#kubernetes (2024-02)

Archive: https://archive.sweetops.com/kubernetes/
2024-02-02
Quick question; I am implementing EKS and some applications (aws-lb controller, some apps, cert-manager). In order to support mTLS, do I need to use a service mesh? I am still trying to understand the service mesh, but is it absolutely necessary to use one to have mTLS communication between pods?
It depends. If the requirement is mTLS, then you’ll need another layer, such as a a mesh. However, sometimes mTLS is used to mean “end to end” TLS, which is not really the same thing. If the requirement is just to provide e2e TLS, then it can be a simple TLS sidecar terminating TLS on the pod. The sidecar can use certs generated from cert-manager, and you can still use the ALB, etc.
(mTLS is where both the client and server authenticate each other using digital certificates.)
also a good question for #office-hours
Thank you for the response. What does a TLS sidecar terminating TLS on the pod look like?
You can just run nginx (or similar) as a sidecar container. This is the gist of it. https://eric-price.net/posts/2023-12-22-nginx-sidecar/
If you’re not ready for a service mesh like Istio, Cillium or Nginx’s own service mesh, an easy way to implement end-to-end encryption from the application LB to your pod or TLS/SSL termination for your pods behind a network LB is a proxy sidecar using Nginx. I’m going to describe how to set this up using cert-manager to fetch a letsencrypt certificate and mount that to the Nginx base image.
Recommend having your service listen on 127.0.0.1:8080 (or similar), and the only exposed port being the nginx sidecar. Since it’s a sidecar, it can talk over localhost to 8080.
If you’re using a helm chart, just embed this into the templates, that way multiple apps can use the same pattern. That’s assuming you use what we call the “monochart” pattern for apps.
monochart being a “helm umbrella” of sorts?
like instead of deploying aws-lb-controller, cert-manager, and the application via individual helm charts, using a helm umbrella chart to do them all?
yes/no. Of course, use vendor-maintained charts if/when available. But if you’re developing services at your corp, consider whether each service truly needs it’s own dedicated chart with 98% boilerplate, or if a generic chart for your organization would suffice. This way, charts become like an interface for deploying new services, and you don’t have an explosion of architectures for k8s.
Ah gotcha. Understood. I will also look into terminating TLS at the sidecar nginx. I need to see if there’s any limitations with Fargate by using this.
2024-02-05
2024-02-08
Hi y’all. In a meeting with @Erik Osterman (Cloud Posse), he mentioned that running Karpenter controllers on Fargate was problematic, but we did not have time to find out why. It’s working for us so far, and seems to be a recommendation in the AWS EKS Best Practices documentation as well. Does anyone have any related experience they can share?
@Jeremy G (Cloud Posse) @Jonathan Eunice
Running Karpenter on Fargate is not in itself a problem, but it leads to problematic cluster configurations in the end. I will elaborate below.
One of the other major lessons learned was also related to CoreDNS as configured out-of-the-box on EKS, if I recall correctly.
We (3Play Media) are running 5 EKS clusters with this configuration (Karpenter on Fargate nodes, as of today 0.31.3 but have run back to 0.2x days). It is working well for us. No real problems encountered across multiple EKS versions. On cluster upgrade, you sometimes have to rollout restart Karpenter a few times before it “catches” the new version (race condition?), but that takes 5 mins maybe. We are considering moving Karpenter to Managed Node Group nodes in some clusters where we run MNGs, just to reduce the number of nodes and the corresponding Datadog monitoring costs. But that is optional and a slight optimization. At present I am unmotivated to prioritize any change away from the Karpenter on Fargate strategy.
The CoreDNS settings/configuration for EKS is in my opinion almost criminally bad. Truly, truly suboptimal. Not good for performance, for latency, and worst of all, not well-configured for high availability. It is, of all the things we buy from AWS, one of the few that makes me question “Does AWS know what it’s doing??”
But, with a few customizations tucked into our Terraform, it’s running fine for us (on normal EC2 nodes, not Fargate).
It was a big debugging project and “OMG why did they do this??” some months back; but once we resolved, no further issues. We’d be happy to share our CoreDNS settings if you’d like.
Thanks for your experience, @Jonathan Eunice. I’d definitely be interested in your CoreDNS setup. We’re running CoreDNS (as a cluster add-on) on Fargate as well. Aside from the annoying compute-type patching stuff, we haven’t noticed anything amiss. CC @E-Love
Update: Karpenter, as of the v1beta migration in v0.33.0, by default deploys the Karpenter controller to an EKS Managed Node Group and recommends deploying the controller into the kube-system namespace.
