#terraform (2019-04)
 Discussions related to Terraform or Terraform Modules
Discussions related to Terraform or Terraform Modules
Archive: https://archive.sweetops.com/terraform/
2019-04-01
Today I tried the fixes that I thought were at the root of my CodePipeline/CodeBuild IAM issues, namely pulling out the ECR module so that it could be created before the pipeline was, but this didn’t actually solve the issue. Back at the same spot I was before.
I’m really not sure why the IAM logic inside of the CloudPosse ecs-codepipeline module is failing for me now.
what’s the error?
this is a working example of using ECS with CodePipeline https://github.com/cloudposse/terraform-aws-ecs-atlantis
Terraform module for deploying Atlantis as an ECS Task - cloudposse/terraform-aws-ecs-atlantis
the module gets called from here https://github.com/cloudposse/terraform-root-modules/tree/master/aws/ecs
Example Terraform service catalog of “root module” invocations for provisioning reference architectures - cloudposse/terraform-root-modules
i feel that you are missing the default backend app https://github.com/cloudposse/terraform-root-modules/blob/master/aws/ecs/default-backend.tf, that is created and deployed to the cluster before the CodePipeline starts building your app
Example Terraform service catalog of “root module” invocations for provisioning reference architectures - cloudposse/terraform-root-modules
@ldlework ^
I’m gonna think about all that
@Andriy Knysh (Cloud Posse) I’ve been going off this, https://github.com/cloudposse/terraform-aws-ecs-alb-service-task
Terraform module which implements an ECS service which exposes a web service via ALB. - cloudposse/terraform-aws-ecs-alb-service-task
And since I need a version that is not exposed by the ALB I have tried to edit it a bit
But now I am just trying to call it directly https://gist.github.com/dustinlacewell/a9cbe46d2ace7b71e2973ffb32531121 and Terraform is complaining:
* module.backend.module.service.aws_ecs_service.ignore_changes_task_definition: 1 error(s) occurred:
* aws_ecs_service.ignore_changes_task_definition: InvalidParameterException: Unable to assume role and validate the specified targetGroupArn. Please verify that the ECS service role being passed has the proper permissions.
oh
try to use this example https://github.com/cloudposse/terraform-aws-ecs-web-app/tree/master/examples/without_authentication first
Terraform module that implements a web app on ECS and supports autoscaling, CI/CD, monitoring, ALB integration, and much more. - cloudposse/terraform-aws-ecs-web-app
remove what you feel you don’t need later
I’m so screwed
this is just not working
I guess I should produce a minimal example
What’s a cloudposse module that uses the ecs-codepipeline module?
There’s one which uses the alb, ecr registry, container definition, the ecs task with alb, codepipeline, autoscaling, and cloudwatch in an example
but I can’t find it now
Race condition is not something I thought I would have to face down with Terraform
https://github.com/cloudposse/terraform-aws-ecs-web-app uses CodePipeline and ECR to deploy a web app to ECS
Terraform module that implements a web app on ECS and supports autoscaling, CI/CD, monitoring, ALB integration, and much more. - cloudposse/terraform-aws-ecs-web-app
Working example how to call it: https://github.com/cloudposse/terraform-aws-ecs-web-app/tree/master/examples/without_authentication
Terraform module that implements a web app on ECS and supports autoscaling, CI/CD, monitoring, ALB integration, and much more. - cloudposse/terraform-aws-ecs-web-app
@Andriy Knysh (Cloud Posse) Yeah that’s the one. I’ve basically tried to create a version of terraform-aws-ecs-web-app that does not expose the service via ALB and it has been a nightmare
Basically the part that really need changing is the module that it uses, terraform-aws-ecs-alb-service-task which has the ALB target groups baked in
terraform-aws-ecs-web-app is more or less an assembly module. It takes a bunch of other modules that do things, like terraform-aws-ecs-alb-service-task.
Best approach, imho, is to fork the module and change the bits that need changing (which can mean that you would need to fork terraform-aws-ecs-alb-service-task as well) and adapt it to your use case.
I ran into a similar issue yesterday as well, since I needed S3 instead of Github in the Codepipeline, for instance.
I’ve done this but I still get the issue I’m having.
Hello terraformers,
I am using this eks module and recieving this error
Error: module.eks_cluster.aws_eks_cluster.this: vpc_config.0: invalid or unknown key: endpoint_private_access
The module for eks https://github.com/terraform-aws-modules/terraform-aws-vpc
Terraform module which creates VPC resources on AWS - terraform-aws-modules/terraform-aws-vpc
hi @Vidhi Virmani
hi @Andriy Knysh (Cloud Posse)
ask in #terraform-aws-modules since you are asking about terraform-aws-vpc from https://github.com/terraform-aws-modules
Collection of Terraform AWS modules supported by the community - Terraform AWS modules
@Andriy Knysh (Cloud Posse) I narrowed it down. Check this out https://gist.github.com/dustinlacewell/0b049b6c7e9699362bf9a4a14cb11469#file-main-tf-L43 When I use the official CloudPosse task module, it works - no race condition. However, when I use my own module I get the race condition with the IAM role and the CodePipeline not being able to execute the CodeBuild step. But my modules is literally a clone of the cloudposse module with no changes
What the actual?!
Simply changing the source = line there causes the issue or not. How is this possible?!
Just as a reminder the error is:
Error calling startBuild: User: arn:aws:sts::607643753933:assumed-role/us-west-1-qa-backend-worker-codepipeline-assume/1554183144481 is not authorized to perform: codebuild:StartBuild on resource: arn:aws:codebuild:us-west-1:607643753933:project/us-west-1-qa-backend-worker-build (Service: AWSCodeBuild; Status Code: 400; Error Code: AccessDeniedException;
If I simply rerun the CodePipeline it runs successfully because the race condition is over.
The gist is basically the aws-ecs-web-app code with very little changes at all.
Minus the webscaling, and alerts
oh god what if the autoscaling and alerts somehow affect the dependency ordering
I mean, both the autoscaling and alerts refer to the ecs-alb-task’s service_name field the same way the codepipeline module does
The pipeline error should have nothing to do with the ECS related parts of the module.
I’ve wasted so many days on this lol
I used the module as is, just disabling the codepipeline part with the parameter and built codepipeline outside and still got the error.
When I use all the modules using git references, it all works.
When I clone the ecs-alb-task locally, and refer to it instead, I get the race condition
Always in the build step of the codepipeline, same error
Since it only occurred when first setting up the pipeline, I didn’t bother investigating, so unfortunately I don’t have a fix for you, ready.
Yeah it only occurs when setting up the pipeline, if you manually rerun it, it works.
It also works, when triggering the pipeline automatically from the source step.
Yeah
manual github webhook trigger or whatever
I’m pretty sure it is some kind of IAM race condition
Like Terraform is not deciding on the same dependency graph when those two lines in my gist are changed.
If I got time later today, I might have a look at it.
@mmuehlberger My personal goal is to just use what’s in the aws-ecs-web-app but without the ALB. I have containers that run just like my web containers but are queue workers that shouldn’t be exposed via ALB.
The whole point of the aws-ecs-web-app module is that it’s a “web app” and an opinonated implementation of how that webapp should work.
if you look at the module, however, you’ll see it’s composed by a handful of other modules
which is why it’s so easy to decompose and create your own opinionated version of what a web app should look like
our approach is not to make an individual module overly configurable, but instead make modules very composable.
so you can ignore me. i jumped in the thread too late.
yea… sorry!
I thought this would be so easy
It always looks that way and it never is.
do you think comparing the output between the two terraform runs might be useful?
I’d check where the permission is set and if there’s an explicit dependency missing. My best guess right now would be, that the policy is not set yet and codepipeline doesn’t wait for it. a depends_on would do the trick.
yeah just no idea on what
something in the task?
something inside the codepipeline module itself? (if so why does changing the task module screw everything up?)
I think that has to do with how Terraform unwraps the dependency graph internally. As I mentioned, I get the exact same issue, but with different changes.
@mmuehlberger oh neat terraform has a graph command
lol
I didn’t want to recommend it, because it does this with complex modules.
mother of god
So you’re pretty confident that it is not actually in the task module, but some non-determinism in the ecs-codepipeline module?
Yes, as the pipeline doesn’t touch ECS until the deploy step and everything is separated.
I noticed that the IAM roles use policy attachments.
Could it be that the codepipeline properly depends on the IAM role but not the attachment?
And so the role gets created before the pipeline, but not the attachment, which Terraform schedules afterwards?
Yes, that was my thought (without looking at the code).
Maybe simply adding a depends_on from the pipeline to all the policy attachments, it might work reliably.
2 am here though I’ll have to try in the morning.
I feel like I just ran into this race condition with policy attachments recently… Different resources and use case for me, but this is ringing a bell… Sometimes terraform’s parallelism gets the better of it :/
ahh, found it… a race condition with an instance profile… had the dependency on the role name rather than the profile name, but ec2 requires the profile to exist before trying to assign the instance profile…
while fixing that, discovered that the profile had no dependency on the policy attachment, so sometimes the instance would start spinning up and not yet have the necessary permissions
@loren do you think you could look at the ecs-codepipeline module to see if you see anything obvious that’s of similar form?
which specific module? (link) i’ve not used any of the ecs stuff, and seems like there’s quite a few repos
Terraform Module for CI/CD with AWS Code Pipeline and Code Build for ECS https://cloudposse.com/ - cloudposse/terraform-aws-ecs-codepipeline
There is some kind of race condition that causes the CodeBuild step of the CodePipeline to fail due to IAM permission failure.
I can get the exact error if that helps.
the only place i see aws_iam_role.default referenced is in the aws_codepipeline.source_build_deploy resource
so i’d say, yeah, if the error is in the pipeline, then try adding a depends block for the attachment to the pipeline resource
@loren Should I do it for each attachment?
As a matter of best-practice?
in this case i would list all attachments in the depends block, not sure i’d go so far as best practice yet
hahaha
like something is ordered differently maybe
2019-04-02
I think terraform got dumber. I got the error now a couple of times, but it should clearly be able to figure out the length of a static list module.chamber_database.aws_ssm_parameter.default: aws_ssm_parameter.default: value of 'count' cannot be computed.
Even this fails:
resource "aws_ssm_parameter" "default" {
count = "${length(local.parameter_write)}"
name = "${lookup(local.parameter_write[count.index], "name")}"
description = "${lookup(local.parameter_write[count.index], "description", lookup(local.parameter_write[count.index], "name"))}"
type = "${lookup(local.parameter_write[count.index], "type", "SecureString")}"
key_id = "${lookup(local.parameter_write[count.index], "type", "SecureString") == "SecureString" ? data.aws_kms_key.chamber.arn : ""}"
value = "${lookup(local.parameter_write[count.index], "value")}"
overwrite = "${lookup(local.parameter_write[count.index], "overwrite", "false")}"
allowed_pattern = "${lookup(local.parameter_write[count.index], "allowed_pattern", "")}"
tags = "${var.tags}"
}
yup
we threw in the towel on using an SSM module for writing to SSM
it just doesn’t work for anything but constant values
basically, writing things from .tfvars to SSM
writing things from any other module to SSM using a module :thumbsdown: (due to count of problems)
I get, when it can’t figure it out from dynamic values from another module and complex conditionals, but without a module, just a local list of params and the resource? How basic do I need to get?
At least it’s not that more repetitive to write them as one resource each.
Hi, i provision a EKS cluster with terraform-aws-eks-cluster/examples/complete everything work but i see that my worked nods have multiple private ip assign to them, is this normal?
