#aws (2023-02)
 Discussion related to Amazon Web Services (AWS)
Discussion related to Amazon Web Services (AWS)
Discussion related to Amazon Web Services (AWS)
Archive: https://archive.sweetops.com/aws/
2023-02-01
I’m using v2 of the aws golang sdk and as someone still relatively new to golang, I’m still trying to wrap my head around real-world uses of context. I’ve not been able to find any example code that does anything with the context object that is required for everything now. Anyone have sample code or use cases they could share with me?
Help writing pytest to test a method in CDK: Hello everyone, I am working with this lab (https://cdkworkshop.com/). Because of coverage, I need to write a test for the method table_name.
class HitCounter(Construct):
@property
def handler(self):
return self._myhandler
@property
def table(self):
return self._table
@property
def table_name(self):
return self._table.table_name
def __init__(
self,
scope: Construct,
id: str,
downstream: _lambda.IFunction,
**kwargs
) -> None:
# expose our table to be consumed in workshop01_stack.py
self._table = ddb.Table(
self,
"Hits",
partition_key={"name": "path", "type": ddb.AttributeType.STRING},
encryption=ddb.TableEncryption.AWS_MANAGED, # test_dynamodb_with_encryption()
read_capacity=read_capacity,
removal_policy=RemovalPolicy.DESTROY,
)
I tried something like this but it is failing, any example or help please?
def test_dynamodb_tablename():
stack = Stack()
myhit = HitCounter(
stack,
"HitCounter",
downstream=_lambda.Function(
stack,
"TestFunction",
runtime=_lambda.Runtime.PYTHON_3_9,
handler="hello.handler",
code=_lambda.Code.from_asset("lambda_cdk"),
),
)
assert myhit.table_name == "mytable"
Error(it returns TOKEN and does not compare):
> assert myhit.table_name == "mytable"
E AssertionError: assert '${Token[TOKEN.825]}' == 'mytable'
E - mytable
E + ${Token[TOKEN.825]}
tests/unit/test_cdk_workshop.py:120: AssertionError
I’m using ECS for orchestration of services by using ec2 as capacity provider. My images in different aws account. I’m not able to fetch the docker image. Please help me in figuring out a solution.
#!/bin/bash
sudo yum install -y aws-cli
aws ecr get-login-password --region ap-south-1 | docker login --username AWS --password-stdin ACCOUNTID.dkr.ecr.ap-south-1.amazonaws.com
cat <<'EOF' >> /etc/ecs/ecs.config
ECS_CLUSTER=qa
ECS_ENABLE_SPOT_INSTANCE_DRAINING=true
EOF
sudo stop ecs && sudo start ecs
NOTE: while using fargate i’m able to pull the image
2023-02-02
hello all, I see this in our RDS:
oscar_oom.cc
Anyone has fix for this ? v1 serverless.
Hi all, we’re facing nginx 504 error frequently, after changing proxy_connection_timeout 600; it’s doesn’t work, please advice
Thanks for reaching out about the Nginx 504 error you’re experiencing. A 504 error typically indicates that the server didn’t receive a timely response from the upstream server, which in this case would be the proxy server.
In order to troubleshoot the issue, here are a few steps you can take:
Check the logs of the upstream server to see if there are any errors or issues that may be causing the delay in responses.
Monitor the network traffic between the Nginx server and the upstream server to see if there are any connectivity issues or bottlenecks.
Increase the buffer sizes in your Nginx configuration to allow for larger payloads to be sent between the server and the proxy.
If you’re using load balancing, consider using a different load balancing method, such as round-robin, to distribute the requests more evenly.
Try increasing the proxy_connection_timeout value to a higher number to see if that resolves the issue.
I hope these suggestions help resolve the issue, but if you’re still having trouble, don’t hesitate to reach out for further assistance.
Sorry for the delay lee, we had nginx 504 error, since we trying to pull huge amount of data
I remember that there were some window desktop tools to upload files to S3 - I’m looking for a solution to give a non technical user. My idea would be to grant them a read-write key on a specific bucket (and or folder) and this tools so they can do it. What options are there?
We’ve got mac users on https://cyberduck.io/ and it works well for them. They do have a windows version as well, but I’ve never used it personally.
