#random (2024-03)
Non-work banter and water cooler conversation
A place for non-work-related flimflam, faffing, hodge-podge or jibber-jabber you’d prefer to keep out of more focused work-related channels.
Archive: https://archive.sweetops.com/random/
2024-03-01
re the whole cp/atmos/sweetops rebrading re logos etc (they look awesome), is there going to be some related swag? with glow in the dark extras? — asking for a friend
we should do that, nothing yet. What’s everyone using these days for that?

(“my friend has”)
Has anyone experienced any longterm affects of not implementing formatting in pipelines? I am curious what potential downfalls could come from a lack of terraform fmt in pipelines
Having this fmt being done in the pipeline save a lot of review remarks re fmtting (anf this the braincells during a pr can be used for actual reviews).
Recently somebody in my team made a remark re some space/tab thing that is not picked up by tf fmt and that was quickly resolve b “if fmt does not & cannot fix it, it’s not an issue”
Also look into pre-commit for terraform fmt, white space, and end of line issues. A huge time saver when it comes to reviews
 1
1I’m currently working with an organization that did not turn on formatting from the start, so utilizing pre-commit and pipelines now formats each commit, and the team is resistant to implement formatting now because they prioritize git history and blame over formatted code. I am trying to rationalize an argument to begin implementing it now, but it isn’t looking promising
was initially also a bit hessitant re auto-formatting and the likes (but in favor of linting etc though), but noticing it saves a lot of non-discussion and provides more content focused reviews. Initially it’s a single sweep, and as we combine it with merged commits combined with small commits, the “blame”/history is a non-issue. (having al these “fix small typo” commut msgs is alo adding more noise as value)
but still quite opposite to mandatory pre-commit hooks or things that run pipeline-side only
I agree, can you elaborate on how the history is a non issue from your experience? @Hans D
we do more or less trunk based development re our infra. Short lived branches, and many ieteration. That way we already get a nice sense of the evolution of the concept - and allowes for faster reaction to the actual production interaction. Having long lived branches (> 3 days) with prs that take days for a proper review and understanding, it tends to generate lot of noisy commits - making the case for “keep the history” already something to be like - too much noise/detail, skip looking at those. Or getting things like, you should do a squash, having essentially the same effect. In combination with github and having the review remarks in there still attached to the commits (good for referencing the blamce etc). And as time continues, that details git history becomes like having 5 sec resolution on your monitoring becoming less relevant/usuable as time continues. having worked with “working on a branch for weeks” combined with all the details and merging paths in git, and the “multiple prs / day” with sweet linear history, I do prefer the latter one. Nice test in that case: if somebody has been on leave for a couple of day, how do they catch up with the changes? I prefer a summary, diff on now…last known situation and look at the interesting bits over having to go through each pr/commit.
Combine that with the non-default formatting/linting with most prs consisting of shoving code around, cause I like to do it in my style …
dont get me wrong, blame is still good to have. Having small prs where just a single person is working on, provides better understanding as lets-have-pre-integration branches where the whole team touches stuff (as the latter does require you keep the whole history).
(some context, our team of 3 + renovatebot generated over 1000 prs in the last 5 months - all to trunk and almost all prs have an additional fmt/code-generation commit - but those get squashed on the merge. Some small change of 3 lines can be amplified into the actual commit being 1000s of lines in what we call dont-panic prs)
@Jeremy White (Cloud Posse) you’ve been witnessing this at our side, perhaps you can share your observations in how we progressed on this bit
in my opinion, formatting terraform code will not bring any benefit at all. Some times, it will introduce false changes that are not necessary, like aligning after equal sign.
alfa = "v1"
beta = "v2"
vs
alfa = "v1"
beta = "v2"
long_variable_name = "v3"
The change on the first two lines are unnecessary and usually noise in the PRs. I totally understand formatting and linters in the real programming languages like php, python, java, rust, and so on, but on terraform not really necessary. So, I would keep the part of the team that doesn’t want to introduce another problem that they don’t have it already.