Yes Vucomir, It is normal. AWS do the trick of assigning secondary IP addresses to Interfaces (ENI) in order to provide native VPC IPs to pods
so i got 10 secondary private ip’s on one mode
and 2 private ip’s
but i did not deploy anything in the cluster
AWS will have already deployed things like coredns, aws-node, etc. for you - so there’ll be some pods running already
According to the ec2 type, the aws eks reserves secondary IPs in advance
Thanks!
if i go with node ports in that case i would not need VPC ip,
sorry for all this question i just start with Kubernetes
This article discusses the trade-offs of aws eks networking https://www.weave.works/blog/aws-and-kubernetes-networking-options-and-trade-offs-part-3

In this instalment of Kubernetes networking on AWS, Mark Ramm, goes through the pros, cons and tradeoffs between VPC native networking vs implementing the VPC CNI plugin.
Thanks @Pablo Costa, will check it
You are welcome !!
@loren @Erik Osterman (Cloud Posse) @Andriy Knysh (Cloud Posse)
Is that better or worse than before?
It would fail instantly before.
Looks like it’s going to complete successfully. Thanks so much to all three of you again.
 1
1
lol
I kind of hate role attachments, but there isn’t yet a better option
Trying hard to get this pr merged, which would handle the attachment right in the role resource,https://github.com/terraform-providers/terraform-provider-aws/pull/5904
Fixes part of #4426 Changes proposed in this pull request: resource/aws_iam_role: Add inline_policy and managed_policy_arns arguments to aws_iam_role to configure role policies and fix out-of-band…
nice @ldlework
so FYI, if you have similar issues and you think it’s a race condition, the fastest way to test it without modifying a bunch of modules is to use --target to provision some resources first
@Andriy Knysh (Cloud Posse) @Erik Osterman (Cloud Posse) should I submit a PR?
please submit
ok
This adds a depends_on clause to the aws_codepipeline resource pointing to each aws_iam_role_policy_attachment. This avoids a race condition where the policy attachments are not yet available when …
released 0.6.1
I was going to submit a talk, but it seems it would boil down to “Use Cloudposse modules” for the most part.

 3
3It’s still happening…

sighs
how is that even possible
Here’s a cleaned up terraform log showing the order in which it did things: https://gist.github.com/dustinlacewell/1c5bfad4b91c3ced519727045588e74d
It looks like it created all of the policy stuff before the codepipeline
ARGH!!!!
wtf is going onnnn
Could the same problem be plaguing the codebuild module?
I added the depends_on to even the codebuild project inside the codebuild module linking to the policy attachments that it uses
And I still get the error
I’m starting to think Terraform is garbage…
It’s solving a realllllllllly hard problem in a generic way
the frustrating thing for me is that the workarounds often mean rearchitecting the terraform modules (combining them and not composing them) and that’s a non-starter
this is why I think the analogies to CSS are so good. you can do it all in CSS, but you end up have a TON of workarounds.
perhaps the problem is that we’re even trying to use HCL as a “programming language” rather than a “configuration”
and hashicorp should instead produce a tool like SASS to generate configurations.
(but I dn’t see that happening!)
So maybe it’s what it says, the assumed role user does not have permissions
Did you go to the AWS console and start the build manually?
@Andriy Knysh (Cloud Posse) If I click the “Release Change” and start the pipeline manually it works fine.
@Andriy Knysh (Cloud Posse) look at this gist which is a cleaned up log of the terraform application: https://gist.github.com/dustinlacewell/0162c8f06273fdefe5c534c3e5267fae
Lines prefixed with @@ show the policy attachment lines
Lines prefixed with !! show the pipeline and codebuild creation lines
It looks like everything is created in the right order?
Under which user do you login to the console manually and start the build?
My own user
It could have different permissions
I have used the policy tester though in the past
i know i’ve seen race conditions in things like s3 bucket policies, where i modify the bucket policy but then it takes a few seconds before it is effective (based on cli tests)
@Andriy Knysh (Cloud Posse) if I kick off the build via telling github to send the webhook that should be a real test right?
Is there any kind of waiter hacks I can do?
sleep in local exec
Like, run this waiter locally until the policy works for the thing
what a tire fire
I wonder if Terraform has a default parallelism I can turn off
yes
-parallelism=1
You can also switch the role in the console and test it manually under the real user
Shouldn’t we be able to deduce precisely which part of the terraform is responsible for this?
If it’s a permissions issue, it’s not terraform responsibility. You can give broader permissions to the created role and apply again
Give it admin permissions to test
@Andriy Knysh (Cloud Posse) What I meant is, the HCL responsible for setting up this permission, like identifying the bit that is supposed to give the right permission to the right role.
I’m not sure what IAM role or policy document etc is responsible for this particular failure…
And if I give it admin, will that even matter since it seems to be a race condition? It wont have admin in time.
That’s how you test if it’s a race condition or permissions issue
@Andriy Knysh (Cloud Posse) do you know which policy is the right one?
Give all four policies an admin permission and test
Also try running the pipeline from the cli, in debug mode. Might capture the permission failure better
like this ?
statement {
sid = ""
actions = ["*"]
resources = ["*"]
effect = "Allow"
}
Yes try it
@Andriy Knysh (Cloud Posse) do I need to add the principal or will omitting it allow any service to assume it or whatever
- aws_iam_role.default: Error creating IAM Role us-west-1-qa-backend-codepipeline-assume: MalformedPolicyDocument: Has prohibited field Resource
data "aws_iam_policy_document" "assume" {
statement {
sid = ""
actions = ["*"]
resources = ["*"]
effect = "Allow"
}
}
i’m going crazy lol
Specify resources
Learn the difference between identity-based policies and resource-based policies.
huh, it’s building on the first time
It should. We used those modules about 125 times and never saw the issues with race conditions (not saying they can’t be introduced by TF or AWS)
@Andriy Knysh (Cloud Posse) I suspect that it has something to do with how I’m wrapping your modules in my own modules. Like for my codepipeline, I call ecs-codepipeline and the cloudposse module for ECR as an example
And I had to fork the ecs task module so I can remove the ALB
Actually, I have zero idea
Because why would making the role an admin work
it makes one want to crawl under their desk and dissapear
Can I ask some general IAM questions about the ecs-codepipeline module? Is it creating one IAM role but attaching multiple policies? Like is one policy, the sts:AssumeRole policy, the policy that lets the CodeBuild service assume the role we’re creating?
and then the other policy documents that are attached describe what that user can do?
freaking magnets
how do they work?!
OK so I narrowed it down
data "aws_iam_policy_document" "codebuild" {
statement {
sid = ""
actions = [
"codebuild:*",
]
resources = ["${module.build.project_id}"]
effect = "Allow"
}
}
Changing the resources there to be "*" fixes the issue apparently.
Thoughts?
Is that project_id actually the arn? codebuild:StartBuild requires the arn…
arn:aws:codebuild:region-ID:account-ID:project/project-name
Describes the AWS CodeBuild API operations and the corresponding actions you grant permissions to perform.
It’s in the official version: https://github.com/cloudposse/terraform-aws-ecs-codepipeline/blob/master/main.tf#L164
Terraform Module for CI/CD with AWS Code Pipeline and Code Build for ECS https://cloudposse.com/ - cloudposse/terraform-aws-ecs-codepipeline

output "project_id" {
description = "Project ID"
value = "${join("", aws_codebuild_project.default.*.id)}"
}

It does seem to be the ARN…
Yeah, it ought to be the arn, https://www.terraform.io/docs/providers/aws/r/codebuild_project.html#id
Provides a CodeBuild Project resource.
There’s never any answers!!!
lol
I’ve redeployed a few times. It’s definitely the “*” for resources on that one policy.
Maybe look in the account and double-check that is the actual arn of the project, and that the policy lists that same arn
ok
OK I redeployed with the original code, and it failed as expected:

And here is the role, and attached policy with resource shown:

Thoughts?
The ARN in the error message, and the ARN listed in the policy are the same.
arn:aws:codebuild:us-west-1:607643753933:project/us-west-1-qa-backend-build
arn:aws:codebuild:us-west-1:607643753933:project/us-west-1-qa-backend-build
This looks like an aws thing, not so much a terraform thing….
There’s some permission getting used under the covers and the error message is obscuring the real error
Still recommend trying to run the pipeline from the cli, using a credential for that same role
Could it have anything to do with:

It’s really hard to create a restrictive IAM policy that doesn’t result in that message. I generally consider it a red herring
I see.
But, if you look at the codebuild IAM link I shared above, you’ll see that some actions do not support resource restrictions… So for those actions, the codebuild:* permission isn’t applying, because the resource attribute is not *
Delete, import, and some “list” actions, in particular
If the pipeline is, under covers, trying one of those actions, maybe list something or other, then it won’t have permission
Which would explain why it works when you change the resource to *
But not why this works for everyone else who uses the CloudPosse module as-is
¯_(ツ)_/¯
What’s the output of this?
output "project_id" {
description = "Project ID"
value = "${join("", aws_codebuild_project.default.*.id)}"
}
I just destroyed and am re-rolling so I’ll let you know if a bit
us-west-1-qa-backend-build
It actually looks like not a permissions issue :) and definitely not a race condition.
project_id = arn:aws:codebuild:us-west-1:607643753933:project/us-west-1-qa-backend-build
project_name = us-west-1-qa-backend-build
It just looks like wrong name
I’m not crazy!!!!
rejoyces.
Want a PR?
I’ll test first actually.
@Andriy Knysh (Cloud Posse) because how does the policy end up with the right ARN as the resource?
@Andriy Knysh (Cloud Posse) ecs-codepipeline does use the project_id
So I think it’s correct…
Helpful question stored to <@Foqal> by @loren:
I suspect that it has something to do with how I'm wrapping your modules in my own modules. Like for my codepipeline, I call ecs-codepipeline and the cloudposse module for ECR as an example...
I’m hedging on @loren’s explanation
You can extend the policy document to include a second statement for codebuild:List* with a resource of *
If that works reliably, good to go, got a viable min permissions policy
Are you using one AWS account or many? That assume role is in the same account?
Because it has nothing to do with the permissions. When you changed the ARN of the build project (by using * but still) it worked
Just one account.
@Andriy Knysh (Cloud Posse) but I showed with screenshots before that the ARN that ends up in the policy is the same one mentioned in the error
But of course it should be the same, otherwise you would not see the error :)
huh?
The policy gives codebuild access to the ARN of the project that shows up in the error complaining the policy doesen’t give it access
The error message was generated from the provisioned resources
That’s why the ARNs are the same
But isn’t the ARNs being the same what gives the service permission to do stuff to that resource?
I feel like I’m missing something big here
Are you using CP label module to name ALL the resources?
Check if namespace, stage and name are the same for all modules you are using
@Andriy Knysh (Cloud Posse) I haven’t changed any of the naming inside of the ecs-codepipeline module. I pass in a namespace, stage, and name to ecs-codepipeline but don’t change how it uses it.
Are you saying this needs to be the same across ALL resources across all CloudPosse modules in use?
Like when I call the container definition, the ecs-alb-task, etc?
(I don’t want to maintain a fork of ecs-codepipeline and so haven’t made any changes except the depends_on changes which were merged, and changing the resource to "*".
