#kubernetes (2024-05)

Archive: https://archive.sweetops.com/kubernetes/
2024-05-01
2024-05-03

Due to a combination of issues with GKE and Linkerd, I ended up deleting my load balancer routes when I removed the Linkerd helm chart.
2024-05-07
Is there a way to run a “virtual load balancer” inside kubernetes so one would not have to manage a cloud-native load balancer (ALB: aws, whatever gcp or azure has)?
There are a few options
First, understand how Service works, and it does not need to be of type load balancer. It can be a ClusterIP
That covers you for anything TCP related.
Now, if you need Ingress functionality, using ingress-nginx, with Service of type ClusterIP , and you now have a solution which does not depend on IaaS.
So with DNS would this work by pointing a new record to the cluster and making requests to the service that way?
Well, provided the ClusterIP is routable
Typically clusters are deployed on private CIDR ranges, so the Service will have a private ClusterIP
If you just want the DNS to work internally, that’s enough. Otherwise, you’ll need to ensure the ClusterIP is on a routable network, or configure port forwarding from some other service, like a firewall
Would have to know more about what your goal - the business objective.
Gotcha, seems easy enough.
i have a helm chart now that uses aws-load-balancer-controller and in order for this helm chart to be deployable “anywhere” (any cloud k8s) its just a matter of removing the IaaS deps
we were only targeting aws customers, but apparently a few customers in the pipeline have/use GCP - which i know nothing about
not even mentioning the cert-manager + istio work effort we’re pulling up on these next few sprints (in our org)
very limited experience with istio - but it too has an ingress, so likely we will go that way + cert-manager for x509 certs to support mTLS internally. we would give the customer an option, deploy cert-m if you don’t have one, just give us a CA to use, or we will gen self-signed. and istio to support it all
2024-05-08
Status: CLOSED Heroes: :crown:@Hao Wang, @Adi
Hey guys! In AWS EKS I have deployed a StatefulSet Apache Kafka, it’s working well except when I upgrade the docker image or if all the nodes goes to 0 it loses the volume data despite having volumeClaimTemplates defined. The full config is in the first reply!
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: kafka
labels:
app: kafka-app
namespace: kafka-kraft
spec:
serviceName: kafka-svc
replicas: 3
selector:
matchLabels:
app: kafka-app
template:
metadata:
labels:
app: kafka-app
spec:
containers:
- name: kafka-container
image: {{placeholder}}/kafka-kraft:6
ports:
- containerPort: 9092
- containerPort: 9093
env:
- name: REPLICAS
value: '3'
- name: SERVICE
value: kafka-svc
- name: NAMESPACE
value: kafka-kraft
- name: SHARE_DIR
value: /mnt/kafka
- name: CLUSTER_ID
value: gXh3X8A_SGCgyuF_lBqweA
volumeMounts:
- name: data
mountPath: /mnt/kafka
imagePullSecrets:
- name: docker-reg-cred
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes:
- "ReadWriteOnce"
resources:
requests:
storage: "1Gi"
CAPACITY, ACCESS MODES, RECLAIM POLICY, STATUS CLAIM, STORAGECLASS, VOLUMEATTRIBUTESCLASS, REASON
• 1Gi, RWO, Delete, Bound, kafka-kraft/data-kafka-2, gp2,
• 1Gi, RWO, Delete, Bound, kafka-kraft/data-kafka-0, gp2,
• 1Gi, RWO, Delete, Bound, kafka-kraft/data-kafka-1, gp2,
@miko can you check what is retain policy
This document describes persistent volumes in Kubernetes. Familiarity with volumes, StorageClasses and VolumeAttributesClasses is suggested. Introduction Managing storage is a distinct problem from managing compute instances. The PersistentVolume subsystem provides an API for users and administrators that abstracts details of how storage is provided from how it is consumed. To do this, we introduce two new API resources: PersistentVolume and PersistentVolumeClaim. A PersistentVolume (PV) is a piece of storage in the cluster that has been provisioned by an administrator or dynamically provisioned using Storage Classes.