Would be better even for you to focus more on the correctness of the code itself, not on how it looks.
And here is another crazy idea that we have in my company and I am totally against it, but the team likes it. Generating readme files for terraform projects that nobody reads.
Would be better even for you to focus more on the correctness of the code itself, not on how it looks.
Human nature: they will first pick on these kind of things, before the actual code. Primary reason why golang was implemented to do the “we determine the formatting, you take care of the code”.
| Generating readme files for terraform projects that nobody reads We do tons of readme generations. Not always read right now, but our futurse self and future team mate will thank that us we did…
well, I disagree on the part with readme generation. While it totally makes sense for terraform module and documentation that somebody actually writes with valuable information, for the terraform projects where the tf-docs only generates a list of resources and modules, I haven’t seen anyone using those files in years
i’ll post my picture, as I’ve been using some of those readme files (also from the cloudposse repos)
again, I am not talking about the terraform modules readme files, those make perfect sense to have and use. What I am talking about is the terraform code that we write as projects to create our infrastructure.
Thinking about this again, I think code generation follows lock step with how to DRY things. After you start copy pasting, you always hit a point where things are ‘human effort’. You have to ask yourself, when does human effort reach a critical point. I advocate generating configuration when you actually find the golden pattern, and that is something you need to soul search for while you work on other DRY efforts.
As for whitespace changes in code formatting, don’t forget that whitespace changes are a matter of configuring your view in PRs. Here’s a screenshot of a public PR on our components repo. Note the setting “Hide Whitespace” in the lower right:
Moreover, you can use .gitattributes to auto fold/accept readme changes if you feel like they are irrelevant to a change: https://docs.github.com/en/repositories/working-with-files/managing-files/customizing-how-changed-files-appear-on-github
@Michael JFYI you can ignore formatting commits for git blame: https://www.stefanjudis.com/today-i-learned/how-to-exclude-commits-from-git-blame/ This is also supported by Github: https://docs.github.com/en/repositories/working-with-files/using-files/viewing-a-file#ignore-commits-in-the-blame-view
(jm2c/unpopular opinion: if they want a clean git history, they should’ve done it right from the beginning)
12024-03-04
2024-03-05
I’m excited to share Quantm (https://quantm.io), a platform I founded that aims to automate and simplify your release workflows. I’m curious to hear your thoughts and experiences. Do any of you currently use tools for deployments? What are the biggest pain points you encounter? Quantm focuses on addressing common issues like:
• Complex release configurations
• Inefficient collaboration during deployments
• Repetitive and time-consuming release tasks We believe Quantm can help streamline your process and free you up to focus on building amazing things. I’d love to hear your feedback and answer any questions you might have. Feel free to share in this channel or reach out directly. Thanks, Yousuf (CEO, Quantm)x
Automate with proven release engineering best practices. Accelerate releases, gather rapid customer insights, and maintain rock-solid reliability.
2024-03-07
2024-03-08
over 9000
(almost)
2024-03-10
Due to the insane demand for our null label module, we have launched a clothing brand. Because these days that’s what you do when you become famous.
Null Label - Unleash Your Unique Style with Curated Streetwear Discover a diverse world of streetwear at Null Label. We curate the latest and most unique selections from various labels, allowing you to express your individuality with confidence. Explore our collection today!
Null Label - Unleash Your Unique Style with Curated Streetwear Discover a diverse world of streetwear at Null Label. We curate the latest and most unique selections from various labels, allowing you to express your individuality with confidence. Explore our collection today!
2024-03-12
2024-03-14
Anyone tried Terraform stacks? I’m curious about your experience and how you think it stacks (pun intended) against tools like Terragrunt
Is it exclusive to Terraform cloud?