I just asked if you used the same namespace, stage and name for all resources and modules that you used in that particular project
No like, when I call a module, I pass in the aws_region as the namespace, the stage name as the stage, and the module name as the name
like I pass in “codepipeline” as the “name” to codepipeline module
I’ll try unifying everything
As far as I can see everything is already unified. I was wrong about changing the name parameter. I pass the top-level var.name all the way down. So everything is getting “backend” as the var.name
Share your complete code, we’ll take a look. Maybe something changed in TF or AWS, or maybe it’s a user/permissions issue (not the permissions from the module, but rather how it’s used)
@Andriy Knysh (Cloud Posse) https://gist.github.com/dustinlacewell/2ae006f32c2c0cd075dbaaf031b75349
Let me know if you want me to add something else
qa/main.tf calls fargate-alb-task/main.tf calls my ecs-codepipeline/main.tf calls CloudPosse ecs-codepipeline
It is basically the ecs-alb-web-app module, with each layer, vpc, aurora, elasticache, alb, ecs, and each of the ecs services implemented as a layer module
each layer module usually calls out to CloudPosse modules - like my ecs-codepipeline module calls both the CloudPosse ECR and CodePipeline modules
stage -> layer -> component -> cloudposse/resources
so the qa stage has a layer called “backend” which is an invocation of the “fargate-alb-service”, which calls a number of my own component modules like “container” “ecs-alb-service” and “codepipeline”. My component modules usually compose a few cloudposse modules and resources.
I should rename my codepipeline module to something like cicd or pipeline
I guess one thing I wonder is whether you guys would accept a patch that allowed you to override the resource value?
This would allow me to move on without having to fork codepipeline for that
So we’ll take a look a little bit later
The problem with using * for resources is a security hole
for the record, here’s what i was trying to get at (while only on my phone last night)…
data "aws_iam_policy_document" "codebuild" {
statement {
sid = ""
actions = [
"codebuild:*",
]
resources = ["${module.build.project_id}"]
effect = "Allow"
}
statement {
sid = ""
actions = [
"codebuild:List*",
]
resources = "*"
effect = "Allow"
}
}
so basically the same, “write” actions still restricted to the project, but the “list” actions would now work
If the issue is just the missing list action, then yes. It needs to be tested
certainly
It gives permissions for all codebuild resources
Yeah I understand. No one would have to use that option to override the resource as “*” though.
These permissions are already pretty loose, https://github.com/cloudposse/terraform-aws-ecs-codepipeline/blob/master/main.tf#L71
Terraform Module for CI/CD with AWS Code Pipeline and Code Build for ECS https://cloudposse.com/ - cloudposse/terraform-aws-ecs-codepipeline
2019-04-03
Hello there! Where i can find some references to cloudflare terraform modules
how can I convert
> replace(replace(replace(replace("m1.xlarge,c4.xlarge,c3.xlarge,c5.xlarge,t2.xlarge,r3.xlarge","/^/","{ \"InstanceType\" :\""),"/,/","\"},"),"/$/","\"}"),"/,/",",{\"InstanceType\": \"")
{ "InstanceType" :"m1.xlarge"},{"InstanceType": "c4.xlarge"},{"InstanceType": "c3.xlarge"},{"InstanceType": "c5.xlarge"},{"InstanceType": "t2.xlarge"},{"InstanceType": "r3.xlarge"}
into
[{ "InstanceType" :"m1.xlarge"},{"InstanceType": "c4.xlarge"},{"InstanceType": "c3.xlarge"},{"InstanceType": "c5.xlarge"},{"InstanceType": "t2.xlarge"},{"InstanceType": "r3.xlarge"}]
and still be able to use it in Cloudformation looks like the } is the issue with the CF template
@tallu you want to convert the string to a list, or just replace the chars?
April 3rd, 2019 from 11:30 AM to 12:20 PM GMT-0700 at https://zoom.us/j/684901853
I’m going to hang out in this zoom for a little bit in case anyone has any questions.
I want to convert string or maybe list "m1.xlarge,c4.xlarge,c3.xlarge,c5.xlarge,t2.xlarge,r3.xlarge" to json
[{ "InstanceType" :"m1.xlarge"},{"InstanceType": "c4.xlarge"},{"InstanceType": "c3.xlarge"},{"InstanceType": "c5.xlarge"},{"InstanceType": "t2.xlarge"},{"InstanceType": "r3.xlarge"}]
that’s quite easy. use smething like this
format("[%s]", join(",", formatlist("{\"InstanceType\": \"%s\"}", split(var.list)))
i haven’t tested that and might have bungled something small
but if you look at the interpolations for terraform, you’ll see where i’m coming from
thanks let me give it a shot
~the output seems to be working but something in that is making Cloudformation fail~evermind it seems something else
Does anyone have any information on how to establish a registered domain name (say on GoDaddy) with AWS via Terraform?
I’ve never done Route53 anything before.
Terraform module to easily define consistent cluster domains on Route53 (e.g. [prod.ourcompany.com](http://prod.ourcompany.com)) - cloudposse/terraform-aws-route53-cluster-zone
@ldlework that module is used to create a zone with delegation
to create a zone in Route53 https://github.com/cloudposse/terraform-aws-route53-cluster-zone/blob/master/main.tf#L52
Terraform module to easily define consistent cluster domains on Route53 (e.g. [prod.ourcompany.com](http://prod.ourcompany.com)) - cloudposse/terraform-aws-route53-cluster-zone
What about the second-level-domain, like “example.com” how do I initially set that up with Route53? Or can I do that with the cluster-zone module?
then get the name servers from the output and update NS records in GoDaddy
What if I want to use AWS for the DNS?
Like I’m trying to migrate a domain from GoDaddy to completely managed by AWS with Terraform as much as possible.
the root name servers are where you buy the domain itself
it can be transfered right?
so if you buy it on GoDaddy, you can’t use the root NS on AWS
if you buy the domain in Route53, then yes
transfer too
OK, so that step has to be manual. But once the domain is “owned” by AWS, then I can create zones and stuff with Terraform.
yes
https://github.com/cloudposse/terraform-aws-route53-cluster-hostname - to create dns records
Terraform module to define a consistent AWS Route53 hostname - cloudposse/terraform-aws-route53-cluster-hostname
Not sure if this is what was being asked, but, 2 things:
- you can manage the DNS in a different place to where you buy the domain, if you want
- Terraform can’t manage Route53 domain registrations/management; just the DNS side of things
you can create zones and records with TF even if you have not transferred the domain yet
it just will not be visible on the internet
I don’t know about GoDaddy, but many Registrars let you use different Nameservers including Route53.
(if you buy the domain on GoDaddy, you have to update the name servers there to point to the AWS NS)
(unless you transfer it to Route53)
OK so it seems like just having the domain’s DNS point to route53 for now is fine and I’ll be able to build out the infrastructure just fine with that setup
thank you
yes, create the zone, get its name servers, update them in GoDaddy, then you can create records in the Route53 zone
also, you will be able to request SSL certs with domain validation only after you update the NS records in GoDaddy
(in other words, ROOT NS records can be updated in the DNS system only by the entity that sold you the domain, or you transfer it to)
We have a single AWS account, and I’m going to be running QA in us-west-1 and Prod in us-east-1 (for the foreseeable future) does it make sense to have some Terraform that is not part of our “environment deployments” that sets up the zone for the dns in a “global-y” way sort of how I’m doing for the initial terraform state?
@ldlework If you still need to setup QA, I would personally opt for a new account and sticking to the same region.
I asked and was denied.
Ugh, why, can I ask ?
We’re a poor startup, far behind schedule, lead by a young inexperienced slightly petulant guy who makes random decisions that can’t be rationally accounted for.
Having seperate accounts is actually part of the AWS Well architected framework
Trust me, its not even close to the most mind-bending thing I have to deal with.
I agree, I’m fully on board.
and does not cost more, actually less if you have support on one account and no support on the qa account ( not sure if this still is the case)
good luck with that anyway, what i do in certain situations is to give prod and dev their own hosted zone
you get a hosted zone, and you get a hosted zone, and you get a hosted zone…
haha
here you go
yaaaaas
The point is you don’t have to convince me, I’m already convinced. I gave many more reasons too.
I see.
dev.domain.com prod.domain.com or more obfusicated, and have terraform setups to maintain those hosted zones
what about “domain.com”
clearly for domain.com and www.domain.com you would need to create an alias to the existing record in prod.domain.com
so I can’t use “domain.com” instead of “prod.domain.com” ?
you can do this (fewer reasons to convince the boss :
[domain.com](http://domain.com)is the vanity domain, the brand (the business owns it)
@ldlework you can , you can have multiple zones in your route53
one for domain.com ( with IN NS records delegating sub domains to different authorative nameservers AKA the other hosted zones you are going to make )
one for dev.domain.com
one for prod.domain.com
- You buy
[domain.io](http://domain.io)in Route53 and use it for all service discovery
- Create
[prod.domain.io](http://prod.domain.io),[staging.domain.io](http://staging.domain.io),[dev.domain.io](http://dev.domain.io)subdomains for your environments
- Then in
[domain.com](http://domain.com)zone, add CNAME to[prod.domain.io](http://prod.domain.io)(this could even be on GoDaddy if the business does not want to move or update it)
^ you separate the business-related stuff from the infra stuff
It makes a lot of sense.
So for a given domain, I have to extract the nameservers from something in Route53 and add them to GoDaddy. Do I extract the nameservers from the zone’s that are created with Terraform? Do I have to do this for each zone or just one?
(You can tell how I’ve never done any of this before)
just for one “root” zone (domain.com)
get its name servers and update in GoDaddy
You don’t think I should manage this indepdendently from environments?
Well you do, you said get two domains, but I only have one for now.
you have two cases here: 1) update the vanity domain NS in GoDaddy and then create all subdomains in the same Route53 zone
2) do service discovery domain and subdomains, and then add CNAME to the vanity domain
Can’t I add one root zone with some side-Terraform for “domain.com”, get the NS from it, add those to GoDaddy. Then in my deployments create a per-deployment zone for “prod.domain.com” “dev.domain.com” etc, which point to that environment’s resources, using remote data resource to get a referencce to the root zone id or whatever? Then I could have some kind of CNAME in the root zone pointing at the “prod.domain.com” record in the prod-specific zone?
So that “domain.com” resolves to “prod.domain.com”?
that’s what we do
it could be in one AWS account, or in multiple (in which case we do DNS zone delegation, which is to say we add NS records from [prod.domain.io](http://prod.domain.io) to the root zone [domain.io](http://domain.io) NS )
OK cool, so first step, write some side-terraform to setup the root zone for “domain.com” and get that configured with GoDaddy. Then I can update my deployment HCL, to get a reference to the root zone, to add a deployment specific zone on a subdomain. I guess I’ll have to hand-add the record pointing from “domain.com” to “prod.domain.com” or something.
Since it seems like a circular reference kinda.
if you with CNAME, those should be diff domains
OK so I’ll need some other kind of record in the root zone then?
Or are you saying with a single domain, I should only have one zone, but each deployment adds records to it?
argh, I should probably just start and a lot will be clearer on the way maybe
see the use-cases above ^
OK
( one side note, for the apex record, not www. , just domain.com CNAME’s don’t exist, but aws has ALIAS A records which achieve the same thing )
that’s why it’s always better to buy a vanity domain in Route53 or transfer to it
1) update the vanity domain NS in GoDaddy and then create all subdomains in the same Route53 zone 2) do service discovery domain and subdomains, and then add CNAME to the vanity domain
So I guess I have to go with 1)
Which means just one zone…
OK I’ll give it a go!
Oh you guys were saying that I can use multiple zones, one root zone, multiple staging zones, if I add NS records to the root zone pointing to the staging zones.
right?
