#terraform (2023-09)
 Discussions related to Terraform or Terraform Modules
Discussions related to Terraform or Terraform Modules
Archive: https://archive.sweetops.com/terraform/
2023-09-01
To be honest, it is disgusting that Hashicorp changes the license and apparently it is looking to sell itself for a big price. OpenTF is one side for community to fight against the venture capitals behind the deal. The other side may be to find an alternative of Terraform. My 2 cents, one of few alternatives: ArgoCD + Crossplane. If you or your companies are already working on them, it would be a good chance to stand up against tyrannies of technologies.
While I wish things were different and we could just return to a “status quo”, I am optimistic that this will be the best for everyone. HashiCorp can focus on better serving enterprises without the weight of open source, while the open source community can get behind a fork and better drive the product forward in a direction that benefits alternative usages.
Everyone is entitled to their opinions and causes, but I’d challenge you to name one company affected by the license change that isn’t backed by venture capital.
There are no openVault/Consul/Nomad/Boundary/Waypoint/Vagrant projects because nobody else (aside from one firm that won’t admit it) has built businesses on any of the rest of those technologies (well, Nomad does have some folks, but they haven’t spoken up).
I think one of the key differences though is that terraform is more like an “interpreted language” built on HCL. It’s akin to ruby, perl, php. So companies have built businesses using this language. Vault, Consul, Nomad, Boundary, and Waypoint are all “services”. In fact, Terraform Enterprise is a service. If Terraform Enterprise was formerly “open source” and then moved to “BUSL”, I would understand. But moving the language to BUSL is my personal contention.
It’s a good point Erik. And one of my major thought exercises is: at what level of abstraction should someone be able to draw a line between open and commercial products. Especially those built on lots of other OSS products.
I actually think OSS needs a rethink in general when it comes to recognizing contributions for the entire software supply chain, but that’s a very different conversation altogether.
Strongly agree with Erik. I’d go a bit further, and say that the BUSL changes makes no sense for client applications. E.g. terraform, packer, vagrant. For the applications with a server component, sure, absolutely reasonable. E.g. vault, consul, nomad, etc.
Every user of Terraform is at least indirectly affected by the license change and the recent registry T&C shenanigans. Good many folks who do not use Terraform are affected, too.
That is why after I thought it over, I want to voice out and fight it, actually it is not just me having the same thoughts I believe, I just saw the trend again, which is similar to when Oracle acquired SUN(MySQL), and then Postgres became more and more popular. But that took a while. This time we can make the transition faster Lol
That’s essentially what OpenTF is about - keeping the legacy of Terraform alive and useful for years to come, regardless of the fate of the original project.
considering to introduce Rust? lol
For providers - why not.
For the core… IDK, not sure about the cost-benefit ratio of a rewrite.
wow this is good, the agreement in provider realm is not clear to me, introducing Rust may get more attentions from developers
I can’t speak on behalf of the OpenTF project, just my own here, but I’d support spinning off some parts of Terraform into plugins (eg. backends).
DevOps/SRE may become more friendly for Rust developers
I think it would be less about Rust or any other language, more about making plugin development language-agnostic.
Theoretically you could write a Terraform provider in anything you want, but the process is not well defined, and there are no libraries or examples to help you get started.
yeah, English is the best programming language, the goal
Even though under the hood it’s just gRPC.
to my understandings, the time-consuming part is the provider APIs and also uncertain part since backend service is so unpredictable
The difficulty of it all is greatly exaggerated TBH.
feel the same
I contributed a few issues in TF before, and tried to write a custom provider, the framework is kinda easy to work with
As Spacelift we’re hoping to organize regular hackathons to help community members learn the core concepts through hacking on small features, and get productive in the codebase.
We’ll test the idea internally in 2 weeks, if it’s successful we’ll try an open one, too.
golang codes are easy to understand but not easy to work with, especially modules lol
cool
with some easy tutorials to follow with please
I feel TF was becoming difficult to get into for entry level golang dev, hope there are better tutorials for them
how-to contribution , how-to troubleshooting, etc.
Crossplane lets you build a control plane with Kubernetes-style declarative and API-driven configuration and management for anything.
Lol I promise I didn’t find this post before
The alternative of Consul -> etcd, which is verified by Kubernetes
etcd concern of it, it is owned by another giant …
Well, I’d say if folks are just using Consul for K/V, moving to something like Etcd or Zookeeper is a good idea in the long run. Consul focus is more Service Discovery/Mesh these days along with integrations to Terraform for automating physical device updates.
owned by another giant
etcd is a CNCF project.
It’s often used for service discovery, not just a K/V store though obviously service discovery is a K/V problem.
For service mesh you have Istio, another CNCF project.
got it, CNCF project
No potential alternative of Vault afaik, but expecting one will rise soon
Honestly, it depends on the part of Vault you need. Most of Vault exists in cloud providers today, we offer some additional pieces already, and there are other providers out there that offer the last part as well. I’m definitely on the side of I don’t understand why people are still using it.
One common API, one management model, and a massive amount of identity mappings. And it works at massive scale. Dynamic (JIT) secrets, Dynamic cloud credentials, simplified PKI, format and non-format preserving encryption (at massive scale) with key material kept in Vault, Bring Your Own Key KMS across all cloud providers, TDE…
That is why Vault is so critical for it works closely with cloud providers who are reluctant to stand up, not like what happened when Elastic changed ELK license AWS was annoyed
Vault is a pretty good product and is hard to beat, but some companies go to Vault because they hear about it ,but in reality many of them could just use almost free services from their cloud providers and a good secret strategy and they will be fine with just that, but , for more complicated workloads Vault is a good choice. The problem I had with Vault is the sales team wanted to charge me 2M a year for 1 prod Vault cluster…..and since then they have been trying to get back into the company and sell more products with no luck
There is a big disconnect between use cases in some places. Many folks just need K/V and nothing else. For which something like Parameter Store or Secrets Manager are good alternatives.
Vault Secrets is in beta now, and I think will be a better fit for simpler use cases:

HCP Vault Secrets provides a centralized, developer-centric cloud-native secrets management solution that serves as an intuitive, single source of truth for your applications.
For a SaaS vendor, there is AKEYLESS And as mentioned above all cloud providers have a solution as well, AWS Secret Manager, AWS KMS, AWS Parameter Store, GCP Secrets Manager, and Azure Key Vault.

Akeyless Vault platform built to secure IT and DevOps resources, credentials, and access, on hybrid cloud and legacy environments.
There’s also https://infisical.com/
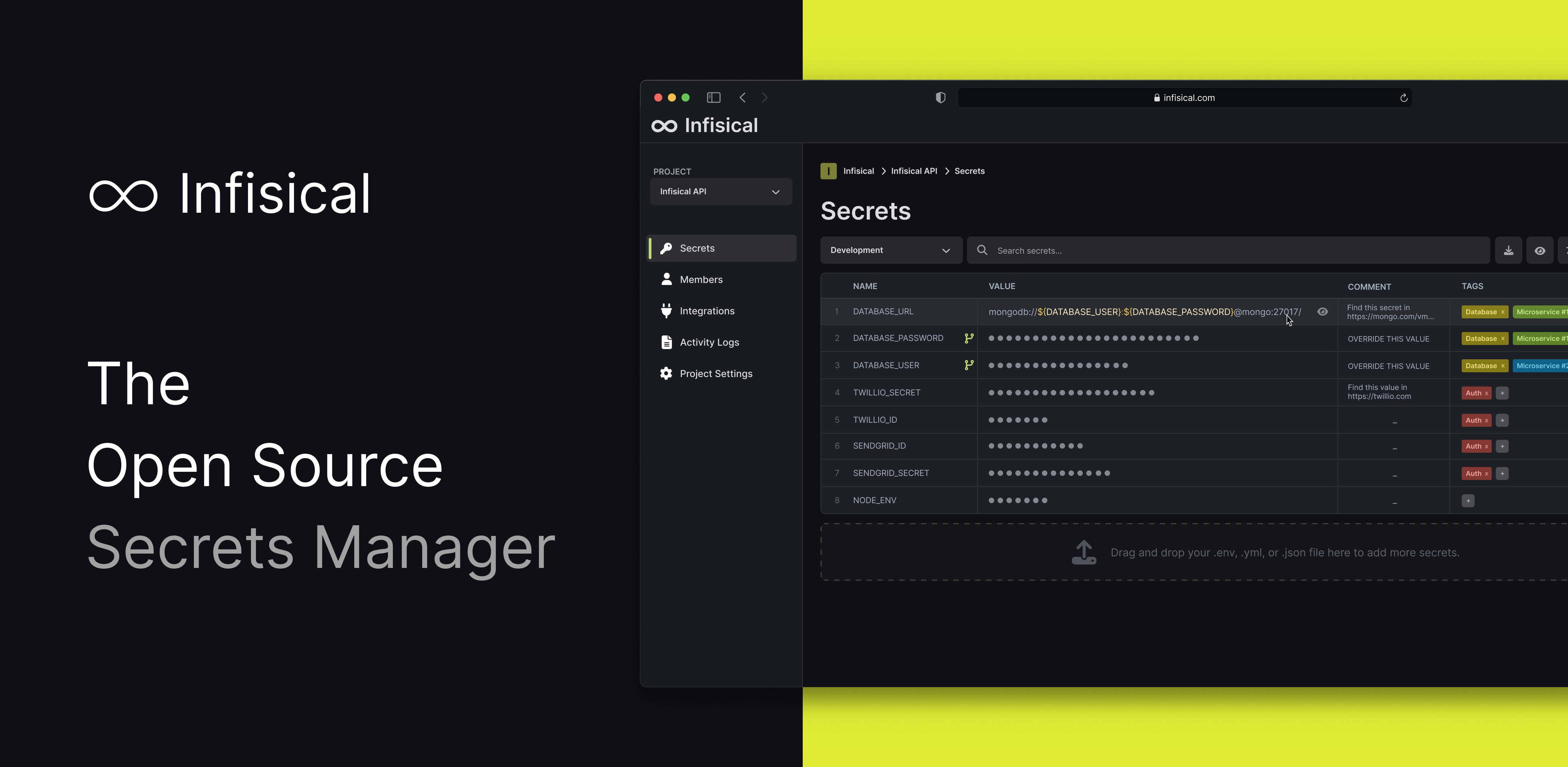
Infisical lets developers manage secrets and environments. Used by everyone from small teams to large corporations. Save time and improve security.
