cluster the redirect/shift traffic scenario should work
My personal recommendation would be for the app/proxy to handle this logic and conditionally offer a permanent redirect to the secondary app.
This can be done in code or by having a proxy (i.e. nginx) in front of the app where you catch 404s and redirect to the secondary app.
Otherwise, if you’re just referring to path based routing and you’re aware of all the primary service routes you can define them in a K8S Ingress for the primary app and have all inexplicitly defined requests go to the secondary app?
ok. thanks for the recommendation. also to do all this behind the scenes there needs to be a proxy plus something that enables communication cross cluster?
Yes, a federated service mesh or an endpoint that was exposed to the internet or intranet on a shared network in a multi-cluster scenario
so what I would like to use is, connect the clusters via a federated service mesh as you mentioned, then I’d like to use a proxy, as you mentioned, in front of the app that catches 404 and caches that route so next time we save ourselves the app startup time. unfortunately from a half an hour research i wasn’t able to find an obvious tool that can be used to solve this. do you have some recommendations there?
Istio + a Deployment with nginx & the primary app where the service points to nginx and the nginx config redirects 404’s to the secondary app is what I had on the top of my head but there is a variety of configurations possible. Also, I don’t know your timeline but federating Istio in a production environment is not trivial
ok, thanks for the heads up
2022-05-21
2022-05-22
2022-05-23
Hey, I’m trying to install prometheus on EKS fargate but I’m getting an error from the prometheus-alertmanager & prometheus-server pods because the pvc is pending: Pod not supported on Fargate: volumes not supported: storage-volume not supported because: PVC prometheus-alertmanager not bound .
I installed the aws-ebs-csi-driver add-on on the eks and it’s still doesn’t work.
I installed everything using “AWS blueprint”
I also saw this error: 2022-05-23T13:06:04+03:00 E0523 10:06:04.065256 1 reflector.go:127] [github.com/kubernetes-csi/external-snapshotter/client/v3/informers/externalversions/factory.go:117](http://github.com/kubernetes-csi/external-snapshotter/client/v3/informers/externalversions/factory.go:117): Failed to watch *v1beta1.VolumeSnapshotClass: failed to list *v1beta1.VolumeSnapshotClass: the server could not find the requested resource (get [volumesnapshotclasses.snapshot.storage.k8s.io](http://volumesnapshotclasses.snapshot.storage.k8s.io)) from the ebs-plugin pod
Anyone knows how can I install prometheus on fargate?
Thank you!

Today, we are introducing a new open-source project called EKS Blueprints that makes it easier and faster for you to adopt Amazon Elastic Kubernetes Service (Amazon EKS). EKS Blueprints is a collection of Infrastructure as Code (IaC) modules that will help you configure and deploy consistent, batteries-included EKS clusters across accounts and regions. You can […]
EKS on Fargate only supports 2 types of storage: local ephemeral storage and EFS. You are trying to use EBS.
There is a feature request for EKS on Fargate to support EBS volumes, but that’s not supported yet.
Community Note
• Please vote on this issue by adding a reaction to the original issue to help the community and maintainers prioritize this request • Please do not leave “+1” or “me too” comments, they generate extra noise for issue followers and do not help prioritize the request • If you are interested in working on this issue or have submitted a pull request, please leave a comment
Tell us about your request
Allow mounting of at EBS volumes onto EKS pods running on fargate
Which service(s) is this request for?
EKS on fargate
Tell us about the problem you’re trying to solve. What are you trying to do, and why is it hard?
We’re looking to migrate a cluster from EC2 nodes to Fargate. There are some stateful pods using EBS which is preventing us from adopting fargate.
Are you currently working around this issue?
We are staying on standard worker nodes
You have a couple options:
• use local ephemeral storage (less than ideal considering that gets deleted when the pod is deleted)
• use EFS instead of EBS
• use EC2 workers instead of Fargate workers
• use Amazon’s Managed Prometheus service
So I’m trying to use Amazon’s Managed Prometheus service and as par as I understand I still need to install Prometheus helm chart on my cluster according to their guide. (I’m doing it through aws eks blueprint) Am I right @Vlad Ionescu (he/him)?
I am not fully up-to-date with Amazon’s Managed Prometheus so I can’t comment with certainty. Sorry!
As far as I know, you can use either Prometheus with remote_write (does that still need storage or can you eliminate the EBS requirement?) or OpenTelemetry agents to send metrics to Amazon’s Managed Prometheus but again, high chance I am wrong.