Which is what I’ll want because I’ll need things like “db.dev.domain.com” so I do need per-stage zones, not just per-stage records in the root zone.
yes
you can use a separate zone per environment
add its name servers records to the root zone NS for the corresponding sub-domain
excellent
we already had a similar discussion with all the examples here https://sweetops.slack.com/archives/CB6GHNLG0/p1552667297261900
I haven’t yet had a chance to try this, but it was on my mind.
Using Geodesic across multiple AWS accounts for each stage, I have Route 53 records to create.
I have one domain name: acme.co.uk
I own [acme.co.uk](http://acme.co.uk).
I have [acme.co.uk](http://acme.co.uk) NS pointing to my ROOT account.
Scenario:
I have to create r53 records, say [test.acme.co.uk](http://test.acme.co.uk).
Naturally I want to create this on my testing account.
I want this r53 record to be public. Naturally this means the testing account needs to have an [acme.co.uk](http://acme.co.uk) r53 public zone… but wait… I already have a public zone for this in ROOT with the public NS pointing to ROOT account.
Problem: Is this possible? Or to have public records for my one domain, must I assume a role into my ROOT account and only create public records there?
aws_route53_zone.root: error deleting Route53 Hosted Zone (Z1I50I6TDQ378M): HostedZoneNotEmpty
oh god
first with s3 buckets, now zones
AWS, and by extension terraform, protecting you from yourself
yeah deleting a zone is definitely something you almost never do outside of testing…
How does one install a third party provider from git?
Without manunally cloning it, etc
oh you can’t
If the third party provider publishes packages for your platform, then you can download that and place it in the same directory as your terraform binary
But if they don’t publish packages, then you need to build it yourself
Yeah I was hoping that there was a mechanism to tell terraform where to get the binary package from like there is with terraform modules
Unfortunately not
Though, modules don’t need to be built, so, not surprising really
neither do binary packages
Well, exactly
Modules are not binary packages, they are just straight source code
I get it.
You guys ever get stuff like
module.backend-worker.module.cicd.module.pipeline.module.build.aws_s3_bucket.cache_bucket: aws_s3_bucket.cache_bucket: error getting S3 Bucket Object Lock configuration: RequestError: send request failed
caused by: Get <https://us-west-1-qa-backend-worker-build-dnwylutrpukx.s3.us-west-1.amazonaws.com/?object-lock=>: dial tcp: lookup us-west-1-qa-backend-worker-build-dnwylutrpukx.s3.us-west-1.amazonaws.com on 192.168.1.1:53: no such host
while refreshing state
don’t know what’s oging on but I can’t seem to make it through a refresh
yup. usually a temporary connectivity issue - just have to try again
(or check if there’s any status page messages on increased API error rates/latency for your service & region)
Right now for a given ECS service I specify the port and protocol in 3 different places: Once in the load_balancer block of the ECS service, once in the ALB listener, and once in the ALB Target Group. If I am trying to do SSL termination at the ALB, what needs the HTTPS details what needs the HTTP details?
I’m guessing the listener gets the HTTPS, the target group gets HTTP and the ECS service gets HTTP
well maybe the ECS also gets HTTPS?
From the aws_ecs_service docs for the container port: The port on the container to associate with the load balancer.
um
I guess this means the internal port, so HTTP
* module.alb.output.dns_name: 1:16: unknown variable accessed: var.domain in:
${var.stage}.${var.domain}
When targetting my frontend module.
But when I target my ALB module, it works fine?
Lol my root module has an output that depends on the module.alb.output.dns_name value and it outputs just fine
But when targetting my frontend… i get this error. It just never ends…
The alb module definitely has a variable named domain
The alb module is definitely getting passed the domain variable by the root module since I can target the alb module and apply it just fine.
maybe a circular dependency
doubt it though
@ldlework as we already discussed (regarding the code pipeline), you can share your complete code (not just snippets) and people here could take a look and help you much faster. It’s difficult to answer anything without looking at the code
2019-04-04
A quick question on best practices regarding Parameter Store/Chamber. We have around 40 secrets/config parameters needed for our app, that we import with chamber. How would you go about adding them to chamber. The database-related secrets, I’d add using terraform, when creating the database. Would you add the rest to TF as well, manually adding secret values later (which is what we did before), or would you use something entirely different?
we write all secrets for the resources created with TF (e.g. RDS, Elasticache, DocumentDB) from TF when we apply. The rest of the secrets (e.g. k8s stuff, app secrets) we were writing manually (admin via geodesic). Maybe there is a better way of doing this
Okay, thanks. That’s exactly the way I’m doing it (and thanks to chamber import/export it’s actually not too bad)

What were you working on @ldlework
@oscarsullivan_old getting some Fargate services deployed behind ALB with automatic SSL challenge/termination
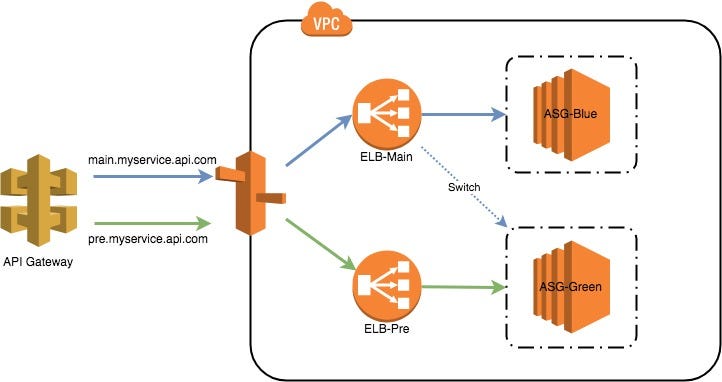
How do i deploy AWS ASG ec2 through terraform as a blue green deployment . i am thinking about diff types of methods
- Create a Launch template which update/ creates new ASG ,new ALB/ELB and switch the R53 domain to new
- Create a new Launch template ,, ASG and ALB and update and target ALB to existing R53
please suggest me best way
#2 will save you on load balancer and looks simpler to implement
Earlier this year, teams at Intuit migrated the AWS infrastructure for their web services to the Application Load Balancer (ALB) from the…
2019-04-05
this post was pretty good also… https://medium.com/@endofcake/using-terraform-for-zero-downtime-updates-of-an-auto-scaling-group-in-aws-60faca582664

A lot has been written about the benefits of immutable infrastructure. A brief version is that treating the infrastructure components as…
personally, i also use terraform to wrap a cfn template for autoscaling groups and ec2 instances
Seen that post a few times; yet to try it; does it work well with the cloudformation stuff?
i think it works great, but there are a couple caveats in our usage…
Community Note Please vote on this issue by adding a reaction to the original issue to help the community and maintainers prioritize this request Please do not leave "+1" or "me to…
Affected Resource(s) aws_cloudformation_stack Background AWS released Termination protection for Cloudformation Stacks in August 2017: https://aws.amazon.com/about-aws/whats-new/2017/09/aws-cloudfo…
neither is a show stopper for most usage, the first is really only an annoyance when developing, the second would be nice to have but can live without it for a while
the biggest benefits are being able to use cfn resource signals to determine instance health (and force terraform to wait until they are really ready) and the UpdatePolicy to easily manage blue/green or rolling updates
I am still not able to understand the downside of using terraform autoscaling groups for non web server clusters. Can someone please care to explain?
who told you there is a downside?
A lot has been written about the benefits of immutable infrastructure. A brief version is that treating the infrastructure components as…
you can see that in this post , they say using terraform Cloudformation resource is preffered over ASG resource
it’s an opinion piece, not a matter of best practice or a generalized statement that will apply to all use cases. try both. deploy your app, update your app, destroy your app. figure out the workflows. use whatever works for you
2019-04-06
What an odd combo
Not an overly old article either
Article:
CloudFormation is free, and by using it to manage the Auto Scaling groups in AWS, we are not increasing the vendor lock-in. So pragmatically, it is hard to find a reason not to leverage the functionality that is only available in CloudFormation. By embedding an aws_cloudformation_stack resource inside Terraform configuration, we get access to these capabilities, while still benefiting from the rich interpolation syntax and variable management in Terraform.
It seems to think ASGs are not doable in TF.
i don’t read that conclusion in that quote at all
they simply say you can do things with an ASG in cloudformation that you cannot do in terraform because they are not exposed via an AWS API. this is simply true. doesn’t make ASG’s undoable in TF
and the two are definitely not one or the other. we use cfn in tf wherever necessary, as sometimes the tf resource just doesn’t yet exist. had tf accept guard duty invites via cfn (until yesterday, when we switched to the new tf resource). probably going use cfn to create email subscriptions to sns topics shortly
2019-04-07
if you’re already using Terraform it’s definitely easier to do ASGs within TF and there’s nothing inherently wrong with doing so. but if you want to do rolling deployments without doing the extra heavy lifting yourself, CF already does it really well (it’s a CF feature, not an ASG feature). the article’s proposition is ‘why not have both?’ - which can be done by managing the CF stack in TF
2019-04-08
anyone ever use this module? https://github.com/terraform-aws-modules/terraform-aws-security-group/tree/v2.16.0
Terraform module which creates EC2-VPC security groups on AWS - terraform-aws-modules/terraform-aws-security-group
in the readme example, they’re passing in a VPC ID as a CIDR block for a security group rule
module "db_computed_merged_sg" {
# omitted for brevity
computed_ingress_cidr_blocks = ["10.10.0.0/16", "${data.aws_security_group.default.id}", "${module.vpc.vpc_id}"]
number_of_computed_ingress_cidr_blocks = 3
}
but I’m having some issue doing the same
I wonder if this is just a typo in the example
maybe also try #terraform-aws-modules
@Noah Kernis https://github.com/cloudposse/terraform-aws-ecs-web-app is an opinionated example of an web ECS app that uses other TF modules. It’s not supposed to be a generic module. You probably should fork it and add what you need, and remove what you don’t need
Terraform module that implements a web app on ECS and supports autoscaling, CI/CD, monitoring, ALB integration, and much more. - cloudposse/terraform-aws-ecs-web-app
@Andriy Knysh (Cloud Posse) thank you for an insanely quick response. Makes sense to me. Had a feeling but wanted to 2x check. Thank you again!
has anyone done ~/.terraformrc on CI to connect to TF Enterprise modules without manually writing the file to your CI server?
anyone know of a way to generate data for all cidr_blocks of all VPCs?
im trying to use data "aws_vpcs" "all" {} to get a list of all my VPC IDs, but not sure what to do after that …
data "aws_vpc" "all" { id = "${data.aws_vpcs.all.ids}" } causes TF to crash lol
you’re in an endless loop at that point. you’re calling a data query from a data query calling a data query from a data query calling….you get the idea.
"${data.aws_vpcs.all.ids}" is accurate, but you would reference that elsewhere in your project
data "aws_vpcs" "foo" {}
resource "aws_flow_log" "test_flow_log" {
count = "${length(data.aws_vpcs.foo.ids)}"
# ...
vpc_id = "${element(data.aws_vpcs.foo.ids, count.index)}"
# ...
}
output "foo" {
value = "${data.aws_vpcs.foo.ids}"
}
Provides a list of VPC Ids in a region
@johncblandii so how do I get the cidr blocks out of data.aws_vpcs.all.ids ?