Yeah, it’s currently exclusive to Terraform Cloud. I’m interested in the feature, but I don’t use TFC.
what do you do now instead? I used to use Terragrunt, but now I use code generation and a Taskfile to manage inter-module dependencies and envs

Terramate also launched this https://terramate.io/docs/cli/stacks/
Learn how stacks help you efficiently build and manage infrastructure as code projects at any scale with technologies such as Terraform.
I still use terragrunt mostly. Also spacelift
I think it’s important to first clarify what a stack is. From Cloud Posse’s perspective, a stack is defined quite differently from others. We define a stack as a collection of loosely coupled components. Components are things like root modules, helm charts, etc. Each of those components has its own lifecycle. From a (cloud posse) best practices perspective, we like to decompose a stack of its parts, separated by lifecycle. The VPC has a different lifecycle, from the databases, clusters, and applications that sit on top of the cluster. Similarly two different stacks might be more or less identical, but deployed in different regions. They should share nothing, including provider configuration. E.g. one component should almost never provision resources in more than one region, to preserve DR capabilities.
For example, in Spacelift, a Stack is simply an invocation of a terraform root module. Is that really anything different from a Root module? When we use spacelift, we deploy what we call “components” as what space lift calls “Stacks”
Terramate defines it yet differently. From their example, a stack seems similarly defined as in Spacelift, and allowing it to depend on other root modules, but again, just a root module configured with dependencies.
# stack.tm.hcl
stack {
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# Configure the metadata of a stack
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
name = "Terraform Example Stack"
description = "An awesome stack for demo purposes"
id = "780c4a63-79c2-4725-81f0-06d7c0435426"
tags = [
"terraform",
"prd",
"service-abc"
]
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# Optionally the orchestration behavior can be configured
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# Ensures that the current stack is executed before the following stacks
before = [
"../stack-a",
"../stack-b",
]
# Ensures that the current stack is executed after the following stacks
after = [
"../stack-c",
]
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# Optionally the trigger behavior can be configured
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# If any of the configured files changed, this stack will be marked as changed in the change detection.
watch = [
"/policies/mypolicy.json"
]
# Forces the execution of a list of stacks whenever the current stack is executed
# even if those don't contain any changes
wants = [
"../stack-d",
]
# Ensures that the current stack always gets executed when a list of configured
# stacks are executed even if the current stack doesn't contain any changes
wanted_by = [
"../stack-e",
]
}
Are you generating a root module based on other modules using Taskfile?
We use a cli tool we built to generate all the terraform in different local directories (modules) with an accompanying auto-generated Taskfile that applies them in order + some convenience management commands for devs
We generate this code for every environment explicitly, so we can check the git repo at any time and see the corresponding TF code in the appropriate directory
So, on the one hand, I agree with committing the TF code for its immutability/auditability (it’s why we vendor & commit components). The practical downside is that no engineer likes doing code reviews of machine-generated code, so large amounts of code go unchecked from a practical point of view.
This is ultimately why we built atmos because we wanted to rely minimally on meta programming for Terraform. This is a departure from a lot of other tools that automate terraform. Cloud Posse has generally not relied on code generation of Terraform, and when we’ve been tempted, realized that our architecture was wrong.
@george.m.sedky I think I might be confusing what you’re doing with how other tools work in the Terraform ecosystem. From our earlier conversations (not in this thread), I recall now that you are developing more of visual CAD software for Terraform, which is different from the problem I address, using Terraform code generation to overcome the perceived limitations of Terraform.
This is the one I’m referring to in this thread https://github.com/stakpak/devx
A tool for generating, validating & sharing all your configurations, powered by CUE. Works with Kubernetes, Terraform, Compose, GitHub actions and much more…
We’re moving away from this approach to work on the visual CAD / Copilot interface I showed you
Ohhhhhh hah, cool. Fun coincidence since you used cue and were asking about stacks. Check this out https://github.com/DavidGamba/dgtools/tree/master/bt#stacks-a-different-take
We discussed it on #office-hours last week
Yes we built a code-gen + stacks approach (as you explained different people define stacks differently) and have been using it with multiple clients over the past year
Devs were split about using CUE, half of the people hate it and the other half love it
We built a lot of tooling around CUE, like a package manager and an LSP to make it easier
But CUE made onboarding take way longer than what the average developer expected
I could imagine
Sounds like a good blog post: lessons we learned trying to adopt cue with Terraform. The good (awesome?), the bad, the ugly.