Infisical vs Vault: why do companies choose Infisical over Hashicorp Vault.
awesome, found its repo here, https://github.com/Infisical/infisical
Infisical is an open-source, end-to-end encrypted platform for secret management: sync secrets across your team/infrastructure and prevent secret leaks.
qq? Is Terragrunt taken as a competitor by new license of Terraform?

Thanks, Open source version attempts normally are hard to excel the original ones, that is the reason I feel we need alternatives :)
stop adopting new features and migrate to alternatives
2023-09-02
2023-09-04
Hi, are you familiar with some tool/github action that posts a small terraform plan output as part of ci/cd pipeline ?
Atlantis: Terraform Pull Request Automation
I wrote this a while back, it’s been pretty much what we needed most of the time: https://gist.github.com/wparad/ea473f573a420134cb12dbac0e2184a9
GitHub actions for terraform
Thanks im testing atlantis seems intersting (we are using terragrunt(
2023-09-05
Heya! I’m looking at the cloudposse/terraform-aws-eks-node-group module and trying to understand, how does it do the user-data stuff for Bottlerocket to work? Does it still drop in the userdata.tpl bash script or does it have some sort of bypass somewhere and generate some sort of TOML?
To enable the container, you can change the setting in user data when starting Bottlerocket, for example EC2 instance user data:
[settings.host-containers.admin]
enabled = true
An operating system designed for hosting containers
Wait wha?
Hi Team,
I am facing challenges with packer, can someone help? I am trying to build an AMI, but i am taking the previous build AMI as source, On the top of that AMI, i want to update some additional packages and some folder needs to create, but when i run the packer command second time, its failing with the folder already exist.
Is there a way to check the folder and if its available, need to skip that provisioner step.
Can someone help me to add that step and ignore if its already available.?
you may need mkdir -p?
Hey! Happy to announce that the OpenTF repository is now public
There are 24 open issues, 125 closed ones
2023-09-06
Hi Team,
I am currently working on project where I need peering between different aws regions within the same account. We used to use cloudposse/vpc-peering/aws which sadly cannot connect different regions. I tried to upgrade the code to use the cloudposse/vpc-peering-multi-account/aws module and ended up with the error: Error: query returned no results. Please change your search criteria and try again . The VPCs and subnets already exist. They are created with a different module in a different deployment.
I will add code snippets to this thread. I really hope you can help me with this.
This is snippet of the code with some comments:
provider "aws" {
region = var.region
}
data "aws_vpc" "vpc" {
filter {
name = "tag:Name"
values = ["${var.namespace}-${var.environment}"]
}
}
provider "aws" {
alias = "eu-west-1"
region = "eu-west-1"
}
data "aws_vpc" "vpc_vpn" {
provider = aws.eu-west-1
id = "vpc-my-fancy-vpc-id"
}
module "vpn_cluster_vpc_peering" {
source = "cloudposse/vpc-peering-multi-account/aws"
version = "0.19.1"
# condition
enabled = contains(var.peering_map[var.environment], data.aws_vpc.vpc_vpn.id)
name = module.label.id
tags = merge(local.tags, { Name = "VPN => ${module.label.id}" })
namespace = var.namespace
attributes = var.attributes
environment = var.environment
# role created via cloudposse/iam-role/aws
requester_aws_assume_role_arn = module.vpc_peering_multi_region_role.arn
requester_vpc_id = data.aws_vpc.vpc_vpn.id
requester_allow_remote_vpc_dns_resolution = false
# hardcoded because it is not working anyways.
requester_region = "eu-west-1"
# same role as for requester
accepter_aws_assume_role_arn = module.vpc_peering_multi_region_role.arn
accepter_vpc_id = data.aws_vpc.vpc.id
# region is setup in a tfvars file. In this case it is "eu-central-1"
accepter_region = var.region
}
How can this be fixed?
I raised a PR that fixes the issue for me. https://github.com/cloudposse/terraform-aws-vpc-peering-multi-account/pull/78
what
• Replaced the “aws_route_table” data source with “aws_route_tables” for better handling of multiple route tables in the VPC. • Added a filter to the “aws_route_tables” data source to only include route tables associated with the subnets in the VPC. • Updated dependencies in the “aws_route” resource to reflect the change in data source.
why
All my VPCs with more then one subnet raised this error.
Error: query returned no results. Please change your search criteria and try again
with module.vpc_vpn_vpc_peering.data.aws_route_table.requester[5],
on .terraform/modules/vpc_vpn_vpc_peering/requester.tf line 124, in data "aws_route_table" "requester":
124: data "aws_route_table" "requester" {
references
https://sweetops.slack.com/archives/CB6GHNLG0/p1694006033839549
@Dan Miller (Cloud Posse)
the vpc-peering-multi-account module does support cross region peering. See requester_region and accepter_region
For example, see our component for vpc-peering
https://docs.cloudposse.com/components/library/aws/vpc-peering/
This component is responsible for creating a peering connection between two VPCs existing in different AWS accounts.
vpc-peering-multi-account does support it, but failed with the requester subnets. Thus the PR.
vpc-peering does not support peering between multiple region as far as I can tell.
also this module did not create default routes in the requestes routing table. fixed it today in the same PR.
Any chance someone can look into this? @Dan Miller (Cloud Posse)?
@Dan Miller (Cloud Posse), @Gabriela Campana (Cloud Posse) You were the only ones replying to this thread. Can anyone have a look at the PR?
Yes apologies for the delay @Vitali I’ll ping our team and we’ll review
Thank you!
pipeline was failing, I just ran fmt and the make parts to fix validate .
this PR depends on the upgrade to support Terraform AWS Provider v5, which we have here: https://github.com/cloudposse/terraform-aws-vpc-peering-multi-account/pull/74
I’ll ask the team to prioritize this module
what
Support AWS Provider V5
Linter fixes
why
Maintenance
references
https://github.com/hashicorp/terraform-provider-aws/releases/tag/v5.0.0
Thanks.
@Dan Miller (Cloud Posse), the PR has been merged already. Is there a chance you can check the other PR now?
Hi @Vitali Daniel is on vacation until next week.
I will see if any one else at Cloud Posse can check the other PR now
We are moving Atlantis to the CNCF!!! please take a minute to give a thumbs up https://github.com/cncf/sandbox/issues/60
2023-09-07
Hello. I found the SweetOps Slack while trying to create AWS Iam Identity Center permission sets using https://github.com/cloudposse/terraform-aws-sso/tree/main/modules/permission-sets with Terragrunt. Running a plan just shows: No changes. Your infrastructure matches the configuration . It seems the inputs block in terragrunt.hcl does not have any effect. How can I use this module with Terragrunt?
could you show us your terragrunt.hcl file ?
Sure. Here is a snippet
terraform {
source = "../terraform-aws-sso//modules/permission-sets"
#source = "<https://github.com/cloudposse/terraform-aws-sso.git?ref${local.vars.locals.release_tag}//modules/permission-sets>"
}
include {
path = find_in_parent_folders()
}
include "root" {
path = find_in_parent_folders()
expose = true
merge_strategy = "deep"
}
inputs = {
permission_sets = [
{
name = "sample_permission_set"
description = "Permission set created with Terragrunt"
relay_state = "",
session_duration = "PT10800S",
tags = {},
inline_policy = "",
policy_attachments = ["arn:aws:iam::aws:policy/job-function/ViewOnlyAccess"]
customer_managed_policy_attachments = []
default = []
}
]
}
It worked when I referenced a local copy of the permission set submodule.
