#terraform (2018-11)
 Discussions related to Terraform or Terraform Modules
Discussions related to Terraform or Terraform Modules
Archive: https://archive.sweetops.com/terraform/
2018-11-01
I have a few more questions … how do I ref the output of a module in another module …
ie create kms key and then pass the arn to my postgres module … then the postgres module pass the endpoint to my rout53 module
Operators adopt tools like HashiCorp Terraform to provide a simple workflow for managing infrastructure. Users write configurations and run a few commands to test and apply changes…
example: you create a VPC module https://github.com/cloudposse/terraform-root-modules/blob/master/aws/backing-services/vpc.tf#L5
Collection of Terraform root module invocations for provisioning reference architectures - cloudposse/terraform-root-modules
then pass its outputs to the RDS module https://github.com/cloudposse/terraform-root-modules/blob/master/aws/backing-services/rds.tf#L168
Collection of Terraform root module invocations for provisioning reference architectures - cloudposse/terraform-root-modules
nice! got it!
Thank you @Andriy Knysh (Cloud Posse)
@johncblandii your PR looks good, merged to master, thanks
Terraform module to provision an AWS Elastic Beanstalk Environment - cloudposse/terraform-aws-elastic-beanstalk-environment
thx
releasing a version or going to stack a few?
new release https://github.com/cloudposse/terraform-aws-elastic-beanstalk-environment/releases/tag/0.6.3
Terraform module to provision an AWS Elastic Beanstalk Environment - cloudposse/terraform-aws-elastic-beanstalk-environment
do you guys have an option on terragrunt?
AFAIK cloudposse/geodesic doesn’t support terragrunt ootb, however you could easily open a PR to change the terraform path to that of terragrunt. The question is why would you want to? After using terragrunt before, and being happy with using in moderation, I’m unsure what you would want that geodesic doesn’t give you. With the added fact that terraform 0.12 is soon landing (not withstanding the beta which is already out) that no doubt will have some backwards compatibility issues with terragrunt. Terragrunt was initially created back when TF was lacking in some of its orchestration. It has moved on since then with alot of this stuff now built in. Yes it still has some nice features that aren’t in mainstream TF, but TF is diverging quicker than that value add IMO
Unpicking your terragrunt when it comes time to will likely be a headache
we have just started our TF journey … so I am playing around with a number of different approaches
The gruntwork TF testing tooling doesn’t support Terragrunt (yet at least), and they wrote it.
so what is the best way to do orchestration of multiple modules in todays landscape?
@joshmyers nice points, thanks
If starting a new project id certainly look at using geodesic over terragrunt
Not taking anything away from the gruntwork folks, it has helped me loads in the past keeping code dry
terragrunt is a nice tool, and we use it sometimes
But geodesic does similar, in a cleaner way IMO
there are a few patterns of doing it
take a look here https://sweetops.slack.com/archives/CB6GHNLG0/p1540514525000100
Although there are many possible ways of doing that, we use containers + ENV vars pattern.
As you mentioned, template rendering is another pattern (as implemented in terragrunt).
We store the ENV vars in either AWS SSM (secrets) or in Dockerfiles (not secrets).
Here are more details:
-
We have a collection of reusable TF modules https://github.com/cloudposse/terraform-root-modules. The modules have no identity, everything is configurable via ENV vars. (In other words, they don’t care where they will be deployed and how).
-
We deploy each stage (root, prod, staging, dev, testing) in a separate AWS account for security and better management
-
For each AWS account/stage (root, prod, staging, dev, testing), we have a GitHub repo which is a container (for which we use
geodesichttps://github.com/cloudposse/geodesic):
https://github.com/cloudposse/root.cloudposse.co https://github.com/cloudposse/prod.cloudposse.co https://github.com/cloudposse/staging.cloudposse.co https://github.com/cloudposse/dev.cloudposse.co https://github.com/cloudposse/testing.cloudposse.co
Not secret ENV vars are defined in the Dockerfiles, e.g. https://github.com/cloudposse/prod.cloudposse.co/blob/master/Dockerfile#L17 In other words, the account containers have identity defined via the ENV vars.
-
https://github.com/cloudposse/terraform-root-modules is added to the containers https://github.com/cloudposse/prod.cloudposse.co/blob/master/Dockerfile#L36
-
Inside the containers, users assume IAM roles ro access the corresponding AWS account and then provision TF modules.
-
Inside the containers we use
chamber(https://github.com/segmentio/chamber) to read secrets from SSM (per AWS account)
So when we run a container (e.g. prod), we already have all ENV vars setup, and we read all the secrets from the account SSM store.
An account/stage can be in any region (also specified via ENV var, e.g. https://github.com/cloudposse/prod.cloudposse.co/blob/master/Dockerfile#L14)
Take a look at our docs for more details: https://docs.cloudposse.com/reference-architectures/ https://docs.cloudposse.com/reference-architectures/cold-start/ https://docs.cloudposse.com/reference-architectures/notes-on-multiple-aws-accounts/ https://docs.cloudposse.com/geodesic/
And only using terraform itself is a huge plus. Trust me saying you don’t want to refactor the state machine for your infra.
What @Andriy Knysh (Cloud Posse) said
@joshmyers @Andriy Knysh (Cloud Posse) these are really good points
I like #6 we will need to look into this as well
yea, as we mentioned, terragrunt is very nice, but it’s another wrapper on top of TF, and wrappers, although solve many problems, always have their own issues
ya one can say the same thing about TF and CNF …
you can
I’m not sure how I feel about modules of modules as it is rabbit holes all the way down and finding where you are and passing in more vars then you want is a pain
but HashiCorp is big, well funded, and is in business for a long time
But that is more of a terraform shortfall than the tooling around it
one day they will be bought
I am not going against HashiCorp or TF, from what I have seen I really like it.
and it is the tool that we are going to be using moving forward …
I am just trying to understand the best way to setup my modules
See how far something like geodesic gets you and go from there. I’ve been using TF from the early days, orchestrated many ways and as of now, geodesic and what the cloudposse folk are doing is the best I’ve seen, especially around orchestration and reusable modules
You probably only need to write your higher level modules if you look at what you can pick off their shelf
roles-profiles-modules …brings be back a few years to my puppet days
Terragrunt gives you a slice of the pie, geodesic gives you the whole thing as far as orchestration, managing secrets, account separation, auditability
And if you have to unpick it, it’s just using normal stuff, no terragrunt magic
Kinda.
ya i am reading up on geodesic now
yea, we use geodesic everywhere, for many clients, and we support it
it’s not about our implementation per se, it’s about tooling and workflows, and not only for TF deployments - it supports tens of other tools including k8s, helm, helmfile etc.
and security (assume IAM roles to access AWS)
and account/stage/env separation (as @joshmyers mentioned)
@Andriy Knysh (Cloud Posse) are ya’ll using it with kops? Looks like it. How does TF generation fit in if at all?
Yea using it with kops
And EKS
Just to be clear, not using both kops and eks at the same time
and there’s no relation between kops and eks
Give me 5 minutes
Will show
oh it has eks support!!!
it is getting better now
Terraform module for provisioning an EKS cluster. Contribute to cloudposse/terraform-aws-eks-cluster development by creating an account on GitHub.
Terraform module to provision an AWS AutoScaling Group, IAM Role, and Security Group for EKS Workers - cloudposse/terraform-aws-eks-workers
Terraform module to provision Auto Scaling Group and Launch Template on AWS - cloudposse/terraform-aws-ec2-autoscale-group
Collection of Terraform root module invocations for provisioning reference architectures - cloudposse/terraform-root-modules
Collection of Terraform root module invocations for provisioning reference architectures - cloudposse/terraform-root-modules
Yup, seen those. Look good. Was specifically wondering more about the kops generating your terraform resources etc in particular, if that was a thing you had looked into.
geodesic does not include EKS support, you can use geodesic container to provision those
kops with geodesic:
-
Provision
kopsbackend and SSH keys https://github.com/cloudposse/terraform-root-modules/blob/master/aws/kops/main.tf -
Provision
kopscluster from the template https://github.com/cloudposse/geodesic/blob/master/rootfs/templates/kops/default.yaml
https://github.com/cloudposse/prod.cloudposse.co/blob/master/Dockerfile#L70
kops create -f /conf/kops/manifest.yml
-
Provision backing services in a VPC (whatever needed for a solution) https://github.com/cloudposse/terraform-root-modules/tree/master/aws/backing-services
-
Provision kops-vpc-peering https://github.com/cloudposse/terraform-root-modules/blob/master/aws/kops-aws-platform/vpc-peering.tf
-
Provision other
kopsresources https://github.com/cloudposse/terraform-root-modules/tree/master/aws/kops-aws-platform -
Provision
chamberresources https://github.com/cloudposse/terraform-root-modules/tree/master/aws/chamber (to store secrets in AWS SSM)
More info: https://docs.cloudposse.com/tools/kops/ https://docs.cloudposse.com/release/0.13.0/geodesic/kops/
^ high level overview
if anyone interested, we can provide more details
more details :
Provision the Kops cluster
We create a kops cluster from a manifest.
The manifest template is located in /templates/kops/default.yaml
and is compiled by running build-kops-manifest in the Dockerfile.
Provisioning a kops cluster takes three steps:
- Provision the
kopsbackend (config S3 bucket, cluster DNS zone, and SSH keypair to access the k8s masters and nodes) in Terraform - Update the
Dockerfileand rebuild/restart thegeodesicshell to generate akopsmanifest file - Execute the
kopsmanifest file to create thekopscluster
Change directory to kops folder
cd /conf/kops
Run Terraform to provision the kops backend (S3 bucket, DNS zone, and SSH keypair)
init-terraform
terraform plan
terraform apply
From the Terraform outputs, copy the zone_name and bucket_name into the ENV vars KOPS_CLUSTER_NAME and KOPS_STATE_STORE in the Dockerfile.
The Dockerfile kops config should look like this:
docker
# kops config
ENV KOPS_CLUSTER_NAME="us-west-2.staging.example.net"
ENV KOPS_DNS_ZONE=${KOPS_CLUSTER_NAME}
ENV KOPS_STATE_STORE="<s3://jexample-staging-kops-state>"
ENV KOPS_STATE_STORE_REGION="us-west-2"
ENV KOPS_AVAILABILITY_ZONES="us-west-2a,us-west-2b,us-west-2c"
ENV KOPS_BASTION_PUBLIC_NAME="bastion"
ENV BASTION_MACHINE_TYPE="t2.medium"
ENV MASTER_MACHINE_TYPE="t2.medium"
ENV NODE_MACHINE_TYPE="t2.medium"
ENV NODE_MAX_SIZE="2"
ENV NODE_MIN_SIZE="2"
Change directory to kops folder, init Terraform, and list files
cd /conf/kops init-terraform
You will see the kops manifest file manifest.yaml generated.