@Adi I run the following command kubectl get statefulset kafka -o yaml and I received this:
apiVersion: apps/v1
kind: StatefulSet
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"apps/v1","kind":"StatefulSet","metadata":{"annotations":{},"labels":{"app":"kafka-app"},"name":"kafka","namespace":"kafka-kraft"},"spec":{"replicas":3,"selector":{"matchLabels":{"app":"kafka-app"}},"serviceName":"kafka-svc","template":{"metadata":{"labels":{"app":"kafka-app"}},"spec":{"containers":[{"env":[{"name":"REPLICAS","value":"3"},{"name":"SERVICE","value":"kafka-svc"},{"name":"NAMESPACE","value":"kafka-kraft"},{"name":"SHARE_DIR","value":"/mnt/kafka"},{"name":"CLUSTER_ID","value":"gXh3X8A_SGCgyuF_lBqweA"}],"image":"<redacted>","name":"kafka-container","ports":[{"containerPort":9092},{"containerPort":9093}],"volumeMounts":[{"mountPath":"/mnt/kafka","name":"data"}]}],"imagePullSecrets":[{"name":"docker-reg-cred"}]}},"volumeClaimTemplates":[{"metadata":{"name":"data"},"spec":{"accessModes":["ReadWriteOnce"],"resources":{"requests":{"storage":"1Gi"}}}}]}}
creationTimestamp: "2024-04-18T07:01:03Z"
generation: 4
labels:
app: kafka-app
name: kafka
namespace: kafka-kraft
resourceVersion: "8108458"
uid: b4179eec-d36d-41ce-aa07-d6bad10d884a
spec:
persistentVolumeClaimRetentionPolicy:
whenDeleted: Retain
whenScaled: Retain
podManagementPolicy: OrderedReady
replicas: 3
revisionHistoryLimit: 10
selector:
matchLabels:
app: kafka-app
serviceName: kafka-svc
template:
metadata:
creationTimestamp: null
labels:
app: kafka-app
spec:
containers:
- env:
- name: REPLICAS
value: "3"
- name: SERVICE
value: kafka-svc
- name: NAMESPACE
value: kafka-kraft
- name: SHARE_DIR
value: /mnt/kafka
- name: CLUSTER_ID
value: gXh3X8A_SGCgyuF_lBqweA
image: <redacted>
imagePullPolicy: IfNotPresent
name: kafka-container
ports:
- containerPort: 9092
protocol: TCP
- containerPort: 9093
protocol: TCP
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /mnt/kafka
name: data
dnsPolicy: ClusterFirst
imagePullSecrets:
- name: docker-reg-cred
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
updateStrategy:
rollingUpdate:
partition: 0
type: RollingUpdate
volumeClaimTemplates:
- apiVersion: v1
kind: PersistentVolumeClaim
metadata:
creationTimestamp: null
name: data
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
volumeMode: Filesystem
status:
phase: Pending
status:
availableReplicas: 3
collisionCount: 0
currentReplicas: 3
currentRevision: kafka-8dd896cf4
observedGeneration: 4
readyReplicas: 3
replicas: 3
updateRevision: kafka-8dd896cf4
updatedReplicas: 3
It seems that the retain policy is Retain
spec:
persistentVolumeClaimRetentionPolicy:
whenDeleted: Retain
whenScaled: Retain
I went to retrieve all the PVCs as well kubectl get pvc and kubectl describe pvc data-kafka-0 for which I received:
Name: data-kafka-0
Namespace: kafka-kraft
StorageClass: gp2
Status: Bound
Volume: pvc-c9f45d3a-e1a7-4d3a-8e51-79a411411d43
Labels: app=kafka-app
Annotations: pv.kubernetes.io/bind-completed: yes
pv.kubernetes.io/bound-by-controller: yes
volume.beta.kubernetes.io/storage-provisioner: ebs.csi.aws.com
volume.kubernetes.io/selected-node: <redacted>.<redacted>.compute.internal
volume.kubernetes.io/storage-provisioner: ebs.csi.aws.com
Finalizers: [kubernetes.io/pvc-protection]
Capacity: 1Gi
Access Modes: RWO
VolumeMode: Filesystem
Used By: kafka-0
Events: <none>
@Adi idk what I’m missing but it seems to be saying Retain as its policy, perhaps it’s due to my Dockerfile path not the same with volumeMounts’ mounthPath from my StatefulSet?
volumeMounts:
- name: data
mountPath: /mnt/kafka
how about “kubectl get pv”?
volumeMode: Filesystem is set, so when the node is gone, the volume is gone with the node
Hi @Hao Wang ohh I’ll check how to change that, but I also lose the data when I upgrade the image version (I’m away from my laptop but when I get back I’ll run “kubectl get pv”)
oh I am wrong, filesystem is not file in docker
should be the retention policy in storageclass and pv
may need to create a new storageclass with reclaimpolicy as Retain
Oooh like change my EBS CSI driver?