Thank you!
I will try
Has anyone had problems with multipass since upgrading to Monterey 12.4? Am frequently seeing time-outs. Managed to start VMs once since the upgrade yesterday.
multipass start k3s-sandbox start failed: The following errors occurred:
k3s-sandbox: timed out waiting for response
To anyone else who sees this issue looks like it might be related to networking https://github.com/canonical/multipass/issues/2387
Multipass crashes unexpectedly, and all instances (including primary) will not restart. I am using multipass 1.8.1+mac,
multipassd 1.8.1+mac. (multipass –version), on macOS Monterey 12.1, M1 Max, 32 GB RAM. I installed multipass for macOS directly from Canonical’s website.
start failed: The following errors occurred:
dbarn: timed out waiting for response
This has happened twice. The first time I uninstalled multipass, reinstalled, and re-built my instances thinking it was a fluke. Multipass performed fine for roughly a week, then crashed again and I lost some work. I am not able to determine what the cause is, or how to reproduce it. System restarts do not help. I’m hoping someone can spot the issue in the logs.
Logs here:
``` [2022-01-04T1356.044] [warning] [qemu-system-aarch64] [2022-01-04T1356.044] [debug] [dbarn] QMP: {“QMP”: {“version”: {“qemu”: {“micro”: 0, “minor”: 1, “major”: 6}, “package”: “”}, “capabilities”: [“oob”]}}
[2022-01-04T1356.062] [debug] [dbarn] QMP: {“return”: {}}
[2022-01-04T1308.663] [debug] [dbarn] QMP: {“timestamp”: {“seconds”: 1641321068, “microseconds”: 663550}, “event”: “NIC_RX_FILTER_CHANGED”, “data”: {“path”: “/machine/unattached/device[7]/virtio-backend”}}
[2022-01-04T1337.352] [debug] [dbarn] process working dir ‘’ [2022-01-04T1337.353] [info] [dbarn] process program ‘qemu-system-aarch64’ [2022-01-04T1337.353] [info] [dbarn] process arguments ‘-machine, virt,highmem=off, -accel, hvf, -drive, file=/Library/Application Support/com.canonical.multipass/bin/../Resources/qemu/edk2-aarch64-code.fd,if=pflash,format=raw,readonly=on, -nic, vmnet-macos,mode=shared,model=virtio-net-pci,mac=5200ff:d3, -cpu, cortex-a72, -device, virtio-scsi-pci,id=scsi0, -drive, file=/var/root/Library/Application Support/multipassd/qemu/vault/instances/dbarn/ubuntu-20.04-server-cloudimg-arm64.img,if=none,format=qcow2,discard=unmap,id=hda, -device, scsi-hd,drive=hda,bus=scsi0.0, -smp, 2, -m, 4096M, -qmp, stdio, -chardev, null,id=char0, -serial, chardev:char0, -nographic, -cdrom, /var/root/Library/Application Support/multipassd/qemu/vault/instances/dbarn/cloud-init-config.iso’ [2022-01-04T1337.353] [warning] [Qt] QProcess: Destroyed while process (“qemu-system-aarch64”) is still running. [2022-01-04T1337.370] [error] [dbarn] process error occurred Crashed program: qemu-system-aarch64; error: Process crashed [2022-01-04T1337.371] [info] [dbarn] process state changed to NotRunning [2022-01-04T1337.371] [error] [dbarn] error: program: qemu-system-aarch64; error: Process crashed [2022-01-04T1337.372] [warning] [Qt] QObject::Process, Unknown): invalid nullptr parameter [2022-01-04T1337.372] [warning] [Qt] QObject::Process, Unknown): invalid nullptr parameter [2022-01-04T1337.372] [warning] [Qt] QObject::Process, Unknown): invalid nullptr parameter [2022-01-04T1337.372] [warning] [Qt] QObject::Process, Unknown): invalid nullptr parameter [2022-01-04T1337.372] [warning] [Qt] QObject::Process, Unknown): invalid nullptr parameter [2022-01-04T1337.372] [warning] [Qt] QObject::Process, Unknown): invalid nullptr parameter [2022-01-04T1338.572] [debug] [update] Latest Multipass release available is version 1.8.0 [2022-01-04T1340.666] [info] [VMImageHost] Did not find any supported products in “appliance” [2022-01-04T1340.671] [info] [rpc] gRPC listening on unix:/var/run/multipass_socket, SSL:on [2022-01-04T1340.673] [debug] [qemu-img] [1300] started: qemu-img snapshot -l /var/root/Library/Application Support/multipassd/qemu/vault/instances/tractorgeeks/ubuntu-20.04-server-cloudimg-arm64.img [2022-01-04T1340.677] [debug] [qemu-img] [1301] started: qemu-img snapshot -l /var/root/Library/Application Support/multipassd/qemu/vault/instances/primary/ubuntu-20.04-server-cloudimg-arm64.img [2022-01-04T1340.681] [debug] [qemu-img] [1302] started: qemu-img snapshot -l /var/root/Library/Application Support/multipassd/qemu/vault/instances/dbarn/ubuntu-20.04-server-cloudimg-arm64.img [2022-01-04T1340.686] [info] [daemon] Starting Multipass 1.8.1+mac [2022-01-04T1340.686] [info] [daemon] Daemon arguments: /Library/Application Support/com.canonical.multipass/bin/multipassd –verbosity debug [2022-01-04T1316.997] [debug] [dbarn] process working dir ‘’ [2022-01-04T1316.998] [info] [dbarn] process program ‘qemu-system-aarch64’ [2022-01-04T1316.998] [info] [dbarn] process arguments ‘-machine, virt,highmem=off, -accel, hvf, -drive, file=/Library/Application Support/com.canonical.multipass/bin/../Resources/qemu/edk2-aarch64-code.fd,if=pflash,format=raw,readonly=on, -nic, vmnet-macos,mode=shared,model=virtio-net-pci,mac=5200ff:d3, -cpu, cortex-a72, -device, virtio-scsi-pci,id=scsi0, -drive, file=/var/root/Library/Application Support/multipassd/qemu/vault/instances/dbarn/ubuntu-20.04-server-cloudimg-arm64.img,if=none,format=qcow2,discard=unmap,id=hda, -device, scsi-hd,drive=hda,bus=scsi0.0, -smp, 2, -m, 4096M, -qmp, stdio, -chardev, null,id=char0, -serial, chardev:char0, -nographic, -cdrom, /var/root/Library/Application Support/multipassd/qemu/vault/instances/dbarn/cloud-init-config.iso’ [2022-01-04T1317.004] [debug] [qemu-system-aarch64] [1384] started: qemu-system-aarch64 -machine virt,highmem=off -nographic -dump-vmstate /private/var/folders/zz/zyxvpxvq6csfxvn_n0000000000000/T/multipassd.pRWjeY [2022-01-04T1317.061] [info] [dbarn] process state changed to Starting [2022-01-04T1317.063] [info] [dbarn] process state changed to Running [2022-01-04T1317.063] [debug] [qemu-system-aarch64] [1385] started: qemu-system-aarch64 -machine virt,highmem=off -accel hvf -drive file=/Library/Application Support/com.canonical.multipass/bin/../Resources/qemu/edk2-aarch64-code.fd,if=pflash,format=raw,readonly=on -nic vmnet-macos,mode=shared,model=virtio-net-pci,mac=5200ff:d3 -cpu cortex-a72 -device virtio-scsi-pci,id=scsi0 -drive file=/var/root/Library/Application Support/multipassd/qemu/vault/instances/dbarn/ubuntu-20.04-server-cloudimg-arm64.img,if=none,format=qcow2,discard=unmap,id=hda -device scsi-hd,drive=hda,bus=scsi0.0 -smp 2 -m 4096M -qmp stdio -chardev null,id=char0 -serial chardev:char0 -nographic -cdrom /var/root/Library/Application Support/multipassd/qemu/vault/instances/dbarn/cloud-init-config.iso [2022-01-04T1317.063] [info] [dbarn] process started [2022-01-04T1317.063] [debug] [dbarn] Waiting for SSH to be up [2022-01-04T1317.347] [warning] [dbarn] qemu-system-aarch64: -nic vmnet-macos,mode=shared,model=virtio-net-pci,mac=5200ff info: Started vmnet interface with configuration: qemu-system-aarch64: -nic vmnet-macos,mode=shared,model=virtio-net-pci,mac=5200ff info: MTU: 1500 qemu-system-aarch64: -nic vmnet-macos,mode=shared,model=virtio-net-pci,mac=5200ff info: Max packet size: 1514 qemu-system-aarch64: -nic vmnet-macos,mode=shared,model=virtio-net-pci,mac=5200ff info: MAC: de9b58:c4 qemu-system-aarch64: -nic vmnet-macos,mode=shared,model=virtio-net-pci,mac=5200ff info: DHCP IPv4 start: 192.168.64.1 qemu-system-aarch64: -nic vmnet-macos,mode=shared,model=virtio-net-pci,mac=5200ff info: DHCP IPv4 end: 192.168.64.254 qemu-system-aarch64: -nic vmnet-macos,mode=shared,model=virtio-net-pci,mac=5200ff info: IPv4 subnet mask: 255.255.255.0 qemu-system-aarch64: -nic vmnet-macos,mode=shared,model=virtio-net-pci,mac=5200ff info: UUID: 9736AE0D-0FAE-4223-847E-517E35533FEA