Run kops create -f manifest.yaml to create the cluster (this will just create the cluster state and store it in the S3 bucket, but not the AWS resources for the cluster).
Run kops create secret sshpublickey admin -i /secrets/tf/ssh/example-staging-kops-us-west-2.pub --name $KOPS_CLUSTER_NAME to add the SSH public key to the cluster.
Run kops update cluster --yes to provision the AWS resources for the cluster.
All done. The kops cluster is now up and running.
NOTE: If you want to change kops cluster settings (e.g. number of nodes, instance types, etc.):
- Modify the
kopssettings in theDockerfile - Rebuild Docker image (
make docker/build) - Run
geodesicshell ([staging.example.net](http://staging.example.net)), assume role (assume-role) and change directory tokopsfolder - Run
kops replace -f manifest.yamlto replace the cluster resources (update state) - Run
kops update cluster --yesto modify the AWS resources for the cluster
NOTE: To force a rolling update (replace the EC2 instances), run kops rolling-update cluster --yes --force
NOTE: To use kops and kubectl commands (e.g. kubectl get nodes, kubectl get pods), you need to export the kubecfg configuration settings from the cluster.
https://github.com/kubernetes/kops/blob/master/docs/kubectl.md
Run kops export kubecfg $KOPS_CLUSTER_NAME to export kubecfg settings.
You need to do it every time before you work with the cluster (run kubectl or kops commands, validate cluster kops validate cluster, etc.) after it has been created.
Geodesic is the fastest way to get up and running with a rock solid, production grade cloud platform built on top of strictly Open Source tools. https://slack.cloudposse.com/ - cloudposse/geodesic
Kubernetes Operations (kops) - Production Grade K8s Installation, Upgrades, and Management - kubernetes/kops
hi is anyone using terraform to deploy EKS/AKS clusters?
moring @btai! yep, we are…. have you seen the cloudposse modules?
~btw, let’s move to #terraform~
isnt this #terraform
hahaha
See above
We posted links to the modules
so i dont have a problem creating the modules
And working example which we provisioned
I was wondering how you are managing upgrades (kubernetes version, node sizes, etc) with zero downtime. the only solution i know of is redeploying a new cluster and doing a cutover
You should not have any problem :)
Ask questions if you have
That’s is not easy yet with EKS
With kops, no problem
yeah, so im not only on AWS but also in azure as well
and kops doesn’t have an azure solution (yet)
yea, terraform is not well suited for managing the lifecycle
we still use kops for managing k8s on aws
i see
there’s a tool by weaveworks attempting to be the kops of eks, but it’s not there yet
it doesn’t handle drain/cordon rolling updates like kops
so kops upgrades the cluster with zero downtime
yup
so i have a tentative solution that I can think of to automate the upgrade for me using just terraform
kops export kubecfg
kops replace -f manifest.yaml
kops update cluster
kops update cluster --yes
kops rolling-update cluster
kops rolling-update cluster --yes
mind if i run it by you guys?
just to get some feedback
yea, for sure - would like to hear
cool
the approach I’m thinking of would be to use blue/green node pools
how does Azure AKS handle that?
this is just a sample solution
# current running version
terraform workspace new kube-1.9.0
terraform apply -var 'kube-version=1.9.0'
# upgraded version
terraform workspace new kube-1.10.0
terraform apply -var 'kube-version=1.10.0'
# cutover process + testing
# destroy old cluster
terraform workspace select kube-1.9.0
terraform destroy
clean up old state file (kube-1.9.0)
the more robust solution would be to maintain a changelog of the cluster workspace so workspace: kube-v1 could be initial, workspace:kube-v2 could be upgrading node size (i.e. c4.large -> c4.xlarge), workspace:kube-v3 upgrades kube version from 1.9.0 to 1.10.0
let me know if that makes sense
(on the phone - will be back in ~20)
ok thanks!
hrm…. that’s a pretty cool notion
need to let that sink in for a moment.
basically, you’re suggesting using “workspaces” as colors for the worker nodes
on the surface that seems like a pretty elegant solution. there still should be a drain+cordon step, but in terms of provisioning the new worker pool this should work
- provision
terraform-aws-eks-clusterindefaultworkspace
- provision
terraform-aws-eks-workersinblueworkspace
… new release of kubernetes …
- provision
terraform-aws-eks-workersingreenworkspace
- drain cordon nodes in
blueworkspace, then destroy node pool. Something like this could maybe be done: https://github.com/dmathieu/dice
Roll all instances within a kubernetes cluster, using a zero-downtime strategy. - dmathieu/dice
not that you’d use dice, but the strategy is interesting.
Roll all instances within a kubernetes cluster, using a zero-downtime strategy. - dmathieu/dice
basically you can label nodes, and dice will then terminate them. so something similar can be done to label, cordon, drain nodes
ill definitely take a look into this
@btai
yep, i’ve used workspaces to deploy in multi-environment and multi-region and its worked really well using only one set of terraform files (keeping things dry)
the workspace pattern i usually use is {environment}_{region}
and you can use map variables to switch on the configs
for my aks cluster, it will have to be a special pattern something like {environment}_{region}_{kube-version}
How is that different of having two autoscaling groups inside one ‘workspace’ with specified seperated min/max controlled by a conditional ?
@maarten it’s a similar strategy, but this is more fluid
its similar
you don’t need to maintain 2 of everything
yep
i went with that route initially
you might need to have 2 GPU node pools, 2 high mem node pools, 2 high network node pools, etc
with workspaces, you can just have 1 of each, then have as many “colors” as necessary
Ok i see
the problem i ran into with the 2 autoscaling groups solution is when I tried to put it in a fully automated CI job, I realized i needed to maintain the state of which blue or green ASG was currently taking traffic
thanks @Erik Osterman (Cloud Posse)
At Lumo, we needed a way to easily update the AMI or other attributes on our EKS nodes with zero downtime. We do blue/green EKS Kubernetes node updates.
this is close to how i’d solve this in AWS, but I’m not allowed enough configurability in Azure
At Lumo, we needed a way to easily update the AMI or other attributes on our EKS nodes with zero downtime. We do blue/green EKS Kubernetes node updates.
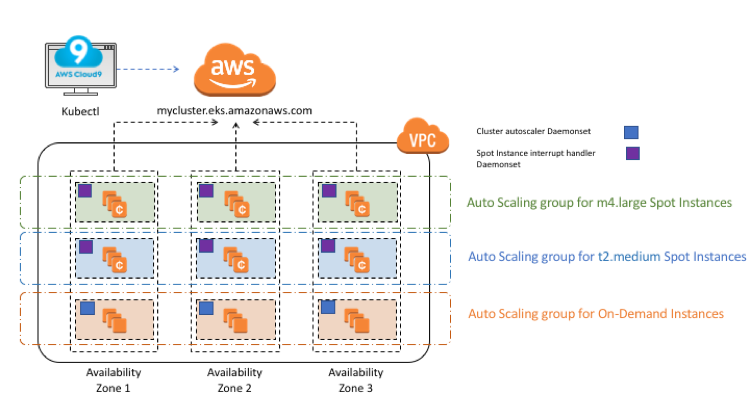
Contributed by Madhuri Peri, Sr. EC2 Spot Specialist SA, and Shawn OConnor, AWS Enterprise Solutions Architect Many organizations today are using containers to package source code and dependencies into lightweight, immutable artifacts that can be deployed reliably to any environment. Kubernetes (K8s) is an open-source framework for automated scheduling and management of containerized workloads. In […]
2018-11-02
If you have multiple ingress rules when creating an SG… for terraform, would I just created multiple ingress brackets
example:
Provides a security group resource.
but it doesnt have a good example of multiple ingress rules
@pericdaniel yes, you add multiple ingress rules
Terraform module for provisioning an EKS cluster. Contribute to cloudposse/terraform-aws-eks-cluster development by creating an account on GitHub.
and you need to (re)create the egress rule since TF deletes the default one https://github.com/cloudposse/terraform-aws-eks-cluster/blob/master/main.tf#L52
Terraform module for provisioning an EKS cluster. Contribute to cloudposse/terraform-aws-eks-cluster development by creating an account on GitHub.
or you can define them inline https://github.com/cloudposse/terraform-aws-rds-cluster/blob/master/main.tf#L12
Terraform module to provision an RDS Aurora cluster for MySQL or Postgres - cloudposse/terraform-aws-rds-cluster
Provides a security group resource.
but don’t mix the two ways in one module, and the first one (standalone resource) is preferred
yea i liked the inline cause it has it all laid out by the specific gorup
but standalone is better
sell me
sell me on the standalone
lol
maybe im misunderstanding somthing
b/c:
- in many cases it’s useful to expose the created SG to outside the module so you or someone else could add rules if needed (not possible if used inline)
- You can use
countsto enable/disable rules based on conditions (not possible inline) https://github.com/cloudposse/terraform-aws-eks-cluster/blob/master/main.tf#L64
Terraform module for provisioning an EKS cluster. Contribute to cloudposse/terraform-aws-eks-cluster development by creating an account on GitHub.
- Since it’s a separate resource, could be controlled separately from TF
but I agree, the inline case looks better
ah that makes sense… like if I add a port or rule… itll have to delete the whole sg and then recreate it rather then just adding that one rule?
AWS implementation of security groups has been done in a way that it’s very hard for Terraform to know if a security group rule reflects to an inline inside a security group resource or if it is a seperate security_group_rule resource. Everything works without problems as long as people don’t mix this up in Terraform.
@pericdaniel exactly
@maarten
yea it would be nice if terraform had some “I’m aware” capability
is the security_group_id = “${join(“”, aws_security_group.default.*.id)}”
joinining it to the the sg
it’s not about that, the problem is that most resources you create have unique identifiers, security group rules don’t.
it’s a splat + join pattern
since the SG uses count
if the SG is disabled (count=0), then `security_group_id = “${aws_security_group.default.*.id)}” would produce errors
b/c TF could not find it (it’s disabled)
so we join it with an empty string
if the SG is disabled, the whole expression just produces an empty string
if you don’t use count, you don’t need it
hmm
Embedded within strings in Terraform, whether you’re using the Terraform syntax or JSON syntax, you can interpolate other values into strings. These interpolations are wrapped in ${}, such as ${var.foo}.
since the SG uses count, it is a list, not a single resource
even if it has just one item (or it does not, if count=0)
does anyone here have a strong argument for using terraform remote state vs a data lookup to get information on resources in different accounts?