I’ve not had to do this so I have no clue
what’s your use here?
so it looks like you can take the id, use the aws_vpc instead of aws_vpcs and pull the cidr from there:
Provides details about a specific VPC
@johncblandii the use is making a security group rule for all the CIDRs in a given region
yeah, then the above should be fine
so with that aws_vpc data source
feed the id you want into the aws_vpc data query and you should be golden
do i just use count?
you can pull just one from the aws_vpcs
thats the thing, I want to feed in all IDs
you’re creating SGs across all VPCs at once?
no
the SG will be in one VPC
but it’ll allow traffic from other VPCs
so why loop or count?
ahh…so you want the sg to be in a loop
well, im using a module to create the SG https://github.com/terraform-aws-modules/terraform-aws-security-group
Terraform module which creates EC2-VPC security groups on AWS - terraform-aws-modules/terraform-aws-security-group
and this module seems to only take in cidr_blocks or other security group ids
i actually opened this issue a second ago: https://github.com/terraform-aws-modules/terraform-aws-security-group/issues/112
Example in README shows VPC ID being passed into computed_ingress_cidr_blocks list. Is this module supposed to allow VPC IDs to be passed into that parameter? module "db_computed_sg" { # …
because their example shows them passing in VPC IDs
If I could pass in just the VPC IDs, that’d be awesome
have you tried using count on the sg module?
nope, how would that look?
i dont think it has that parameter
module "http_sg" {
source = "terraform-aws-modules/security-group/aws"
count = "${length(data.aws_vpcs.all)}"
...
}
besides i dont need multiple SGs, I just need one with a lot of rules
ah
so you want ingress_cidr_blocks to be “all vpcs”?
all_vpcs.cidr_blocks
unless that module can take in VPC IDs instead of cidr blocks, but I dont think it can, eventhough they have an example in their readme doing just that
and, for clarity, you are not wanting peering, right?
you just want to allow traffic
nope, peering has been sorted out already
yeah just want the rules
so we just use an aws_security_group with ingress defined by other security groups. they’re all internal to the same vpc, though.
your github issue seems to have code showing how to do it
did you try that and it failed?
yeah i think for some reason you actually cannot pass in VPC IDs
I think this might work for me:
data "aws_vpcs" "all" {}
data "aws_vpc" "all" {
count = "${length("${data.aws_vpcs.all.ids}")}"
id = "${element("${data.aws_vpcs.all.ids}", count.index)}"
}
ingress_cidr_blocks = ["${data.aws_vpc.all.*.cidr_block}"]
i see the computed_ingress_cidr_blocks variable throughout a lot of modules in that repo
computed_ingress_cidr_blocks should be it, but i dont see anything in the source code that takes a VPC ID and returns cidr blocks
maybe just try to output those cidr_block to verify you get back the cidr then you can likely just use https://www.terraform.io/docs/providers/aws/r/security_group.html
Provides a security group resource.
ingress takes a list of cidr_blocks
this is working great: ingress_cidr_blocks = ["${data.aws_vpc.all.*.cidr_block}"]
here is our db sg:
ingress {
description = "Application traffic"
from_port = 5432
to_port = 5432
protocol = "TCP"
security_groups = [
"${module.vpc.internal_only_security_group_id}",
"${module.vpc.web_security_group_id}",
]
}
oh, great…so you got it working?
yep
sweet
data "aws_vpcs" "all" {}
data "aws_vpc" "all" {
count = "${length("${data.aws_vpcs.all.ids}")}"
id = "${element("${data.aws_vpcs.all.ids}", count.index)}"
}
good deal
glad you got it
thanks for the help
np
fwiw since you mentioned it above - count doesn’t work for modules, sadly
i dont need it to but thanks
2019-04-09
Help !! Regarding Error
* provider.vault: failed to create limited child token: Error making API request.
URL: POST <https://vault.abc.net/v1/auth/token/create>
Code: 403. Errors:
* 1 error occurred:
* permission denied
I am trying to get my AWS KEYS from Vault.
provider "vault" {
}
data "vault_generic_secret" "aws_auth" {
path = "secret/project/abc/infra_secrets"
}
provider "aws" {
access_key = "${data.vault_generic_secret.aws_auth.data["access_key"]}"
secret_key = "${data.vault_generic_secret.aws_auth.data["secret_key"]}"
#profile = "${var.profile}"
#profile = "dev"
region = "${var.region}"
}
Question regardin module cloudposse/terraform-aws-s3-bucket: How can I enable “Static website hosting” on the bucket created via the module?
@kritonas.prod you can use this module to create S3 website https://github.com/cloudposse/terraform-aws-s3-website
Terraform Module for Creating S3 backed Websites and Route53 DNS - cloudposse/terraform-aws-s3-website
Thanks @Andriy Knysh (Cloud Posse) I’ll have a look!
here is a working example on how to use the module together with CloudFront CDN https://github.com/cloudposse/terraform-root-modules/blob/master/aws/docs/main.tf#L72
Example Terraform service catalog of “root module” invocations for provisioning reference architectures - cloudposse/terraform-root-modules
that’s how https://docs.cloudposse.com/ is deployed
@Andriy Knysh (Cloud Posse) thank you so much, that’s exactly what I was looking for! sorry for the late reply
Glad it worked for you
Hi guys, do you have any module for privatelink?
@AgustínGonzalezNicolini CloudPosse doesn’t have such a module, maybe other people here have it
also take a look at https://github.com/traveloka?utf8=%E2%9C%93&q=privatelink&type=&language=
Enabling Mobility. Traveloka has 2 repositories available. Follow their code on GitHub.
thanks!
* provider.vault: failed to create limited child token: Error making API request.
URL: POST <https://vault.or1.net/v1/auth/token/create>
Code: 403. Errors:
* 1 error occurred:
* permission denied
Any pointers
No experience with the vault provider.
Is there any way I can use my AWS access and secret key from remote I don’t want to set environmental variables for aws access and secrets key or locally
in geodesic, we use assume role to login to diff accounts. But you will have to provision the required roles, and in your TF modules add the code for TF to assume the roles as well, e.g. https://github.com/cloudposse/terraform-root-modules/blob/master/aws/eks/main.tf#L11
Example Terraform service catalog of “root module” blueprints for provisioning reference architectures - cloudposse/terraform-root-modules
Let me integrate the same
Thanks
geodesic uses aws-vault to store the credentials
I am unable to use that > https://github.com/cloudposse/terraform-root-modules/blob/master/aws/eks/main.tf#L11
Example Terraform service catalog of “root module” blueprints for provisioning reference architectures - cloudposse/terraform-root-modules
Not understand where i need to add this
provider "vault" {
}
data "vault_generic_secret" "aws_auth" {
path = "secret/lav/projects/infra_secrets"
}
provider "aws" {
access_key = "${data.vault_generic_secret.aws_auth.data["access_key"]}"
secret_key = "${data.vault_generic_secret.aws_auth.data["secret_key"]}"
#profile = "${var.profile}"
profile = "dev"
region = "${var.region}"
}
https://github.com/99designs/aws-vault is a completely different thing from the HashiCorp Vault. We did not use the HashiCorp Vault provider
A vault for securely storing and accessing AWS credentials in development environments - 99designs/aws-vault
It also supports aws-okta if you want to login with SAML provider
Hi Guys, Question regarding ASL-ELB . Once my stack are deployed with AWS ASG and a classic load balancer . Next terraform plan and apply is deregistering the instances behing the load balancer. I am unable to find the root cause for deregistering the instances . How do i make sure ASG instances are always registered under ELB
@phanindra bolla it sounds more like terraform wants to recreate something and that’s why they are getting deregistered.
if you share the plan output, that would help more.
2019-04-10
Hi,
I was trying to run this code on my local https://www.terraform.io/docs/providers/helm/repository.html but receiving this error
helm_release.mydatabase: Couldn't load repositories file (helm/repository/repositories.yaml).
sorry this was my mistake I have set the home as ./helm. By removing home in provider fixed the issue
Strange, I’ve had to change my values for bucket prefix
Working: TF_BUCKET_PREFIX="backend"
old way: export TF_CLI_INIT_BACKEND_CONFIG_KEY="backend"
Terraform v0.11.11
+ provider.aws v2.5.0
+ provider.local v1.2.0
+ provider.null v2.1.0
+ provider.template v2.1.0
Any way to have R53 zones for acme.co.uk on two accounts?
Got records like [dev-api.acme.co.uk](http://dev-api.acme.co.uk) on account 1 and [staging-api.acme.co.uk](http://staging-api.acme.co.uk) on account 2
But having the acme.co.uk zones on multiple accounts obviously isn’t picked up. Feel like a NS needs updating somewhere to listen to all the accounts….?
You can do cross-account route53/iam
but the zone must exist in exactly one account
or you can delegate zones
Have done a cross-acount r53 IAM
With an aliased provider for R53 resources!
nice! you’re moving fast
The reason for this is because I originally had a zone on each account called [develop.acme.co.uk](http://develop.acme.co.uk), however my *.[acme.co.uk](http://acme.co.uk) SSL was single level subdomain and I couldn’t figure out how to get a second level SSL cert
The only other option I can think of is having all R53 resources be run against an IAM role for the root account which has the functional [acme.co.uk](http://acme.co.uk) zone
^ That deffo doesn’t have in mind the Terraform / Geodesic model
Sounds like your thinking more about AWS than DNS. This is an easy DNS issue. AWS has nothing to do with it. You can spread DNS subdomains across as many accounts as you want. I have multiple per account. You just need to create a NS record for each one in it’s parent zone
As far as SSL, you need to add aliases when the SSL cert is created for each subdmain you want it to apply too
So, if you created a SSL cert for *.acme.co.uk you would have added an alias for *.develop.acme.co.uk to it
- I have
*.[acme.co.uk](http://acme.co.uk)SSL cert - On my root account I have a working
[acme.co.uk](http://acme.co.uk)R53 zone (connected to our domain providers records) - On my develop account I have either
[develop.acme.co.uk](http://develop.acme.co.uk)or[acme.co.uk](http://acme.co.uk)R53 zone
I would like to have [develop.api.acme.co.uk](http://develop.api.acme.co.uk) use my *.[acme.co.uk](http://acme.co.uk) SSL certificate, somehow
So it’s either I change it to [develop-api.acme.co.uk](http://develop-api.acme.co.uk)
Can’t without recreating the cert
SSL wildcards are single level only
Ah right
I would rather not have to use two level certs
I would like to have multiple [acme.co.uk](http://acme.co.uk) zones across my account and them all work publically
An alternative I see is have them be private zones (all accounts are VPC peered)
so when I go onto VPN I’ll get the DNS records
What I do, is for each subdomain x.example.com I create a cert with *.x.example.com and *.example.com that everything in that subdomain can use
I also have 3 and 4 level SSL certs in my org
Where do you do this
Atm I’m stuck with certificates from godaddy
Keen to move cert management to ACM
But I think I would invalidate my existing, prod live, cert in the process
I organize multiple app environments per AWS account. We decided to reflect this as name spacing in DNS as app.env.account.company.com. I create SSL certs to handle all layers so I can create DNS aliases at any level
You can have many different certs for the same thing (*.example.com) as long as a given service only uses only one of them
And you manage this in ACM?
Yes. It is easy there because it can be fully automated in terraform
It was also done this way to simplify terraform use. The run that setups up the route53 zone needs access to 2 AWS accounts (subdomain and parent domain accounts), but after that other terraform runs only need to use the subdomain account
@Erik Osterman (Cloud Posse) Please checkout the terraform plan . This is what my plan changes when i re run the terraform life cycles .
can you share the code in this thread where you attach the instances?
@oscarsullivan_old why do you think using ACM would invalidate your godaddy certs?
I think you have to point ‘it’ to AWS ?
Also I can’t find a place to actually give an ACM CSR to godaddy
you can’t give AWS cert to GoDaddy, or to anybody else.They are not exportable and can be used only with other AWS services
Thanks. What I meant was I go to create a CA and you have a CSR that needs to be given to the parent CA – don’t htink you can do that with CA
You should first solve how you manage DNS..