[2022-01-04T1317.348] [warning] [qemu-system-aarch64] [2022-01-04T1317.351] [debug] [dbarn] QMP: {“QMP”: {“version”: {“qemu”: {“micro”: 0, “minor”: 1, “major”: 6}, “package”: “”}, “capabilities”: [“oob”]}}
[2022-01-04T1317.399] [debug] [dbarn…
2022-05-25
Hi there Me and @Nimesh Amin are trying to upgrade the kube-prometheus-stack to use AWS Managed Prometheus service and are facing an issue where we cant seem to figure out how to enable the Sigv4 on the grafana deployed by the kube-prometheus-stack chart.
More on this issue https://github.com/prometheus-community/helm-charts/issues/2092
TLDR; how to enable sigv4 auth in grafana.ini for kube-prometheus-stack helm chart.
Is your feature request related to a problem ?
We have configured the prometheus to remoteWrite to the AWS Managed Prometheus service endpoint, however there is no option in the Grafana deployed with kube-prometheus-stack to enable the “Sigv4” auth on the prometheus datasource —this is needed to configure the AWS Managed Prometheus query endpoint as datasource and use the Sigv4 to assume the ServiceAccount IAM Role permissions.
Please advise if you have been able to solve this issue.
Describe the solution you’d like.
Settings / values to enable the sigv4 auth for grafana
Describe alternatives you’ve considered.
Deploy the https://github.com/grafana/helm-charts in a new namespace as the default installation allows to use “Sigv4” auth for the prometheus datasource.
Additional context.
No response
Sorry for the late reply and this is not really an answer - just saying these kinds of issues are why we ended up abandonining kube-prometheus. Just so much over head to do the upgrades. We started using it when it was an open source project at Ticket Master, then it moved to CoreOS, then it moved to “charts official” helm/charts, then that was deprecated, then we started using the bitnami version, then we said NEVER AGAIN.
Is your feature request related to a problem ?
We have configured the prometheus to remoteWrite to the AWS Managed Prometheus service endpoint, however there is no option in the Grafana deployed with kube-prometheus-stack to enable the “Sigv4” auth on the prometheus datasource —this is needed to configure the AWS Managed Prometheus query endpoint as datasource and use the Sigv4 to assume the ServiceAccount IAM Role permissions.
Please advise if you have been able to solve this issue.
Describe the solution you’d like.
Settings / values to enable the sigv4 auth for grafana
Describe alternatives you’ve considered.
Deploy the https://github.com/grafana/helm-charts in a new namespace as the default installation allows to use “Sigv4” auth for the prometheus datasource.
Additional context.
No response
All good Erik - We have figured out the right config that works on EKS with sigv4 -its a YAML jungle out there. :)
https://github.com/prometheus-community/helm-charts/issues/2092#issuecomment-1140332174
Here is the configuration that worked for us .
Thank you for your response.
We figured the following settings worked for us .
grafana:
serviceAccount:
create: false
name: iamproxy-service-account
grafana.ini:
auth:
sigv4_auth_enabled: true
additionalDataSources:
- name: prometheus-amp
editable: true
jsonData:
sigV4Auth: true
sigV4Region: us-west-2
type: prometheus
isDefault: true
url: <https://aps-workspaces.us-west-2.amazonaws.com/workspaces/<ID>>
serviceAccount:
create: false
name: iamproxy-service-account
prometheusSpec:
remoteWrite:
- url: <https://aps-workspaces.us-west-2.amazonaws.com/workspaces/<ID>/api/v1/remote_write>
prometheus:
sigv4:
region: us-west-2