Good question. We do both. No specific “best practices” related to it right now.
i suppose it comes down to RBAC
to use remote state bucket, you need to grant full read access to that state file which may/may not expose secrets stored therein
while if you usse the data providers you can use IAM to gate access without exposing anything sensitive in the statefiles
yawp, we’re working to avoid secrets stored in state. In the end, we realized there’s little value generating IAM access keys with TF if it just puts secrets in the state, and they are hard^Wnon-trivial to rotate
Depending on situation, I’d opt for data sources rather than remote state. Use case where had different remote state for lots of things including a DR environment. If the main environment goes down due to AWS issues for example, you can’t terraform your DR environment if it relies on pulling state from S3 in a failed region
Have found a data lookup to be more reliable. Then again if you are working in a massive account which is constantly hitting API rate limiting even after AWS increasing, you may want the one hit request Vs potentially lots of data lookups
Which S3 are you using @joshmyers
I like Remote State, but learned to not chain remote states too much. Especially with Terraform updates this can be a huge pain. Pro’s of remote state is that the “master”- state only needs to have the information filled in ones and the “slave”- states are updated.
Using datasources one would still need to replicate data a bit as the datasources need to be addressed. For never changing information like vpc_id that is probably fine, but it works just as well with remote state. Matter of taste then.
Pulling in 5 different remote states during a run, mostly from different accounts, on top of the actual state file the main resources was a pain point.
I was joking a bit, but availability of S3 as argument for not using remote state is of course a bit far fetched no.
Not when you are building for the government and the entire point was for a DR scenario due to an entire regional outage.
Most situations, yes :)
ok wow, wouldn’t think something like that would happen. I remember one s3 outage 2 years ago in us-east-1 i think, but it was solved quickly and most of it was available.
Agreed, extremely unlikely but it has happened before and it was a scenario the client wanted a working DR environment.
AFAICR IAM policies on the KMS keys across a ccounts was also a pain when using the default KMS key. You couldn’t change the policy on the default key and we had strict policy limits like source IPs and MFA etx
oh yes, i think I’ve struggled with that once
also AWS did not have any good guide on that online
Yeah, lost a day or so to that one. Cloudtrail shows source IP being the correct one, so policy should have been OK. In fact the request was coming from another internal service was failing, despite cloudtrail showing otherwise
ah nice..
Still it’s quite cool that the US has something like GovCloud. Here in Europe governments are not so quick on moving to Cloud Services which are US HQ’ed.
So a lot of those projects end up on super expensive private clouds.
This is UK government. Large chunks of UK gov is on public cloud like Amazon these days
But yeah, the shitty private vcloud private clouds are shitty expensive
so you would resort to only using local state?
Some teams used git and git-crypt
git hosted on a private server?
Yup, gitlab/GitHub enterprise
is it still hosted in the cloud?
artifactory or consul for remote state works too
oh, interesting - didn’t know about the artifactory backend
Terraform can store state in artifactory.
have you used it? @btai
for terraform backend, no
but i wanted to throw that out there because remote state gives you state locking
2018-11-03
I am sure we have seen the integration of Terraform with Google Cloud Shell. I love this feature. You can read my blog about it. https://medium.com/@nnamani.kenechukwu/terraform-in-gcloud-shell-learning-infrastructure-automation-made-simple-7ef4a4300ec4

In the world of DevOps, automation is inevitable. We can automate anything and everything from the point of creating the application to…
2018-11-05
@nnamani.kenechukwu thanks for sharing, interesting article
woohoo! @Andriy Knysh (Cloud Posse) added serverless support to https://github.com/cloudposse/terraform-aws-rds-cluster
Terraform module to provision an RDS Aurora cluster for MySQL or Postgres - cloudposse/terraform-aws-rds-cluster
Just wondering have you heard anything regarding Mysql5.7 support for serverless
Terraform module to provision an RDS Aurora cluster for MySQL or Postgres - cloudposse/terraform-aws-rds-cluster
Not supported yet
And also not publicly accessible, only in a VPC
Problem The SSL policy is set to None by default. This means all versions of TLS, etc are supported and cannot be controlled. Solution Added a new loadbalancer_ssl_policy var Testing Tested with…
no clue why the commits bloated, but the files changed are legit
2018-11-06
@johncblandii thanks, merged to master
no prob
what are your thoughts on coupling your EKS cluster with a VPC, so when you do an upgrade to the cluster (spinning up a new cluster + cutover) you are also spinning up a new VPC with it
blue/green clusters+vpc?
yeah
that vs blue/green cluster within same VPC
my biggest concern with that would just be ensuring security groups are kept current and allow both VPCs
at a certain scale, would maybe be better to consider an active/active setup where you can take one cluster out of commission for upgrades
maintain two identical clusters at all time?
yes, but they don’t need to be scaled up equally
but i find that if something’s not in use, you don’t know until it’s too late what doesn’t work.
Some larger orgs I’ve worked at give you a vpc to operate in, nevermind all vpc setup like peering etc. I’d rather have that separated out
Is there a specific reason you’d want to do that?
2018-11-07
@joshmyers not a really good reason, the org im at currently follows that pattern (done with kops) which has worked for them
i personally gravitate towards how you feel which is why i brought up the question
we are actually going multi-cloud so I’m terraforming my azure clusters and its dependencies (vnet, subnets, etc) and I was debating whether to keep the same pattern vs doing the cutover within the vnet
vnet = azure’s vpc if youre unaware
How do you manage terraform codebases for the different providers?
Different runs, code, state files etc?
yeah
terraform repo with an aws sub-directory and an azure sub-directory
its different providers so the terraform code is completely different
but regardless terraform will allow us to manage multi-cloud infrastructure much easier
2018-11-08
hey guys, i’m having an issue when creating an EMR cluster using terraform… I have tried multiple things, none of them seem to stick
here is the error message:
* aws_emr_cluster.a: Error waiting for EMR Cluster state to be "WAITING" or "RUNNING": TERMINATED_WITH_ERRORS: VALIDATION_ERROR: The VPC/subnet configuration was invalid: No route to any external sources detected in Route Table for Subnet: subnet-05df0470906f7ce15 for VPC: vpc-046d66b0ac8496fcd
the interesting thing is, that if i run ‘terraform apply’ again, then it works
Race condition?
exactly
the networking dependencies have not yet been fully created
then it attempts to launch emr cluster prematurely
i have tried adding “depends on” statements
but no joy
tried moving the networking resources to the main.tf file, but that doesn’t seem to make any difference…
Terraform Version 0.8.8 Affected Resource(s) emr_cluster Terraform Configuration Files resource "aws_emr_cluster" "emr-cluster" { name = "${var.stack_name}-emr-cluster"…
Maybe?
wow — exactly my issue
but… i don’t see a solution
Without more info, hard to help
Use terraform apply -target module.vpc -target module.subnets to first provision the network
If these are disposable things you will be destroying and recreating often, it’s probably gonna bite again.
ok, thanks aknysh… that may work — i’ll give it a try
Or move the network files into a separate folder and provision it first. Then in EMR module look up the vpc and subnets, or use a remote state
so, in general practice, is it normal to provision some items first? and then run terraform apply again for the rest?
If you have those issues, yes
You can do it in three different ways: use target, lookup data source, or remote state
It happens but is not ideal. If depends on doesn’t fix it there is likely a race condition AWS end in creation of the resource from when you call create and it is ready. Generally resources like this need to support polling the API until a thing is ready
right — makes sense
i suppose there is not a way to add a “sleep” or increase timeout setting?
because i find that it if would just wait a few more seconds, then it would work
Yea, but not a good practice :). What if next time you need to wait for 7 seconds, but you have timeout only for 3
Terraform provides some primitives for this e.g. https://github.com/terraform-providers/terraform-provider-aws/blob/master/aws/resource_aws_dynamodb_table.go#L780-L799
Terraform AWS provider. Contribute to terraform-providers/terraform-provider-aws development by creating an account on GitHub.
p.s. I have no idea if that is the case for your route table resources etc as I haven’t looked into it
If this is a one off thing, @Andriy Knysh (Cloud Posse) suggestions are the way to go
If you destroy and re run this 10 times a day, that will get tiresome.
yes, agreed — i just ran the -target vpc and it worked
this is an OK workaround for now, i guess — but would prefer that i could run it just once
i will look into the other 2 options…
i can also share my emr.tf if you care to take a peek..
Are you seeing any of these error messages? https://github.com/terraform-providers/terraform-provider-aws/blob/master/aws/resource_aws_route_table.go#L129
Terraform AWS provider. Contribute to terraform-providers/terraform-provider-aws development by creating an account on GitHub.
no — the route table is simply updated
ah sorry, I probably misread
agree, all those workarounds are not ideal (better to just do terraform apply once). We had a few situations like this with complex module dependencies. So instead of spending days on trying to find a solution which might not even exists, just use -target
i use vpc module to create the initial artifacts, enable nat gateway, and then on my emr.tf I create a new subnet and add it to an existing route table
why not create a VPC and subnets first, and then in the EMR module just use them?
well i thought i did that by moving all of the networking resources to main.tf
but, yes i think creating the VPC first with a targeted approach makes sense
then run terraform apply a 2nd time…
works for me
yea i think that when you create a subnet and add it to the route table, it takes time. And then EMR wants to use the route, but it does not exist yet. If you create all subnets first and then use one of them for EMR, should work
agreed — thank you both for your input
separate topic:
i’m still trying to provision an internal load balancer from one of your modules, but not sure if that is supported
what module?
Hello, I recently started using your module and was able to create a new Elastic Beanstalk environment successfully. However, I need my load balancers to be internal facing only. I could not find a…
ah yea, not supported yet, we have an issue opened for that
ok — that’s fine
if you know how to do it, can open a PR?
uhm… not sure, i guess if i were to manually create the load balancer
but I’m relying on elastic beanstalk because of all of the automation that is included
but i’ll keep digging, maybe I can figure it out
need to add a few settings, one of them is
setting {
namespace = "aws:ec2:vpc"
name = "ELBScheme"
value = "internal"
}
Configure globally available options for your Elastic Beanstalk environment.
value = "internal" should be a variable
so we have already 4 settings in the aws:ec2:vpc namespace
need to add just this one
setting {
namespace = "aws:ec2:vpc"
name = "ELBScheme"
value = "${var.elb_scheme}"
}
ok, great — looks quite straightforward
thanks again for your help
2018-11-09
OK, so, Terraform.
Context: I have some infra (really mostly scheduled ECS tasks) that needs to repeat for multiple IAM roles (it’s auditing infra, each IAM role represents a role in an account with auditing privileges, each scheduled task is a kind of audit). It seems terraform won’t let me do that because no count in modules. Since cloudposse uses modules extensively, I’m guessing I’m not the first person to run into this problem. How do you solve it?
Right now I’m solving it by having another program generate terraform for me, which is the most go thing I’ve done this week.
