#terraform (2024-10)
 Discussions related to Terraform or Terraform Modules
Discussions related to Terraform or Terraform Modules
Archive: https://archive.sweetops.com/terraform/
2024-10-01
Hi!
First sorry if this is not the best place to ask, I’ll move it to a different channel if it’s better,
I’m running into this issue when deploying a helm chart with the module:
terraform {
source = "git::<https://github.com/cloudposse/terraform-aws-helm-release.git//?ref=0.10.1>"
}
And I’m getting a constant drift for it in the metadata:
# helm_release.this[0] will be updated in-place
~ resource "helm_release" "this" {
id = "myapp"
~ metadata = [
- {
- app_version = "v2.8.6"
- chart = "myapp"
- name = "myapp"
- namespace = "myapp"
- revision = 16
- values = jsonencode(
{
...
Do you know what I can do so the information is properly understood and the drift only happening if there are real changes?
Thank you so much!
@Jeremy G (Cloud Posse)
@Igor Rodionov
I think that’s more about settings in the helm terraform provider. Be sure you don’t have any experiments enabled.
@Julio Chana this comes from helm provider
In version 2.13.2 metadata was output block https://registry.terraform.io/providers/hashicorp/helm/2.13.2/docs/resources/release#metadata
In version 2.14.0 they changed it to list of objects https://registry.terraform.io/providers/hashicorp/helm/2.14.0/docs/resources/release#metadata
Try pin helm provider to 2.13.2 and check if drift will be still there
Older helm provider versions didn’t show this metadata changes when terraform detected a change/run plan, and the new helm provider versions are posting a wall of text of metadata changes which have no real value (to me) and just clog up my tf plan output.
example doing a tf plan on a helm resource where we only updated the image tag var:
# module.api-eks.helm_release.app will be updated in-place
~ resource "helm_release" "app" {
id = "api"
~ metadata = [
- {
- app_version = "latest"
- chart = "api"
- name = "api"
- namespace = "production"
- revision = 1420
- values = jsonencode(
{
- appConfig = {
- apiBackendReplicationTaskId = "none"
- applicationMode = "none"
- baseApiUrl = "none"
- something = "else"
- foo = "bar"
-
< it goes on for many >
< many >
< lines >
< and it's of no value >
< just noise on tf plan >
let’s say we only have a field deploymentTimestamp updated. We’d rather see the changed field only on terraform plan, and suppress the whole metadata update, e.g. terraform plan should only show
# module.api-eks.helm_release.app will be updated in-place
~ resource "helm_release" "app" {
id = "api"
[...]
# (25 unchanged attributes hidden)
+ set {
+ name = "deploymentTimestamp"
+ value = "19012024-225905"
}
# (62 unchanged blocks hidden)
This way the terraform plan is clear and concise, more human (easier to read/follow) without the metadata removal. Does it make sense?
Terraform version, Kubernetes provider version and Kubernetes version
Terraform version: v1.6.5
Helm Provider version: v2.12.0 (same on v2.12.1)
Kubernetes version: v2.24.0
Terraform configuration
resource “helm_release” “app” { namespace = var.namespace != “” ? var.namespace : terraform.workspace chart = var.chart_name version = var.chart_version name = var.app_name timeout = var.deployment_timeout cleanup_on_fail = var.helm_cleanup_on_fail atomic = var.helm_atomic_creation max_history = var.helm_max_history wait = var.helm_wait_for_completion
dynamic “set” { for_each = local.k8s_app
content {
name = set.key
value = set.value
} }
values = var.some_ingress_values }
Question
Is there any way to suppress the metadata changes at terraform plan?
Terraform, Provider, Kubernetes and Helm Versions
Terraform version: v1.7.3
Provider version: v2.12.1
Kubernetes version: v1.29.2+k3s1
Affected Resource(s)
• helm_release
Terraform Configuration Files
terraform { required_providers { helm = { source = “hashicorp/helm” version = “2.12.1” } } }
provider “helm” { kubernetes { config_path = “~/.kube/config” } }
resource “helm_release” “this” { name = “redis” repository = “https://charts.bitnami.com/bitnami” chart = “redis” namespace = “cache” create_namespace = false version = “19.x” }
Debug Output
https://gist.github.com/meysam81/8b4c8805d7dcfa7dd116443c4cc42841
NOTE: In addition to Terraform debugging, please set HELM_DEBUG=1 to enable debugging info from helm.
Panic Output
Steps to Reproduce
Either of the following:
• terraform apply
• terraform plan -out tfplan && terraform apply tfplan
Expected Behavior
Even in the case where the latest chart version is the same as the running helm-release, it is still updating the metadata and trying to re-deploy the release. A frustrating experience really. Ansible helm module is doing a much better job in this regards when it comes to idempotency.
The funny thing is, if you pin the version to exact version, e.g. 19.0.1, this won’t happen and a No changes will be printed on the screen. But any version wildcard versioning causes the release to recompute the metadata. :shrug:
Actual Behavior
It finds metadata changed for every single plan-apply.
Important Factoids
Nothing special. I have tried this in different clusters with different versions. All have the same outcome.
References
Community Note
• Please vote on this issue by adding a reaction to the original issue to help the community and maintainers prioritize this request • If you are interested in working on this issue or have submitted a pull request, please leave a comment
Terraform, Provider, Kubernetes and Helm Versions
Terraform version: 1.4.6
Provider version: v2.10.0
Kubernetes version: 1.23.17 (EKS)
Affected Resource(s)
• Helm Repository: https://dysnix.github.io/charts • Helm Chart Version: 0.3.1 • Helm Chart: raw
Terraform Configuration Files
resource “helm_release” “filebeat” { chart = “raw” name = var.filebeat.name namespace = var.filebeat.namespace repository = “https://dysnix.github.io/charts” version = “0.3.1”
values = [ «-EOF ${yamlencode({ resources = [local.filebeat] })} EOF ] }
Debug Output
NOTE: In addition to Terraform debugging, please set HELM_DEBUG=1 to enable debugging info from helm.