I guess I’m just committing a mistake in the way I set the source.
yes, shared modules like permission-sets are not supposed to be used directly in terragrunt. See https://terragrunt.gruntwork.io/docs/reference/config-blocks-and-attributes/#a-note-about-using-modules-from-the-registry for the explanation.
Learn about all the blocks and attributes supported in the terragrunt configuration file.
ok, thank you
although, it created the resources
using the local copy of the submodule
I wonder why it does not detect any changes if I run the gitlab repo as a source
You should check the content of .terragrunt-cache. See what was copied in both cases.
thanks for the tip
terraform {
source = "git::<https://github.com/cloudposse/terraform-aws-sso.git//modules/permission-sets?ref=${local.vars.locals.release_tag}>"
}
All chnages are detected and applied correctly after referencing to the submodule in that format
v1.5.7 1.5.7 (September 7, 2023) BUG FIXES: terraform init: Terraform will no longer allow downloading remote modules to invalid paths. (#33745) terraform_remote_state: prevent future possible incompatibility with states which include unknown check block result kinds. (<a href=”https://github.com/hashicorp/terraform/issues/33818“…
We install remote modules prior to showing any validation errors during init so that we can show errors about the core version requirement before we do anything else. Unfortunately, this means that…
Terraform 1.5 introduced a new check result kind, which causes a decode failure when read by Terraform 1.3 and 1.4. This means that a 1.5+ state file cannot be read by the terraform_remote_state da…
2023-09-08
2023-09-09
Hy folks, I’m trying to create a public s3 bucket, So objects can only be read-only by public and write access via keys. Below is my code. After bucket creation i can not access the objects via object url
module "s3_public_bucket" {
source = "cloudposse/s3-bucket/aws"
version = "4.0.0"
name = "${var.name}-${var.environment}-assets"
s3_object_ownership = "BucketOwnerEnforced"
acl = "public-read"
enabled = true
user_enabled = false
versioning_enabled = false
ignore_public_acls = false
block_public_acls = false
block_public_policy = false
force_destroy = true
sse_algorithm = "AES256"
allow_encrypted_uploads_only = true
allow_ssl_requests_only = true
cors_configuration = [
{
allowed_origins = ["*"]
allowed_methods = ["GET", "HEAD", ]
allowed_headers = ["*"]
expose_headers = []
max_age_seconds = "3000"
}
]
allowed_bucket_actions = [
"s3:ListBucket", "s3:ListBucketMultipartUploads", "s3:ListObjects", "s3:ListMultipartUploadParts", "s3:PutObject",
"s3:PutObjectTagging", "s3:GetObject", "s3:GetObjectVersion", "s3:GetObjectTagging", "s3:AbortMultipartUpload",
"s3:ReplicateObject", "s3:RestoreObject", "s3:BatchDelete", "s3:DeleteObject", "s3:DeleteObjectVersion",
"s3:DeleteMultipleObjects", "s3:*"
]
lifecycle_configuration_rules = []
}
What’s wrong here?
This is a bit of a meta comment, but it’s generally recommended to use cloudfront in front of an S3 bucket for reading rather than allowing people to access the bucket directly.
2023-09-10
why “s3:*” at the end?
2023-09-11
I would appreciate if you could take a look on the PR
Its for firewall-manager - [shield_advanced.tf](http://shield_advanced.tf)
@Dan Miller (Cloud Posse)
@Gabriela Campana (Cloud Posse)
@Elad Levi Please see comments
Hi @Gabriela Campana (Cloud Posse) Just did what @Andriy Knysh (Cloud Posse) asked.
@Elad Levi Andriy made more comments
Hey folks, we open-sourced a li’l reusable GitHub Action workflow to run Terraform commands via PR comments: for a CLI-like experience on the web. To demo how we use the workflow:
1st PR comment: For example, let’s plan this configuration from a given directory in ‘dev’ workspace with a variable file.
-terraform=plan -chdir=stacks/sample_instance -workspace=dev -var-file=env/dev.tfvars
2nd comment: After reviewing the plan output, apply the above planned configuration.
-terraform=apply -chdir=stacks/sample_instance -workspace=dev -var-file=env/dev.tfvars3rd comment: To clean up afterwards, let’s plan a targeted destruction of resources in the same configuration.
-terraform=plan -destroy -target=aws_instance.sample,data.aws_ami.ubuntu -chdir=stacks/sample_instance -workspace=dev -var-file=env/dev.tfvars4th comment: After reviewing the destructive plan output, apply the above planned configuration.
-terraform=apply -destroy -target=aws_instance.sample,data.aws_ami.ubuntu -chdir=stacks/sample_instance -workspace=dev -var-file=env/dev.tfvarsInternally, found it ideal for DevOps/Platforms engineers to promote self-service of infra-as-code without the overhead of self-hosted runners or VMs like Atlantis.
There’re some other quality-of-life improvements to trigger the workflow more seamlessly, but would be stoked to have your usage feedback/consideration or edge-cases that have yet to be patched. Cheers!
Reusable workflow CI/CD to interface Terraform CLI via GitHub PR comments.
I need to setup Aws Organization, SSO, etc and I have been looking at AFT, account factory, control tower and I wonder if I should go with AFT or just do everything independently ?
I have seen AFT and is a big of a monster with all this step functions and lambdas and such
and in this client I will not need to create accounts all the time
i don’t really see a huge value to AFT. creating an account is a single, one-time call to the org:CreateAccount api. i just use the aws-cli instead
AFT is a lot of complexity for so little value
yes it is a lot of stuff just to create accounts with sso and such
SSO is another story. tons of customization required to get it into shape for any given environment/customer. hard to see any one-size-fits-all module really working out
I’m using gsuite in my case
are you going to use SCIM also? gsuite has an interesting limitation where, though it can sync users, it can’t (yet) sync groups to to aws sso
I was thinking to use that
I set up AFT last year. It is kind of a pain. If you do it wrong, you get half set up accounts, and then it’s a pain to troubleshoot and rectify. That said, when creating several accounts, it was nice to get new accounts setup already with an IAM role for Atlantis to do the rest.
if you want another option that will create such a role and doesn’t require AFT, we have a lambda wrapped in a terraform module that uses the role provisioned by org:CreateAccount to create a role in a new account https://github.com/plus3it/terraform-aws-org-new-account-iam-role
Terraform module that creates an IAM Role in a new account (useful for bootstrapping)
we use that to create a role for the CI/CD system, and then use a import block in the account’s tf config to bring the role back into management. pretty easy really
ohhhhh that is cool, that is a good idea too
we’re about to start doing that import trick for backend s3/ddb configs also. simplify that bootstrap, while also managing the config “normally” with tf
you do a lookup and then an import?
Nah, no need for lookup. The import id is predictable and fixed
import {
to = aws_iam_role.this
id = "NameOfCiRole"
}
ohhhhh right…cool interesting
2023-09-12
Very interesting move by Google https://cloud.google.com/infrastructure-manager/docs/overview
Learn about the features and benefits of Infrastructure Manager.
i wonder … why is that not seen as a competitor to TFC by Hashi ?
Learn about the features and benefits of Infrastructure Manager.
google is hitching their wagon to Hashicorp for now at least. They have jointly managed tickets for support, had a joint talk at Cloud Next, Hashicorp were on their podcast recently, and it looks like they’ll be supporting terraform for their on-prem sovereign cloud.
Unclear how much heads up google had or how long the agreements are for, I guess the real decision point would be when there’s a breaking TF change they add support for in their managed version.
Wow
“To work with Infra Manager, you should be familiar with Terraform, which is an open source tool.”
 sounds like they may need a new open source tool.
sounds like they may need a new open source tool.
2023-09-13
Hi, does anyone has a proper solution how to build a standard 3-tier (public/private/data) architecture on AWS with cloudposse modules? “dynamic-subnets” just creates public/private, data is missing. “cloudposse/rds” not creating any subnets. “named-subnets” creates subnets only in a single AZ. Workaround would be to stack maybe “”dynamic-subnets”” and “named-subnets” in my own module together.
The concept of “data” subnets is not really suited to cloud workloads
You will probably have to roll your own implementation for this if it’s a requirement foisted upon you. If you have the power to change this requirement, I recommend doing so
dynamic-subnets can create multiple subnets per AZ. You can have a set of private subnets (for backend, database, etc.) and a set of public subnets if needed
anything more complicated than that, you can create your own module
Yeah we just use a bunch of the dynamic modules, i’m probably a freak here but i actually don’t like making too deep for modules. IMO terraform is more a manifest language than a functional one. If i can’t look at 1-2 files and understand what is being done it detracts from some of the niceties of iac.