@lvh sounds like generating TF files in this case is a good idea. What module are you using? Over what settings do you want to iterate? Maybe we could improve the module, or you could just use plain TF resources with counts
Well, our modules might not address this particular use-case, but that doesn’t preclude using modules
you might need some more specialized module that supports what you want to do
i’d need to see some more concrete code to visualize it (i’m more of a visual person)
i’d avoid the code generation for as long as necessary
is there one cloudposse module in particular you’re referring to?
terraform workspaces
if you want to use the same terraform module with different variables
@btai that could be used
Nah, it’s not a single module that’s causing problems, it’s an entire file with multiple resources + cloudposse modules in it
It has ECS tasks, scheduling, iam roles, etc etc
I also have an input set of IAM roles; I need to replicate the entire structure for multiple IAM roles – the obvious way to do that IMO would be to wrap the entire thing in a module and then have a count?
so at the very least, sounds like you want to wrap as much of that into a module for “business logic” and then invoke that N times
but of course, count still won’t help
on the “code generation” front, if you make each invocation a separate file e.g. “customer1.tf”, “customer2.tf”, then it should be easy to add N invocations and just doing a text-replace
if you want to do a screenshare, lmk
But I guess I can just write out the module calls explciitly
hrm… the approach @btai suggests might be interesting
anyone know if this may be easier in terraform 0.12? (the universal hail mary)
I like the @btai option, I guess @lvh has different customers to audit with different roles respectively. A workspace per customer sounds like a nice idea and scales easily. Wit a big variable map with the iam roles populated per customer makes it easy for the calling code to do a simple lookup.
@lvh i would use terraform workspaces with variable maps
module "some_random_module" {
source = "../../modules/some-random-module"
name = "${var.name_map[terraform.workspace]}"
}
variable "name_map" {
type = "map"
default = {
"customer_a" = "customer_a_name"
"customer_b" = "customer_b_name"
}
}
terraform workspace new customer_a
terraform workspace new customer_b
I do have multiple customers but each customer has separate IAM roles, because each customer has multiple accounts
i already have an AWS acct per customer though? so I guess I can do a … workspace per customer account
which seems annoying but ok it’ll work
thanks!
@Erik Osterman (Cloud Posse) and no, 0.12 won’t fix this because they’ve given up on making it work for resources and modules
oh really! have you seen them say that “count” has no ETA of ever making it into tf modules?
sorry I meant for 0.12; they claim to have laid a lot of the ground work for it? but it seems very very far away, and they already said 0.12 wont have it
just the comprehensions (maps, lists)
it might still happen eventually, but not any time soon
You should totally have different state files per customer if not already
Until 0.12 maps are good for what you suggest but only 1 level deep so no rich data there without nasty hacks
So I’d probably do a workspace per customer per env?
^ ++
for the time being ive been using the workspace to switch on multiple
{environment}_{region}
and then split the workspace on _
2018-11-11
212 votes and 105 comments so far on Reddit
2018-11-12
Anyone having issues with security groups with v0.11.10 ?
What sort of issues?
I think it’s more related to anton’s module, will deep dive later
is this a 0 -> -1 change?
yes
I wondered about that - an AWS API change? I had a similar one last week with something eles
maybe a change in the terraform aws provider? https://github.com/terraform-providers/terraform-provider-aws/blob/master/CHANGELOG.md#1432-november-10-2018
Terraform AWS provider. Contribute to terraform-providers/terraform-provider-aws development by creating an account on GitHub.
this look like the same issue? https://github.com/terraform-providers/terraform-provider-aws/pull/6407#issuecomment-437627440
Fixes #1920 Previously: — FAIL: TestAccAWSSecurityGroupRule_Description_AllPorts (21.74s) testing.go Step 2 error: Error applying: 1 error occurred: * aws_security_group_rule.te…
I asked a question over in #announcements concerning one of your terraform project, but am thinking this is probably the more correct place to do it. Should I move that question over here?
I’m attempting to peer a VPC in another region but get this error message
* module.cluster_to_vpn.module.vpc_peering.data.aws_vpc.requestor: data.aws_vpc.requestor: InvalidVpcID.NotFound: The vpc ID 'vpc-xxxxxx' does not exist
status code: 400
nah, we can just link it here
we’ve not tried to set up inter-region tunnels with that module
our use-case was to peer a backing services VPC (e.g. one with RDS, ElastiCache, etc) with a kops vpc
I suspect the reason it’s not working is that the module will need to have multiple providers so that it can reference two different regions
I feel like someone submitted PR for another module that does this, but I can’t find which repo that was in (it was not related to vpc peering)
(also, we implemented the module before inter-region VPC peering was possible)
(jumping on a call)
I see! thanks for the info. I will attempt to fork it and try it out.
This is similar to my use case as well, but I have additional VPCs, like a general infra VPC and a VPN VPC I need to peer as well (one of which is in a different region).
I am trying to use ELB health for the ASG instead of EC2 health check!
2018-11-13
Any VI users in the house? Give me your thumbs up https://github.com/scrooloose/nerdcommenter/pull/350
What Replacing the commenting delimiter from a ; to a # for the .tf-file extension. Why Autodesk Transcript Files are in popularity not anything near Terraform files and it is hard to find a single…
done
Done, I’ve been using https://github.com/tpope/vim-commentary for a long time and haven’t had any issues so far.
commentary.vim: comment stuff out. Contribute to tpope/vim-commentary development by creating an account on GitHub.
do you guys use any tools for autocompletion for terraform on vim?
A (Neo)Vim Autocompletion and linter for Terraform, a HashiCorp tool - juliosueiras/vim-terraform-completion
An honorable mention, not specifically for autocompletion but some other terraform nice to haves: https://github.com/hashivim/vim-terraform
basic vim/terraform integration. Contribute to hashivim/vim-terraform development by creating an account on GitHub.
exactly what i was looking for
basic vim/terraform integration. Contribute to hashivim/vim-terraform development by creating an account on GitHub.
enjoy! it’s been serving me well so far
2018-11-14
Hi everyone, i’m using https://github.com/cloudposse/terraform-aws-vpc-peering to setup peering connection between two vpcs
Terraform module to create a peering connection between two VPCs - cloudposse/terraform-aws-vpc-peering
the first time i run apply, everything is created correctly
the second time, terraform deletes routes on the two route tables of the two vpcs
the third, the routes are recreated , and so on
@nutellinoit it’s been a few months since we tested our implementation here https://github.com/cloudposse/terraform-root-modules/blob/master/aws/kops-aws-platform/vpc-peering.tf
Collection of Terraform root module invocations for provisioning reference architectures - cloudposse/terraform-root-modules
Terraform module to create a peering connection between a backing services VPC and a VPC created by Kops - cloudposse/terraform-aws-kops-vpc-peering
can you confirm that you use similar setup (we did not see the issue you described)
uhm
but maybe something changed in TF or other things
investigating the issue i think it’s related to another vpc module that i’m using, the one from hashicorp aws best practice
i’ll get in touch if this is the case
yea thanks. you can try our vpc module and see what happens
found it, the conflict is caused by inline base rule on the aws_route_table resource (like the 0.0.0.0/0 for the igw)
2018-11-15
2018-11-17
Is it possible to create a private dns route 53 address and resolve it as static website in web browser internally behind vpn with internal elb using terraform or cloudformation
2018-11-18
@Tee what problem are you trying to solve? Terraform / CF are just tools which talk to the AWS API. Is this possible via the API?
Yes. So i want a simple webpage that is only available behind vpn using internal dns. https://internal.example.com so when i open link in web browser i can see content only when connected to vpn. As it just internal route 53 private domain resolved behind VPN
@Tee I’ve responded to you in #aws
Thanks
2018-11-19
looks like my terraform state wasn’t saved. resources were created but they don’t exist in the state file. how do folks deal with a situation like this?
should i try an import?
sure
@mmarseglia There is also https://github.com/dtan4/terraforming for generating the state of those resources, which you can hack back into Terraform if you now have split state. Although this can mean hand mangling JSON, which you would rather avoid.
Export existing AWS resources to Terraform style (tf, tfstate) - dtan4/terraforming
thanks.. i’ll check that out and maybe try a terraform import
i’ve got the code written..it’s just a matter of getting terraform to recognize what it already did
i’m still wondering why it didn’t save.. if maybe i did an apply and then shut my system down before it could save
@mmarseglia Are you using remote state ?
i am
saving to an s3 bucket
Have you checked for a file “errored.tfstate”
in your root module folder
It should obey SIGTERM/SIGINT in a sane way and try and get the state stored. Did you end up with half a state, with some resources?
unfortunately i didn’t notice what was wrong, cleaned up by removing the .terraform directory, and tried applying again
so any errored.tfstate file is gone
errored.tfstate isn’t stored in .terraform afaik
oh.. maybe it’s still around then
i’ll look
my clean step is a rm -rf terraform/.terraform terraform/*.tfstate output.json inspec.json bucket
ah yeah, that’s quite rigorous
@joshmyers some resources are in the state file, there’s an IAM policy in there that was created
but others are not
Sometimes simpler than importing is to just delete everything which isn’t in the state and apply again.
i’ll have to reconsider that clean step
sounds like it’s too drastic
yep
do you need this thing that failed to build?
or can you destroy and re provision?
i think i can go through and delete the resources it created and didn’t save state for
that might be easier than an import
Have worked on codebases where a single TF run contains 500+ resources, not so easy to delete, hah. Filter by Terraform tag on resources and delete
this is why i need to tag things
Also there is a tradeoff between large state files (the collateral damage that a bad TF run could do) and splitting into tiny but related state, where you find yourself then having to run multiple times to pick up new changes etc. How to draw those dependencies?
that’s a tough problem.
Terragrunt has a kinda neat way of dealing with it
Terragrunt is a thin wrapper for Terraform that provides extra tools for working with multiple Terraform modules. - gruntwork-io/terragrunt
i like it
didn’t think about separate .tfvars for different environments. but that’s a good idea
right now i just run two environments, dev and prod, in separate AWS accounts
Isn’t ideal though as planning B doesn’t pick up changes that planning changes in A has done, because A’s haven’t actually been apply’d yet. AFAICR
that’ll be resolved once .12 comes out; modules get depends_on
Not things in different state though, no? Hence why it is important to try and split state on logical boundaries
maybe use something simple like Makefile to execute terragrunt/terraform in a required order?
Aye, that fixes half of that problem. Other half is harder because of state.
https://charity.wtf/2016/03/30/terraform-vpc-and-why-you-want-a-tfstate-file-per-env/ is quite old but lessons largely still stand
How to blow up your entire infrastructure with this one great trick! Or, how you can isolate the blast radius of terraform explosions by using a separate state file per environment.
hi all
whats the difference between https://github.com/cloudposse/terraform-aws-key-pair and https://github.com/cloudposse/terraform-tls-ssh-key-pair ?