FileZilla was another option
Cool, didn’t know filezilla could do that now.
oh I guess it’s only Pro, sorry
Commander One on Mac works ok for me
Are you looking for a secure and fast Amazon S3 client for Mac? Try Commander One and connect to multiple S3 accounts right from the file manager.
There is also a VM image for enterprise that connects to S3 and allows you to expose that as a SMB network share.
Use Amazon S3 File Gateway to connect your on-premises environment with cloud-based storage.
for Window(s), there are a bunch of those tools, e.g. https://s3browser.com/
S3 Browser - Amazon S3 Client for Windows. User Interface for Amazon S3. S3 Explorer. Bucket Explorer.
S3 Browser is the one I use. Petty simple actually.
+1 for cyberduck. I set it up for a team that uses mac and windows. non-tech folks that needed up transfer files from local storage to s3. it worked great.
 1
1Cloudberry
2023-02-03
2023-02-08
huh, this is new to me, though i see it was released in nov 2022… cross-account visibility for cloudwatch logs? anyone use this yet? https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/CloudWatch-Unified-Cross-Account.html
Learn how to set up a monitoring account to view CloudWatch, CloudWatch Logs, and X-Ray data from multiple source accounts.

Deploying applications using multiple AWS accounts is a good practice to establish security and billing boundaries between teams and reduce the impact of operational events. When you adopt a multi-account strategy, you have to analyze telemetry data that is scattered across several accounts. To give you the flexibility to monitor all the components of your […]
Anyone using ssm parameter policies? In the cli help for ExpirationNotification and NoChangeNotification it states that a cloudwatch event will be created. Then at https://docs.aws.amazon.com/systems-manager/latest/userguide/parameter-store-policies.html it states that an EventBridge event will be created. So.. which is it? Or are they both somehow correct? I’ve never used EventBridge so I’m
Manage your parameters by assigning a Parameter Store Expiration, ExpirationNotification, or NoChangeNotification policy to a parameter.
Poking around in the console it appears that CloudWatch events are EventBridge events. Guess the cli docs are just out of date.
Manage your parameters by assigning a Parameter Store Expiration, ExpirationNotification, or NoChangeNotification policy to a parameter.
2023-02-09
Any advice on moving an s3 bucket from one region to another? I’ve used S3 Batch Replication before, but I’m wondering if there is cheaper (and therefore likely slower, but that might be fine).
set up replication https://docs.aws.amazon.com/AmazonS3/latest/userguide/replication.html and switch over at a certain time. the tricky bit is really how to switch over as thats the bit where you may end up with eventual consistency issues. if you can live with a bit of downtime, (minutes?) this can easily become a non-problem however. depends on your usecase.
Yeah but if you want to move a bucket, just setting up replication is not enough as that will only handle new objects created after replication has been setup. It will not replicate existing objects in the bucket.
That’s why AWS created S3 Batch Replication (ga August 2022, very recent), but it’s not clear whether there are cheaper (and likely slower) ways. Batch replic on a bucket having 200M objects will cost at least $200. Quite affordable, but is there cheaper
- create a new bucket
- aws s3 sync <s3://orig> <s3://tmp>
- delete old bucket
- create orig bucket in new region
- sync back
- delete tmp bucket
It’s the best…. Step 0 should be stop create/update/deletes to bucket.
if you have the time to wait for the sync and include downtime where there are no writes/reads, yes this is the easiest solution. its also the cheapest option usually
when you don’t want to be offline and/or its a huge amount of data and offline would be too long or you want to minimize it, replication is the way and its a combination of batch replication and replication itself. as you noted batch replication is for the old things and replication itself for anything, that changes. batch also fixes things if there are failed objects (that didnt replicate). in any case, both are described there on that page and they will cost more than an s3 sync
so really if you can live with that downtime of waiting for the s3 sync, that is the cheapest available option. Alex is right about that and I should have mentioned it too
Yes, there are a few different options for moving an S3 bucket from one region to another, and each has its pros and cons in terms of cost and speed. Here are a few methods you could consider:
S3 Batch Replication: This is the method you’ve already used, and it’s a good option if you need to replicate a large number of objects or have specific requirements around replication time and data consistency. However, it can be relatively expensive compared to other options.
S3 Transfer Acceleration: This feature allows you to transfer data to S3 over the Amazon CloudFront content delivery network, which can speed up transfers by up to several times compared to standard internet transfer speeds. While this option is faster than batch replication, it’s still not the cheapest option.