Original message: I believe the idea of running Karpenter on Fargate was put forward by the Karpenter team because: • They were proud of their accomplishment and wanted to show it off • If you don’t run Karpenter on Fargate, then you have to deploy some nodes some other way, which makes using Karpenter a lot more complicated and the benefits less obvious • In particular, for people setting up an EKS cluster without the help of Terraform and modules like Cloud Posse supplies, creating a managed node pool is a lot of work that can be avoided if you use Karpenter on Fargate • Karpenter’s ability to interact with managed node pools was limited to non-existent when it first launched Karpenter works well with managed node pools now, and the complications of setting up a node pool are greatly mitigated by using Cloud Posse’s Terraform modules and components. So the above motivations are not that powerful.
Our evolution of the decision against running Karpenter on Fargate went like this:
• If you do not run at least one node pool outside of Karpenter, then you cannot create, via Terraform, an EKS cluster with certain EKS-managed add-ons, such as Core DNS, because they require nodes to be running before they will report they are active. Terraform will wait for the add-ons to be active before declaring the cluster completely created, so the whole cluster creation fails. • To support high availability, Cloud Posse and AWS recommend running nodes in 3 separate availability zones. Implied in this recommendation is that any cluster-critical services should be deployed to 3 separate nodes in the 3 separate availability zones. This includes EKS add-ons like Core DNS and EBS CSI driver (controller). • Last time I checked (and this may have been fixed by now), if you specified 3 replicas of an add-on, Karpenter was not sufficiently motivated by the anti-affinity of the add-ons to create 3 nodes, one in each AZ. It just creates 1 node big enough to handle 3 replicas. What is worse, anti-affinity is only considered during scheduling, so once you have all 3 replicas on 1 node, they stay there, even as your cluster grows to dozens of nodes. Your HA and even your basic scalability (due to network bandwidth constraints on the node and cross-AZ traffic) are undermined because Karpenter put all your replicas on 1 node So to get around all of the above, we recommend deploying EKS with a normal managed node pool with 3 node groups (one per AZ). This allows the add-ons to deploy and initialize during cluster creation (satisfying Terraform that the cluster was properly created), and also ensures that the add-ons are deployed to different nodes in different AZs. (While you are at it, you can set up these nodes to provide some floor on available compute resources that ensure all your HA replicas have 3 nodes to run on at all times.) You do not need to use auto-scaling on this node pool, just one node in each AZ, refreshed occasionally.
There is another advantage: you can now have Karpenter provision only Spot instances, and run the managed node pool with On Demand or Reserved instances. This gives you a stable platform for your HA resources and the price savings of Spot instances elsewhere in a relatively simple configuration.
Now that you have a basic node pool to support HA, you can run Karpenter on that node pool, without the risk that Karpenter will kill the node it is running on. Karpenter now (it didn’t for a long time) properly includes the capacity available in the managed node pool when calculating cluster capacity and scaling the nodes it manages, and can scale to zero if the managed node pool is sufficient.
(The caveat here is that we are focusing on clusters that are in constant use and where paying a small premium for extra reliability is worth it. For a cluster where you don’t care if it crashes or hangs, the argument for having 3 static nodes is less compelling.)
Regarding costs, Fargate has a premium in both cost per vCPU and GiB of RAM, and in the quantization of requests. If you are concerned about the cost of running the static node pool, especially for non-production clusters, you can run t3 instances, and/or run 2 instead of 3 nodes.
Pricing comparison in us-west-2 : A c6a.large, which is what we recommend as a default for the static node pool in a production cluster, has 2 vCPUs and 4 GiB of memory, and costs $0.0765 per hour. A Fargate pod requesting 2 vCPUs and 4 GiB would cost $0.09874 per hour. A minimal pod (which is sufficient to run Karpenter) costs $0.0123425 per hour (1/8 the cost of the larger Fargate pod, about 1/6 the cost of the c6a.large, a little more than the cost of a t3.micro with 2 vCPUs and 1 GiB memory). If you have workloads that can run on Gravitron (all the Kubernetes infrastructure does) then you can use the relatively cheaper c6g or c7g mediums at around $0.035 per hour, or $25/month.
So our recommendation is to run a minimal managed node pool and run Karpenter on it. The exception might be for a tiny unimportant cluster where a baseline cost of $120/month is unacceptably high.

This section describes some of the unique Pod configuration details for running Kubernetes Pods on AWS Fargate.
That’s an impressive design argument @Jeremy G (Cloud Posse)! Much appreciated! We started before MNGs were realistic, so our structure reflects “MNGs aren’t available, how else can we make this work?” If we were starting now, we’d probably go an MNG route and nix Fargate. It isn’t a super-priority for us to change, but we might evolve there even as it is, even with Fargate working fine for us.