Terraform Module to Automatically Generate SSH Key Pairs (Public/Private Keys) - cloudposse/terraform-aws-key-pair
Terraform module for generating an SSH public/private key file. - cloudposse/terraform-tls-ssh-key-pair
@i5okie the first one can generate a key and import it into AWS
the second one just generates a key-pair (does not touch AWS at all)
how does it import it into AWS?
nvm
Terraform Module to Automatically Generate SSH Key Pairs (Public/Private Keys) - cloudposse/terraform-aws-key-pair
2018-11-20
Trying to trial ecs-codepipeline, but as far as I see there is no example of what generates this https://github.com/cloudposse/terraform-aws-ecs-codepipeline/blob/master/main.tf#L234
Terraform Module for CI/CD with AWS Code Pipeline and Code Build for ECS https://cloudposse.com/ - cloudposse/terraform-aws-ecs-codepipeline
any pointers?
@pecigonzalo https://github.com/cloudposse/terraform-aws-ecs-codepipeline/blob/master/main.tf is using codebuild. Bigger context is https://github.com/cloudposse/terraform-aws-ecs-web-app/blob/master/main.tf which is using the codepipeline module.
Terraform Module for CI/CD with AWS Code Pipeline and Code Build for ECS https://cloudposse.com/ - cloudposse/terraform-aws-ecs-codepipeline
Terraform module that implements a web app on ECS and supports autoscaling, CI/CD, monitoring, ALB integration, and much more. - cloudposse/terraform-aws-ecs-web-app
Yeah, i know that part
I was checking aws-ecs-web-app
but the pipeline says codebuild will output a task
but I dont find any examples of in which format, if it expects the generated JSON or just a taskarn:version
etc
@pecigonzalo I can provide examples in about 2 hours
Yeah no rush! I was just curious/testing/playing around
@Erik Osterman (Cloud Posse) Dont mean to bother, but if you could show that example, it would be great
Hey! So hands are a bit tied by phone
This has the build spec example
We had another example in the chat history but unfortunately it’s over 10K messages ago
(We are working to exporting slack archive so we can link to these conversations)
Yeah no proble, maybe someyhing like Obie could work
Thanks
2018-11-21
I’ve just released it to the public! Now nice AWS diagrams created using cloudcraft.co can be exported to Terraform infrastructure code. Please try it and share with your circles. More details in my blog post - https://medium.com/@anton.babenko/modules-tf-convert-visual-aws-diagram-into-terraform-configurations-e61fb0574b10
I am excited to announce public-release of modules.tf — project which allows conversion of visual AWS diagrams created using Cloudcraft.co…
Wow @antonbabenko this is truly amazing!
I am excited to announce public-release of modules.tf — project which allows conversion of visual AWS diagrams created using Cloudcraft.co…
Thanks!
anyone using terraform to apply tags on vpcs/subnets? it looks like terraform does this destructively, so if any tag is created outside terraform, the tag is removed on next apply… any workaround for that behavior?
This is intended, you have a tag list, if it changes, terraform re-conciliates.
You can probably use ignore_changes to only apply initially and then forget about them.
That’s unfortunate. We’d like to be able to set mandatory tags (and manage those over time), and otherwise let users set their own
I dont believe this is possible, maybe lets wait for someone else
it’s kind of a pain… we have one user that wants to use kops, which wants to set tags on vpcs/subnets, but if we even set the Name tag, then terraform wipes out their tags
Why do they need to put manual tags?
different teams managing different parts of the environment… we generally setup the boundaries around the account access and network, but within that boundary we don’t care what they do
i didn’t mean to imply they were manually setting tags… they can do it however they want, it’s just not in this terraform config/state…
@Erik Osterman (Cloud Posse) i did make readme on the pull request https://github.com/cloudposse/terraform-aws-ecs-container-definition/pull/14#pullrequestreview-177052914
Hello, I needed mount points on container definition, so I added it
merged!
Hello, I needed mount points on container definition, so I added it
0.5.0
quick q. How can I count the size of multiple splitted values of a string , inside a map, inside a list.
[ {
env: "key1:val,key2:val"
somethingelse: "hello"
},
{
env: "key1:val,key2:val,key3:val"
somethingelse: "hi there"
}]
count =5
perhaps share with us what you want to achieve ? it might open up other possibilities
It’s work in progress @ https://github.com/blinkist/terraform-aws-airship-ecs-service/blob/f8df876804f41fd4673e8ad3a47068074ba39d00/modules/ecs_scheduled_tasks/main.tf#L146
I’m creating json which will be sent to a lambda. What I wanted to achieve is to have AWS style NAME VALUE pairs as JSON interpolated inside the task_defs datasource for the container_environment.
I wanted to use a null_resource and loop through the var.ecs_scheduled_tasks to create the name value pairs and refer to them from the task_defs datasource .
But as I control the lambda I can also just pass it through to the lambda and let the lambda figure it out.
Terraform module which creates an ECS Service, IAM roles, Scaling, ALB listener rules.. Fargate & AWSVPC compatible - blinkist/terraform-aws-airship-ecs-service
dammit
Terraform is not a proper language
There is probably a hack for it…dare I ask if 0.12 fixes this?
didn’t deep dive yet
doesn’t look like that nested loops work
from: https://www.hashicorp.com/blog/hashicorp-terraform-0-12-preview-for-and-for-each
for num in var.subnet_numbers:
cidrsubnet(data.aws_vpc.example.cidr_block, 8, num)
As part of the lead up to the release of Terraform 0.12, we are publishing a series of feature preview blog posts. The pos…
so maybe it does
Manage multiple provisions of the same Terraform scripts. - shuaibiyy/terraform-provisioner
I am not sure I understand this project I mean, do we need something like this for real?
Manage multiple provisions of the same Terraform scripts. - shuaibiyy/terraform-provisioner
Looks interesting
State file for terraform project state
Wow! This is like Helmfile for Terraform: https://github.com/uber/astro/blob/master/README.md
Astro is a tool for managing multiple Terraform executions as a single command - uber/astro
slick, i like it!
Astro is a tool for managing multiple Terraform executions as a single command - uber/astro
interesting alternative to terragrunt
i like that it’s more similar to other workflow automations i’ve seen in yaml
First of all, I love the direction of this utility. It's a generalized approach to orchestrated complex, multi-phased applies for terraform. It's a nice alternative to terragrunt that's…
couldn’t help it
i saw i use terragrunt all over the place at the moment, but this is certainly intriguing as an alternative
Dig it
Has anyone attempted vendoring terraform modules?
Not quite what I want: https://github.com/claranet/python-terrafile/blob/master/README.md
Manages external Terraform modules. Contribute to claranet/python-terrafile development by creating an account on GitHub.
Templating terraform has come up a few times. Was going through my stats and found this https://github.com/cbroglie/terrastache/blob/master/README.md
Use terraform variables and mustache templates to generate terraform configs - cbroglie/terrastache
@lvh
Use terraform variables and mustache templates to generate terraform configs - cbroglie/terrastache
A binary written in Go to systematically manage external modules from Github for use in Terraform - coretech/terrafile
This might be the tool we need to achieve some kind of vendoring with terraform
2018-11-22
hello, does anyone know how to edit an existing resource that belongs to another module (was created by another module) by terraform
I’m using github.com/cloudposse/terraform-aws-ec2-bastion-server and I want to edit the aws_security_group, I want to add the egress part to that.
# Main bastion
module "bastion" {
source = "github.com/cloudposse/terraform-aws-ec2-bastion-server"
name = "${var.name}"
ami = "${var.ami}"
instance_type = "${var.instance_type}"
# This key needs to be created beforehand
key_name = "${var.deploy_key_name}-${terraform.workspace}"
vpc_id = "${var.vpc_id}"
subnets = "${var.subnets}"
ssh_user = "${var.ssh_user}"
security_groups = []
namespace = "${var.namespace}"
stage = "${terraform.workspace == "staging" ? "staging" : "production"}"
}
resource "aws_security_group" "default" {
name = "${var.name}"
vpc_id = "${var.vpc_id}"
ingress {
protocol = "tcp"
from_port = 22
to_port = 22
cidr_blocks = ["xxx/32", "yyy/32"]
}
egress {
protocol = "tcp"
from_port = 22
to_port = 22
cidr_blocks = ["xxx/32", "yyy/32"]
}
depends_on = ["module.overblock_public_bastion"]
}
thanks.
i think you need only an additional egress rule on the bastion security group
2018-11-23
@loren and other #terragrunt users, I’d love to hear your feedback on terragrunt structure I generate when generating code from cloudcraft.co diagrams.
got an example repo?
@loren This is an example which was generated from the complete diagram mentioned in my blogpost (includes VPC, SG, and real dependencies)
i don’t see any issues with the terragrunt structure, very easy to follow
the dynamic values script idea is definitely brilliant/hacky
would maybe like to see it in python instead, to try to get some cross-platform support (easy to install python on windows as a prereq)
might be nice to pin the version for the source modules, also
and have an option in the generation to use https source urls
- dynamic values script worth dedicated blog post I consider externalizing it away to a separate repository and add bats-tests, or maybe rewrite it using devops-default-language (not python)
- modules sources as https and versions - yes, good idea. Isn’t
gitpreferred overhttps? I don’t remember
GitHub docs seem to indicate a preference for https, but I’m thinking mostly just that different teams have different standards, and the source url doesn’t support interpolation, so whatever you choose imposes constraints on the authentication mechanism for all users…
I don’t know that there is a “default” devops language… Golang could work instead of python, or node.js… Go can be annoying with its GOPATH requirements… makes it less portable when running from src. Of course, a compiled binary is perfectly portable, but not great for including in a git repo…
Also, looks like some movement on a feature in terragrunt that might support dynamic interpolation? https://github.com/gruntwork-io/terragrunt/issues/603
I would like to propose the following enhancement to terragrunt. My team and I have been using terragrunt for about a year now and we like the value it adds on top of terraform :) The issue I have …
Dynamic values you mentioned in this github issue are not exactly what I am doing with the shell script. Thanks for pointing to this issue!
I think Go scripts which compile and release would be great for portability. Thought I still don’t know how to run different scripts in terragrunt hooks based on type of OS. Lmk if you know.
My language of choice is python, which makes it easy. No need to run different scripts on different platforms, just handle the platform logic in the script. Ought to be able to do the same with any non-shell language
could you link to the post?
I am excited to announce public-release of modules.tf — project which allows conversion of visual AWS diagrams created using Cloudcraft.co…
Good idea, maybe a bit later, I really need people to try it and I can see errors in logs (much fewer than I expected really)
ID be happy to try it
It is free for all types of cloudcraft users
I'm working in South Korea, and our connection to fastly CDN is terribly slow (<100KB/s). Before 0.10.0, every provider plugin was bundled in terraform binary so it was fine, but It became p…
train + ipv6 = fail
or just BAHN = fehl
hahaha
It’s funny how it’s possible to have more or less working WIFI on airplanes, but crappy signal the moment a train goes faster than 100mph.
its great in the tunnels
im gonna be doing this trip regularly
might start building packetloss ands signal noise heat map
which trip is it ?