Or explicitly define the storage class to use in my statefulset?
can try edit gp2 and set reclaim policy to Retain
@Hao Wang running kubectl get pv and I get this:
they were created 22 days ago
are they reused?
sorry dumb question but what do you mean by reused? what I’ve done so far is run my StatefulSet which I thought should be enough to get a persistent volume :C and yes I’ve run my StatefulSet many days ago but it’s just recently I realized that whenever I upgrade my StatefulSet kafka is I lose the messages inside of it
got it :+1: we can change the storageclass to Retain and it should fix the issue
Omg I checked the gp2 description and it’s policy is Delete
but how come :CCC why is the policy Delete? :C
kubectl describe storageclass gp2
Name: gp2
IsDefaultClass: Yes
Annotations: kubectl.kubernetes.io/last-applied-configuration={"apiVersion":"storage.k8s.io/v1","kind":"StorageClass","metadata":{"annotations":{"storageclass.kubernetes.io/is-default-class":"true"},"name":"gp2"},"parameters":{"fsType":"ext4","type":"gp2"},"provisioner":"kubernetes.io/aws-ebs","volumeBindingMode":"WaitForFirstConsumer"}
,storageclass.kubernetes.io/is-default-class=true
Provisioner: kubernetes.io/aws-ebs
Parameters: fsType=ext4,type=gp2
AllowVolumeExpansion: <unset>
MountOptions: <none>
ReclaimPolicy: Delete
VolumeBindingMode: WaitForFirstConsumer
Events: <none>
this may be an old EKS, AWS got gp3
my cluster version is 1.29 but I deployed my AWS EKS via terraform along with the EBS CSI driver
ooh wait my EBS CSI driver I manually installed via ~Helm~ eksctl
eksctl may not touch storageclass
@Hao Wang I found the command to update gp2 reclaim policy, I’ll give it a try!
kubectl patch pv <your-pv-name> -p '{"spec":{"persistentVolumeReclaimPolicy":"Retain"}}'
yeah, it is the one
oh this is for pv
kubectl edit sc gp2
Ohh I have to edit gp2 directly?
Ooowkie thank you!
np
wow I can’t edit reclaim policy
The StorageClass "gp2" is invalid: reclaimPolicy: Forbidden: updates to reclaimPolicy are forbidden.
would it be better if I try and migrate to gp3 and try to set default storageclass to gp3 for my future statefulset to always use gp3?
yeah, let us give it a try
Holy smokes… migrating to GP3 is a pain in the butt:
https://aws.amazon.com/blogs/containers/migrating-amazon-eks-clusters-from-gp2-to-gp3-ebs-volumes/
Since this cluster is not production I will just delete the resources in the following order: StatefulSet, PVC, PV and re-apply my StatefulSet again.
The quickest solution that doesn’t require deletion is to change the reclaim policy of PV and not StorageClasses level:
• DONT
◦ kubectl edit sc gp2
◦ edit reclaim policy to Retain
◦ -> The StorageClass "gp2" is invalid: reclaimPolicy: Forbidden: updates to reclaimPolicy are forbidden.
• DO
◦ kubectl patch pv pvc-646fef81-c677-46f4-8f27-9d394618f236 -p '{"spec":{"persistentVolumeReclaimPolicy":"Retain"}}'
Hello folks, good evening from Costa Rica. I was wondering if someone here has ever had a similar question to this.
How do you usually monitor performance for an app running inside a Kubernetes/OpenShift cluster?
I just found a tool bundled within OpenShift called Performance Profile Creator, but it unknown to me if there’s any Kubernetes-native solutions.
What are you trying to measure/improvement exactly? Is it a web app where client requests are slower then you would like? Are you trying to ensure nothing like CPU throttling is happening on the app? or that the node/worker is not overloaded?
Mostly that there are no CPU throttling issues or overloads
So I’ve been using kube prometheus stack https://artifacthub.io/packages/helm/prometheus-community/kube-prometheus-stack
It has built in CPU throttling alerts already as I’ve seen them when my pods didn’t have enough requests set.
I’ve noticed it the default charts/graphs don’t do steel time. So i’ve been meaning to do a contribution for that. But if steel time is a concern for you (ex. you aren’t using dedicated/metal nodes), you may want to use this query:
sum by (instance, cpu) (rate(node_cpu_seconds_total{mode="steal"} [2m]))
ref: https://stackoverflow.com/questions/76742560/how-to-measure-cpu-steal-time-with-prometheus-node-exporter-metrics#<i class="em em-~"</i>text=Node%20exporter%20exposes%20metric%20node_cpu_seconds_total,as%20part%20of%20cpu%20collector.&text=can%20show%20you%20how%20much,every%20CPU%20of%20every%20machine>.