Panic Output
N/A
Steps to Reproduce
- Use the above define Helm chart to deploy something. You can really deploy any type of Kubernetes resource.
- Rerun
terraform plan - Observe that the metadata is going to be regenerated when it shouldn’t.
Downgrading from 2.10.0 to 2.9.0 causes the issue to go away.
Expected Behavior
I would expect that rerunning Terraform where there are no changes to the Helm values that the metadata should not be recomputed.
Actual Behavior
Observe that the metadata gets regeneratred
Terraform used the selected providers to generate the following execution
plan. Resource actions are indicated with the following symbols:
~ update in-place
Terraform will perform the following actions:
# module.kubernetes_filebeat_autodiscovery_cluster_1.helm_release.filebeat will be updated in-place
~ resource "helm_release" "filebeat" {
id = "autodiscover"
~ metadata = [
- {
- app_version = ""
- chart = "raw"
- name = "autodiscover"
- namespace = "elastic-monitors"
- revision = 3
- values = jsonencode(
{
- resources = [
- {
- apiVersion = "beat.k8s.elastic.co/v1beta1"
- kind = "Beat"
- metadata = {
- labels = null
- name = "autodiscover"
- namespace = "default"
}
... <spec_removed>
},
]
}
)
- version = "v0.3.1"
},
] -> (known after apply)
name = "autodiscover"
# (27 unchanged attributes hidden)
}
Plan: 0 to add, 1 to change, 0 to destroy.
Important Factoids
References
• GH-1097
Community Note
• Please vote on this issue by adding a reaction to the original issue to help the community and maintainers prioritize this request • If you are interested in working on this issue or have submitted a pull request, please leave a comment
There are several issues with this problem ^
I’ve tried with both versions and it’s still happening. I’m still investigating how to fix this.
Is it also happening to you?
@Igor Rodionov
@Julio Chana can you show me logs of your terraform plan?
Guys, would you be able to help me with issues I’m facing? I’m trying to deploy AWS EKS cluster with the LB, but I’m getting this error.
@Igor Rodionov @Jeremy G (Cloud Posse)
@Stan V you didn’t describe the error, so I don’t know where to start, but I would guess this question is more appropriate for the #kubernetes channel.
@Jeremy G (Cloud Posse) https://sweetops.slack.com/files/U06G3MZCBQF/F07PSJF4NF7/image.png
{kind=link}
locals {
cluster_name = var.cluster_name
}
module "eks" {
source = "terraform-aws-modules/eks/aws"
version = "20.15.0"
cluster_name = local.cluster_name
cluster_version = "1.29"
cluster_endpoint_public_access = true
enable_cluster_creator_admin_permissions = true
cluster_addons = {
aws-ebs-csi-driver = {
service_account_role_arn = module.irsa-ebs-csi.iam_role_arn
}
}
vpc_id = module.vpc.vpc_id
subnet_ids = module.vpc.private_subnets
eks_managed_node_group_defaults = {
ami_type = var.ami_type
}
eks_managed_node_groups = {
one = {
name = "node-group-1"
instance_types = ["t3.medium"]
min_size = var.min_size
max_size = var.max_size
desired_size = var.desired_size
}
two = {
name = "node-group-2"
instance_types = ["t3.medium"]
min_size = var.min_size
max_size = var.max_size
desired_size = var.desired_size
}
}
}
module "lb_role" {
source = "terraform-aws-modules/iam/aws//modules/iam-role-for-service-accounts-eks"
role_name = "shop_eks_lb"
attach_load_balancer_controller_policy = true
oidc_providers = {
main = {
provider_arn = module.eks.oidc_provider_arn
namespace_service_accounts = ["kube-system:aws-load-balancer-controller"]
}
}
depends_on = [
module.eks
]
}
resource "kubernetes_service_account" "service-account" {
metadata {
name = "aws-load-balancer-controller"
namespace = "kube-system"
labels = {
"app.kubernetes.io/name" = "aws-load-balancer-controller"
"app.kubernetes.io/component" = "controller"
}
annotations = {
"eks.amazonaws.com/role-arn" = module.lb_role.iam_role_arn
"eks.amazonaws.com/sts-regional-endpoints" = "true"
}
}
depends_on = [
module.lb_role
]
}
resource "helm_release" "alb-controller" {
name = "aws-load-balancer-controller"
repository = "<https://aws.github.io/eks-charts>"
chart = "aws-load-balancer-controller"
namespace = "kube-system"
set {
name = "region"
value = "eu-west-3"
}
set {
name = "vpcId"
value = module.vpc.vpc_id
}
set {
name = "serviceAccount.create"
value = "false"
}
set {
name = "serviceAccount.name"
value = "aws-load-balancer-controller"
}
set {
name = "clusterName"
value = local.cluster_name
}
depends_on = [
kubernetes_service_account.service-account
]
}
Ah, well, the issue here is that you cannot deploy resources to an EKS cluster in the same Terraform plan as where you create the cluster. I mean, you can hack something that usually works, but it is not officially supported.
Best practice is to have one root module that creates the EKS cluster, and then additional modules that install things into the cluster.