Berlin to Freiberg and back
long one cute city btw
Yea its a good 5-6 hour trip
beats the crap out of flying to Zurich and driving back in
at least on the train I can work
provided I dont need to download every thing
running tf locally ?
I hadnt planned it well
You can use terraform aws provider for plans locally, yes
cached to ~/.terraform?
Just hit Berlin, internet should get better
oh
in /localhost/
nice
Check my blogpost for arguments in provider - https://link.medium.com/zfM60Pfp5R

Working with Terraform on a daily basis I feel it can be a good idea to share some small tips I have. Let me start with this one.
so with skip_requesting_account_id to true, how does that affect say, aws_vpc ?
you can run “terraform plan -refresh=false” and terraform won’t perform API calls externally
2018-11-24
@antonbabenko I’ll check them out with our state and see the improvements because we are sending the apply times to CW for measurement.
Thanks!
Last time I checked it was reduced number of calls, but not speed improvement in first place. Let us know here, or leave a comment to the post and I will update it.
will do
2018-11-25
never thought I’d be doing this. But I’m using terraform to create an obstacle course of a broken AWS environment for an interview process. But it’s kind of fun.
that’s cool
Yeah. We’re finally expanding the team and I wanted a way to be able to reproduce a broken environment.
for testing purposes
having to reference my modules quite a bit without actually using them, as they’re all built with as much validation as I can put in them to prevent exactly what I’m building from happening
i’ve tried to write similar things for other languages. it can be tricky to come up with fair challenges.
one thing i’ve noticed is that technical domain expertise related to triaging “bugs” can be highly tied to an organization’s style of development
we had a developer on our team who was a very senior terraform guy
yet when it came to developing on our modules, the kinds of errors he ran into we’re new to him
not sure how to be express this. what i mean is that we see often the same kinds of errors for our stuff, which might not be the same kind of errors another company often sees. the “count of cannot be computed” is common for us. yet it seems (from my experience interviewing a lot of candidates) that there are sr terraform developers who are not familiar with this error, despite having written a lot of modules.
so… i am curious, what kinds of things do you want to test for?
so we’re not actually testing terraform
we’re testing AWS knowledge/troubleshooting
aha! i see what you mean
I considered testing terraform, but I ran into the same thoughts you’ve mentioned above
gotcha, so using terraform to “stage” an environment in a “broken” state
yep
are you creating a disposable org at the same time?
not at this point in time. It’s just a single account thing.
The role is a juniorish one
It’s our first time hiring for this role externally so we’ll probably adjust it as we go.
yea, plant a stake and start somewhere
But for now I’ve been told to avoid doing anything particularly nasty compared to some of the other obstacle courses I’ve made.
I made a linux based one where it kicks off a shutdown timer for 60 seconds when you login the first time. We don’t use it often, as we have tons of them, it’s mostly used for the people who are smug and try and throw their weight around in the interview process.
2018-11-26
Doh, just about to open a PR for the Terraform org CloudTrail stuff and appear to have been pipped by https://github.com/terraform-providers/terraform-provider-aws/pull/6580
Closes #6579 Changes proposed in this pull request: resource/aws_cloudtrail: Add is_organization_trail argument tests/resource/aws_cloudtrail: Add import TestStep to all acceptance tests and add i…
Pretty much same implementation, ah well
Pipped by 5 hours
Half a day I’m never getting back
Argh! That’s annoying….
It’s pretty amazing (generally) how fast this stuff gets contributed by the community.
Hi, is this the proper support channel for terraform-aws-kops-vpc-peering?
hey Ben, yes it is
Hi - We are looking to peer our Kops VPC to a VPC in another AWS account so pods can access services in the outside account. In looking for a way to codify the “routes” we had planned on adding manually, I came across your project. Few questions - why does namespace need to be specified. Where do we define the network ranges for which traffic to send over the peer? Why does a namespace need to be declared? Mulitple pods in multiple namespaces might be sending traffic to the peer. And what is stage?
the namespace in the module is not a k8s namespace. namespace+stage+name is our naming convention (how we uniquely name all AWS resources
for example, if you company is CloudPosse, then you can select the namespace as cp (or any other name you want)
stage could be prod, staging, dev, testing
name is your app/solution name
so, for production, you would select cp-prod-myapp to name all the AWS resources created by the modules
we use the label modules for that
Terraform Module to define a consistent naming convention by (namespace, stage, name, [attributes]) - cloudposse/terraform-null-label
Terraform Module to define a consistent naming convention by (namespace, stage, name, [attributes]) - cloudposse/terraform-terraform-label
Got it, what is the purpose of bastion_name masters_name nodes_name is it for identifying existing SGs/Roles?
here is an example on how we use it to peer the kops VPC with backing services VPC https://github.com/cloudposse/terraform-root-modules/tree/master/aws/kops-aws-platform
Collection of Terraform root module invocations for provisioning reference architectures - cloudposse/terraform-root-modules
we did not test it cross-account
https://github.com/cloudposse/terraform-aws-kops-vpc-peering/blob/master/variables.tf#L22 - masters_name is the subdomain name for k8s masters
Terraform module to create a peering connection between a backing services VPC and a VPC created by Kops - cloudposse/terraform-aws-kops-vpc-peering
(default to how kops names the masters and the nodes)
Does the module support peering with VPCs in different accounts? InvalidVpcID.NotFound
we did not test it, not sure what needs to be done for that (will have to take a look)
Thanks for the help!
np
the module does not support cross-account b/c it was created before it was added by AWS
you need to use new resources for cross-account https://www.terraform.io/docs/providers/aws/r/vpc_peering.html
Provides a resource to manage a VPC peering connection.
i recall with one of our clients we setup cross account VPCs. the downside was there was no easy way to “Autoapprove” (if i recall correctly)
so there was a manual step necessary to establish the tunnels
i’m going off vague memory here
you need to define two providers, one for each end of the link
provider "aws" {}
provider "aws" {
alias = "peer"
}
data "aws_vpc" "peer" {
count = "${var.create_peering_connection ? 1 : 0}"
provider = "aws.peer"
id = "${var.peer_vpc_id}"
}
resource "aws_vpc_peering_connection" "this" {
count = "${var.create_peering_connection ? 1 : 0}"
peer_owner_id = "${var.peer_owner_id}"
peer_vpc_id = "${var.peer_vpc_id}"
vpc_id = "${var.vpc_id}"
tags = "${merge(var.tags, map("Name", "${var.name}-${var.vpc_cidr}<->${var.peer_alias}-${data.aws_vpc.peer.cidr_block}"))}"
}
resource "aws_vpc_peering_connection_accepter" "this" {
count = "${var.create_peering_connection ? 1 : 0}"
provider = "aws.peer"
vpc_peering_connection_id = "${aws_vpc_peering_connection.this.id}"
auto_accept = true
tags {
Name = "${var.peer_alias}-${data.aws_vpc.peer.cidr_block}<->${var.name}-${var.vpc_cidr}"
}
}
you can also create routes on both ends, using the multiple providers… (though now i’m seeing i biffed the route table association and just grabbed one instead of iterating over the list)
resource "aws_route" "public" {
count = "${var.create_peering_connection ? 1 : 0}"
route_table_id = "${var.public_route_tables[0]}"
destination_cidr_block = "${data.aws_vpc.peer.cidr_block}"
vpc_peering_connection_id = "${aws_vpc_peering_connection.this.id}"
}
resource "aws_route" "private" {
count = "${var.create_peering_connection ? 1 : 0}"
route_table_id = "${var.private_route_tables[0]}"
destination_cidr_block = "${data.aws_vpc.peer.cidr_block}"
vpc_peering_connection_id = "${aws_vpc_peering_connection.this.id}"
}
resource "aws_route" "peer" {
count = "${var.create_peering_connection ? length(var.peer_route_tables) : 0}"
provider = "aws.peer"
route_table_id = "${var.peer_route_tables[count.index]}"
destination_cidr_block = "${var.vpc_cidr}"
vpc_peering_connection_id = "${aws_vpc_peering_connection_accepter.this.id}"
depends_on = ["aws_vpc_peering_connection_accepter.this"]
}
thanks @loren
you pass providers in when instantiating the module, like so:
module "pcx" {
source = "../pcx"
providers = {
aws = "aws"
aws.peer = "aws.peer"
}
// vars
}
2018-11-27
oh, and now we have a transit gateway option, looks to make vpc peering mostly obsolete? https://aws.amazon.com/blogs/aws/new-use-an-aws-transit-gateway-to-simplify-your-network-architecture/

It is safe to say that is one of the most useful and central features of AWS. Our customers configure their VPCs in a wide variety of ways, and take advantage of numerous connectivity options and gateways including (via Direct Connect Gateways), NAT Gateways, Internet Gateways, Egress-Only Internet Gateways, VPC Peering, AWS Managed VPN Connections, […]
Nice!
Im curious to see a cost comparison
Hi
so, the terraform-aws-elastic-beanstalk-environment module isn’t working for me right now. with load-balancer type set to “application” i get CREATE_FAILED
Creating load balancer failed Reason: Property HealthyThreshold cannot be empty
im testing it with adding the setting
@i5okie Do you have a gist of output or anymore info?
lost terraform’s ouput.
gah now its stuck in “invalid state” lol grrreat
Generally stayed away from EBS as it is a pain to debug. Black box.
for some of the beanstalk @johncblandii is probably the most senior!
he’s taken it above and beyond
hehe. More is coming too.
Ping me directly, @i5okie. I’ll see if I can help.
2018-11-28
yeah i can’t figure it out. I thought adding that one setting would help, but it didnt. ended up switching back to classic elb
probably some other settings are missing https://docs.aws.amazon.com/elasticbeanstalk/latest/dg/environments-cfg-alb.html
Use an Application Load Balancer to route application layer request traffic to different ports on environment instances based on the HTTP path.
Also, checkout https://docs.aws.amazon.com/elasticbeanstalk/latest/dg/command-options-general.html specifically the elbv2 ones might help. I remember running into issues as well and stuck with Classic.
