#kubernetes (2023-07)

Archive: https://archive.sweetops.com/kubernetes/
2023-07-03
When i try to deploy a statefulset application on GKE(created by Autopilot mode) using cloudshell, its throwing the below error, can someone help me to fix this?
Error from server (GKE Warden constraints violations): error when creating "envs/local-env/": admission webhook "warden-validating.common-webhooks.networking.gke.io" denied the request: GKE Warden rejected the request because it violates one or more constraints.
Violations details: {"[denied by autogke-disallow-privilege]":["container increase-the-vm-max-map-count is privileged; not allowed in Autopilot"]}
Requested by user: 'dhamodharan', groups: 'system:authenticated'.
need to disable Autopilot mode if privileged is required
is it possible to disable the autopilot mode?? or do i need to delete this cluster and recreate with standard mode??
You want to customize the node system configuration, such as by setting Linux sysctls.
When to use Standard instead of Autopilot
I have Standard GKE cluster and want to migrate all my running services to new Autopilot cluster. I research official documentation and don’t find anything how I can perform this migration
didn’t find the exact words mentioning no conversion though
2023-07-04
Hi a cluster-autoscaler question. We appear to have a discrepancy between:
• Resource metrics reported in AWS console (see example with CPU=~50%)
• Resource metrics reported by cluster-autoscaler (they often appear to be bigger than the ones in AWS console) e.g. CPU~80% I’ve attached screenshots of each for the same EC2 instance
So it looks as though the cluster-autoscaler is getting incorrect information. Has anyone seen this issue before?
If I hit the metrics server directly:
k get --raw /apis/metrics.k8s.io/v1beta1/nodes/ip-10-48-37-79.eu-west-1.compute.internal | jq '.usage'
{
"cpu": "1854732210n",
"memory": "2290572Ki"
}
This is an amd64 c5.xlarge SPOT instance with 4 vCPU
usage_nano=1854732210
capacity_milli=4000
usage_percentage=$(awk "BEGIN { print (($usage_nano / ($capacity_milli * 1000000)) * 100) }")
echo $usage_percentage
46.3683
they should be using the same metric, what is the value at 15:10 for instance?
Ah someone in the Kubernetes slack had this explanation:
cluster-autoscaler is looking at the amount of cpu requests vs node allocatable
This isn’t the amount of cpu time used, it’s the amount of cpu reserved by Pods
e.g. if you have a pod that has a cpu request of 3, and then it does nothing but sleep, cluster-autoscaler will see the node as 75% used, aws will see it as 0%
You can’t scale it down, because that Pod still needs to go somewhere that can satisfy the reservation
got it, differences between request and limit Thanks for sharing the details
Is there GPU being used in the instances?
If there is no GPU, from the codes, the utilization of Daemonsets and MirrorPods are counted by Autoscaler
How did you deploy autoscaler? Both utilizations of Daemonsets and MirrorPods can be disabled by --ignore-daemonsets-utilization and --ignore-mirror-pods-utilization
Then it should have the similar metrics as instance
2023-07-05
2023-07-09
hello all, What backup solution do you use for k8s ? Currently we use velero. Anybody who uses stash, Trilio, Kasten ? How expensive are they ? Are they better than velero ?
2023-07-10
https://medium.com/@xpf6677/gitops-with-kcl-programming-language-cb910230e310 Hi forks  ! I wrote a blog about GitOps + KCL Integration and and would love to hear your feedback!
! I wrote a blog about GitOps + KCL Integration and and would love to hear your feedback!
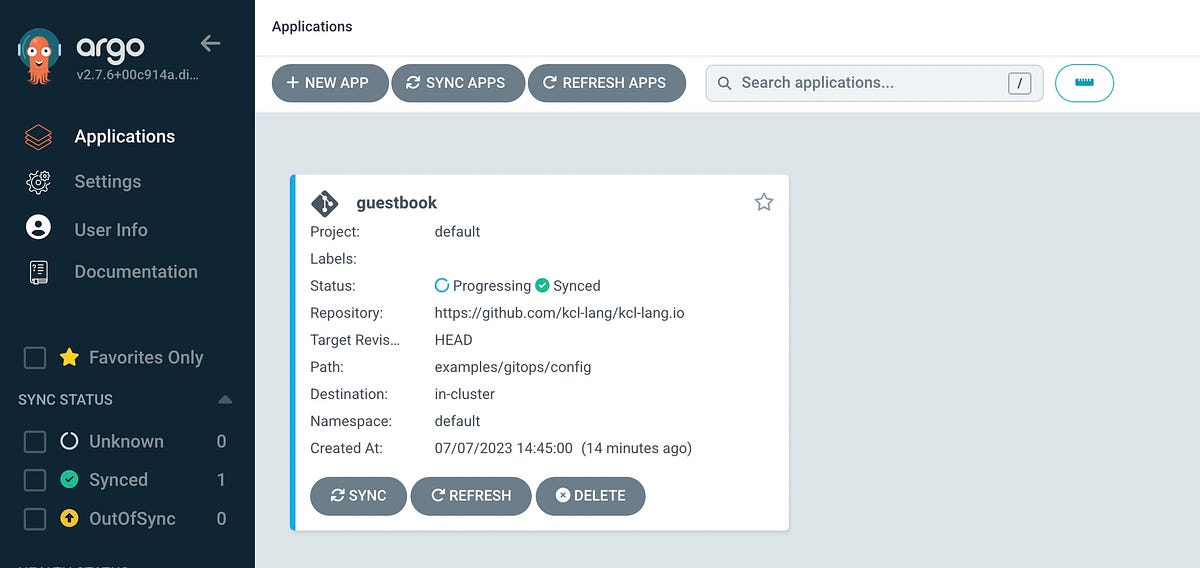
Thanks for the blog, inspiring
This comparison is interesting, https://kcl-lang.io/docs/user_docs/getting-started/intro/
What is KCL?
oh more interesting is why AntGroup invests into DevOps toolings lol
The quality of KCL’s codes and documents look good, and I’ve got some ideas of how it is used now
We are facing some challenges in cloud-native internally, so we have opened up our internal IaC and GitOps practices, Kusion and KCL, hoping to explore and solve common problems with the community. Nice to communicate with you.