2024-03-15
2024-03-16

Reduces build times and repository maintenance costs through high-quality developer tooling.
pretty wild stuff in here. For instance, they have their own query lang for your monorepo: https://moonrepo.dev/docs/concepts/query-lang
moon supports an integrated query language, known as MQL, that can be used to filter and select
Time to make a PR for supporting atmos
they already have terraform https://moonrepo.dev/docs/proto/tools#terraform
Looks fascinating
2024-03-18
hard to sell in a good price, the potential buyers know if opponents invest into OpenTofu, Hashicorp’s stock is down with no limit
have seen this in many products… it is a dillema
2024-03-21
hello everyone, i’m wondering if someone already try to manage cluster with Argocd And Velro with Backup ? i want to be able to recover from a disaster with velero , but my infra is driven by argocd so if my cluster is destroyed i wanna to restore eveything based on Argocd (repo git )
- data from Velero some one already tried something like this ?
Velero makes sense as a general purpose solution to restore services, however, did you also consider an IaC gitops solution? What works for us is deploying all infrastructure, up through kubernetes and essential backing services with Terraform. We deploy argocd with Terraform. We use GitHub Actions or spacelift together with atmos.
How does velero handle full reconstitution of the cluster? In our deployments ArgoCD is behind and ALB, with tls and DNS. The ingress controller is deployed ahead of argocd. And external DNS is required for the TLS (ACM) to work together with the ALB. All these uncertainties are why I like the approach of building a cluster rather than restoring a cluster from backups. I could imagine velero restoring ingress, acm, external DNS. Then after multiple reconciliations ingress getting deployed, new load balancers provisioned, DNS updated by external-DNS, argocd coming up, etc. The logs will be pulluted with failures, but eventually every thing coming online and things settling down.
i’ve quite the same Approch
• Tf => cluster + argocd (deploy + config) AppSet repo
• then everything is deployed in few minutes
• argocd is sefl managed btw at this point eveything is working as expected ( DNS/argocd/ SVCs adn velero backup are stored in S3)
now i’m wondering if i want to recover from a disaster how do i manged both argocd And velero
because when eveything is up again .. i ‘ll trig at some point a Vlero restore
but there seems to be an conflict between freshly new pvc/pv created and those backuped from velero
Also, if some other system was ultimately responsible for provisioning those services restored by velero, and those other systems (e.g. terraform) keep state, that state is now out of sync with the cluster and drifting. So using both together would not make sense.
Yes, so i agree with your last statement
i don’t think i’m the only one how think about such a solution ( or maybe i’m in the wrong direction )
And regarding PVs it gets real ugly. If you can avoid it, that is what we advise our clients.
what do you advise so to restore data ( which are not store in Argocd repo ( helm definition of Svcs)?=)
There are different schools of thought with k8s. Some aim for treating clusters as cattle with very little requirements on state durability. Others full tilt the other direction. Stick everything in the cluster.
So when operating on public cloud, keep data outside of the cluster in fully managed services. Avoid patterns that rely on filesystems for durability.
But when on-prem, or dealing with legacy apps, solutions are on a case by case basis. Silver bullets do not exist.