I don’t know if godaddy supports delegating a subdomain to AWS but if it does not then you would have to migrate everything (DNS) to AWS
After that ACM can use DNS to validate the domains you want to have SSL certs generated for
Hi, Do we have an example of creating a cloud-init module with multiple cloud init configurations within it. So that the terraform code can source the cloud-init module and use specific cloud-init config from the cloud-init module. Can we make cloud-init template_file optional so that we can render specific template_file in terraform code depends on the requirement
do we have an example of achieving it using https://www.terraform.io/docs/providers/template/d/cloudinit_config.html
Renders a multi-part cloud-init config from source files.
making template_files optional and render only template_file what is needed for end terraform code >
Hi @praveen there’s an open pr where this resource is being used have a look, https://github.com/cloudposse/terraform-aws-cloudwatch-agent/pull/1 it should help you getting started.
This PR includes: a module for installing a cloudwatch agent on ec2 instances. documentation for it ( examples, inputs, outputs ) I excuse myself for the massive PR. If needed I can split it up i…
Hi @Nikola Velkovski, My question was about cloud-init
rendering terraform
let me know if I am confusing you
Contribute to cloudposse/terraform-aws-cloudwatch-agent development by creating an account on GitHub.
check this file out
the resource is the same as the one you where asking about.
@Nikola Velkovski the current example is sourcing multiple cloud init configurations and merging them. My requirement is to create separate cloud-init module, with all yaml files (configuration files ) required for complete environment is made available within it. For end Terraform code when I source the cloud-init module I should be able to render specific cloud-init config file for the specific service(without rendering all configuration files)
which means the cloud-init module should omit(making all template_files optional) all cloud-init files and render specific file needed for the service/terraform code
am i making sense. I mean, can this be achieved.
that will not be easily doable because of Yamls requirement for strict spacing. Maybe if passing the pieces base64 encoded.
is it, let me prepare a module and test it to see if we can achieve it. I will share the module once i create
As this approach being new, wanted to to check if it is doable
Thank you Nikola
you are welcome
@praveen I did this type of thing in a different tool years ago. If you create a template for each cloud-init section and then either concat them together or use a template to put them together with a little conditional logic you should be able to do this
hi Steven, can I have reference to the repo, so that I can refer to it
The one that I did was in puppet for a config file for something else. So, the logic would be different (also not sure where it is). But the concept should work. Probably will not be easy to debug or elegant
I remember in puppet it worked well, but the code was not easy to understand
Sure Steven, let me create one and try. Thanks for the info Steven
welcome
Office Hours Today from 11:30 AM to 12:20 PM (PST) at https://zoom.us/j/684901853
hiya, so forgive me if this a dumb question, but I’m new to the community and I’ve found you through the registry and it seems this is a fairly active set of maintained modules and contributers. I’m looking to reproduce something like https://docs.aws.amazon.com/quickstart/latest/compliance-nist/overview.html in terraform. I’m in the experiment stage and so I wrote a more simple public private subnet without peering or the addtional things in the diagram. At this point, I’m not exactly sure what bit’s and pieces will make sense and how to best ultilze some of the modules and aim for something closer to my goal on this iteration.
Overview of the NIST-based standardized architecture on AWS: topology, AWS services, best practices, and cost and licenses.
hey @Rich Allen welcome
did you see this https://github.com/aws-quickstart/quickstart-compliance-nist
AWS Quick Start Team. Contribute to aws-quickstart/quickstart-compliance-nist development by creating an account on GitHub.
it’s in CloudFormation, but should give you ideas what needs to be done
yes, I was hoping to remain cloud agnostic about it for future purposes. We use aws right now, however for this particular need we’d also like to do other providers.
Strongly recommend this read also, https://bravenewgeek.com/multi-cloud-is-a-trap/
It comes up in a lot of conversations with clients. We want to be cloud-agnostic. We need to avoid vendor lock-in. We want to be able to shift workloads seamlessly between cloud providers. Let me s…
this looks very interesting, I gave it a scan and will review it later. I’m not sure if this addresses that but my worry is not to run a single application in HA/Failover in many clouds, we will deploy slightly different variotions of a basic web application stack (something like django or symfony). My thought is, even if we have to maintain a few different stacks (azure, gcp, aws), we don’t have to have everyone know CF + Terraform. I’m also considering k8s but at this point I feel like k8s is a challenge and we’re not really super mature our CICD/Iaac yet. That read should help me understand my approch avoiding CF. It may be just as easy to use the aws_cloudformation_stack, that’s seems to be a bit of an extra layer of abstraction but it’s something I still need to look into.
it just seemed like this was common, and before I went out and wrote something
just wanted to check in with some folks who might have advice or a module I was missing.
your suggestion is my exact plan at the moment haha
yea, when you look at those templates, you will have more info on what needs to be implemented
also, TF is not cloud agnostic either, it’s just the same syntax, but different resources and modules
Community Note Please vote on this issue by adding a reaction to the original issue to help the community and maintainers prioritize this request Please do not leave "+1" or "me to…
2019-04-11
Hi, Has someone tried to setup istio using terraform?
As opposed to using helm?
…otherwise, using terraform to call helm to install the official chart?
2019-04-12
Hello
Can someone help me with https://github.com/cloudposse/terraform-aws-iam-role/issues/4
I am trying to create an iam role using this module. The template file looks like below data "aws_iam_policy_document" "resource_full_access" { statement { sid = "FullAcces…
May be I am doing something wrong and one of you guys can help to sort it out
Which one would you vote for… remote exec or userdata?
hey @Raju did @Igor Rodionov get back to you?
He’s the one who wrote/maintains that module
2019-04-13
Hi @Erik Osterman (Cloud Posse) Nops, I am yet waiting for a response on it
@Raju sorry about that. @Igor Rodionov has been incredibly busy on another project. I’ll ping him again next week.
Thanks a lot
@Raju can you provide the versions of terraform and aws provider
You can ran terraform version
I have
Terraform v0.11.11
+ provider.aws v2.6.0
+ provider.null v2.1.1
+ provider.random v2.1.1
Your version of Terraform is out of date! The latest version
is 0.11.13. You can update by downloading from www.terraform.io/downloads.html
The aws and null provider versions are different
Terraform v0.11.11
+ provider.aws v1.8.0
+ provider.null v1.0.0
+ provider.random v2.1.1
Your version of Terraform is out of date! The latest version
is 0.11.13. You can update by downloading from www.terraform.io/downloads.html
have you guys heard of pulumi? at this point, I have severe distaste of it
I’ve also heard the same. In fact, I’ve not heard anything positive yet from it.
That said, i want to like it given the short comings of HCL.
So I remain optimistic that by the time we do dig into it, it’s matured to the point it solves a real problem for us.
the general tone of the marketing, the ideal and its execution is pretty weak, and the fact that is a full SaaS service is a main issue for me
I didn’t realize it was full-SaaS. That’s a deal breaker.
AFAIK they provide on-prem/self-hosted options. Also Pulumi could store its state on the local filesystem instead of doing REST API calls.
hi @Julio Tain Sueiras, we heard of it, looked at some examples, but did not actually use it
i thought it was nice to try b/c it uses general purpose languages (Python, Go, Node) so could have much fewer restrictions than terraform
also can deploy k8s using the same language
@Erik Osterman (Cloud Posse) my big issue with pulumi is mostly stem from them piggybacking from terraform, but at the same time dissing terraform
I like that they piggy back on terraform though. Can you imagine the amount of trade skill/knowhow/lessons learned baked into the terraform providers? I would hate to have to go through all that again in another system. That said, I guess the way I’ve been mentally painting pulumi is as the equivalent of SASS for HCL. But I haven’t actually tried using pulumi in any way.
(their provider is actually terraform provider)
@Andriy Knysh (Cloud Posse) my opinion about General purpose languages is , that it def can help with less restriction, but then at the same time move away from the ideal of the code is the infrastructure
2019-04-14
2019-04-15
Look at the onboarding process of new employees with something like pulumi versus terraform. Lot more skill with and best practices with the latter out there.
XTerrafile is a pure Go tool for managing vendored modules and formulas using a YAML file - devopsmakers/xterrafile
Nope but looks interesting, seeing more and more of these small Terraform helper tools for managing and vendoring modules
@Abel Luck do you know if it works recursively?
(for modules composed of other modules)
i haven’t tried it yet, but that would be a requirement for my use case as well
as much as i like the community taking the initiative to develop tools, i can’t help but feel it should be a part of terraform proper.
yea, we recently tried to do this with the help of @tamsky
it’s not an easy problem to solve.
nested modules, pinned at different versions of the same modules. we were able to mock up a prototype using terraform init to fetch all modules, parsed modules.json with jq to get the inventory, and did and some sed foo to rewrite sources to local ones.
but the part that got messy is we couldn’t really use a vendor/ folder b/c it would mean huge amounts of ../../../.././../vendor/github.com/cloudposse/terraform-null-label/0.4.5 type stuff
something like govendor/glide/etc for terraform…. With a true hcl parser/templater and round trip read/write support
I wonder if hashicorp would consider a terraform vendor or terraform package command ..?
Are you using some of our terraform-modules in your projects? Maybe you could leave us a testimonial! It means a lot to us to hear from people like you.
2019-04-16
@Andriy Knysh (Cloud Posse) have you guys used nix before?
@Julio Tain Sueiras what is nix?
Looks interesting, we didn’t use it
the most interesting use of it for me is baking packages into docker image
so no more using ansible or Dockerfile to do apt install or yum install etc
is just
contents = [
vim
terraform
]
 1
1Codefresh’s UI looks really good. There are some quality updates since the last UI I saw
Yea, the are constantly improving it. In fact, there’s even a newer UI than in this demo that they are about to release.
That update will make it easier to visually deal with hundreds of repos and dozens of pipelines per repo.
2019-04-17
anyone have exp w/ the TF ALB resource, particularly the access_logs block. I define an existing bucket, but get access denied. note that this is in dev, I created the bucket and the TF apply is running under my account
Specifically access denied to what?
aws_lb.alb_example: Failure configuring LB attributes: InvalidConfigurationRequest: Access Denied for bucket: shaitestiasapi[hidden]. Please check S3bucket permission status code: 400, request id: 5ba27350-610e-11e9-af7f-1535341880fe
in cloudtrail I see `“errorCode”: “InvalidConfigurationRequestException”, “errorMessage”: “Access Denied for bucket: shaitestiasapi[hidden]. Please check S3bucket permission”,
The AWS LB documention shows no references for access logs, so I’m wondering if this is a bug or old feature in TF: https://docs.aws.amazon.com/cli/latest/reference/elbv2/index.html
If I comment the access_log block out, then the TF template deploys fine:
# access_logs {
# bucket = “${var.s3_alb_logs_bucket}”
# prefix = “${var.log_prefix}”
# enabled = false
# }
Your account needs permissions to S3 bucket to setup and LB needs permissions to write the logs
are there any particular permissions?
I have full admin
Then you’re good for the terraform run. But you need to give the LB permissions to S3
Should be an example of that somewhere
@Steven thx for the help, yep, I’m looking for that example as that’s the part that’s holding me back
it’s here, thx! https://docs.aws.amazon.com/elasticloadbalancing/latest/application/load-balancer-access-logs.html?icmpid=docs_elbv2_console
Learn how to monitor your Application Load Balancer using access logs provided by Elastic Load Balancing.
here’s how we create S3 bucket with policy for LB logs (it’s Elastic Beanstalk, but should be the same for any LB) https://github.com/cloudposse/terraform-aws-elastic-beanstalk-environment/blob/master/main.tf#L1029
Terraform module to provision an AWS Elastic Beanstalk Environment - cloudposse/terraform-aws-elastic-beanstalk-environment
ty!