@Stan V FYI
locals {
cluster_name = var.cluster_name
}
module "eks" {
source = "terraform-aws-modules/eks/aws"
version = "20.15.0"
cluster_name = local.cluster_name
cluster_version = "1.29"
cluster_endpoint_public_access = true
enable_cluster_creator_admin_permissions = true
cluster_addons = {
aws-ebs-csi-driver = {
service_account_role_arn = module.irsa-ebs-csi.iam_role_arn
}
}
vpc_id = module.vpc.vpc_id
subnet_ids = module.vpc.private_subnets
eks_managed_node_group_defaults = {
ami_type = var.ami_type
}
eks_managed_node_groups = {
one = {
name = "node-group-1"
instance_types = ["t3.medium"]
min_size = var.min_size
max_size = var.max_size
desired_size = var.desired_size
}
two = {
name = "node-group-2"
instance_types = ["t3.medium"]
min_size = var.min_size
max_size = var.max_size
desired_size = var.desired_size
}
}
}
module "lb_role" {
source = "terraform-aws-modules/iam/aws//modules/iam-role-for-service-accounts-eks"
role_name = "shop_eks_lb"
attach_load_balancer_controller_policy = true
oidc_providers = {
main = {
provider_arn = module.eks.oidc_provider_arn
namespace_service_accounts = ["kube-system:aws-load-balancer-controller"]
}
}
depends_on = [
module.eks
]
}
resource "kubernetes_service_account" "service-account" {
metadata {
name = "aws-load-balancer-controller"
namespace = "kube-system"
labels = {
"app.kubernetes.io/name" = "aws-load-balancer-controller"
"app.kubernetes.io/component" = "controller"
}
annotations = {
"eks.amazonaws.com/role-arn" = module.lb_role.iam_role_arn
"eks.amazonaws.com/sts-regional-endpoints" = "true"
}
}
depends_on = [
module.lb_role
]
}
resource "helm_release" "alb-controller" {
name = "aws-load-balancer-controller"
repository = "<https://aws.github.io/eks-charts>"
chart = "aws-load-balancer-controller"
namespace = "kube-system"
set {
name = "region"
value = "eu-west-3"
}
set {
name = "vpcId"
value = module.vpc.vpc_id
}
set {
name = "serviceAccount.create"
value = "false"
}
set {
name = "serviceAccount.name"
value = "aws-load-balancer-controller"
}
set {
name = "clusterName"
value = local.cluster_name
}
depends_on = [
kubernetes_service_account.service-account
]
}
2024-10-02
v1.9.7 1.9.7 (October 2, 2024) BUG FIXES:
config generation: escape map keys with whitespaces (#35754)
This PR updates the config generation package so map keys with whitespace are escaped with quotes. This is already handled automatically for the normal attribute generation, and nested blocks are a…
2024-10-03
Hi. I’m using ATMOS for a multi-account multi-enviroment project on AWS… And I love it! Now I need to deploy multiple times (mostly in the same environment) the same group of terraform components (about 20 components) by changing only the name (I’m using the tenant context to achieve this). The idea is to have for example, demo-a, demo-b, demo-c, etc…
So, I used GO templates and it works…
ecs/service/application{{ if .tenant }}/{{ .tenant }}{{ end }}:
...
ecs/service/api{{ if .tenant }}/{{ .tenant }}{{ end }}:
...
...
And then
atmos terraform apply ecs/service/application/demo-a -s uw2-dev
atmos terraform apply ecs/service/api/demo-a -s uw2-dev
...
But I have the feeling there must be a better way to do this… (and probably easier) Any idea? Thanks.
hi @Mauricio Wyler
I think this is a good way to do it, we also use Go templates in the component names when we need to dynamically generate many Atmos components If it’s works for you, then it’s fine
Thanks @Andriy Knysh (Cloud Posse) for your reply… Good to know I’m on the correct path!
@Andriy Knysh (Cloud Posse) do workflows support Go templates? Env vars? Or something to help me make them dynamic?
In:
name: Stack workflows
description: |
Deploy application stack
workflows:
apply-resources:
description: |
Run 'terraform apply' on core resources for a given stack
steps:
- command: terraform apply ecs/service/application/demo-a -auto-approve
- command: terraform apply ecs/service/api/demo-a -auto-approve
I would like pass demo-a as a parameter or env variable… to prevent me from creating repeated workflows for demo-b, demo-c, etc…
Thanks again!
Is anyone familiar with setting up flink workspaces on confluent?
I noticed there are some flink resources available through the confluent provider. I am not familiar enough to know if this is the best pattern to follow. For example, would it be better to run flink on kubernetes or on self hosted AWS resources? If anyone has some experience with this and can give some insight, I would appreciate it.
@Dan Miller (Cloud Posse) @Andriy Knysh (Cloud Posse) @Matt Calhoun
Did anyone see this ai atlantis song made by a community member? We need more ai songs about our tools lol
2024-10-04
Took a while to find the right combination of actions, but happy to share my guide on securing cloud-provisioning pipeline with GitHub Automation, which spans:
• “keyless” AWS authentication
• Terraform/Tofu IaC workflow
• deployment protections. (this is my first blog/article in years and super-keen for any feedback, from content to formatting and anything in between – thank you!)
Master best practices to secure cloud provisioning, automate pipelines, and deploy infrastructure-as-code in DevOps lifecycle.
Anyone know if the Pluralith project is still alive? They havent had a new release since March of 2023 so im guessing not. It also looks like they are not responding to any issues either. If it is dead does anyone know of a good alternative?