^ Assumes you install kube prometheus stack first.

kube-prometheus-stack collects Kubernetes manifests, Grafana dashboards, and Prometheus rules combined with documentation and scripts to provide easy to operate end-to-end Kubernetes cluster monitoring with Prometheus using the Prometheus Operator.
How CPU Steal Time can be measured by Prometheus Node-exporter CPU metrics? We have an OpenStack/KVM environment and we want to measure/Know how much CPU steal happens (Percent) in our Computes/Hosts/
Also, i’m using EKS but that chart should work on any k8s distro
2024-05-09
2024-05-10
2024-05-15
Anyone here have recommendations on ML based tools that can help recommend or even automatically set things like: Requests, Limits, Affinity, and Anti-affinity scheduling policies?
Get your resource requests “Just Right”
are there good projects to inject “chaos” pod termination/node termination, network failures into kubernetes? in order to test our applications resiliency
Something like https://github.com/asobti/kube-monkey
An implementation of Netflix’s Chaos Monkey for Kubernetes clusters
chaoskube periodically kills random pods in your Kubernetes cluster.
2024-05-16
2024-05-23
Hey I watched a CNCF webinar by someone from Werf about a tool called “nelm”. I have not tried it but it is a backwards compatible fork from helm 3 to solve many important problems with helm, one of which that helm is barely evolving to fix its problems (eg helm 4 is 2 years behind schedule and no roadmap to get there).
It’s a 50 minute presentation but here is a summary slide from the end of the presentation. In particular, Werf team has maintained compatibility with helm 3, they have done away with 3-way merge in favor of k8s server-side-apply, nelm tracks resources and can rollback properly, it has improved support for CRDs and helm charts can be fetched directly from git (like terraform for modules), nelm has a dependency system, etc.
It is not yet available as a standalone package but Werf is working on it, so currently you have to install werf to get nelm.
Interesting… thanks for sharing
helm v4 is coming.
Interesting! I need to get up to speed on that.
Is it further along than it appears via issues?
Are there any resources / links available to know more about the strategy of helm 4?
2024-05-24
Status: CLOSED Hero: @Piotr Pawlowski
Hey guys, I’m reading Cluster-level logging architectures but I can’t quite understand what this means:
You can implement cluster-level logging by including a node-level logging agent on each node. The logging agent is a dedicated tool that exposes logs or pushes logs to a backend. Commonly, the logging agent is a container that has access to a directory with log files from all of the application containers on that node.
What does it mean to implement something at a node-level? Does it simply mean to run the YAML inside the cluster? What do they mean by agent? The deployment is the agent?
it means you run some agent (service) on each node, most often as a daemonset, which is responsible for collecting logs from each of the container running on particular node, and forward them to centralised log storage
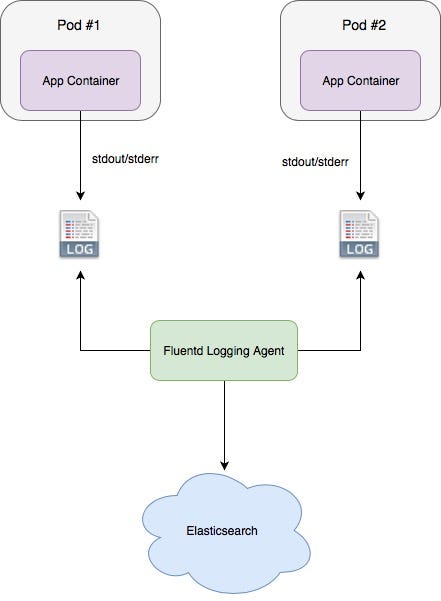
Logs are crucial to help you understand what is happening inside your Kubernetes cluster. Even though most applications have some kind of…
When it says to node specific it just simply means to deploy in the cluster right? Because control plane is on another machine
true for kubernetes as a service (EKS, AKS) where you do not have access to control plane nodes, for self-hosted k8s yopu should run them on CP too in order to collect logs from pods running on those nodes as well
2024-05-28
Is there any example of eks addons interaction with EBS?
What do you mean? The CSI driver?
Are you using the cloudposse module?