Some of our customers get by using EFS on AWS when they need durable filesystems and their I/O patterns don’t make it cost prohibitive. Again not a silver bullet, but one way to simplify things.
ok i get your point and totally aggree with you . the golden choice when u are on public cloud is to store your data on your own DFS obviously , but in my case i can’t that’s why i came with both velero and Argocd managed everything as a gitops stuff
will try to dig more thank you for your time and your explanation
Aha, yes, I understand better now with those requirements. Would be great to hear how it works out with Velero given your constraints. Report back!
one solution after few internal disucussion would
to have pre-hook/installthat will try to check on Velero side if there is any Backup existence, if yes, then restore if not => just continue the process
i have a bunch of mandatory svc , taht don’t need backup and there populated first in all my cluster => that’s why this solution can fit my need
but i need to test it now ^^
EDIT: Wrong account sorry !
2024-03-25
Newly discovered vuln in Apple M-series chips lets attackers extract secret keys from Macs. “The flaw—a side channel allowing end-to-end key extractions when Apple chips run…widely used cryptographic protocols—can’t be patched” https://t.co/yjQTogcIzk
whoopsie
Newly discovered vuln in Apple M-series chips lets attackers extract secret keys from Macs. “The flaw—a side channel allowing end-to-end key extractions when Apple chips run…widely used cryptographic protocols—can’t be patched” https://t.co/yjQTogcIzk
physical security is key now
now? It always has been.
2024-03-26
Hey all! We just launched QueryPal on Devhunt (a product discovery platform built by developers for developers). QueryPal is an AI powered Slack assistant that automatically provides answers to Slack questions using company data, freeing your team up to deliver the outcomes that drive real growth. QueryPal integrates with Google Drive, Notion, Jira, Confluence and more.
Take and look and throw us an upvote if you think it’s interesting! Can’t wait to hear your thoughts
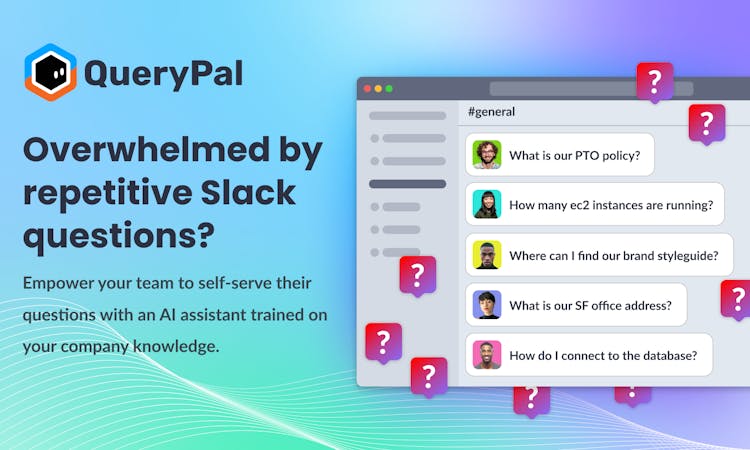
The smartest AI-powered Slack assistant for high-performance teams
Is this like https://github.com/danswer-ai/danswer?
Gen-AI Chat for Teams - Think ChatGPT if it had access to your team’s unique knowledge.
Hey Erik! Nice to connect and thanks for your question. I think we have some overlapping core features, but you can customize the knowledge stores by each Slack channel and also set granular admin permissions for each bot. Added a screenshot here for clarity
Would be curious to hear your thoughts given your background
@george.m.sedky see this? https://www.infoq.com/news/2024/03/actionforge-github-action-gui/

Actionforge provides a visual, node-based interface to create and maintain GitHub Action workflows masking their underlying YAML textual definition. Packaged as an extension for Visual Studio Code, the tool does not require any external services and is now available in beta.
2024-03-27
2024-03-28
On March 21, Redis Ltd. announced that the Redis “in-memory data store” project would now be released under non-free, source-available licenses, starting with Redis 7.4. The news is unwelcome, but not entirely unexpected. What is unusual with this situation is the number of Redis alternatives to choose from; there are at least four options to choose as a replacement for those who wish to stay with free software, including a pre-existing fork called KeyDB and the Linux Foundation’s newly-announced Valkey project. The question now is which one(s) Linux distributions, users, and providers will choose to take its place.