In the clusters that we care about (prod first and foremost, but dev and automation as well), we haven’t seen much trouble with Karpenter allocating a nice spread across AZs. If we needed to guarantee all three AZs, we’d probably need MNG, but Karpenter seems stochastically to get there on its own given sufficient load. (That Karpenter doesn’t have any “at a minimum” configs like “at a minimum, use 3 AZs” or “by default leave X ‘headroom’ for new pods to consume” is one of our complaints / feature requests / hopes for the future.)
Karpenter will try to keep a nice balance across AZs, but at cluster creation time, it’s only going to create 1 node. That leads to all your add-on replicas being run on the same 1 node, and since they are cluster critical, they do not get killed and moved to other nodes as the cluster grows. You can be stuck with this non-HA setup for a very long time.
We configure a PodDisruptionBudget and topologySpreadConstraints per-cluster. The tPC in particular seems to pretty strongly encourage multi-AZ spread. But primordial spinup / cluster creation time, might not be enough and even after that doesn’t seem a strict guarantee, so anyone needing that needs the stricter MNG approach for assured AZ distribution.
"topologySpreadConstraints": [
{
"maxSkew": 1,
"topologyKey": "topology.kubernetes.io/zone",
"whenUnsatisfiable": "DoNotSchedule",
"labelSelector": {
"matchExpressions": [{"key": "k8s-app", "operator": "In", "values": ["kube-dns"]}]
}
},
{
"maxSkew": 2,
"topologyKey": "kubernetes.io/hostname",
"whenUnsatisfiable": "ScheduleAnyway",
"labelSelector": {
"matchExpressions": [{"key": "k8s-app","operator": "In","values": ["kube-dns"]}]
}
}
]
Those are some very detailed explanations, and I appreciate it. We’ve struggled with some of the same things - for instance, the difficulty in spinning up a functional EKS cluster in one shot via Terraform. The HA considerations are also pretty compelling. Thank you both for filling me in!
@Corky Do you use Atmos workflows? Not sure we’re at the point where we can “spin up a whole AWS account” or “spin up an entire EKS cluster,” soup to nuts, with one command—but we’re closing on it. We can do large swaths of the setup in single workflow commands. Major time/effort/worry saver.
My colleague and I were recently made aware of Atmos and are considering it. I watched the live demo and did some reading the other day, and it seems like it may be able to alleviate some pain for us. Config management is a huge PITA right now, with multiple Terraform projects all with their own tfvars and we’re doing very rudimentary sharing of outputs via remote state sharing. The one thing that’s a bigger pain at the moment, however, is spiraling AWS costs - hence the questions on Karpenter, which we’ve deployed to the cluster with our internal tooling but not yet to production clusters.
Yeah, managing AWS costs is a bear. Tags and Cost Explorer are your friends there, but it’s a constant fight, keeping the node counts modest, container images as thin as possible, as little on EFS as possible, the NAT Gateways few & with as little traffic as possible, etc. etc. Did not realize I was signing up for my PhD in AWScostology, but here we are, part way through my dissertation.
so that you have a voting majority if one node crashes Karpenter doesn’t use voting. Leader election uses kubernetes leases, which implement simple locking. There is no technical requirement to have more than 2 pods, unless you have more strict HA requirements.
2024-02-09
Thought this might be relevant here as well
Anyone else get bitten by the new charge for all public IPv4 IPs as of Feb 1? Turns out running a SaaS with a single tenant architecture on EKS (one namespace per customer) with the AWS LB controller (without using IngressGroups) is a recipe for a ton of public IPs (number of AZs times number of ALBs).
2024-02-13
Hi, anyone here have experience with deploying Apache Ranger in Production (on EC2 or EKS)? All the references I find online seem more related to dev env.
2024-02-16
hello everyone!
i just wanted to share kftray, an open-source project for kubernetes users. it’s a cross-platform menu bar app that simplifies managing multiple kubectl port forwards. also, i was super happy to see kftray mentioned during the DevOps “Office Hours” (2024-01-10).
since that episode, i’ve made some significant bug fixes and added new features!
check it out, and any feedback or contributions are more than welcome! here are some links about the project:
i hope you find it useful!