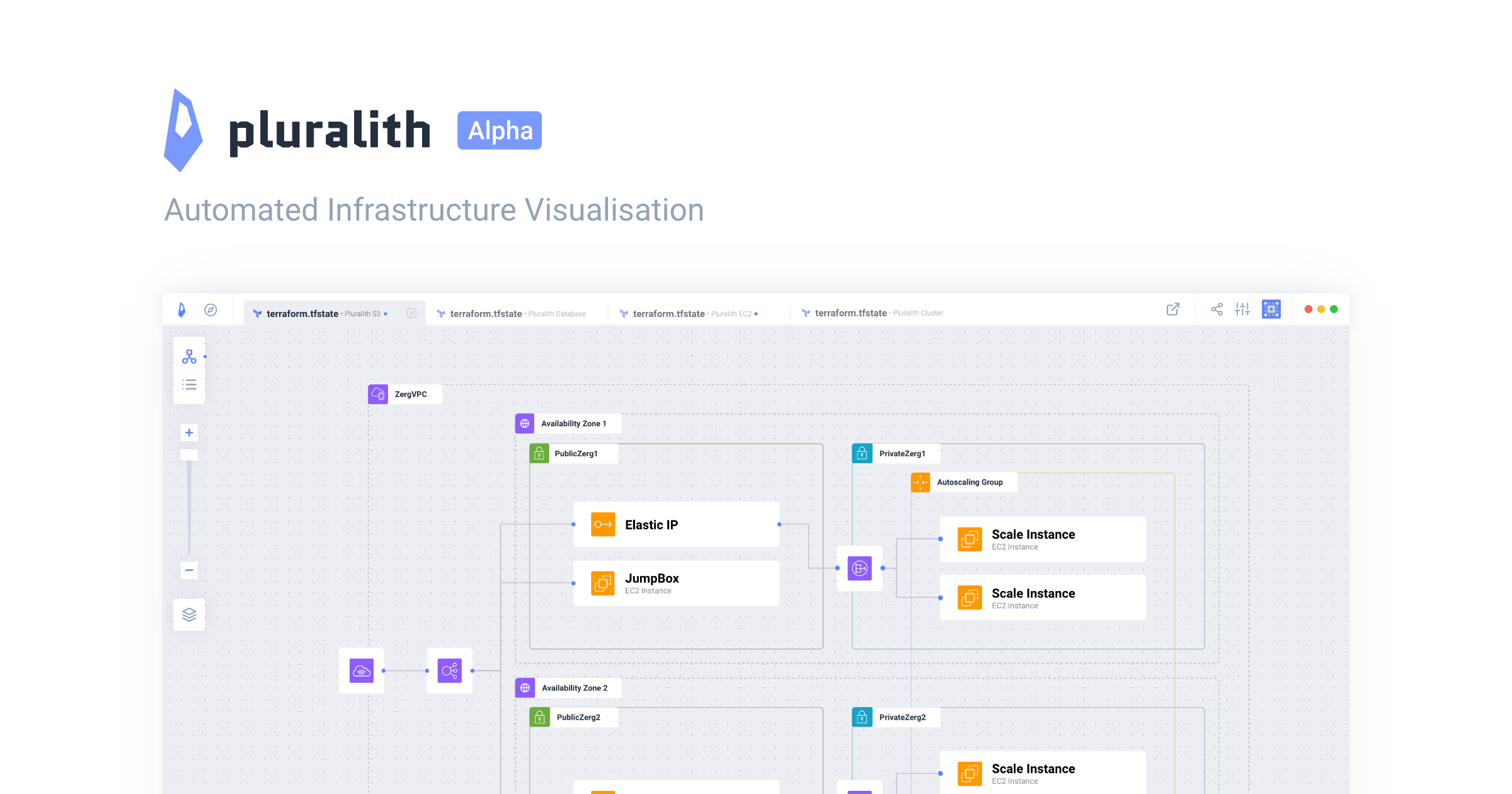
Pluralith lets you visualise and document your Terraform infrastructure in a completely automated way.
I can only recommend our solution: https://www.brainboard.co

Brainboard is an AI driven platform to visually design, generate terraform code and manage cloud infrastructure, collaboratively.
2024-10-07
Hey, I’m trying Atmos for the first time and I’m trying to set it up with opentofu. I have tofu available in my current path and I have a pretty straightforward (I guess) atmos.yaml file:
base_path: "./"
components:
terraform:
command: "tofu"
base_path: "components/terraform"
apply_auto_approve: false
deploy_run_init: true
init_run_reconfigure: true
auto_generate_backend_file: false
stacks:
base_path: "stacks"
included_paths:
- "deploy/**/*"
# excluded_paths:
# - "**/_defaults.yaml"
name_pattern: "{stage}/{region}"
logs:
file: "/dev/stderr"
level: Debug
However, when I try something like atmos terraform init -s dev/us-east-1 or atmos terraform init -s dev or atmos terraform init , I get:
exec: "terraform": executable file not found in $PATH
Any ideas? I’m not entirely sure about what I’m missing to make this work. Thank you!
please make sure you don’t have command: in the YAML manifests, similar to this
components:
terraform:
vpc:
command: "terraform"
Atmos natively supports OpenTofu, similar to the way it supports Terraform. It’s compatible with every version of opentofu and designed to work with multiple different versions of it concurrently, and can even work alongside with HashiCorp Terraform.
I don’t think I have any
could this be related with faulty definitions in other places?
please run atmos describe component <component> -s <stack> and check what value is in the command field in the output
oh wait
this is a wrong command
atmos terraform init -s dev/us-east-1
it needs a component and a stack
oh!
atmos terraform init <component> -s dev/us-east-1
silly mistake
2024-10-08
Hey, I’m trying to execute a plan and I’m getting the following output:
% atmos terraform plan keycloak_sg -s deploy/dev/us-east-1
Variables for the component 'keycloak_sg' in the stack 'deploy/dev/us-east-1':
aws_account_profile: [redacted]
cloud_provider: aws
environment: dev
region: us-east-1
team: [redacted]
tfstate_bucket: [redacted]
vpc_cidr_blocks:
- 172.80.0.0/16
- 172.81.0.0/16
vpc_id: [redacted]
Writing the variables to file:
components/terraform/sg/-keycloak_sg.terraform.tfvars.json
Using ENV vars:
TF_IN_AUTOMATION=true
Executing command:
/opt/homebrew/bin/tofu init -reconfigure
Initializing the backend...
Initializing modules...
Initializing provider plugins...
- Reusing previous version of hashicorp/aws from the dependency lock file
- Using previously-installed hashicorp/aws v5.70.0
OpenTofu has been successfully initialized!