Configure globally available options for your Elastic Beanstalk environment.
i think i just figured out why my user data file isn’t getting pushed to bastion, with the aws_ec2_bastion_server module..
there is a variable “user_data_file”. but it is not actually used anywhere else in the module lol.
you know how we can add propagate_at_launch = "true" to some of the resources but not all of them
. i see that we can use cloudposse/terraform-null-label
additional_tag_map = {
propagate_at_launch = "true"
}
but wouldn’t it add this to all the resources ?
and i am not sure about the side effects of adding this to all the resources
so i am trying to figure out how to add this tag only to the resources that need it
any help ?
hrm…. “wouldn’t it add this to all labels”
can you clarify/elaborate
oh, i think i gotcha
typo
updated it
so there’s a tags_as_list_of_maps output which uses those additional tags
this was something @jamie added to make it easier to add tag that only apply to certain resources (E.g. autoscale groups)
Terraform Module to define a consistent naming convention by (namespace, stage, name, [attributes]) - cloudposse/terraform-null-label
so the tags defined in additional_tag_map will only be applied when i call "${module.my_app.tags_as_list_of_maps}" and will not be applied when i call "${module.my_app.tags}" , correct ?
almost, but i think you got it reversed
so the tags defined in additional_tag_map will only be applied when i call "${module.my_app.tags_as_list_of_maps}" and will not be applied when i call "${module.my_app.tags}"
lol yeah
Terraform Module to define a consistent naming convention by (namespace, stage, name, [attributes]) - cloudposse/terraform-null-label
makes sense
this is great
i also see that there is another module called terraform-terraform-label
what’s the difference between these two modules ?
hi @rohit
terraform-terraform-label is a simpler version of terraform-null-label (before a lot of features were added to it)
for simple use-cases you can use terraform-terraform-label
@Andriy Knysh (Cloud Posse) i don’t think it has the feature he wants: tags_as_list_of_maps
those tags as list of maps are only for some AWS resources
@Andriy Knysh (Cloud Posse) makes sense. Thanks
is it possible to use string interpolation in both these modules ?
also, terraform-null-label supports a few additional features: 1) context; 2) var.environment
@rohit what do you mean by string interpolation? string interpolation can be used in any TF resource
i mean when using terraform-null-label, can i use something like stage = "${terraform.workspace}" ?
yes
nice
(it’s not related to terraform-null-label, you can do it with any module or resource)
i am fairly new to terraform and i noticed that there are some restrictions on where you could use string interpolation, count variable etc. so just wanted to confirm
aha
ah ok, yes you can use it as inputs to any module
but be aware of “count cannot be computed”!
good to know
so if i do something like this
tag_specifications {
resource_type = "instance"
tags = "${module.app.tags}"
}
in aws_launch_template resource and tags = ["${module.app.tags_as_list_of_maps}"] in aws_autoscaling_group resource, will it apply the tags twice ?
take a look how we do it here https://github.com/cloudposse/terraform-aws-ec2-autoscale-group/blob/master/main.tf
Terraform module to provision Auto Scaling Group and Launch Template on AWS - cloudposse/terraform-aws-ec2-autoscale-group
notice that we used terraform-terraform-label https://github.com/cloudposse/terraform-aws-ec2-autoscale-group/blob/master/main.tf#L2
Terraform module to provision Auto Scaling Group and Launch Template on AWS - cloudposse/terraform-aws-ec2-autoscale-group
and calculated tags_as_list_of_maps separately https://github.com/cloudposse/terraform-aws-ec2-autoscale-group/blob/master/main.tf#L61
Terraform module to provision Auto Scaling Group and Launch Template on AWS - cloudposse/terraform-aws-ec2-autoscale-group
because of the “count cannot be computed” issues with terraform-null-label when it’s used in some complex module hierarchies (not all)
it makes sense how you did it using terraform-terraform-label but if i use terraform-null-label, does my question above makes sense ?
well, i don’t think my question is related to using one vs other
yea, your question is related to how the tags will be applied to the EC2 instances if they are specified in both launch template and auto-scaling group
yup
so in your case what happens ?
we did not see duplicate tags
ok
how did you organize your modules ? was it based on apps or category ?
i am planning to do it based on category
modules/compute/app1,modules/storage,module/networking
and i noticed that some people do it by apps
yea, we have a pretty novel way of doing things.
just want to know how you did it
first as you see, we have a lot of modules. these follow the naming convention set forth by the terraform registry
then there are the invocations of these modules; basically, how we use these modules in concert with eachother
we call this our terraform-root-modules because they are the “root” module
Anyone can publish and share modules on the Terraform Registry.
then we pull in the root modules where we want to use them.
Example Terraform Reference Architecture that implements a Geodesic Module for an Automated Testing Organization in AWS - cloudposse/testing.cloudposse.co
notice we use docker for everything
this eliminates almost all local (or native) dependencies since we can bundle it in the docker image
e.g. terraform, chamber, aws-vault, etc
there are certainly a lot of ways to do things
here are our refrence architectures: http://cpco.io/reference-architectures
we are not using docker and i am not sure which one to pick from two approaches i mentioned
Also google #terragrunt and check out their reference architectures
heard a lot about terragrunt
but terraform is new to me and i didn’t want to learn a new tool on top of terraform
is there a reason why you didn’t use terragrunt ?
there are two main patterns to assemble everything together and provide variables:
- Template rendering (as done by
terragrunt)
- Using Docker containers + multi-stage images + ENV vars specified in Dockerfile (and in some secret storage as AWS SSM for secrets) - we do it with
geodesic(https://github.com/cloudposse/geodesic)
so we mostly use #2 as you can see in http://cpco.io/reference-architectures

@rohit to answer you question how did you organize your modules ? was it based on apps or category ?, it’s never that straightforward, we probably organize the modules by categories first https://github.com/cloudposse/terraform-root-modules/tree/master/aws
Collection of Terraform root module invocations for provisioning reference architectures - cloudposse/terraform-root-modules
@Andriy Knysh (Cloud Posse) i am planning to organize by category too
Is it possible to download userdata template from S3 ?
checkout this module: https://github.com/cloudposse/terraform-aws-user-data-s3-backend
Terraform Module to Offload User Data to S3. Contribute to cloudposse/terraform-aws-user-data-s3-backend development by creating an account on GitHub.
this is a nice pattern for offloading the user data to S3
unfortunately, this module is quite old and the documentation is ~poor~issing
the basic idea is inject user data which curls a resource on S3
Terraform Module to Offload User Data to S3. Contribute to cloudposse/terraform-aws-user-data-s3-backend development by creating an account on GitHub.
the example here looks simpler
Provides metadata and optionally content of an S3 object
that won’t overcome size limits
user_data = "${data.aws_s3_bucket_object.bootstrap_script.body}"
i forget the exact limit, but it’s low - like 16K
their example is solving a different use-case
perhaps some 3rd party generates a bootstrap script or you have a library of bootstraping scripts somewhere
but the problem remains that if the script is large, it will get rejected by the AWS apis
that’s true. there is always that size limit that we have to overcome
Is there a reason why your modules are not posted on terraform registry ?
or is that not part of your plan ?
i think you do have great modules and pushing them to terraform registry would be great, just a thought
oh yes! that’s our biggest traffic source
that’s good
i didn’t know that you had modules up there
we were so excited about it. the day it was announced we immediately started a huge initiative to rename all of our modules to follow convention and publish them on the registry.
awesome
i couldn’t find terraform-aws-user-data-s3-backend on registry
oh, crap
maybe we missed that one. i thought they were all there.
do you feel it needs any updates or just have to push it to registry ?
so the registry just pulls in realtime from github
we haven’t used it lately, so it might need some TLC
(we accept nearly all PRs after codereview)
i might be able to help if you can let me know what needs to be updated
oh, i think it’s in full working order - that’s the way we last left it
but it was many terraform versions ago, so things might have chagned
i don’t see any pins on terraform version
BTW, is this module used to download userdata from S3 or the opposite ?
both
i believe…
i think it will upload the user data to s3 and configure the user data script to pull it from s3
so it’s an end-to-end solution
hmmm. what i am looking for is a way to download the template already stored on s3
how did the template get to S3?
it was manually uploaded
in that case, you might just want to fork this module and create a new one
though my professional opinion is to avoid the “manual” part of that upload
i agree with you on the manual part
i guess i am debating whether to store the userdata template in the same terraform repo or just pull that template from S3
so the usecase here is, we use chef for configuration management and it needs few variables called roles,recipes,chef_environment which is different for different apps. All the other stuff is common across apps, so what we currently do is include a light weight userdata script as part of each launch template which in turn calls downloads the userdata store on s3 and passes the variables to that script
i hope my usecase makes sense to you
@rohit have done exactly this. In cloud-init we set the Chef dna JSON based on Terraform vars
Why not use the thing to automate putting the userdata to S3 in the first place?
definitely agree on automating the push to s3, and would recommend keeping the provisioning templates/scripts in source control along with the logic/automation for launching the instance
Note that you can also do multipart cloud-init for multiple scripts. Probably has been mentioned and obvs but one of the advantages of splitting out and keeping cloud-init minimal and having it call something else that does the heavy lifting, is that if you change the heavy lifting script, Terraform won’t want to immediately throw away all your infra because cloud-init changes force a new resource (unless using lifecycle stuff)
Very good point! A change to user data requires a new instance!
Always fun to roll your infra for a whitespace change
I assume @rohit has hit this problem every time wanting to add/change a node attribute
what i am looking for is a way to download the template already stored on s3
a reasonably nice and simple example is here; though the concept of error handling is missing:
@joshmyers do you mind sharing what you did in your project?
Don’t have that codebase anymore but it was pretty much what https://github.com/cloudposse/terraform-aws-user-data-s3-backend/blob/master/main.tf does
Terraform Module to Offload User Data to S3. Contribute to cloudposse/terraform-aws-user-data-s3-backend development by creating an account on GitHub.
Terraform puts an object in S3. Terraform knows your environment etc and likely other Chef node attribute type things. You nodes actual cloud-init is an upstart to pull said file from S3 and run it
How do you overcome the issue that i mentioned here https://github.com/terraform-providers/terraform-provider-aws/issues/6019 ?
Is there a way to set the latest computed version to be the Default value in resource aws_launch_template ?
@rohit are you asking about this https://github.com/cloudposse/terraform-aws-ec2-autoscale-group/blob/master/main.tf#L97?
Terraform module to provision Auto Scaling Group and Launch Template on AWS - cloudposse/terraform-aws-ec2-autoscale-group
@Andriy Knysh (Cloud Posse) what i currently have is
launch_template = {
id = "${aws_launch_template.app.id}"
version = "$$Latest"
}
we had that before as well
switched to the code here https://github.com/cloudposse/terraform-aws-ec2-autoscale-group/blob/master/main.tf#L97
Terraform module to provision Auto Scaling Group and Launch Template on AWS - cloudposse/terraform-aws-ec2-autoscale-group
and that would use whatever version is generated from launch template resource ?
yes
(don’t remember all the little details)
there is a PR open for this issue
Community Note Please vote on this issue by adding a reaction to the original issue to help the community and maintainers prioritize this request Please do not leave "+1" or "me to…
so i am not sure if this is the same issue people are facing
If anyone is getting ‘the value of count cannot be computed’ errors when using the null label module can you show me an example of where it’s used? I have recently been troubleshooting this and I have found some new cases where that error shows up when it normally wouldn’t.