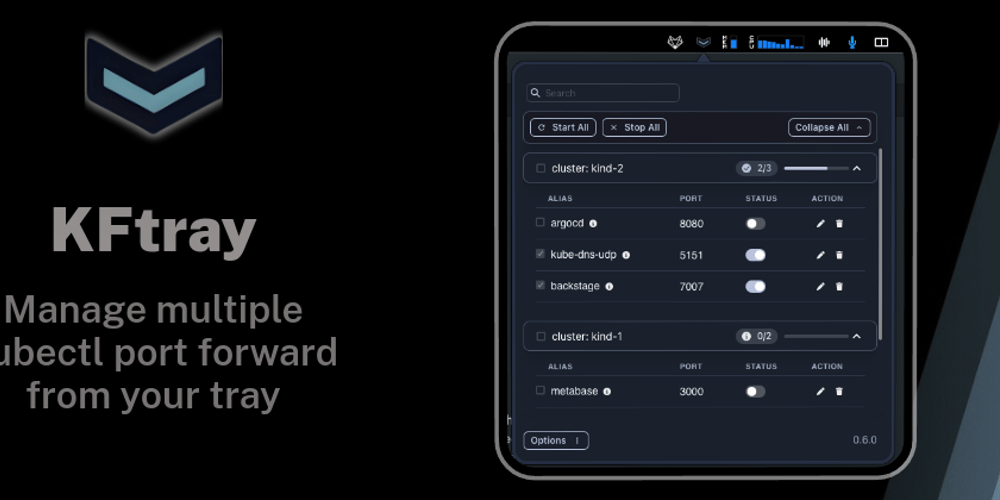
KFtray, the new open-source for Kubernetes users. It simplifies managing your kubectl port…

Saw this on Reddit. Any updates on GitHub codespaces support? :)
KFtray, the new open-source for Kubernetes users. It simplifies managing your kubectl port…
hey!
sure thing, checked it out the last few days and honestly have no clue where to start
but one thing i noticed: kftray is built with tauri (rust and typescript) and doesn’t have native codespace plugin support, so looks like we’d need to start from scratch to get something like that
but ill look more into it and let u know 
2024-02-21
has anyone implemented a service mesh (any recommendations) to support authn/authz for oauth2 tokens that supports custom scopes? was looking at istio but fairly new to this. did not want to implement something like aws cognito+api gateway to support this. wanted to see if it was feasible to do this all within kubernetes. thanks!
Did this with istio. It puts the jwt claims into http headers so then you can use them in the routing decision config by inspecting the headers and denying or allowing a route based on the value of the header. We also didn’t use istio as a service mesh but instead used it as a control plane for envoy, i.e. we configured istio to act as an ingress controller only
Ah thank you for that information. I would like to try this, do you know any public projects that have implemented something like this?
No. I followed the istio docs to get it done. First get it deployed and acting as an ingress controller. Next enable jwt validation - https://istio.io/latest/docs/tasks/security/authorization/authz-jwt/.
Shows how to set up access control for JWT token.
This is necessary as without it istio will not process the jwt and put it in the headers
After that you should get access to the jwt claims in the header. https://istio.io/latest/docs/tasks/security/authentication/jwt-route/
Shows you how to use Istio authentication policy to route requests based on JWT claims.
2024-02-22
AWS is aware of the recent announcement from Weaveworks about shutting down commercial operations. In addition to their significant contributions to the the CNCF and open source, Weaveworks has been a great partner to EKS and we are continuously grateful to Weaveworks for their leadership and development of the eksctl project.
In 2019, AWS and Weaveworks formed a partnership to designate the open-source eksctl CLI tool as the officially supported CLI for Amazon EKS, driven by significant customer demand and the tool’s capability to streamline and automate numerous EKS cluster management tasks. Since then, EKS as a service has evolved, implementing features that closed some of those early automation gaps. eksctl has always stayed a step ahead, adding usability enhancements before similar features are built into EKS service APIs.
Last year, AWS and Weaveworks announced a renewed partnership to co-develop eksctl. As part of that announcement, the eksctl project was moved under the shared /eksctl-io GitHub organization, and AWS engineers were added as project maintainers. Moving forward, AWS will take over full responsibility and ownership of the eksctl. We plan to continue development to meet the needs of customers with continued frequent eksctl releases. We are fully committed to the ongoing development and maintenance of eksctl. Later in 2024, we will move the eksctl project repo to the /aws GitHub organization. We will leave this issue open in case of any questions, comments, or concerns.
2024-02-27
@Jeremy G (Cloud Posse) could you reopen https://github.com/kubernetes-sigs/aws-efs-csi-driver/issues/1100 please?
Reopened
Thanks!
2024-02-28
Dropped in on the Bottlerocket community meeting today. Main topic was their deprecation of metal nodes. In Q&A I asked about my pet desire, container motion a la vMotion or CRIU. Expected to get a “not our gig” brush-off, but they were surprisingly open. They’re actively considering some quasi-related hot kernel update/patching work, and they immediately understood my frustration with Karpenter scheduling and the stranding of long-running workloads. They requested I post an issue in their GitHub for more visibility, which I did. Still a long-shot, but appreciated their receptiveness.
Just curious, does karpenter skip the node entirely or does it wait until the job completes (ex. 12 hours) ?
Karpenter waits until workload on a node completes, up to a settable maximum. We were running as long as 24h max wait for a job to complete.