Command info:
Terraform binary: tofu
Terraform command: plan
Arguments and flags: []
Component: keycloak_sg
Terraform component: sg
Stack: deploy/dev/us-east-1
Working dir: components/terraform/sg
Executing command:
/opt/homebrew/bin/tofu workspace select -keycloak_sg
Usage: tofu [global options] workspace select NAME
Select a different OpenTofu workspace.
Options:
-or-create=false Create the OpenTofu workspace if it doesn't exist.
-var 'foo=bar' Set a value for one of the input variables in the root
module of the configuration. Use this option more than
once to set more than one variable.
-var-file=filename Load variable values from the given file, in addition
to the default files terraform.tfvars and *.auto.tfvars.
Use this option more than once to include more than one
variables file.
Error parsing command-line flags: flag provided but not defined: -keycloak_sg
Executing command:
/opt/homebrew/bin/tofu workspace new -keycloak_sg
Usage: tofu [global options] workspace new [OPTIONS] NAME
Create a new OpenTofu workspace.
Options:
-lock=false Don't hold a state lock during the operation. This is
dangerous if others might concurrently run commands
against the same workspace.
-lock-timeout=0s Duration to retry a state lock.
-state=path Copy an existing state file into the new workspace.
-var 'foo=bar' Set a value for one of the input variables in the root
module of the configuration. Use this option more than
once to set more than one variable.
-var-file=filename Load variable values from the given file, in addition
to the default files terraform.tfvars and *.auto.tfvars.
Use this option more than once to include more than one
variables file.
Error parsing command-line flags: flag provided but not defined: -keycloak_sg
exit status 1
goroutine 1 [running]:
runtime/debug.Stack()
runtime/debug/stack.go:26 +0x64
runtime/debug.PrintStack()
runtime/debug/stack.go:18 +0x1c
github.com/cloudposse/atmos/pkg/utils.LogError({0x105c70460, 0x14000b306e0})
github.com/cloudposse/atmos/pkg/utils/log_utils.go:61 +0x18c
github.com/cloudposse/atmos/pkg/utils.LogErrorAndExit({0x105c70460, 0x14000b306e0})
github.com/cloudposse/atmos/pkg/utils/log_utils.go:35 +0x30
github.com/cloudposse/atmos/cmd.init.func17(0x10750ef60, {0x14000853480, 0x4, 0x4})
github.com/cloudposse/atmos/cmd/terraform.go:33 +0x150
github.com/spf13/cobra.(*Command).execute(0x10750ef60, {0x14000853480, 0x4, 0x4})
github.com/spf13/[email protected]/command.go:989 +0x81c
github.com/spf13/cobra.(*Command).ExecuteC(0x10750ec80)
github.com/spf13/[email protected]/command.go:1117 +0x344
github.com/spf13/cobra.(*Command).Execute(...)
github.com/spf13/[email protected]/command.go:1041
github.com/cloudposse/atmos/cmd.Execute()
github.com/cloudposse/atmos/cmd/root.go:88 +0x214
main.main()
github.com/cloudposse/atmos/main.go:9 +0x1c
I’m not really sure what I can do since the error message suggests an underlying tofu/terraform error and not an atmos one. I bet my stack/component has something wrong but I’m not entirely sure why. The atmos.yaml is the same of the previous message I sent here yesterday. I’d appreciate any pointers
(Please use atmos)
sure!
2024-10-09
v1.10.0-alpha20241009 1.10.0-alpha20241009 (October 9, 2024) NEW FEATURES:
Ephemeral resources: Ephemeral resources are read anew during each phase of Terraform evaluation, and cannot be persisted to state storage. Ephemeral resources always produce ephemeral values. Ephemeral values: Input variables and outputs can now be defined as ephemeral. Ephemeral values may only be used in certain contexts in Terraform configuration, and are not persisted to the plan or state files.
terraform output -json now displays…
2024-10-11
I was trying to use https://registry.terraform.io/modules/cloudposse/stack-config/yaml/1.6.0/submodules/remote-state and found out that actually it’s a submodule of yaml-stack-config module.
Since every submodule of yaml-stack-config is using context (null-label) that got me thinking:
if terraform-provider-context is meant to supersede null-label , should I even start using yaml-stack-config when starting my codebase pretty much from scratch?
@Matt Calhoun
The tl;dr is that yes, the terraform-provider-context is designed to replace null-label but the Cloud Posse modules and components have not yet been updated to support its use, so it’s probably premature to start using it if you are also using Cloud Posse open source terraform modules. We are currently in the planning phase of how those upgrades will occur, but it will be some time before they are rolled out to our open source modules.
A terraform console wrapper for a better REPL experience
This is easier to use than creating a new directory of files with test code
A terraform console wrapper for a better REPL experience
And probably eliminates the need for troubleshooting with outputs, I’ll have to try it out
Ola  I am struggling with loop ( over subnets ) and this structure
I am struggling with loop ( over subnets ) and this structure
variable "vpcs" {
description = "List of VPCs"
type = list(map(any))
default = [
{
name = "vpc-1"
cidr = "10.0.0.0/16"
subnets = [
{
name = "subnet-1"
cidr = "10.0.1.0/24"
},
{
name = "subnet-2"
cidr = "10.0.2.0/24"
}
]
},
{
name = "vpc-2"
cidr = "10.0.0.0/16"
subnets = [
{
name = "subnet-3"
cidr = "10.0.3.0/24"
},
{
name = "subnet-4"
cidr = "10.0.4.0/24"
}
]
}
]
}
any ideas? something like
for_each = { for v in var.vpcs, s in v.subnets : "${v.name}-${s.name}" => s }
@Dan Miller (Cloud Posse)
this structure is a little confusing, list(map(any)). How about changing the variable to a list(object({...})) ?