2024-03-30
Small announcement from my end. My journey from DevOps -> DataEngineering -> StartupFounder. (apologies in advance - if this comes across as spam!)
*About my Startup Journey*
◦ I’m building [HRHouz](https://www.hrhouz.com) - a platform dedicated to bringing AI driven Recruitment toolsets for Employers. The idea and motivation to build [HRHouz](https://www.hrhouz.com) largely stems from my personal experiences and life incidents. It started as a hobby, and is getting into the serious zone today ….
◦ My first product, AI Driven Reference Checks, is now live and used at a few companies. It has helped Employers save 4hrs to 6hrs in HR/Employer time per candidate. With just one click, Employers can collect candidate references, analyze them, gain deeper candidate insights, detect candidate fraud, and address associated HR reporting & compliance challenges.
◦ My second product, AI Driven [Resume Scanner](https://www.hrhouz.com/resume-scanner) (completely FREE - do try it!), was crafted to help recruiters - in asking better candidate screening questions, in delving deeper into candidate engagement, and reducing the mental strain from back-to-back candidate meetings. We are rolling out an update to this soon to fine-tune questions based on Job Description (stay tuned!). <i class="em em-information_desk_person"></i> _*Requesting Help*_
◦ I recently got accepted into <https://www.linkedin.com/feed/update/urn<i class="em em-li">[Antler VC](/i>activity:7179160311453609984) residency at Austin. I’m still continuing my discussions and exploring other avenues. I would appreciate any warm intros to VC’s or any guidance on this front.
◦ I would greatly appreciate any support (follows, likes and reshares) on HRHouz socials *[LinkedIn](https://www.linkedin.com/company/hrhouz/)*, *[Twitter](https://twitter.com/hrhouz)*, *[Facebook](https://www.facebook.com/hrhouz)*, *[Instagram](https://www.instagram.com/hrhouz/)*, *[Threads](https://www.threads.net/@hrhouz)*. This would help me get the word out more organically to people outside my network.
◦ I would love to do a 1:1 demo, discuss HRTech, discuss associated Engineering Challenges, GTM, PMF etc. with smart folks in this group. Also, if you have any ideas I can be building in the HRTech space, would love to listen and/or collaborate.
◦ **I am giving the product out for free (with no strings attached). And more importantly if you are hiring - I would love to connect, show you HRHouz, and explore how I can add value to your hiring efforts.
◦ **If you know any HR Folks, Recruiters or Talent Acquisition Folks - intro’s to them would be of great help - as they are my target users today.
*Travelling to Austin!*
◦ I will be in Austin for 2 months (April & May) attending Antler VC residency. I would love to catch up with folks from this slack group in Austin.

Exciting News Alert!
| We are thrilled to announce that HRHouz has been accepted into the highly competitive Antler’s Prestigious Residency Program! … | 85 comments on LinkedIn |
If you are ever in Houston, hit me up
Exciting News Alert!
| We are thrilled to announce that HRHouz has been accepted into the highly competitive Antler’s Prestigious Residency Program! … | 85 comments on LinkedIn |
Hey @Erik Osterman (Cloud Posse) - will do .. as of now - the plan is to stay put in austin. But that may change and push me towards austin / houston. Will follow up with you if I make the trip.
2024-03-31

Please note: This is being updated in real time. The intent is to make sense of lots of simultaneous discoveries
Fascinating read
Please note: This is being updated in real time. The intent is to make sense of lots of simultaneous discoveries
I was curious about who commit the codes, and waiting for this post, tada unfortunately and unsurprisingly
great share … this is a good read!
is there a particularly good email list or something where you find out about this stuff? I found out just via youtube, I wish I had it a few days earlier
hmm don’t really remember, I got my pad back yesterday and found this one…
From my interactions on LinkedIn, some users are fake and malicious even their names are not in Chinese -> names will give you a distraction to make you tend to believe or not, be very careful
I have proved this news with my own experiences, https://www.bbc.com/news/uk-66599376