S3 Cross-Region Replication: This is another option that you can set up to automatically replicate objects from one bucket to another in a different region. Unlike batch replication, this feature is designed for continuous replication and provides immediate and eventual consistency for updates. It’s a more cost-effective option compared to batch replication, but the transfer speed may be slower.
S3 Transfer Manager: You can use the AWS S3 Transfer Manager to move objects between S3 buckets in different regions. This is a good option if you have a large number of smaller files, as it provides a higher level of parallelism and can be faster than batch replication or cross-region replication. However, it’s not as cost-effective as cross-region replication.
Ultimately, the best option for you will depend on your specific requirements, including transfer speed, cost, and the number and size of objects you need to move.
Thanks guys I appreciate all the input.
Note for others reading this: s3 cross-region replication will not copy existing objects, so cloning a non-empty bucket cannot be done with it alone.
To force replication in the past I wrote a script to update metadata in the source objects
2023-02-10
what was that SSM ssh client interactive utility that was mention here before?
was written in golang
and it will search for the instance in a specific region
this one
Easy connect on EC2 instances thanks to AWS System Manager Agent. Just use your ~/.aws/profile to easily select the instance you want to connect on.
mmmm not updated lately
You can use the ssm start-session so not sure why you’d need a 3rd party tool. https://awscli.amazonaws.com/v2/documentation/api/latest/reference/ssm/start-session.html#examples
The sshm utility is pretty handy. It still works for me even tho its old
this 3rd party tool searches for all the instance running and registered with ssm in your region and you can select them from a menu, it is very handy
2023-02-11
Do you use any tool to discover how much things are exactly costing? I’m trying to use the cost explorer and I can’t reliably get the data I want. Which is basically, give me all charges you are making detailed by item.
infracost
That looks good, but I have not created AWS Backups through Terraform. Can you or someone else recommend a local tool that uses aws cli or something similar to find costs?
look at the office-hours videos, there has been some mention of many tools before
If you want to use cost explorer CLI to get costs by service, you can use the ce module.
for example, i use the following to get monthly costs by service by team from four accounts:
for profile in acct1-{prod,nonprod} acct2-{prod,nonprod};
do
aws --profile=${profile} ce get-cost-and-usage \
--time-period Start=2023-01-01,End=2023-01-31 \
--granularity=MONTHLY \
--filter <file://filters.json> \
--group-by Type=DIMENSION,Key=SERVICE \
--metrics=UnblendedCost| tee UnblendedCost-${profile}.json
done
the file filters.json looks like this:
{
"Tags": {
"Key": "TEAM_ID",
"Values": ["abcdefghijklmnopqrstuvwxyz0123456789"]
}
}
Output looks like this:
{
"GroupDefinitions": [
{
"Type": "DIMENSION",
"Key": "SERVICE"
}
],
"ResultsByTime": [
{
"TimePeriod": {
"Start": "2023-01-01",
"End": "2023-01-31"
},
"Total": {},
"Groups": [
{
"Keys": [
"AWS Direct Connect"
],
"Metrics": {
"UnblendedCost": {
"Amount": "0.0024723419",
"Unit": "USD"
}
}
},
{
"Keys": [
"Amazon Elastic Load Balancing"
],
"Metrics": {
"UnblendedCost": {
"Amount": "11278.9931034615",
"Unit": "USD"
}
}
}
],
"Estimated": false
}
],
"DimensionValueAttributes": []
}
Thanks! but, this is all so cryptic. I have credits on my account so when running this command I get negative costs. Is there a metric that tells me what would AWS charge for the usage?
Cost estimator gives actual and expected costs for the account.
Are you trying to get an estimate?
in that case you will have to use the pricing module and do some calculations. but if you think the ce output is cryptic, the pricing output is even more so…
i have the following call (but not the contents of filters.json:
aws pricing get-products --service-code AmazonEC2 --filters <file://filters.json> --format-version aws_v1 --max-results 1 --region us-east-1
you can check out the man page docs for pricing to get more details.
good luck! 