variable "vpcs" {
description = "List of VPCs"
type = list(object({
name = string
cidr = string
subnets = list(object({
name = string
cidr = string
}))
}))
default = [
{
name = "vpc-1"
cidr = "10.0.0.0/16"
subnets = [
{
name = "subnet-1"
cidr = "10.0.1.0/24"
},
{
name = "subnet-2"
cidr = "10.0.2.0/24"
}
]
},
{
name = "vpc-2"
cidr = "10.0.0.0/16"
subnets = [
{
name = "subnet-3"
cidr = "10.0.3.0/24"
},
{
name = "subnet-4"
cidr = "10.0.4.0/24"
}
]
}
]
}
then you can loop over it like this
for_each = {
for vpc in var.vpcs :
for subnet in vpc.subnets : "${vpc.name}-${subnet.name}" => subnet
}
^ agree
2024-10-14
2024-10-15
Would love to get some feedback on my latest project – Terraform Module Releaser – a GitHub Action that automates versioning, tags, releases, and docs for Terraform modules in monorepos! Great for module collections in a single repo with tags representing logical folders/tf roots. Spent a lot of time to make this literally a drop-in for anyone using GHA with defaults sanely configured.
Check it out here: [https://github.com/techpivot/terraform-module-releaser] Feel free to star if you find it useful! Happy to answer any Qs in as well!
GitHub Action to automate versioning, releases, and documentation for Terraform modules in monorepos.
2024-10-16
Hello, team! This is about Rotate .pem for AWS EKS nodes, and the.pub and .private keys are generated using the source URL listed below.
https://github.com/cloudposse/terraform-aws-key-pair/blob/main/main.tf Whenever we update the key pair name in the keypair.tf, the key pair name changes, but the .private and.pub keys remain the same as earlier.
Need change the .pub and .private keys for the EKS nodes.
locals {
enabled = module.this.enabled
public_key_filename = format(
"%s/%s",
var.ssh_public_key_path,
coalesce(var.ssh_public_key_file, join("", [module.this.id, var.public_key_extension]))
)
private_key_filename = format(
"%s/%s%s",
var.ssh_public_key_path,
module.this.id,
var.private_key_extension
)
}
resource "aws_key_pair" "imported" {
count = local.enabled && var.generate_ssh_key == false ? 1 : 0
key_name = module.this.id
public_key = file(local.public_key_filename)
tags = module.this.tags
}
resource "tls_private_key" "default" {
count = local.enabled && var.generate_ssh_key == true ? 1 : 0
algorithm = var.ssh_key_algorithm
}
resource "aws_key_pair" "generated" {
count = local.enabled && var.generate_ssh_key == true ? 1 : 0
depends_on = [tls_private_key.default]
key_name = module.this.id
public_key = tls_private_key.default[0].public_key_openssh
tags = module.this.tags
}
resource "local_file" "public_key_openssh" {
count = local.enabled && var.generate_ssh_key == true ? 1 : 0
depends_on = [tls_private_key.default]
content = tls_private_key.default[0].public_key_openssh
filename = local.public_key_filename
}
resource "local_sensitive_file" "private_key_pem" {
count = local.enabled && var.generate_ssh_key == true ? 1 : 0
depends_on = [tls_private_key.default]
content = tls_private_key.default[0].private_key_pem
filename = local.private_key_filename
file_permission = "0600"
}
resource "aws_ssm_parameter" "private_key" {
count = local.enabled && var.generate_ssh_key && var.ssm_parameter_enabled == true ? 1 : 0
name = format("%s%s", var.ssm_parameter_path_prefix, module.this.id)
type = "SecureString"
value = tls_private_key.default[0].private_key_pem
tags = module.this.tags
}
@Yonatan Koren @Andriy Knysh (Cloud Posse)
locals {
enabled = module.this.enabled
public_key_filename = format(
"%s/%s",
var.ssh_public_key_path,
coalesce(var.ssh_public_key_file, join("", [module.this.id, var.public_key_extension]))
)
private_key_filename = format(
"%s/%s%s",
var.ssh_public_key_path,
module.this.id,
var.private_key_extension
)
}
resource "aws_key_pair" "imported" {
count = local.enabled && var.generate_ssh_key == false ? 1 : 0
key_name = module.this.id
public_key = file(local.public_key_filename)
tags = module.this.tags
}
resource "tls_private_key" "default" {
count = local.enabled && var.generate_ssh_key == true ? 1 : 0
algorithm = var.ssh_key_algorithm
}
resource "aws_key_pair" "generated" {
count = local.enabled && var.generate_ssh_key == true ? 1 : 0
depends_on = [tls_private_key.default]
key_name = module.this.id
public_key = tls_private_key.default[0].public_key_openssh
tags = module.this.tags
}
resource "local_file" "public_key_openssh" {
count = local.enabled && var.generate_ssh_key == true ? 1 : 0
depends_on = [tls_private_key.default]
content = tls_private_key.default[0].public_key_openssh
filename = local.public_key_filename
}
resource "local_sensitive_file" "private_key_pem" {
count = local.enabled && var.generate_ssh_key == true ? 1 : 0
depends_on = [tls_private_key.default]
content = tls_private_key.default[0].private_key_pem
filename = local.private_key_filename
file_permission = "0600"
}
resource "aws_ssm_parameter" "private_key" {
count = local.enabled && var.generate_ssh_key && var.ssm_parameter_enabled == true ? 1 : 0
name = format("%s%s", var.ssm_parameter_path_prefix, module.this.id)
type = "SecureString"
value = tls_private_key.default[0].private_key_pem
tags = module.this.tags
}
Can you please update on the request?
Hi @Prashant Thank you for reaching out! As a small team, we prioritize our paying clients, which means community support might take a bit longer. I’ll be sure to share your request with our engineers, but please bear with us as we work through our current projects. While we can’t provide a specific ETA, we’ll do our best to get back to you as soon as we can. Thank you for your understanding!