How does KCL compare to something like Cuelang?
Hi @kallan.gerard Here are some blogs to explain it . https://kcl-lang.io/blog/2022-declarative-config-overview https://kcl-lang.io/docs/user_docs/getting-started/intro
The blog is only used to clarify the landscape of declarative configuration, KCL core concept and features, as well as the comparison with other configuration languages.
What is KCL?
2023-07-11
2023-07-16
Hi all. KCL v0.5.0 is out! See here for release note and more information. https://kcl-lang.io/
- Use KCL language and IDE with more complete features and fewer errors to improve code writing experience and efficiency.
- Use KPM, KCL OpenAPI, OCI Registry and other tools to directly use and share your cloud native domain models, reducing learning and hands-on costs.
- Using community tools such as Github Action, ArgoCD, and Kubectl KCL plugins to integrate and extend support to improve automation efficiency.
KCL is an open-source constraint-based record & functional language mainly used in configuration and policy scenarios.
2023-07-17
has anyone in tried template controller with fluxcd? https://medium.com/kluctl/introducing-the-template-controller-and-building-gitops-preview-environments-2cce4041406a
I’m super interested in trying to make ephemeral preview environments and this approach looks pretty slick
2023-07-18
Hi all. I was wondering, how are you autoscaling pods (workers) that consume SQS messages? How stable is the autoscaling? Are you happy with it?
It depends
I’d avoid thinking of this as strictly an SQS and Kubernetes problem. Queues with n workers are quite a common pattern and they’re part of a system as a whole
What’s producing the messages, what’s the queue size, whats the ordering, what is consuming messages and what is that thing doing with those messages, what is an acceptable amount of time for a message to remain in the queue, are the messages many aggregates with small lifecycles or few aggregates with long lifecycles, etc etc etc
I’d probably just start with one and see what happens
Thanks for the input. Are you scaling workers up and down? If so, based on what? Do you have an example (or two)?
In one example I can think of we use a custom metric with HPA which is based off the age of the oldest unacknowledged message in the queue
It’s a rough metric but it means if the ingesting workers start being overloaded, there will be more messages in the queue than what they can process, which means the message at the back of the queue will get older, which will cause another pod to be scheduled, which will help process messages faster,
But you’ll have to do the engineering for your particular requirements. Like I said these aren’t really kubernetes problems, these are application architecture problems. Don’t mix the two.
Well, I wouldn’t say I’m mixing something here Kubernetes is the tool doing the actual scaling based on metrics we provide. There is also pretty extensive documentation for the HPA like algorithms, scaling behaviour etc. so I’d say it’s definitely part of it of course you should also consider application requirements if there are any other than “please process my messages the fastest way possible”. Interesting metric for scaling. Thanks in any case.
Yes HPA would be whats being used, but Kubernetes is an implementation detail. This is a problem that’s at the application architectural level. Yes there needs to be feedback about what’s actually feasible and sensible with Kubernetes but it’s not what drives the decision.
It’s like deciding how much cereal you need to stow on a ship based on the size of the packets the cereal company sells.
There’s about a dozen questions that need to be decided first that have nothing to do with cereal boxes
2023-07-19
Looking to see if anyone has come across a “config” or other type setup that will mark an ec2 as unhealthy. Reason being when using self managed node groups as part of our patching policy we need to build new AMIs and perform instance refresh in AWS. After hearing what happened to datadog i’m hoping there’s a more sane approach to having the ASG back out of an instance refresh if the nodes aren’t able to register with the cluster and start taking pods.
So ideally i’m looking for a health check that the ASG will understand and then ideally issueing an instance refresh with rollback so if something goes wrong it backs out to the safe launch template (and the older AMI).
2023-07-20
2023-07-22
Hey folks - seeing some weird behavior within an EKS cluster that started happening recently. It involves not being able to properly attach cluster role/service account/cluster role binding stuff to our Ambassador pods so they can call the cluster API and start up properly. (This is in an older v1.21 cluster) This has worked fine for over a year and now any new pods brought in fail the same way and go into backoff. I wrote up the issue here, wondering if anyone else has seen similar behavior or has any idea a workaround or way to remedy it? If we lose the current pods in service or they get rescheduled I am worried all of our Ambassador ingresses will become unavailable. (We are in the middle of an upgrade to 1.24 but in the process of building that cluster in the background.)
Thanks!
Kubernetes discussion, news, support, and link sharing.
I’ve been able to resolve this by adding fsGroup: 1337 to the securityContext as described in this article under “Check the pod and user group”. Even though we aren’t using IRSA on this cluster, and even though we are definitely past 1.19 (on 1.21) it seems to fix if I edit the deployment and put that value in there, in case anyone else is in the same boat!
My pods can’t use the AWS Identity and Access Management (IAM) role permissions with the Amazon Elastic Kubernetes Service (Amazon EKS) account token.
2023-07-25
Hi all. Is there a way to find out which feature gates are enabled on EKS clusters?
AFAI was able to see, feature gates are not configurable with EKS. But I was wondering how to find out which of them are enabled. I found this in the docs
“The feature gates that control new features for both new and existing API operations are enabled by default.”
Does that mean that we can assume all features gates that control new features are enabled? I know I just repeated what it says but maybe someone can confirm or correct it.