Short answer being: if upstream dependant resources have an error, that error isn’t displayed and instead downstream computed values like count are broken.
2018-11-29
@jamie here is an example of that
we tried to use null-label here https://github.com/cloudposse/terraform-aws-ec2-autoscale-group/blob/master/main.tf
Terraform module to provision Auto Scaling Group and Launch Template on AWS - cloudposse/terraform-aws-ec2-autoscale-group
And when used, it gives the error?
Terraform module to provision Auto Scaling Group and Launch Template on AWS - cloudposse/terraform-aws-ec2-autoscale-group
sometimes or all the time?
all the time
Oh…. sorry i saw you respond
in under someone else
thanks, ill grab that and test it too.
thanks
Do you have an example code i can cut and paste or shall i just write a new one to use it?
To run the module
don’t have example with null label (did not save it), but should be in the github history I think
If i change that terraform-terraform-label to null-label it errors?
@Andriy Knysh (Cloud Posse)
and you need to use tags_as_list_of_maps from the label instead of https://github.com/cloudposse/terraform-aws-ec2-autoscale-group/blob/master/main.tf#L61
Terraform module to provision Auto Scaling Group and Launch Template on AWS - cloudposse/terraform-aws-ec2-autoscale-group
that’s the main part of the issue
@Andriy Knysh (Cloud Posse) I have something for you to test
Do you have an example handy to run the module?
with the error?
no sorry, it was a few months ago when I tested it
ahh you mean to run the updated module?
it’s our EKS modules
So in that module, i think the error stems to one particular thing
(maybe)
if i comment out
# iam_instance_profile {
# name = "${var.iam_instance_profile_name}"
# }
and run it
i get no errors… well.. apart from the example code having the min and max values around the wrong way..
variable "max_size" {
default = 2
description = "The maximum size of the autoscale group"
}
variable "min_size" {
default = 3
description = "The minimum size of the autoscale group"
}
Which when i swap them.. i don’t get any errors based on ‘count’
I’m heading to bed. But can you test this again when you have time to see if the error actually still happens for you?
I switched it to use the tagging as you said, and I’m not getting any errors (after commenting out the iam_instance_profile block)
Night
@jamie thanks
I’m busy with other things, but I’ll take a look
Also I’ll prepare a working (haha) solution for you using null-label that produces the count errors
Question: For terraform-aws-codebuild what is the buildspec variable? i have a buildspec.yml file in my repo. How do i configure my codebuild to use that?
Terraform module to provision an AWS AutoScaling Group, IAM Role, and Security Group for EKS Workers - cloudposse/terraform-aws-eks-workers
1 sec @Stephen
and it was throwing a lot of count can't be computed errors
that’s why we just added this https://github.com/cloudposse/terraform-aws-ec2-autoscale-group/blob/master/main.tf#L61 to calculate tags_as_list_of_maps separately
Terraform module to provision Auto Scaling Group and Launch Template on AWS - cloudposse/terraform-aws-ec2-autoscale-group
@Andriy Knysh (Cloud Posse) i think i got the answer from an issue re: that variable. It picks it up in the root dir during build if not set.
yep, also take a look here https://github.com/cloudposse/terraform-aws-cicd/blob/master/variables.tf#L59
Terraform Module for CI/CD with AWS Code Pipeline and Code Build - cloudposse/terraform-aws-cicd
Provides reference information about build specification (build spec) files in AWS CodeBuild.
one working example for this here https://github.com/cloudposse/jenkins/blob/master/buildspec.yml
Contribute to cloudposse/jenkins development by creating an account on GitHub.
jenkins gets built by https://github.com/cloudposse/terraform-aws-jenkins
Terraform module to build Docker image with Jenkins, save it to an ECR repo, and deploy to Elastic Beanstalk running Docker stack - cloudposse/terraform-aws-jenkins
Terraform Module for CI/CD with AWS Code Pipeline and Code Build - cloudposse/terraform-aws-cicd
Terraform Module to easily leverage AWS CodeBuild for Continuous Integration - cloudposse/terraform-aws-codebuild
@Andriy Knysh (Cloud Posse) It worked It just pushed my git repo project up to dockerhub?
Now to hook up the pipeline, and then webhooks i think. Then it will be EtoE
nice @Stephen
Your cicd example is GitHub -> ECR (Docker image) -> Elastic Beanstalk (running Docker stack) but i will need to replace ECR w/ Dockerhub.
let us know if you need any help
It looks like maybe i should have just used terraform-aws-cic instead. It looks like it has the Build and Pipeline together?
you can
i am trying to get the aws-cicd example to match with my existing pipeline configuration. What are the available options for Stage.actions.output.Artifacts?
as well as inputArtifacts
my live pipeline:
"outputArtifacts": [
{
"name": "BuildArtifact"
}
],
"inputArtifacts": [
{
"name": "SourceArtifact"
}
]
my new build stage in aws-cicd:
input_artifacts = ["code"]
output_artifacts = ["package"]
@Stephen it’s just names you select for the stages’ input and output artifacts, you can assign any names as long as you use the same name from the stage output to the next stage input
Represents information about an artifact to be worked on, such as a test or build artifact.
Represents information about the output of an action.
Terraform Module for CI/CD with AWS Code Pipeline and Code Build - cloudposse/terraform-aws-cicd
Ok, another question. i am pulling from a public GH repo but it seems like i am required to use a GITHUB_TOKEN for pipeline, even though the codebuild module worked fine without it.
yes, currently the module requires GitHub token (we used it for private registries) https://github.com/cloudposse/terraform-aws-cicd/blob/master/variables.tf#L33
Terraform Module for CI/CD with AWS Code Pipeline and Code Build - cloudposse/terraform-aws-cicd
you can add a token (even if you use only public repos)
Can we make the token optional?
i don’t remember if making the token optional will work here https://github.com/cloudposse/terraform-aws-cicd/blob/master/main.tf#L197
Terraform Module for CI/CD with AWS Code Pipeline and Code Build - cloudposse/terraform-aws-cicd
needs to be tested
@Stephen if you test it and it works, can open a PR, we’ll review promptly, thanks
Leaving it blank fails
can you test with any random string?
tried that, it then tried to auth
w/o string it complained about the config not correct.
yea, that’s why it’s there, for private repos
ya, it would be better if it were optional. Guess thats upstream issue?
for just public, the module needs to be changed to support that
it’s AWS API ‘issue’: you don’t provide a tokem, can access only public repos. You provide a token, it will try to auth even if you don’t want to use it
you can create a token with limited permissions and use it for now
also can you open an issue in the repo and explain that? thanks
How would i go about adding ENV vars to the pipeline->Build stage?
In my case, in my buildspec.yml I do a docker login with my dockerhub u/p
so i can push the docker image up
pre_build:
commands:
- echo Logging in to Docker Hub...
# Type the command to log in to your Docker Hub account here.
- docker login -u $DOCKER_USERNAME -p $DOCKER_PASSWORD
@Andriy Knysh (Cloud Posse) re: the token issue: https://github.com/terraform-providers/terraform-provider-aws/issues/6646
Community Note Please vote on this issue by adding a reaction to the original issue to help the community and maintainers prioritize this request Please do not leave "+1" or "me to…
you guys ever seen this before?
@i5okie Ya, i think you added the wrong stack name
I was originally using this solution_stack_name = "64bit Amazon Linux 2018.03 v2.8.6 running Ruby 2.3 (Passenger Standalone)"
64bit Amazon Linux 2018.03 v2.8.6 running Ruby 2.3 (Passenger Standalone) is valid.
and copied the config over for another account. and now its complaining wrong stack. so i changed the name to what is in the screenshot
ooh wait.. i think i know whats wrong
2.8.4 not found
i’ve changefd to 2.8.4 but didn’t change the date
hehe
four eyes is better than two
@Stephen re: env vars in codebuild
Terraform Module to easily leverage AWS CodeBuild for Continuous Integration - cloudposse/terraform-aws-codebuild
Terraform Module to easily leverage AWS CodeBuild for Continuous Integration - cloudposse/terraform-aws-codebuild
unfortunately, not propagated to https://github.com/cloudposse/terraform-aws-cicd
Terraform Module for CI/CD with AWS Code Pipeline and Code Build - cloudposse/terraform-aws-cicd
ya, i just added it to my local version
@Andriy Knysh (Cloud Posse) Getting this now during my EB deploy stage:
Deployment failed. The provided role does not have sufficient permissions: Failed to deploy application. Service:AWSLogs, Message:User: arn:aws:sts::xxxxx:assumed-role/xxxx-development-app/xxxxx is not authorized to perform: logs:PutRetentionPolicy on resource: arn:aws:logs:us-east-1:xxxx:log-group:/aws/elasticbeanstalk/xxxxx-dev-node-demo/var/log/nginx/error.log:log-stream:
Any ideas?
It needs access to cloudwatchlogs in order to create log streams and put retention policies on them etc
Did that resolve the issue for you?
I think it would be nicer to split out those perms into a more scoped form, rather than applying on every resource.
so yea, we did not use logs for our EB apps
@joshmyers Yes, i was able to Source, Build, and Deploy once i added that new action
Also had to add this as well:
thanks @Stephen will review and merge
starting on your webhook module now…
@Stephen reviewed https://github.com/cloudposse/terraform-aws-cicd/pull/36, thanks, just a few comments
How do i replicate the CodePipline UI where it connects to github and i tell it to use “webhooks” for the detection option?
@Stephen terraform-aws-cicd does not use webhooks, it uses this https://github.com/cloudposse/terraform-aws-cicd/blob/master/main.tf#L203
Terraform Module for CI/CD with AWS Code Pipeline and Code Build - cloudposse/terraform-aws-cicd
if you know how to implement it, we’ll accept one more PR (thanks again for the two PRs)
nope still
straight from > eb platform list -v
oh crap. its not letting me create a new environment with older stack. argh well this screws me over
lol. again.. stupid elastic beanstalk haha
Is it possible to create an rds postgres instance with multiple databases ?
Yes/no
You would use the Postgres terraform provider to provision the additional databases inside of the RDS instance
The AWS API for RDS does not enable additional databases (as in schemas) to be provisioned
is there any example that you use ?
No we don’t have an example
But there is one here https://www.terraform.io/docs/providers/postgresql/index.html
A provider for PostgreSQL Server.
thanks Erik
2018-11-30
I have used the postgres TF provider, it works okay
I would up scrapping it, because I still needed to do enough work after applying changes with it that it wasn’t worth using it in the first place