@Prashant when you create an EKS cluster, you can specify a KMS key to encrypt the volumes, for example
https://github.com/cloudposse/terraform-aws-eks-cluster/blob/main/main.tf#L85
if you change the KMS key, it invoves a lot of steps (some of them are manual) to correctly update the cluster to use the new key
New Key Only Affects New Volumes:
Updating the encryption key will not retroactively change the encryption on existing EBS volumes.
Old volumes will still use the original KMS key unless you migrate them.
Backup and Migration:
If you need to re-encrypt existing volumes with the new key, you'll have to create new encrypted volumes using the new key and migrate data.
Impact on Pods/Workloads:
If you're using persistent volumes (PVs), updating encryption keys involves moving data, which may lead to downtime unless handled properly (e.g., by draining nodes).
IAM Role Changes:
Ensure that the EKS node IAM roles and other services have appropriate permissions for both the old and new KMS keys during the migration.
these steps need to be done
they are not supported by the https://github.com/cloudposse/terraform-aws-eks-cluster TF module
<https://github.com/cloudposse/terraform-aws-key-pair/blob/main/main.tf>
Whenever we update the key pair name in the keypair.tf, the key pair name changes, but the .private and.pub keys remain the same as earlier.
can you provide more info on the above? (e.g. there is no [keypair.tf](http://keypair.tf) file in the module)
Thank @Andriy Knysh (Cloud Posse) @Gabriela Campana (Cloud Posse) for reaching out to me.
@Andriy Knysh (Cloud Posse) To add context to this. The SSH keys (.Pub and.Privte) are saved in the Secrets Manager with the name of the keypair, which is indicated in keypair.tf, as well as key stories in the key pairs service in the AWS console. When EC2 instances are created, the keypair is assigned to them automatically.
When we edit the key pair name (aws) (-${var.env}-${var.app}-${random_id.uniquekeypair.hex}-keypair) in the keypair.tf, the name changes, but the private and pub keys remain the same as before.
We need something different. The pub and private keys are then the same as those stored in the Secrets Manager.
resource "random_id" "uniquekeypair" {
byte_length = 4
}
module "ssh_key_pair" {
source = "git::<https://github.com/cloudposse/terraform-aws-key-pair.git?ref=main>"
name = "aws-${var.env}-${var.app}-${random_id.uniquekeypair.hex}-keypair"
ssh_public_key_path = "./secrets"
generate_ssh_key = "true"
private_key_extension = ".pem"
public_key_extension = ".pub"
tags = local.core_tags
The aws-key-pair module is deprecated because of the various ways it leaks the keys. You have run into one of several issues with this module. The easiest path forward is just to
terraform taint "...tls_private_key.default[0]"
where the ... must be replaced by whatever prefix you see when you run terraform state list.
v1.9.8 1.9.8 (October 16, 2024) BUG FIXES:
init: Highlight missing subdirectories of registry modules in error message (#35848) init: Prevent crash when loading provider_meta blocks with invalid names (<a href=”https://github.com/hashicorp/terraform/pull/35842” data-hovercard-type=”pull_request”…
Backport This PR is auto-generated from #35839 to be assessed for backporting due to the inclusion of the label 1.9-backport.
Warning automatic cherry-pick of commits failed. If the first commit…
This PR updates the parsing of the provider_meta blocks so that providers with invalid names aren't returned. This prevents a crash that occurs later when the names are parsed, and doesn't …
Say you have Terraform running as part of your provisioning workflow, and the plan output is returned as a PR comment.
For a large enough project, you’re likely to run into GitHub’s character limit for comments. In that situation, would you prefer:
• the first thousands of characters
• the last thousands of characters Before rushing to the second option because the plan summary is stored within the last few lines, consider that plan summary is pulled out at the top of the PR comment already.
So which “end” is more useful to you? And would the same “end” be useful from the apply command’s output as well?
That’s plan B
Plan A, is don’t use GitHub comments. It’s use github job summaries instead
Job summaries can be much larger, I believe as large as 1MB of markdown text
When it’s larger than that, I would just attach the logs as an artifact, and shame them for having root module that is too large.
Boy am I glad you mentioned that, because outputting the TF command output to the workflow job summary is the default behaviour. The PR comment is for ease of reference within the conversation thread.
For context, I’m pulling together a reusable workflow for plan/applying Terraform+Tofu, so I have no say/judgement over how it gets used by the broader audience. I just want the dev-experience to be smooth, even in edge-cases where the plan output may be longer than character limits, and needs to be truncated.
For added support, both the PR comment and job summary includes a direct link to the view the workflow log in its entirety. Additionally, the last 1-line summary of the plan is pulled out to the very top, as that’s probably the most relevant piece of info you’re after.
You could also add a summary of your terraform plan changes with something like tf-summarize. (Particularly like this) & save your larger plan run as an artifact and point to it via a comment.
Thanks @akhan4u, that summarize is undeniably cool , and I’ve seen it taken even further with the likes of prettyplan, though it’s outside the formatting scope of a mere PR comment.
A rather simpler approach to outlining the plan I’d been considering was to extract the lines starting with # and applying some basic regex to generate diff like so.
The other option is to just to post an “anchor” comment in the PR, with the TL;DR, a link to the full job summary, and a link to the job.
 1
1This is what vercel does
I kind of like that. Not overwhelming in the PR. It’s convenient to quickly naviate.
In the same vein, when pushing multiple commits to a PR branch, would you prefer the Terraform plan output to:
• update the existing comment (bonus revision/edit history)
• delete the existing comment and create a new one (easier to scan chronologically).