I feel like there’s a habbit of making stuff super DRY but sometimes copy paste has its merits if its making it easier to see whats going on for a reviewer
v1.3.10 1.3.10 (September 13, 2023) BUG FIXES: terraform_remote_state: fix incompatibility with states produced by Terraform 1.5 or later which include check block results. (#33813)
Terraform 1.5 introduced a new check result kind, which causes a decode failure when read by Terraform 1.3 and 1.4. This means that a 1.5+ state file cannot be read by the terraform_remote_state da…
v1.4.7 1.4.7 (September 13, 2023) BUG FIXES: terraform_remote_state: fix incompatibility with states produced by Terraform 1.5 or later which include check block results. (#33814)
Terraform 1.5 introduced a new check result kind, which causes a decode failure when read by Terraform 1.3 and 1.4. This means that a 1.5+ state file cannot be read by the terraform_remote_state da…
2023-09-14
v1.5.7 1.5.7 (September 7, 2023) BUG FIXES: terraform init: Terraform will no longer allow downloading remote modules to invalid paths. (#33745) terraform_remote_state: prevent future possible incompatibility with states which include unknown check block result kinds. (<a href=”https://github.com/hashicorp/terraform/issues/33818“…
We install remote modules prior to showing any validation errors during init so that we can show errors about the core version requirement before we do anything else. Unfortunately, this means that…
Terraform 1.5 introduced a new check result kind, which causes a decode failure when read by Terraform 1.3 and 1.4. This means that a 1.5+ state file cannot be read by the terraform_remote_state da…
v1.6.0-beta2 backport of commit 3845650 (#33895)
Co-authored-by: Liam Cervante
Terraform enables you to safely and predictably create, change, and improve infrastructure. It is a source-available tool that codifies APIs into declarative configuration files that can be shared amongst team members, treated as code, edited, reviewed, and versioned. - Fix typo in login link from test command doc page · hashicorp/terraform@3845650
Backport This PR is auto-generated from #33892 to be assessed for backporting due to the inclusion of the label 1.6-backport. The below text is copied from the body of the original PR.
d’oh
v1.6.0-beta1 1.6.0-beta1 (August 31, 2023) UPGRADE NOTES: On macOS, Terraform now requires macOS 10.15 Catalina or later; support for previous versions has been discontinued. On Windows, Terraform now at least Windows 10 or Windows Server 2016; support for previous versions has been discontinued. The S3 backend has a number of significant changes to its configuration format in this release, intended to match with recent changes in the hashicorp/aws provider: Configuration settings related to assuming IAM…
1.6.0-beta1 (August 31, 2023) UPGRADE NOTES:
On macOS, Terraform now requires macOS 10.15 Catalina or later; support for previous versions has been discontinued. On Windows, Terraform now at least…
v1.6.0-beta2 1.6.0-beta2 (September 14, 2023) UPGRADE NOTES: On macOS, Terraform now requires macOS 10.15 Catalina or later; support for previous versions has been discontinued. On Windows, Terraform now at least Windows 10 or Windows Server 2016; support for previous versions has been discontinued. The S3 backend has a number of significant changes to its configuration format in this release, intended to match with recent changes in the hashicorp/aws provider: Configuration settings related to assuming…
1.6.0-beta2 (September 14, 2023) UPGRADE NOTES:
On macOS, Terraform now requires macOS 10.15 Catalina or later; support for previous versions has been discontinued. On Windows, Terraform now at le…
We’re doing a pretty big refactor of an old legacy prod environment and moving to the null-label for everything because of the obvious advantages, however for prod items where aws doesn’t allow renaming of the asset without blowing it away which isn’t practical does/has cloudposse got a pattern for managing that with null-label? The trivial thing is for us to just add a ignore_changes and import the old resources - but that means that we basically have to commit ignore_changes to the resouces in any modules we have that have context embedded which doesn’t seem ideal. Is it just a tough sh*t type thing or is there some pattern that you guys have found works best? The previous team was super loose with naming convs so they dont give nice consistent patterns.
Ignoring changes on the name seems fine to me. How often do you change names?
I wish Terraform had a message when ignore changes was active though, to help debugging
Your use case makes sense, although we haven’t really had to deal with it too often. Mostly, in the case of S3 buckets in which case we supply an override name for the bucket.
Ignoring changes seems reasonable.
2023-09-15
Hi folks,
I wonder if anyone has few tips around working and debugging complex data structures?
Console doesn’t always help as you can’t use dynamic blocks or for_each , not to mentioned some basic features like (https://github.com/paololazzari/terraform-repl) .
Do you have your own dummy/ fake module which is generic enough to allow you to try things out w/o having to create real resources in cloud envs ?
May be local_file …
you want to expand a bit more please ?
That is one way but i wonr’t be able to use the native for_each or dynamic block.
I am also looking at https://github.com/gruntwork-io/terraform-fake-modules as is an interesting idea
back in the days of Saltstack i used to have what you suggested and it was working v well since it was full j2
Introduction This how-to article explains how you can leverage the local_file resource in combination with the functions jsonencode and templatefile to output a map of values to a text file. Use…
I believe you can use for_each this way (untested):
resource local_file "test" {
for_each = toset(["a","b"])
name = "file${each.key}.txt"
content = "test ${each.value}"
}
But you’re right about dynamic blocks.
Right, is better than console. Thx a bunch for giving me few ideas
you’re welcome
I’m not entirely sure about what you’re trying to do.
Generally if I have to do some messy hcl transformations I might break that out into a config module
Which at the end of the day is just a directory with terraform variables, locals and outputs, with no resources. To make a stateless/pure module
You can then just use a test.tfvars file or similar to test, and run the outputs through jq if you really want.
There’s tftest for python if you need something a bit more structured for handling inputs and outputs
All, Wondering if email does does not support sns topic module
Terraform sns_topic_subscription partially supports email
https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/sns_topic_subscription.html
•
protocol- (Required) Protocol to use. Valid values are:sqs,sms,lambda,firehose, andapplication. Protocolsemail-json,httpandhttpsare also valid but partially supported. See details below. If anaws_sns_topic_subscriptionuses a partially-supported protocol and the subscription is not confirmed, either through automatic confirmation or means outside of Terraform (e.g., clicking on a “Confirm Subscription” link in an email), Terraform cannot delete / unsubscribe the subscription. Attempting todestroyan unconfirmed subscription will remove theaws_sns_topic_subscriptionfrom Terraform’s state but *will not* remove the subscription from AWS. Thepending_confirmationattribute provides confirmation status.
@Dan Miller (Cloud Posse) Can you point on how to set the topic name using cloudposse module
Have used name variable..but it is not working
without using context.tf
module "sns" {
source = "cloudposse/sns-topic/aws"
# Cloud Posse recommends pinning every module to a specific version
# version = "x.x.x"
attributes = var.attributes
name = var.name
namespace = var.namespace
stage = var.stage
subscribers = {
email = {
protocol = "email"
endpoint = "[email protected]"
endpoint_auto_confirms = false
}
}
sqs_dlq_enabled = false
}
module "sns" {
source = "cloudposse/sns-topic/aws"
# Cloud Posse recommends pinning every module to a specific version
# version = "x.x.x"
name = "sns_topic_example"
subscribers = {
email = {
protocol = "email"
endpoint = "[email protected]"
endpoint_auto_confirms = false
}
}
sqs_dlq_enabled = false
}
let me check
thanks for response
@Dan Miller (Cloud Posse) Thank you able to create sns topic with required name but experiencing an issue with outputs.
value = sns_topic_arn.arn
A managed resource sns_topic_arn arn has not been declared in the root module
nevermind sorted it out.
2023-09-16
hi, does anyone here have any good resources for advanced terraforming? how do i bring my environment to the next level is my question i guess.
What problems or limitations do you face? What is your current level?
2023-09-18
hey all.. we have a gap in our module registry.. whilst it’s pretty easy to find a module, it can be a little convoluted on just exactly how to consume the module.. we use tf-docs to generate documentation but thinking it’d be helpful if there was like a dummy repo/branch with an example? in which case, could you use a long-running branch (per module repo) with a set of tfvars that goes off and does a plan/apply then destroy to ensure any code changes don’t break the module? could you then also use this to test for any breaking changes to the module? keen to hear how others are tackling this..

Yes, @loren is correct. Modules should have an examples folder, with different examples in separate sub folders. Ideally then, terratest is also used to validate each example as part of the CI process. See Cloud Posse modules for examples
2023-09-20
v1.6.0-beta3 1.6.0-beta3 (September 20, 2023) UPGRADE NOTES:
On macOS, Terraform now requires macOS 10.15 Catalina or later; support for previous versions has been discontinued. On Windows, Terraform now at least Windows 10 or Windows Server 2016; support for previous versions has been discontinued. The S3 backend has a number of significant changes to its configuration format in this release, intended to match with recent changes in the hashicorp/aws provider:
Configuration settings related to assuming…
1.6.0-beta3 (September 20, 2023) UPGRADE NOTES:
On macOS, Terraform now requires macOS 10.15 Catalina or later; support for previous versions has been discontinued. On Windows, Terraform now at le…
Linux Foundation Launches OpenTofu: A New Open Source Alternative to Terraform, https://www.linuxfoundation.org/press/announcing-opentofu

Backed by industry leaders and hundreds of developers, OpenTofu is set to become the go-to infrastructure as code solution.