What I’m trying to do and failing is to understand how fast will my credits burn. What does a negative amount in Cost even mean? Maybe that’s what AWS is crediting… Anyway, thanks
2023-02-13
does anyone know a fast way to delete all the objects in an S3 bucket? I am waiting to delete the contents of our cloudtrail S3 bucket but its taking literally forever to delete them via the CLI
Try the console? Click the bucket and select the option to Empty it
it won’t let me delete from here
One level higher. Select the bucket and at the top right you should see empty
Hi!
There is a faster way to delete all the objects in an S3 bucket, which is by using the AWS CLI command aws s3 rm. This command will recursively remove all objects and directories in the specified S3 bucket.
Here is an example:
aws s3 rm s3://my-bucket –recursive
Note that this command will permanently delete all the objects in the specified bucket and it cannot be undone, so make sure you have a backup of the data if needed. Also, keep in mind that when you delete a large number of objects in a bucket, it may take a while to complete the operation.
I tried this but its still super slow
because the bucket is versioned
i am doing it like @Charles Rey proposed and its on 20800 objects already and counting
Sorry Steve, don’t have any more ideas. Good luck
set a lifecycle rule to delete objects older than one day, and wait a day
if you have a big bucket this will also save non-trivial $ as you aren’t charged for the API calls to list the bucket and delete individual objects
2023-02-14
does anyone happen to know how quickly an s3 lifecycle kicks in after being changed?
if you google this exact phrase you can find out in the first result
@Alex Jurkiewicz you do realize that the results you get from google are personalized? I know my reply is not helping too
2023-02-15
hey all anyone have good resources on setting up AWS SSO & cross-account permissions? specifically looking for “do it this way” or “here are some things to consider”
At this year re:invent it has been a chalk talk about AWS SSO and this use-case is still not one of the well supported by AWS SSO. if you need to access external AWS accounts, probably AWS SSO is not the right choice.
Under IAM Identiy Center you can add external accounts under Applications and “External AWS Account” under Preintegrated applications.
Need one each for every type of access.
This access type is to me not so useful. It’s not easy to implement programmatic access as other accounts
2023-02-16
2023-02-17
2023-02-20
hey all is it recommended to have a single SNS topic for all cloudwatch style events (at the account level)
SNS doesn’t charge per-topic. Do whatever is easier for you
i want to start setting events to slack for guardduty, security hub, rds and other services
2023-02-21
Hi there I have an issue with max pods limit in our EKS cluster. We created it using tf module “cloudposse/eks-cluster/aws”. Not sure if this belongs rather to #terraform than to #aws … I found this thread https://sweetops.slack.com/archives/CB6GHNLG0/p1658754337537289, but wasn’t able to figure out what I might do. Our cluster (dev cluster) uses t3a.small instances as worker nodes. Each of which have a pod capacity of only 8. So I read about the CNI add-on, added it (manually using the AWS console), set ENABLE_PREFIX_DELEGATION=true and WARM_PREFIX_TARGET=1. Increased the node count (manually, again), so a new worker node was added. But also that new node still has this 8 pods limit. Any hints what else I might check?
Hi all, I have provisioned an EKS cluster and two node-groups using the latest version of the cloudposse/eks-node-group/aws module. The max allocatable pods for a t3a.large node is 8 and I can not find a way to specify this value as the extra bootstrap arguments to be added to the bootstrap.sh script is removed in the last versions. Has anyone else experienced this issue so far?
*the max allocatable pods for a t3a.large node is 35 when you create a node-group using the EKS console.
@Dan Miller (Cloud Posse)
Hi all, I have provisioned an EKS cluster and two node-groups using the latest version of the cloudposse/eks-node-group/aws module. The max allocatable pods for a t3a.large node is 8 and I can not find a way to specify this value as the extra bootstrap arguments to be added to the bootstrap.sh script is removed in the last versions. Has anyone else experienced this issue so far?
*the max allocatable pods for a t3a.large node is 35 when you create a node-group using the EKS console.
AFAIK pod capacity is recorded in launch template userdata, which is managed by Managed Node Group, which re-reads state of vpc-cni addon on changes to MNG configuration.
In short you need to recreate MNG or trigger its update, like changing AMI version or allowed instance types.
Yeah, thank you, @z0rc3r! As you suggested, updating the node group to the latest AMI version did the trick . Now my new nodes show the 98 pods limit, which is the expected number.