Hashicorp email just came through
Maybe You Don’t Need Kubernetes, Unleashing Terraform 0.12, and Nomad 0.9 & Vault 1.1 Releases

^ me right now at seeing .12 mentioned
I did the same double take
I got amped because I thought it was them releasing it
Even went to the github releases page thinking…. “waaaaaiit a minute, did I miss something?”
LMBO
my sprint was about to get jacked up!
lol
andddddddd…the referenced article is from March: https://medium.com/hashicorp-engineering/unleashing-the-power-of-terraform-0-12-f864dd0cec4b

Office Hours Today from 11:30 AM to 12:20 PM at https://zoom.us/j/684901853
(PST)
has anyone runinto challenges deploying an s3 bucket when the role has a policy w/ s3:GetBucketWebsite deny?
- aws_s3_bucket.b: aws_s3_bucket.b: error getting S3 Bucket website configuration: AccessDenied: Access Denied status code: 403, request id: 58F8BCE915142469, host id: BJd1A2Zr/RhBG7CNU+zOe4cFoCW63zt+h9ea6jsqC/D7fl3x90uxIrvBIVMezFY8sr5/yxNYdZ0=
resource “aws_s3_bucket” “b” { bucket = “my-tf-test-buckeas231231232144445” acl = “private”
tags = { Name = “test bucket” Environment = “Dev” } }
provider “aws” { region = “us-east-1” }
that’s the TF code, nothing else
IAM policy: { “Version”: “2012-10-17”, “Statement”: [ { “Sid”: “VisualEditor0”, “Effect”: “Deny”, “Action”: [ “s3:DeleteBucketWebsite”, “s3:GetBucketWebsite”, “s3:PutBucketWebsite” ], “Resource”: “*” } ] }
you denied those actions. any reason for doing it?
not my env, customers that insists those have to be denied
heh, chicken, meet egg
might need some kind of condition on the statement such that it doesn’t apply to whatever principal you want to use to apply the tf config
yeah, that’s what I’m thinking, but oddly I can run the create bucket via CLI with no issues. So TF is doing something with the CLI call beyond the basics I’m asking it to do
yes, TF does a lot of “get”-type calls to check state
@shaiss do you create the same policy with Deny when using cli?
policy is already their when they setup the account
hmm…
both TF and cli call the same AWS API
The AWS cli is only doing the create bucket though, TF is trying to manage all the attributes on the bucket and so queries the current state first
No, that would be a security hole :) the policy is already in the account as I understand it
@shaiss might be creating S3 website bucket in TF (not actually using the code shown above), but just plain bucket from the cli
i’m not following that… his role/user is not allowed the s3:GetBucketWebsite action, but TF is clearly attempting to do exactly that
@Andriy Knysh (Cloud Posse) that shouldn’t be the case w/ the TF code I posted above as it’s pulled directly from the Terraform doc for creating a basic bucket
@loren exactly
all i’m saying is that TF makes many api calls when it refreshes state, because TF isn’t doing a single api action in an s3_bucket resource
I love to see the underlying API call TF is making, I enabled tracing but the output is still a bit cryptic
if the policy is a resource (bucket) policy, creating S3 website would not work in any case
@Andriy Knysh (Cloud Posse) the policy is an IAM policy
that IAM policy is attached to the role I’m assuming
Identity-based policies – Attach managed and inline policies to IAM identities (users, groups to which users belong, or roles). Identity-based policies grant permissions to an identity.
Resource-based policies – Attach inline policies to resources. The most common examples of resource-based policies are Amazon S3 bucket policies and IAM role trust policies. Resource-based policies grant permissions to a principal entity that is specified in the policy. Principals can be in the same account as the resource or in other accounts.
set yourself up with a throwaway aws account for the free tier, then setup a role with zero read privs, use that with TF to create the bucket. then you’ll see all the aws api calls that TF is performing, as you get denied one-by-one, grant yourself that specific api read action
that IAM policy is attached to the role I’m assuming
are you assuming the same role when using the cli?
in TF, a different set of api actions is required to create the bucket the first time vs applying the config again (even with no changes) due to the extra read cycle
Terraform AWS provider. Contribute to terraform-providers/terraform-provider-aws development by creating an account on GitHub.
Terraform AWS provider. Contribute to terraform-providers/terraform-provider-aws development by creating an account on GitHub.
skim that file for s3conn. to get an idea of the api actions required
i’m just trying to say that if @shaiss assumes the role with the policy when using TF, then it will not work b/c/ of the permissions. With cli, if he assumes the same role, it should not work either. If he uses another way to login with cli, then it would work since the policy is not attached to the other credentials. If he assumes the same role using cli and it works, then it’s very strange
right, the difference is that with the aws cli, the only thing he did is create-bucket
TF does much more than just create-bucket when operating on an aws_s3_bucket resource
@Andriy Knysh (Cloud Posse) I assume the role w/ both TF and CLI, and CLI works, TF fails
@loren is on the right path here.
it’s those additional things that TF is doing that in this case fails b/c the customer insists on having that IAM policy attached to ALL roles
i can’t really imagine why they’d want to restrict s3:GetBucketWebsite on all buckets, that just means they can’t even confirm that the buckets do not have a website configured, as you’re seeing 
yea agree, that permission should be lifted since it’s just read-only anyway
@loren I agree, but atm they won’t budge, so before I argue that point, I want to make sure there’s no other Terraform way around this
looking at the TF code, i don’t see a way. TF needs it to execute its “read” operation on the bucket
and without supporting the “read” operation, there isn’t much point in using TF
maybe I just need to fork it and remove that
I’ll call it shaiform
lulz
from the TF code, it does look like the bucket should have been created… it would be after that when TF attempts the read operation that fails… can you double-check that maybe?
it does indeed create the bucket
but the customer would still say the terraform code is invalid because of that error
after that you ask them to remove s3:GetBucketWebsite
it’s not a big deal and not a security concern
man I know!
it’s a pain atm and just trying to submit clean code without errors
i mean, you could try to submit an issue asking that the TF provider be more considerate of insanely restrictive IAM policies and illogical customers
since the TF config doesn’t specify an s3 website config, TF could key on that absence to avoid the calls
2019-04-18
guys, is there any way to user archive_file zip with -X argument?
because every time when I do apply, .zip change timestamp, and upload lambda function
I want to stop it. and do upload when it changed only
I know what you mean, and I don’t think it’s possible
really ?
Not using archive file
I saw some one write an idempotent zip generator (reddit?)
But I can’t find it now and forgot to star it
Also the order of the files matters
It was specifically for this use case
there are usecases and workarounds on github issues of (probably aws provider?) , they build around lifecycle { ignore_changes } feature of TF
yes, aws provider
@Gabor Csikos could you do me a favour and provide a link to ignore_changes feature?
lifecycle {
ignore_changes = ["filename"]
}
I found
Is anyone using the terraform-aws-eks-cluster TF module?
Using the example provided, I’m having the following issue:
Error: Error running plan: 5 error(s) occurred:
* module.eks_cluster.output.eks_cluster_id: Resource 'aws_eks_cluster.default' does not have attribute 'id' for variable 'aws_eks_cluster.default.*.id'
* module.eks_cluster.output.eks_cluster_version: Resource 'aws_eks_cluster.default' does not have attribute 'version' for variable 'aws_eks_cluster.default.*.version'
* module.eks_cluster.local.certificate_authority_data_list: local.certificate_authority_data_list: Resource 'aws_eks_cluster.default' does not have attribute 'certificate_authority' for variable 'aws_eks_cluster.default.*.certificate_authority'
* module.eks_cluster.output.eks_cluster_arn: Resource 'aws_eks_cluster.default' does not have attribute 'arn' for variable 'aws_eks_cluster.default.*.arn'
* module.eks_cluster.output.eks_cluster_endpoint: Resource 'aws_eks_cluster.default' does not have attribute 'endpoint' for variable 'aws_eks_cluster.default.*.endpoint'
@dalekurt have you looked at the example https://github.com/cloudposse/terraform-aws-eks-cluster/tree/master/examples/complete
Terraform module for provisioning an EKS cluster. Contribute to cloudposse/terraform-aws-eks-cluster development by creating an account on GitHub.
it’s tested many times, and many people have deployed EKS cluster using it
@Andriy Knysh (Cloud Posse) Yes, i’m actually using that
I will give another go with a clean slate.
@Andriy Knysh (Cloud Posse) should we pin the AWS provider on that module?
yea, good idea, we pin all dependencies except the provider
i think we need to since the provider has been breaking so much stuff
I’ll open PRs
the provider broke stuff on us recently
all things were blocked; very disappointing
@dalekurt I’m using the EKS module. i haven’t seen that issue
Thanks @johncblandii @Andriy Knysh (Cloud Posse) I plowed through that and now i’m solving for the following
Error: Error refreshing state: 1 error(s) occurred:
* module.eks_workers.data.aws_ami.eks_worker: 1 error(s) occurred:
* module.eks_workers.data.aws_ami.eks_worker: data.aws_ami.eks_worker: Your query returned no results. Please change your search criteria and try again.
@dalekurt what region are you using for EKS?
@Andriy Knysh (Cloud Posse) us-east-1a
My filter was based on amazon-eks-node-v*
A terraform provider to create to create a zip file from different kind of source. - ArthurHlt/terraform-provider-zipper
does anyone have experience with https://docs.geopoiesis.io?
Turbocharging your infrastructure-as-code
looks like atlantis but seems to have a nicer interface and ability to limit user access better
oh right! thanks for bringing that back to my attention
SweetOps is a collaborative DevOps community. We welcome engineers from around the world of all skill levels, backgrounds, and experience to join us! This is the best place to talk shop, ask questions, solicit feedback, and work together as a community to build sweet infrastructure.
@antonbabenko might have some experience (by now)
I have not looked into it since we talked about it last time. Too busy with other things. You know :)
So it is a Terraform Enterprise competitor with a 100x worse name?
I kid.
terraforming
geo = earth, poiesis = making
“second, there is the principle of gaian geopoiesis, a global principle of self-organization, that trumps the interests of individuals and species.”
Learn something new every day; still can’t pronounce it.
Yea the name is overboard
That’s nice to see each stage and changes pending
Very cool
2019-04-19
Hm might give that go. Looks easier than Atlantis at a glance
Easier to try 0.12 now… https://www.hashicorp.com/blog/announcing-terraform-0-1-2-beta-2
We are pleased to announce the availability of the second beta release of HashiCorp Terraform 0.12! The 0.12 release of Terraform contains major language improvements and a host of…
 4
4uh oh….can’t wait
SEARCH IN THE DOCS!! SEARCH IN THE DOCS!! SEARCH IN THE DOCS!! SEARCH IN THE DOCS!! SEARCH IN THE DOCS!! SEARCH IN THE DOCS!!
Terraform is used to create, manage, and manipulate infrastructure resources. Examples of resources include physical machines, VMs, network switches, containers, etc. Almost any infrastructure noun can be represented as a resource in Terraform.
nice - looks like they revamped the docs
Google probably still faster
lmbo. prob so
What’s the recommended workflow for secrets management with terraform and the google cloud provider?
I’m curious if there’s a non-vault way that’s as easy as the AWS’s KMS integration with terraform.