Implication s for the name of this Channel?
Backed by industry leaders and hundreds of developers, OpenTofu is set to become the go-to infrastructure as code solution.
I’m trying to create an aws aurora cluster with mysql 5.7 using cloudposse terraform-aws-rds-cluster.
engine="aurora-mysql" with family="aurora-mysql5.7" gives the error DBParameterGroupFamily aurora-mysql5.7 cannot be used for this instance. Please use a Parameter Group with DBParameterGroupFamily aurora-mysql8.0. Is it no longer possible to create a mysql 5.7 cluster? Also, I’d like to see what aws api call terraform is making. i’ve turned on logging TF_LOG_PROVIDER=TRACE but that only shows the response, not the request. Any insight is appreciated!
Have you also set engine version? The default version is 8
Logging also shows the request, maybe you missed it in the spam
thanks, that sounds promising! I don’t see anything like engine version in the param list. Know what it’s called offhand?
ah - found it
BINGO! Thank you Alex!!
When you use logging, consider -parallelism 1 or whatever the option is called
2023-09-21

An exploration of Kubernetes Resource Manager and the Google Config Connector
short answer from me: no if your usecase fits entirely in a k8 cluster then sure its an option but the subset of things that this article touches on that live inside the cluster is a really small subset of the full picture.
An exploration of Kubernetes Resource Manager and the Google Config Connector
Does Cloudposse publish like a module guidelines on how best to write the wrapper logic around the count? Like i see stuff like:
//
vpc_id = aws_vpc.default[0].id
vpc_id = join("",aws_vpc.default.*.id)
vpc_id = (other method from getting a count value).
I can’t really pick the pattern of how it’s done of like when a join makes more sense vs [0].x etc. I was wondering if there was a guide so i could keep any modules we write internally match the style guide of the rest
since terraform constantly evolved, we used diff ways of doing that. Probably the best way now is to use the one() function
vpc_id = one(aws_vpc.default[*].id)
Hi all! Does anyone know if terraform fmt -recursive can be enforced somehow to run locally (not in CI) without depend to someone manually run the command or install and run it in a pre-commit git hook?
in short no pre-commit hook is your best bet for automatic action, or editor configuration. But honestly if its not enforced in CI its a matter of time before it gets missed.
yy currently the CI part it’s passive (no edits) for TF
I asked to check if there is something out there that we haven’t found
for up until CI will enforce them
Thanks for your answer!
Well, you can run it in CI and fail the build if it doesn’t come up with a non-diff…
2023-09-22
Hey folks! I’m looking to help out with https://github.com/cloudposse/terraform-aws-ecs-container-definition. There are some open PRs related to ECS service connect that I’d love to help get merged. Can anyone help set me up as a contributor?
Terraform module to generate well-formed JSON documents (container definitions) that are passed to the aws_ecs_task_definition Terraform resource
Amazon ECS Service Connect provides management of service-to-service communication as Amazon ECS configuration. It does this by building both service discovery and a service mesh in Amazon ECS. This provides the complete configuration inside each Amazon ECS service that you manage by service deployments, a unified way to refer to your services within namespaces that doesn’t depend on the Amazon VPC DNS configuration, and standardized metrics and logs to monitor all of your applications on Amazon ECS. Amazon ECS Service Connect only interconnects Amazon ECS services.
what PR do you want to be reviewed and merged?
Terraform module to generate well-formed JSON documents (container definitions) that are passed to the aws_ecs_task_definition Terraform resource
Amazon ECS Service Connect provides management of service-to-service communication as Amazon ECS configuration. It does this by building both service discovery and a service mesh in Amazon ECS. This provides the complete configuration inside each Amazon ECS service that you manage by service deployments, a unified way to refer to your services within namespaces that doesn’t depend on the Amazon VPC DNS configuration, and standardized metrics and logs to monitor all of your applications on Amazon ECS. Amazon ECS Service Connect only interconnects Amazon ECS services.
There are actually two open PRs for the same change:
• https://github.com/cloudposse/terraform-aws-ecs-container-definition/pull/168
• https://github.com/cloudposse/terraform-aws-ecs-container-definition/pull/166
Just saw that https://github.com/cloudposse/terraform-aws-ecs-container-definition/pull/166 was merged, thanks for getting that in! Will let you know if I run into other issues related to ECS service connect.
what
• Add optional variable name to portMappings to allow Service Discovery registration
why
• Unable to allow ECS container definitions to register with Service Discovery
references
• closes #162
Do you mind flagging this PR for your team to review? https://github.com/cloudposse/terraform-aws-ecs-container-definition/pull/169 Looks like I’ll also need access to the appProtocol field and the previous PR updated var.container_definition but not var.port_mappings
what
• Adding missing fields to var.port_mappings (appProtocol, name, containerPortRange)
why
• So that devs have access to all of the available fields: https://docs.aws.amazon.com/AmazonECS/latest/APIReference/API_PortMapping.html
references
hey question, how to use different AWS_PROFILE/or AWS_ROLE_ARN for aws provider and AWS_PROFILE/or AWS_ROLE_ARN for s3 backend ? TLDR I want to have DRY code and the ability to run from local and also from CI. Seems that backend does not support env variables. Thanks
question, how to use different AWS_PROFILE/or AWS_ROLE_ARN for aws provider and AWS_PROFILE/or AWS_ROLE_ARN for s3 backend ? TLDR I want to have DRY code and the ability to run from local and also from CI. Seems that backend does not support env variables. Thanks
EDIT: of course its doable with terragrunt and conditions, but i am switching terragrunt for terramate
Should I use:
AWS_PROFILE=accountOne terraform init -backend-config="profile=accountTwo"
for local run and:
AWS_ROLE_ARN=arn-from-accountOne terraform init -backend-config="role_arn=arn-from-accountTwo"
for CI ?
Use the same in both environments. In the CI you can also write AWS cli profiles to its config file
I’m having trouble with the Spacelift space-admin component and getting the yaml config setup properly. I’m using the examples from https://docs.cloudposse.com/components/library/aws/spacelift/spaces/, but am hitting an error I can’t figure out (in thread).
Error: Invalid index
│
│ on main.tf line 4, in locals:
│ 4: root_admin_stack_name = local.create_root_admin_stack ? keys(module.root_admin_stack_config.spacelift_stacks)[0] : null
│ ├────────────────
│ │ module.root_admin_stack_config.spacelift_stacks is object with no attributes
│
│ The given key does not identify an element in this collection value: the collection has no elements.
All the pieces are there to solve this and I’m failing somehow. :confused:
I did run into an issue applying the spaces module where the example code needed tweaked. Hoping this is just a tweak I can’t figure out.
the error sayas that module.root_admin_stack_config.spacelift_stacks is empty. Did you provision the root space and root admin stack first? (please review the steps here https://github.com/cloudposse/terraform-aws-components/tree/main/modules/spacelift)
@Matt Calhoun please confirm that the error is b/c the root space or root admin stack was not provisioned first
atmos terraform apply spaces -s root-gbl-spacelift
atmos terraform apply admin-stack -s root-gbl-spacelift
atmos terraform apply spacelift/worker-pool -s core-ue1-auto
I’m under the impression from the instructions that running atmos terraform apply admin-stack -s root-gbl-spacelift is the step of provisioning the root stack? That’s what’s failing.
yes, if the first step is failing, then local.create_root_admin_stack ? keys(module.root_admin_stack_config.spacelift_stacks)[0] : null is not the correct expression when you do Spacelift cold start. @Matt Calhoun please take a look at this
@RickA in https://docs.cloudposse.com/components/library/aws/spacelift/, did you set the root_administrative variable?
These components are responsible for setting up Spacelift and include three components: spacelift/admin-stack, spacelift/spaces, and spacelift/worker-pool.
components:
terraform:
# This admin stack creates other "admin" stacks
admin-stack:
metadata:
component: spacelift/admin-stack
inherits:
- admin-stack/default
settings:
spacelift:
root_administrative: true
labels:
- root-admin
- admin
vars:
enabled: true
root_admin_stack: true # This stack will be created in the root space and will create all the other admin stacks as children.
context_filters: # context_filters determine which child stacks to manage with this admin stack
administrative: true # This stack is managing all the other admin stacks
root_administrative: false # We don't want this stack to also find itself in the config and add itself a second time
labels:
I’ve attempted to set root_administrative with false (what is on the document page) and true. Thinking perhaps it’d need done manually one way and toggled the other when Spacelift is in the mix. Same error in both values.
Rick, I’m wondering if there may be a bug in the code. Do you have other admin stacks defined in the stack config (but not yet applied)? If not, there may be an issue where we are expecting to find them in stack config, but aren’t finding them, and therefore the error that you are experiencing. Also, if it helps, there is a very small repo in my personal GitHub that I used to setup the minimal use case for this and there may be some useful config in there.
I do have a config laying around that’s for an admin stack that I want the root to create.
Thanks for the link. As soon as I’m able I’ll run through things and report back.