So close to
2024-10-17
2024-10-18
I’m running into an issue when adding routes for peering connections. I get the existing routes that exist for all subnets in a VPC and then try to use count to go through them and add a route. But it won’t let me use a data element to get routes unless I comment out the aws_route that I’m trying to create then, after it gets the data I can uncomment to run it. This is the error
The "count" value depends on resource attributes that cannot be determined until apply, so Terraform cannot predict how many instances will be created. To work around this, use the
│ -target argument to first apply only the resources that the count depends on.
I tried assigning the data request to a local var, but still got the error
2024-10-19
2024-10-23
v1.10.0-alpha20241023 1.10.0-alpha20241023 (October 23, 2024) NEW FEATURES:
Ephemeral resources: Ephemeral resources are read anew during each phase of Terraform evaluation, and cannot be persisted to state storage. Ephemeral resources always produce ephemeral values. Ephemeral values: Input variables and outputs can now be defined as ephemeral. Ephemeral values may only be used in certain contexts in Terraform configuration, and are not persisted to the plan or state files.
terraform output -json now displays…
1.10.0-alpha20241023 (October 23, 2024) NEW FEATURES:
Ephemeral resources: Ephemeral resources are read anew during each phase of Terraform evaluation, and cannot be persisted to state storage. Ep…
Hello, I previously submitted a pull request for Cloud Posse Terraform Datadog Platform, https://github.com/cloudposse/terraform-datadog-platform/pull/107. May I get some eyes on it or be directed to where I may find an approval? It’s a simple one-line-change that fixes Advanced Scheduling for Synthetics Tests.
what
Change loop to use child objects instead of timeframes object.
why
Currently, the Synthetics Test module is only capable of setting an advanced schedule for one day. It is unable to accept or set multiple days. This change allows for multiple days to be set in an advanced schedule.
references
Closes #100
Thread moved to #pr-reviews https://sweetops.slack.com/archives/CUJPCP1K6/p1729818458931139?thread_ts=1729703106.614279&cid=CUJPCP1K6
@Bob Berg Thank you for this PR.
At the moment, the automated tests are failing. The test failures do not appear to be related to this PR, but still, we do not like to accept/merge PRs when the tests are failing. I am looking into it; no further action is required on your part at this time. However, because the failure involves Datadog rejecting what was previously a valid test, it will take quite a while to figure out.
2024-10-24
This message was deleted.
2024-10-25
Hi folks, fairly new to terraform and have a few questions on how to approach a problem.
I wish to create a web portal where it is possible to provision an entire project with different environments (dev, prod, e.t.c). Idea is to create a singular internal module which would include all of my needed public modules for example EC2, RDS, S3 and others. For DEV and PROD environments I want default variables to already contain all the logic what these environments need and if needed the module caller can edit those values. Result could be for example module caller could deploy and entire dev environment without providing any variables.
Question is it a fine approach to create this singular module this way? Any suggestions would help! Thanks you!
I did a quick read through, and it sounds like you are describing something like Atmos or Terragrunt.
Terraform Orchestration Tool for DevOps. Keep environment configuration DRY with hierarchical imports of configurations, inheritance, and WAY more. Native support for Terraform and Helmfile.
@Roberts Jānis Sīklis you can join the atmos channel
and review the quick start https://atmos.tools/quick-start/mindset
Atmos can change how you think about the Terraform code you write to build your infrastructure.
you are at Stage #1 of the Terraform Journey.
Learn about the typical Terraform journey when not using Atmos.
Thanks! Will take a look!
2024-10-29
hello guys
I am playing Atmos and GitHub for my project
currently, I am having a problem with posting comments to GitHub pull requests with atmos terraform plan <stack> -s #####
I cant parse output in a readable this relative to terraform -no-color
my question is:
can I run atmos terraform plan
2024-10-30
I am having a problem with the elasticache-redis module, when I turn on the variable
allow_ingress_from_this_vpc
I get the following error
│ Error: Inconsistent conditional result types
│
│ on .terraform/modules/redis_clusters.redis.aws_security_group/normalize.tf line 81, in locals:
│ 81: all_ingress_rules = local.inline ? [for r in local.all_inline_rules : r if r.type == "ingress"] : []
│ ├────────────────
│ │ local.all_inline_rules is tuple with 3 elements
│ │ local.inline is false
│
│ The true and false result expressions must have consistent types. The 'true' tuple has length 2, but the 'false' tuple has length 0.
╵
exit status 1
I chased it to through the following files
starts here https://github.com/cloudposse/terraform-aws-components/blob/main/modules/elasticache-redis/main.tf#L41-L43
Goes to this module https://github.com/cloudposse/terraform-aws-components/blob/main/modules/elasticache-redis/modules/redis_cluster/main.tf#L12
Goes to this module https://github.com/cloudposse/terraform-aws-elasticache-redis/blob/main/main.tf#L36
to here https://github.com/cloudposse/terraform-aws-security-group/blob/main/normalize.tf#L81
but it seems the default value for a variable called inline_rules_enableddefaults to false
https://github.com/cloudposse/terraform-aws-elasticache-redis/blob/1.4.1/security_group_inputs.tf#L158
And it never gets set by the component, or the upstream modules to true. So the if statement on L81 will always be false, and the contents appear to mixmatch
2024-10-31
v1.10.0-beta1 1.10.0-beta1 (October 31, 2024) NEW FEATURES:
Ephemeral resources: Ephemeral resources are read anew during each phase of Terraform evaluation, and cannot be persisted to state storage. Ephemeral resources always produce ephemeral values. Ephemeral values: Input variables and outputs can now be defined as ephemeral. Ephemeral values may only be used in certain contexts in Terraform configuration, and are not persisted to the plan or state files.
terraform output -json now displays ephemeral…
1.10.0-beta1 (October 31, 2024) NEW FEATURES:
Ephemeral resources: Ephemeral resources are read anew during each phase of Terraform evaluation, and cannot be persisted to state storage. Ephemeral …