(me too)
I asked the same question on reddit https://www.reddit.com/r/Terraform/comments/bf2ly2/secrets_management_with_terraform_and_google/?utm_source=share&utm_medium=web2x. There have been a couple of replies. Sops is an interesting take on the problem.
3 votes and 3 comments so far on Reddit
2019-04-21
Has anyone successfully deployed the reference-architectures? I’m currently using it for my company but I’m not getting a successful deployment. I would love some help troubleshooting this
https://github.com/cloudposse/reference-architectures
Get up and running quickly with one of our reference architecture using our fully automated cold-start process. - cloudposse/reference-architectures
@dalekurt’s question was answered by <@Foqal>
@dalekurt best to ask in #geodesic for now
Maybe should create dedicated channel
2019-04-22
Thanks @Erik Osterman (Cloud Posse)
by now you have figured out I’m using a lot of your terraform modules on numerous projects. I’m trying to get this Terraform module <https://github.com/cloudposse/terraform-aws-eks-cluster> but I’m coming up with a single error
Error: Error refreshing state: 1 error(s) occurred:
* module.eks_workers.data.aws_ami.eks_worker: 1 error(s) occurred:
* module.eks_workers.data.aws_ami.eks_worker: data.aws_ami.eks_worker: Your query returned no results. Please change your search criteria and try again.
The module
data "aws_ami" "eks_worker" {
count = "${var.enabled == "true" && var.use_custom_image_id == "false" ? 1 : 0}"
most_recent = true
name_regex = "${var.eks_worker_ami_name_regex}"
filter {
name = "name"
values = ["${var.eks_worker_ami_name_filter}"]
}
most_recent = true
owners = ["602401143452"] # Amazon
}
@dalekurt what AWS region and what version (release) of the module are you using?
@Andriy Knysh (Cloud Posse) us-east-1 and master
the AMI search and filter were changed in recent PRs, You can create a separate project using just the code above, and try to update eks_worker_ami_name_regex and/or eks_worker_ami_name_filter to see what’s returned. If nothing returned, then the AMI list has already been changed in AWS, try to change eks_worker_ami_name_regex to see if you can find any EKS AMIs
Okay, I was on the right track for resolving this. I will try that after my stand up. Thank you very much
@Andriy Knysh (Cloud Posse) Confirmed, I created a new project for the EKS cluster using the example and the result was the same. I will look into the eks_worker_ami_name_regex
I defined a terraform.tfvars with
eks_worker_ami_name_filter = "amazon-eks-node-*"
eks_worker_ami_name_regex = "^amazon-eks-node-[1-9,\\.]+-v\\d{8}$"
` Which got me past that issue.
Now I get the following
------------------------------------------------------------------------
Error: Error running plan: 5 error(s) occurred:
* module.eks_cluster.output.eks_cluster_id: Resource 'aws_eks_cluster.default' does not have attribute 'id' for variable 'aws_eks_cluster.default.*.id'
* module.eks_cluster.output.eks_cluster_endpoint: Resource 'aws_eks_cluster.default' does not have attribute 'endpoint' for variable 'aws_eks_cluster.default.*.endpoint'
* module.eks_cluster.local.certificate_authority_data_list: local.certificate_authority_data_list: Resource 'aws_eks_cluster.default' does not have attribute 'certificate_authority' for variable 'aws_eks_cluster.default.*.certificate_authority'
* module.eks_cluster.output.eks_cluster_version: Resource 'aws_eks_cluster.default' does not have attribute 'version' for variable 'aws_eks_cluster.default.*.version'
* module.eks_cluster.output.eks_cluster_arn: Resource 'aws_eks_cluster.default' does not have attribute 'arn' for variable 'aws_eks_cluster.default.*.arn'
I have to define the certificate data for one of those errors.
Join us for “Office Hours” every Wednesday 11:30AM (PST, GMT-7).
This is an opportunity to ask us questions on terraform and get to know others in the community on a more personal level. Next one is Mar 20, 2019 11:30AM.
Add it to your calendar
 https://zoom.us/j/684901853
https://zoom.us/j/684901853
 #office-hours (our channel)
#office-hours (our channel)
2019-04-23
guys, quick question
in the module terraform-terrafom-label there is a “local.enabled == true ? … ” isn’t it redundant and could be just defined as “local.enabled ? …” ?
I mean, is there a specific reason why that is written that way?
no specific reason, could be written both ways
thanks!
Is there an example out there of how to do a list of ports with aws terraform security groups?
If they’re all in order, you could just do a range - from and to.
Otherwise, I’d probably put them into a local variable as a list and build the rules from that with count.
Something like:
locals {
ports = [80, 443]
}
resource “aws_security_group_rule” “main” {
count = “${length(local.ports)}”
...
from = “${local.ports[count.index]}”
...
}
Awesome!
Also, I’m trying to create generic automation builds… Is there a way to somthing like this: If a user has a subnet they want the instance in then they can input that subnet else create a subnet to put the instance in but dont create a subnet if they do put a subnet in…
you could create a variable that defaults to an empty string
and then use count = "${var.subnet = "" ? 1 : 0}" on your subnet resource to only create it if the variable is blank
How would you get resources to select whichever one had a value?
use a similar conditional
subnet = "${var.subnet = "" ? ..... : var.subnet}"
Would it be:
subnet = “${var.subnet = “” ? ….. : data.subnet}”
the ...... i left for you to fill in, but data.subnet wouldn’t be a valid address - if you’re pulling the subnet in through a data source it would be something like data.aws_subnet.selected.subnet_id
subnet = “${var.subnet = “” ? : data.aws_subnet.selected.subnet_id”
So like that^ Sorry trying to learn this piece of it
subnet = "${var.subnet = "" ? data.aws_subnet.selected.subnet_id : var.subnet"
See https://www.terraform.io/docs/configuration-0-11/interpolation.html#conditionals for further details on how it works
2019-04-24
Utilizing the VPC Peering module. I am getting this regardless if I use VPCID’s or VPC Tags for the selector: data.aws_vpc.requestor: multiple VPCs matched; use additional constraints to reduce matches to a single VPC
Each of my VPC’s are uniquely named and have unique vpc ID’s obviously.
Ah, nevermind. I had two blocks of VPC peering module in my main.tf.
Can you iterate over nested blocks in Terraform?
2019-04-25
just found a weird behavior in terraform
locals {
tasks = {
main_num = 200
other_num = "${local.tasks["main_num"] + (local.tasks["main_num"] * 0.50)}"
}
}
output "other_num" {
value = "${local.tasks["other_num"]}"
}
output "main_num" {
value = "${local.tasks["main_num"]}"
}
we recently got a lot of issues with TF maps. Work in some cases, in other don’t (mostly don’t work across many modules). And we’ve seen issue where a map gets sent b/w modules, but arrives empty or broken
well can’t wait for 0.12 they should’ve tackled all of these issues.
this empties the whole tasks map!
Can someone point me to sample terraform project which pulls a docker image from dockerhub and deploys into ecs ?
@ankur.gurha take a look here https://github.com/cloudposse/terraform-aws-ecs-web-app
Terraform module that implements a web app on ECS and supports autoscaling, CI/CD, monitoring, ALB integration, and much more. - cloudposse/terraform-aws-ecs-web-app
it deploys an app into ECS
look into the examples https://github.com/cloudposse/terraform-aws-ecs-web-app/tree/master/examples
Terraform module that implements a web app on ECS and supports autoscaling, CI/CD, monitoring, ALB integration, and much more. - cloudposse/terraform-aws-ecs-web-app
hey ho, any one using https://github.com/cloudposse/terraform-aws-vpc-peering-multi-account?ref=tags/0.5.0 with success?
Terraform module to provision a VPC peering across multiple VPCs in different accounts by using multiple providers - cloudposse/terraform-aws-vpc-peering-multi-account
I can use it perfectly fine via the geodesic images but struggling via a jenkins pipeline
hey @Jan, we deployed it to a client recently
working example here https://github.com/cloudposse/terraform-root-modules/tree/master/aws/kops-legacy-account-vpc-peering
Example Terraform service catalog of “root module” blueprints for provisioning reference architectures - cloudposse/terraform-root-modules
@Jan it needs to be able to assume role into multiple accounts
Does Jenkins have that permission?
As far as I am aware yes, I am debugging further. Whats interesting is that terraform errors out about not having credentials for the providers (running the same module with the same tfvars just as the reference./geodesic admin user it works)
Can anyone help me understand this error
kubernetes_service_account.tiller: 1 error(s) occurred:
* kubernetes_service_account.tiller: Post <http://localhost/api/v1/namespaces/kube-system/serviceaccounts>: dial tcp [::1]:80: connect: connection refused
sounds like your k8s cluster API isn’t accessible
you’re running it locally, right? is it definitely up, etc.?
no running through terraform enterprise.
maybe i need to set kubernetes provider. I am only relying on helm kubernetes config
yeah it looks like it’s trying to connect to a local cluster, which won’t work in enterprise you’ll need to set the host and access details for the kubernetes provider
2019-04-26
I want to set a local value in terraform, the value should be the value from a data provider, if the value exists, otherwise a value from a variable.. anyone know if this is possible?
in psuedo non-hcl code: local foobar = data.something.foobar != null ? data.something.foobar : var.default_foobar
hm i suppose a ternary might work in the interpolation?
@Abel Luck why not ?
data "aws_ami" "test" {
most_recent = true
filter {
name = "name"
values = ["Deep Learning AMI (Ubuntu)*"]
}
owners = [
"amazon",
]
}
locals {
abel = "${data.aws_ami.test.id != "" ? data.aws_ami.test.id : "bar"}"
}
output "abel" {
value = "${local.abel}"
}
although the data.aws_ami resource is a poor example since it fails when not being able to match any amis but the logic is the same with whatever you are using.
2019-04-29
Join us for “Office Hours” every Wednesday 11:30AM (PST, GMT-7).
This is an opportunity to ask us questions on terraform and get to know others in the community on a more personal level. Next one is Mar 20, 2019 11:30AM.
Add it to your calendar
https://zoom.us/j/684901853
#office-hours (our channel)
@Andriy Knysh (Cloud Posse) hi?
Hi @Julio Tain Sueiras
so , I have officially started on the LSP implementation for terraform
and from what I am seeing so far, once I have the base configs for parsing done, the completion will be reading for not just resources but for any user defined object variable
so is going to be a very interesting approach
got somestuff working
it will be hcl2 parser inside the terraform to parse the source code, then adapt tfschema to use go-plugin grpc to call the provider binary directly to get the schema
since terraform have split the providers
2019-04-30
what do we all think of modules containing A LOT of data lookups? we have our own module, called “aws”, and this module … we’re thinking about putting a ton of data lookups we use all the time but, seems that whenever we call the module, all the data lookups get evaluated
We’ve done this before and it “works” however it totally breaks cold-starts
friend of mine saying it’ll end up beating up the aws api
i thought there was a way to have data lookups evaluated only when you use them
@cabrinha if data sources are in the code, they will be evaluated with terraform plan (and apply of cause)
you can use count in data sources if you want to disable them https://www.terraform.io/docs/configuration/data-sources.html#multiple-resource-instances
Data sources allow data to be fetched or computed for use elsewhere in Terraform configuration.
thanks
generally it works ok when everything is already created and in good state
issues could arise during cold start (as @Erik Osterman (Cloud Posse) mentioned) and with terraform destroy
What are the pros and cons of using data lookup vs remote state file ?
If in an large organization where different group does different part and the remote state file is not accessible the I would say use data lookup. But if the same time that does all the setup then is it better to use either data lookup or remote state file ?