Just a follow up on the topic to say thanks…
Matt your repo helped, appreciate it. I have a suspicion that I made mistakes in the docs examples somewhere as that response ought to have reappeared otherwise. I had different errors in the infra-live example that I found to be user error. The errors generated aren’t so helpful, but also I have no idea how we’d make them better when the issue was me putting bad/unexpected config into the yaml file.
Thanks again and have a great rest of your day/weekend.
2023-09-23
2023-09-25
2023-09-26
Can anyone help how to use for_each in this case ? The problem is that I need to reference both modules so for_each fails to cyclic dependency. ( It does work for single certificate and domain validation, but I am not sure how to handle this with list of maps and for_each ) Thanks
locals {
certificates = [{
name = foo.bar.com
sans = ["foo.bar.com"]
}]
}
module "acm" {
for_each = { for c in local.certificates : c.name => c }
source = "terraform-aws-modules/acm/aws"
version = "~> 4.0"
domain_name = each.value.name
subject_alternative_names = each.value.sans
create_route53_records = false
validation_record_fqdns = module.route53_records[each.value.name].validation_route53_record_fqdns < --------------- THIS ?
}
module "route53_records" {
for_each = module.acm
source = "terraform-aws-modules/acm/aws"
version = "~> 4.0"
providers = {
aws = aws.organization
}
create_certificate = false
create_route53_records_only = true
distinct_domain_names = each.value.distinct_domain_names
zone_id = local.environments.organization.route53_zone_id
acm_certificate_domain_validation_options = each.value.acm_certificate_domain_validation_options
}
Even without considering the for_each loop, there’s a cyclic dependency between the 2 modules. You should first try to break this one.
But its working for single certification..
Hey folks, please have anyone used terraform to handle AWS RDS Blue/green approach to upgrade MYSQL RDS from 5.7 to 8.0
I have a cloudposse sg module and an alb module paired, but when I change the name of the sg or an sg rule (even with create_before_destroy enabled) the load balancer is not updating with the new sg until the next run. Is there something wrong with this code?
module "alb_security_group" {
source = "cloudposse/security-group/aws"
version = "2.2.0"
attributes = ["lb", "sg"]
allow_all_egress = false
rules = [{
description = "Allow LB Traffic to ECS"
cidr_blocks = ["10.22.0.0/22"]
from_port = 80
protocol = "tcp"
self = "false"
to_port = 80
type = "egress"
}] # #var.lb_object.security_group_rules
vpc_id = var.lb_object.vpc_id
context = module.this.context
create_before_destroy = true
}
module "alb" {
source = "cloudposse/alb/aws"
version = "1.10.0"
vpc_id = var.lb_object.vpc_id
security_group_ids = [ module.alb_security_group.id ]
....
Did you try adding a depends_on to the module.alb block, to see if the changes then happen in the same run ?
depends_on = [
module.alb_security_group
]
If that works, and you’re curious, you could use terraform graph with/without the depends_on to shed some more light on it.

The terraform graph command generates a visual representation of a configuration or execution plan that you can use to generate charts.
That did not resolve it
I don’t understand why, but the compact call is what is causing the issue
https://github.com/cloudposse/terraform-aws-alb/blob/main/main.tf#L79-L81
security_groups = compact(
concat(var.security_group_ids, [one(aws_security_group.default[*].id)]),
)
concat(var.security_group_ids, [join("", aws_security_group.default.*.id)])
What if instead of module.alb_security_group, you added its egress rule alone to the security group given by module.alb.security_group_id ?
Or, my preference (and because module.alb’s SG already allows full egress) just create an ingress rule on the ECS SG, specifying source_security_group_id = module.alb.security_group_id .
What if instead of module.alb_security_group, you added its egress rule alone to the security group given by module.alb.security_group_id ?
whether the egress is in the rules or rules_matrix var it doesn’t seem to matter. The issue seems to be directly with how the alb module handles the concat of the var.security_group_ids and the default group created by the module
Or, my preference (and because module.alb’s SG already allows full egress) just create an ingress rule on the ECS SG, specifying source_security_group_id = module.alb.security_group_id .
I figured allowing default egress anywhere (even an lb) was not a best practice. We also restrict the ingress on the ECS service side as well.
If I did use the default security group provided with the module (var.security_group_enabled) then this might not be an issue.
I figured allowing default egress anywhere (even an lb) was not a best practice.
Personally I like setting egress targets to other security groups (source_security_group_id) … precise, maintainable, and still applies defense-in-depth, but depending on the circumstances I might not mind allowing egress-anywhere (e.g. if the LB only accepted internal traffic). Maybe raise an issue on the alb module to support input egress rules (and/or the security_groups expression of course).
2023-09-27
RDS Blue-Green Updates & TF State desync. When applying an attribute change to a primary RDS instance with a read replica, such as the CA, then the instance blue-greens and also replaces the replica. Afterward, if you try to apply a change to the replica, it attempts to act against it’s defined resource which is now named “-old1”, as it’s been kept around after the blue-green sequence from AWS. To correct this, I updated the state file to point at the correct endpoint and resource ID… Has anyone seen this, or have a better approach to fixing it? Terraform refresh wouldn’t do it, since it would still hit the resource id of the “-old1” instance.
https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/blue-green-deployments-overview.html
@Max Lobur (Cloud Posse)
Yeeep. This is reproducible.
- Create an RDS instance with a read replica and blue-green enabled.
- Update something that triggers b/g. IE: the CA with apply_immediately true.
- The primary will have the new instance reflected in the state file at instances.attributes.id, ~.resource_id.
- The read replica will not have its new ID populated in the state file, BUT does see its address and endpoint fields updated to reflect “-old1”. At this point, you have to go put in the new ID and remove -old1 from the affected fields to associate the resource with the AWS issued (bg) one.
Crud.
There’s a line in the doc linked above that mentions old instances are not deleted. This is true for the read replica, but the primary instance doesn’t get left behind. I bet this is the break point for this workflow.
I have a depends_on in the replica… I wonder if that might be the culprit. I can imagine it snagging on the update logic. Trying without.
Second thing… Blue/green makes the specified CA (rds-ca-rsa2048-g1) fall off on the AWS issued green instance, meaning it gets the default (rds-ca-2019), which is expiring and must be updated.
Here’s the issue on this one. https://github.com/hashicorp/terraform-provider-aws/issues/33702
Terraform Core Version
1.2.2
AWS Provider Version
5.18.1
Affected Resource(s)
• aws_db_instance
Expected Behavior
An RDS Instance with a read replica when configured with blue_green_update:enabled, should execute updates requiring instance refreshes and update the terraform state file with the ID’s of the new instances.
Actual Behavior
When a blue/green update is actioned, the primary instance is replaced and has its ID updated in the terraform state file as expected, but the read replica is left pointing at the now named ‘-old1’ instance instead of the replacement.
Note that when the primary is replaced its “-old1” instance is deleted, but the read replica’s “-old1” instance is persisted.
This situation can be resolved by editing the state file entries for the read replica with the ID of the new instance, and removing the “-old1” string from the address, endpoint, etc.
See the Blue Green Deployments Overview for more on this process, including details on “old1”, and the fact that the instances should (both?) remain afterwards.
Relevant Error/Panic Output Snippet
No response
Terraform Configuration Files
provider "aws" {
region = "us-east-2"
}
module "vpc" {
source = "terraform-aws-modules/vpc/aws"
name = "test"
cidr = "10.0.0.0/16"
azs = ["us-east-2a", "us-east-2b", "us-east-2c"]
private_subnets = ["10.0.1.0/24", "10.0.2.0/24", "10.0.3.0/24"]
public_subnets = ["10.0.101.0/24", "10.0.102.0/24", "10.0.103.0/24"]
enable_nat_gateway = true
enable_vpn_gateway = true
}
resource "aws_security_group" "test" {
vpc_id = module.vpc.vpc_id
ingress {
from_port = 3306
to_port = 3306
protocol = "tcp"
cidr_blocks = concat(module.vpc.private_subnets_cidr_blocks)
}
egress {
from_port = 0
to_port = 65535
protocol = "tcp"
cidr_blocks = concat(module.vpc.private_subnets_cidr_blocks)
}
}
resource "aws_db_subnet_group" "test" {
subnet_ids = module.vpc.private_subnets
}
resource "aws_db_parameter_group" "test" {
family = "mariadb10.11"
}
resource "aws_db_instance" "primary" {
identifier = "test"
engine = "mariadb"
engine_version = "10.11.5"
instance_class = "db.t4g.small"
storage_type = "gp3"
allocated_storage = 50
max_allocated_storage = 2000
username = "david"
password = "hasselhoff"
multi_az = true
db_subnet_group_name = aws_db_subnet_group.test.id
vpc_security_group_ids = [aws_security_group.test.id]
parameter_group_name = aws_db_parameter_group.test.name
publicly_accessible = false
maintenance_window = "Tue:00:00-Tue:02:00"
skip_final_snapshot = false
backup_retention_period = 14
backup_window = "22:00-23:59"
delete_automated_backups = false
apply_immediately = true
blue_green_update {
enabled = true
}
}
resource "aws_db_instance" "replica" {
identifier = "test-replica"
engine = "mariadb"
engine_version = "10.11.5"
instance_class = "db.t4g.small"
replicate_source_db = aws_db_instance.primary.identifier
storage_type = "gp3"
max_allocated_storage = 2000
multi_az = true
vpc_security_group_ids = [aws_security_group.test.id]
parameter_group_name = aws_db_parameter_group.test.name
publicly_accessible = false
maintenance_window = "Tue:00:00-Tue:02:00"
skip_final_snapshot = false
backup_retention_period = 14
backup_window = "22:00-23:59"
delete_automated_backups = false
apply_immediately = true
}
Steps to Reproduce
- Create an RDS instance with the example above.
- Add the following parameter to both instances. (Or something else to cause a b/g.)
ca_cert_identifier = "<some-other-cert>" - Inspect the state file to observe the replica state pointing at the “old1” instance rather than the newly provisioned one. Here’s a jq for convenience:
jq -r '.resources[] | select(.name == "replica") | .instances[].attributes | "\(.identifier)\n\(.id)"' terraform.tfstate
Certs are listed here if needed.
Note that during blue/green, you may, depending on your configurations, see the ca change to something different than is defined in the tf. This is detailed here, and is unrelated to this issue, but may present if using the ca update in reproducing it. TLDR: It’s a conflict between the AWS default CA for that region and what’s specified in the TF conf.
Debug Output
No response
Panic Output
No response
Important Factoids
I’ve run this a few times with different TF confs and with the same result, including with the reproduction tf provided above.
The AWS Docs on RDS blue/green updates mention that instances should not be deleted afterwards, but in this situation we see that the primary is being deleted while the replica persists. A clue, maybe.
References
No response
Would you like to implement a fix?
No
Hey friends, could use a review on https://github.com/cloudposse/terraform-aws-ecs-container-definition/pull/169 when someone has time!
what
• Adding missing fields to var.port_mappings (appProtocol, name, containerPortRange)
why
• So that devs have access to all of the available fields: https://docs.aws.amazon.com/AmazonECS/latest/APIReference/API_PortMapping.html
references
Hi all, I could use some guidance on the best way to use the CloudPosse AWS Lambda module for my use case: https://github.com/cloudposse/terraform-aws-lambda-function
Here’s the situation:
• We’ll use Terraform to create the Lambda infrastructure and related resources in AWS (buckets, IAM roles/policies, etc…)
• An application deployment pipeline will bundle the Lambda function code into a .zip and drop it into S3.
• That .zip doesn’t exist yet, but I need to create the infrastructure.
• Application deployments should ideally not need to involve Terraform, but just drop a new object into the well-known S3 path for the .zip file.
Is this possible?
Can the cloudposse module handle creating a Lambda where the s3_bucket exists but the s3_key doesn’t yet? I just want to prep the infrastructure to be used later.
This may be the solution I use: https://github.com/hashicorp/terraform-provider-aws/issues/5945#issuecomment-496904498
- Provide a dummy filename for initial creation (though I don’t want to commit a
.zipfile to the git repo that TF is in) - Set a lifecycle rule to ignore
s3_keywhen that eventually gets used.
Unfortunately the cloudposse/lambda-function/aws module doesn’t support s3_key as a lifecycle rule
Manage the resources yourself, rather than using the module. It doesn’t do anything particularly complex
Thanks, and yeah I’m coming to that same realization myself.
v1.6.0-rc1 1.6.0-rc1 (September 27, 2023) UPGRADE NOTES:
On macOS, Terraform now requires macOS 10.15 Catalina or later; support for previous versions has been discontinued. On Windows, Terraform now at least Windows 10 or Windows Server 2016; support for previous versions has been discontinued. The S3 backend has a number of significant changes to its configuration format in this release, intended to match with recent changes in the hashicorp/aws provider:
Configuration settings related to assuming…
2023-09-28
Hi, how can I use the sqs module? It is asking me to set up the atmos config file. Is there a way to do it without Atmos?
Atmos components are actually wrappers with some opinioned practices of fetching remote state and other things.
So if you don’t want to use atmos, you just use the wrapped terraform modules. In your case, try use https://github.com/cloudposse/terraform-aws-components/tree/1.313.0/modules/sqs-queue/modules/terraform-aws-sqs-queue
It is actually just a wrapper of stock sqs resource from AWS provider.
as you can see here https://github.com/cloudposse/terraform-aws-components/blob/1.313.0/modules/sqs-queue/modules/terraform-aws-sqs-queue/main.tf, the component/module is nothing more than a few lines of code configuring resource "aws_sqs_queue" - you can just use the same code
locals {
enabled = module.this.enabled
}
resource "aws_sqs_queue" "default" {
count = local.enabled ? 1 : 0
name = var.fifo_queue ? "${module.this.id}.fifo" : module.this.id
visibility_timeout_seconds = var.visibility_timeout_seconds
message_retention_seconds = var.message_retention_seconds
max_message_size = var.max_message_size
delay_seconds = var.delay_seconds
receive_wait_time_seconds = var.receive_wait_time_seconds
policy = try(var.policy[0], null)
redrive_policy = try(var.redrive_policy[0], null)
fifo_queue = var.fifo_queue
fifo_throughput_limit = try(var.fifo_throughput_limit[0], null)
content_based_deduplication = var.content_based_deduplication
kms_master_key_id = try(var.kms_master_key_id[0], null)
kms_data_key_reuse_period_seconds = var.kms_data_key_reuse_period_seconds
deduplication_scope = try(var.deduplication_scope[0], null)
tags = module.this.tags
}
our terraform modules don’t require Atmos, you can use them as plain terraform https://github.com/cloudposse?q=terraform-&type=all&language=&sort=
our catalog of terraform components, on the other hand, can be configured with Atmos (but this is also not required) https://github.com/cloudposse/terraform-aws-components
Opinionated, self-contained Terraform root modules that each solve one, specific problem
Atmos allows you to separate code/implementation from configuration (in stacks). But you can use all those modules/components directly by providing all variables that they require
Note that I’ve been seeing issues with RDS Instances with read replicas having their CA updated then having that CA revert to the one expiring in 2024. The issue and solution are described here for anyone experiencing it. https://github.com/hashicorp/terraform-provider-aws/issues/33546#issuecomment-1739777113
2023-09-29
Hi everyone, we are trying to use this https://github.com/cloudposse/terraform-aws-cloudfront-s3-cdn/blob/0.76.0/main.tf repo when I enable the s3_origin_enabled = true, we are getting the issue at line number 210: data “aws_iam_policy_document” “combined” and remove the sid or make the unique , please use the unique sid , but now how fix the issue using the same repo anyone help to fix this issue
``` locals { enabled = module.this.enabled
# Encapsulate logic here so that it is not lost/scattered among the configuration website_enabled = local.enabled && var.website_enabled website_password_enabled = local.website_enabled && var.s3_website_password_enabled s3_origin_enabled = local.enabled && ! var.website_enabled create_s3_origin_bucket = local.enabled && var.origin_bucket == null s3_access_logging_enabled = local.enabled && (var.s3_access_logging_enabled == null ? length(var.s3_access_log_bucket_name) > 0 : var.s3_access_logging_enabled) create_cf_log_bucket = local.cloudfront_access_logging_enabled && local.cloudfront_access_log_create_bucket
create_cloudfront_origin_access_identity = local.enabled && length(compact([var.cloudfront_origin_access_identity_iam_arn])) == 0 # “” or null
origin_id = module.this.id origin_path = coalesce(var.origin_path, “/”) # Collect the information for whichever S3 bucket we are using as the origin origin_bucket_placeholder = { arn = “” bucket = “” website_domain = “” website_endpoint = “” bucket_regional_domain_name = “” } origin_bucket_options = { new = local.create_s3_origin_bucket ? aws_s3_bucket.origin[0] : null existing = local.enabled && var.origin_bucket != null ? data.aws_s3_bucket.origin[0] : null disabled = local.origin_bucket_placeholder } # Workaround for requirement that tertiary expression has to have exactly matching objects in both result values origin_bucket = local.origin_bucket_options[local.enabled ? (local.create_s3_origin_bucket ? “new” : “existing”) : “disabled”]
# Collect the information for cloudfront_origin_access_identity_iam and shorten the variable names cf_access_options = { new = local.create_cloudfront_origin_access_identity ? { arn = aws_cloudfront_origin_access_identity.default[0].iam_arn path = aws_cloudfront_origin_access_identity.default[0].cloudfront_access_identity_path } : null existing = { arn = var.cloudfront_origin_access_identity_iam_arn path = var.cloudfront_origin_access_identity_path } } cf_access = local.cf_access_options[local.create_cloudfront_origin_access_identity ? “new” : “existing”]
# Pick the IAM policy document based on whether the origin is an S3 origin or a Website origin iam_policy_document = local.enabled ? ( local.website_enabled ? data.aws_iam_policy_document.s3_website_origin[0].json : data.aws_iam_policy_document.s3_origin[0].json ) : “”
bucket = local.origin_bucket.bucket bucket_domain_name = var.website_enabled ? local.origin_bucket.website_endpoint : local.origin_bucket.bucket_regional_domain_name
override_origin_bucket_policy = local.enabled && var.override_origin_bucket_policy
lookup_cf_log_bucket = local.cloudfront_access_logging_enabled && ! local.cloudfront_access_log_create_bucket cf_log_bucket_domain = local.cloudfront_access_logging_enabled ? ( local.lookup_cf_log_bucket ? data.aws_s3_bucket.cf_logs[0].bucket_domain_name : module.logs.bucket_domain_name ) : “”
use_default_acm_certificate = var.acm_certificate_arn == “” minimum_protocol_version = var.minimum_protocol_version == “” ? (local.use_default_acm_certificate ? “TLSv1” : “TLSv1.2_2019”) : var.minimum_protocol_version
website_config = { redirect_all = [ { redirect_all_requests_to = var.redirect_all_requests_to } ] default = [ { index_document = var.index_document error_document = var.error_document routing_rules = var.routing_rules } ] } }
Make up for deprecated template_file and lack of templatestring
https://github.com/hashicorp/terraform-provider-template/issues/85
https://github.com/hashicorp/terraform/issues/26838
locals { override_policy = replace(replace(replace(var.additional_bucket_policy, “\({origin_path}", local.origin_path), "\){bucket_name}”, local.bucket), “$${cloudfront_origin_access_identity_iam_arn}”, local.cf_access.arn) }
module “origin_label” { source = “cloudposse/label/null” version = “0.25.0”
attributes = var.extra_origin_attributes
context = module.this.context }
resource “aws_cloudfront_origin_access_identity” “default” { count = local.create_cloudfront_origin_access_identity ? 1 : 0
comment = local.origin_id }
resource “random_password” “referer” { count = local.website_password_enabled ? 1 : 0
length = 32 special = false }
data “aws_iam_policy_document” “s3_origin” { count = local.s3_origin_enabled ? 1 : 0
override_json = local.override_policy
statement { sid = “S3GetObjectForCloudFront”
actions = ["s3:GetObject"]
resources = ["arn:aws:s3:::${local.bucket}${local.origin_path}*"]
principals {
type = "AWS"
identifiers = [local.cf_access.arn]
} }
statement { sid = “S3ListBucketForCloudFront”
actions = ["s3:ListBucket"]
resources = ["arn:aws:s3:::${local.bucket}"]
principals {
type = "AWS"
identifiers = [local.cf_access.arn]
} } }
data “aws_iam_policy_document” “s3_website_origin” { count = local.website_enabled ? 1 : 0
override_json = local.override_policy
statement { sid = “S3GetObjectForCloudFront”
actions = ["s3:GetObject"]
resources = ["arn:aws:s3:::${local.bucket}${local.origin_path}*"]
principals {
type = "AWS"
identifiers = ["*"]
}
dynamic "condition" {
for_each = local.website_password_enabled ? ["password"] : []
content {
test = "StringEquals"
variable = "aws:referer"
values = [random_password.referer[0].result]
}
} } }
data “aws_iam_policy_document” “deployment” { for_each = local.enabled ? var.deployment_principal_arns : {}
statement { actions = var.deployment_actions
resources = distinct(flatten([
[local.origin_bucket.arn],
formatlist("${local.origin_bucket.arn}/%s*", each.value),
]))
principals {
type = "AWS"
identifiers = [each.key]
} } }
data “aws_iam_policy_document” “s3_ssl_only” { count = var.allow_ssl_requests_only ? 1 : 0 statement { sid = “ForceSSLOnlyAccess” effect = “Deny” actions = [“s3:”] resources = [ local.origin_bucket.arn, “${local.origin_bucket.arn}/” ]
principals {
identifiers = ["*"]
type = "*"
}
condition {
test = "Bool"
values = ["false"]
variable = "aws:SecureTransport"
} } }
data “aws_iam_policy_document” “combined” { count = local.enabled ? 1 : 0
source_policy_documents = compact(concat( data.aws_iam_policy_document.s3_origin..json, data.aws_iam_policy_document.s3_website_origin..json, data.aws_iam_policy_document.s3_ssl_only..json, values(data.aws_iam_policy_document.deployment)[].json )) }
resource “aws_s3_bucket_policy” “default” { count = local.create_s3_origin_bucket || local.override_origin_bucket_policy ? 1 : 0
bucket = local.origin_bucket.bucket policy = join(“”, data.aws_iam_policy_document.combined.*.json) }
resource “aws_s3_bucket” “origin” {
#bridgecrew:skip=BC_AWS_S3_13:Skipping Enable S3 Bucket Logging because we cannot enable it by default because we do not have a default destination for it.
#bridgecrew:skip=CKV_AWS_52:Skipping Ensure S3 bucket has MFA delete enabled due to issue in terraform (https://github.com/hashicorp/terraform-provider-aws/issues/629).
count = local.create_s3_origin_bucket ? 1 : 0
bucket = module.origin_label.id acl = “private” tags = module.origin_label.tags force_destroy = var.origin_force_destroy
dynamic “server_side_encryption_configuration” { for_each = var.encryption_enabled ? [“true”] : []
content {
rule …
@Monica Hart
Hello! Just wondering, is the practice of using this setup.rpm.sh mentioned in our bastion component we received in order to grab user key information still in use?
#!/bin/bash
curl -1sLf '<https://dl.cloudsmith.io/public/cloudposse/packages/setup.rpm.sh>' | sudo -E bash
yum install -y chamber
for user_name in $(chamber list ${component_name}/ssh_pub_keys | cut -d$'\t' -f1 | tail -n +2);
do
groupadd $user_name;
useradd -m -g $user_name $user_name
mkdir /home/$user_name/.ssh
chmod 700 /home/$user_name/.ssh
cd /home/$user_name/.ssh
touch authorized_keys
chmod 600 authorized_keys
chamber read ${component_name}/ssh_pub_keys $user_name -q > authorized_keys
chown $user_name:$user_name -R /home/$user_name
done
echo "-----------------------"
echo "END OF CUSTOM USER DATA"
echo "-----------------------"
I’m not seeing chamber get installed when we deploy new bastion hosts is the issue I’m having.
We’re also not getting a successful connection when we try and connect with that Cloudsmith url
welllllll…. the current bastion user-data is of the opinion to add chamber to a docker image and then have the machine pull that. It’s admittedly more steps, but I guess if you can push this to ECR and update the bastion to have permissions to pull (I guess just add it to the ECR policy however you see fit), then you could just go that way.
#!/bin/bash
# Mount additional volume
echo "Mounting additional volume..."
while [ ! -b $(readlink -f /dev/sdh) ]; do echo 'waiting for device /dev/sdh'; sleep 5 ; done
blkid $(readlink -f /dev/sdh) || mkfs -t ext4 $(readlink -f /dev/sdh)
e2label $(readlink -f /dev/sdh) sdh-volume
grep -q ^LABEL=sdh-volume /etc/fstab || echo 'LABEL=sdh-volume /mnt ext4 defaults' >> /etc/fstab
grep -q \"^$(readlink -f /dev/sdh) /mnt \" /proc/mounts || mount /mnt
# Install docker
echo "Installing docker..."
amazon-linux-extras install docker
amazon-linux-extras enable docker
mkdir -p ~/.docker
echo '{ "credsStore": "ecr-login" }' > ~/.docker/config.json
service docker start
usermod -a -G docker ec2-user
# Additional Packages
echo "Installing Additional Packages"
yum install -y curl jq git gcc amazon-ecr-credential-helper
# Script
echo "Moving script to /usr/bin/container.sh"
sudo mv /tmp/container.sh /usr/bin/container.sh
echo "-----------------------"
echo "END OF CUSTOM USER DATA"
echo "-----------------------"
I’m reading that setup.rpm.sh since there’s probably still a one-off way to get it jiggered back into working order
testing this I think it works, but I did have to modify the script to do a sudo yum install -y chamber…. you might try that. But it should work well enough
if you get more issues, I’d recommend a couple ways forward. For one, cloud-init should be putting its scripts in /var/lib/cloud/instance… if you snoop around in there, you should find the scripts you need to re-run so you can see errors. If they don’t error out and chamber works when you run it from there, then the issue is deeper
you can use systemctl to look at any degraded units (you’ll probably find cloud init as one of them), and then you can inspect those logs using journalctl -xu <degraded unit name>. I could probably make a quick video showing how to diagnose this if you like. And you can always just run journalctl without any args and instead use the / command to start a search… you ought to be able to search for either chamber or yum and see helpful info there
journalctl uses a ‘vim-like’ mode, so you use the h, j, k, and l keys to move around and / to search down or ? to search up
Hey @Jeremy White (Cloud Posse) !! Thanks for looking into this for me