Hi guys, the latest release of the terraform-aws-alb module (v1.7.0) uses a alb_access_logs_s3_bucket_force_destroy_enabled variable as seen here: https://github.com/cloudposse/terraform-aws-alb/commit/43aa53c533bef8e269620e8f52a99f1bac9554a0#diff-05b5a57c136b6ff5965[…]84d9daa9a65a288eL209-L221
The sole purpose of this variable appears to be passed down to the terraform-aws-lb-s3-bucket module (as seen here: https://github.com/cloudposse/terraform-aws-alb/commit/43aa53c533bef8e269620e8f52a99f1bac9554a0#diff-dc46acf24afd63ef8c5[…]aa09a931f33d9bf2532fbbL50)
The terraform-aws-lb-s3-bucket module previously used this variable in an earlier release, but no longer does (removed in v0.16.3 as seen here: https://github.com/cloudposse/terraform-aws-lb-s3-bucket/commit/876918fac8682a1b9032cecc61496e61587f6857#diff-05b5a57c136b6ff[…]9daa9a65a288eL17-L30)
While it’s technically valid since it’s pinned to the earlier release of the terraform-aws-lb-s3-bucket module (v0.16.0) - it was quite confusing to understand the purpose of this variable vs. a very similar alb_access_logs_s3_bucket_force_destroy (same variable name without the “enabled” suffix).
It appears there was some sort of possible breaking issue associated with this: https://github.com/cloudposse/terraform-aws-s3-log-storage/wiki/Upgrading-to-v0.27.0-(POTENTIAL-DATA-LOSS)
Is there any reason this can’t be updated to v0.16.3 in the next release of terraform-aws-alb to avoid this confusion?
Anyone know if you can use terraform (module or resource) to customize the AWS access portal URL? By default, you can access the AWS access portal by using a URL that follows this format: [d-xxxxxxxxxx.awsapps.com/start](http://d-xxxxxxxxxx.awsapps.com/start). But, I want to customize it with TF.
Here I am on my crusade against extra AWS costs - Is there a centralized place to disable cloudwatch metrics from being collected or you need to go service by service and disable from there?
the latter. Good luck
i suppose you could use an SCP to deny cloudwatch:PutMetric*
2023-02-22
Does anyone have experience with ADOT (AWS Distro for OpenTelemetry)? Specifically I am investigating if it is possible to use cross account, or if each account needs to have its own instance
2023-02-23
Is there any way to figure out the RDS postgres DB parameters apply_type on runtime? we are using AWS RDS official module
2023-02-24
When using this EKS module (terraform-aws-modules/eks/aws) you need to specify a kubernetes provider in order to modify the aws-auth configmap. I’m trying to create a kubernetes provider with an alias, but I’m not sure how to pass the alias information to the EKS module. Anyone know how to do this?
2023-02-26
Do you have an example of or a reference for IAM policies that:
- allows an IAM user to create/update/delete CloudFormation stacks
- allows an IAM user to pass a service role to CloudFormation so it can create resources
- limits the service role to a few types, ie SG, EC2, and RDS only
2023-02-27
Does AppSync not support Automatic Persisted Queries… ? I went with Apollo GraphQL on Lambda years ago because of this, but I could swear I heard of an AppSync v2? that supported APQ….?
Looks like no… https://github.com/aws/aws-appsync-community/issues/83
Hi, this is more of a question than an issue but I can’t figure out how to prevent the Appsync Graphql-api from having unrestricted access no matter which client being used.
This is my scenario:
I have a React-client accessing the Appsync graphql API with some queries and mutations. The user is authenticated using Cognito. Running the app works fine, the user can query and update data as expected.
However, the very same user can access the API using a 3rd party app like Postman and send unwanted values to a mutation. These values should be calculated internally by the client application only.
How do I secure this? I.e I only want an authenticated user to be able to access the API using the client.
Thanks in advance
2023-02-28
Any recommendations for further protecting an EKS cluster API server that has to be accessible to a cloud CI/CD’s deployers (that deploy containers into a cluster), beyond what is offered via RBAC? IP filtering is easy to setup and has worked well, but I don’t like the idea of relying a list of IP addresses which could change anytime without notice (although this has yet to happen with the CI/CD provider we are using). Are there betters options? Eg OIDC but I’m not finding a way to configure an EKS cluster to use support that auth mechanism.
Found https://developer.okta.com/blog/2021/10/08/secure-access-to-aws-eks, interesting
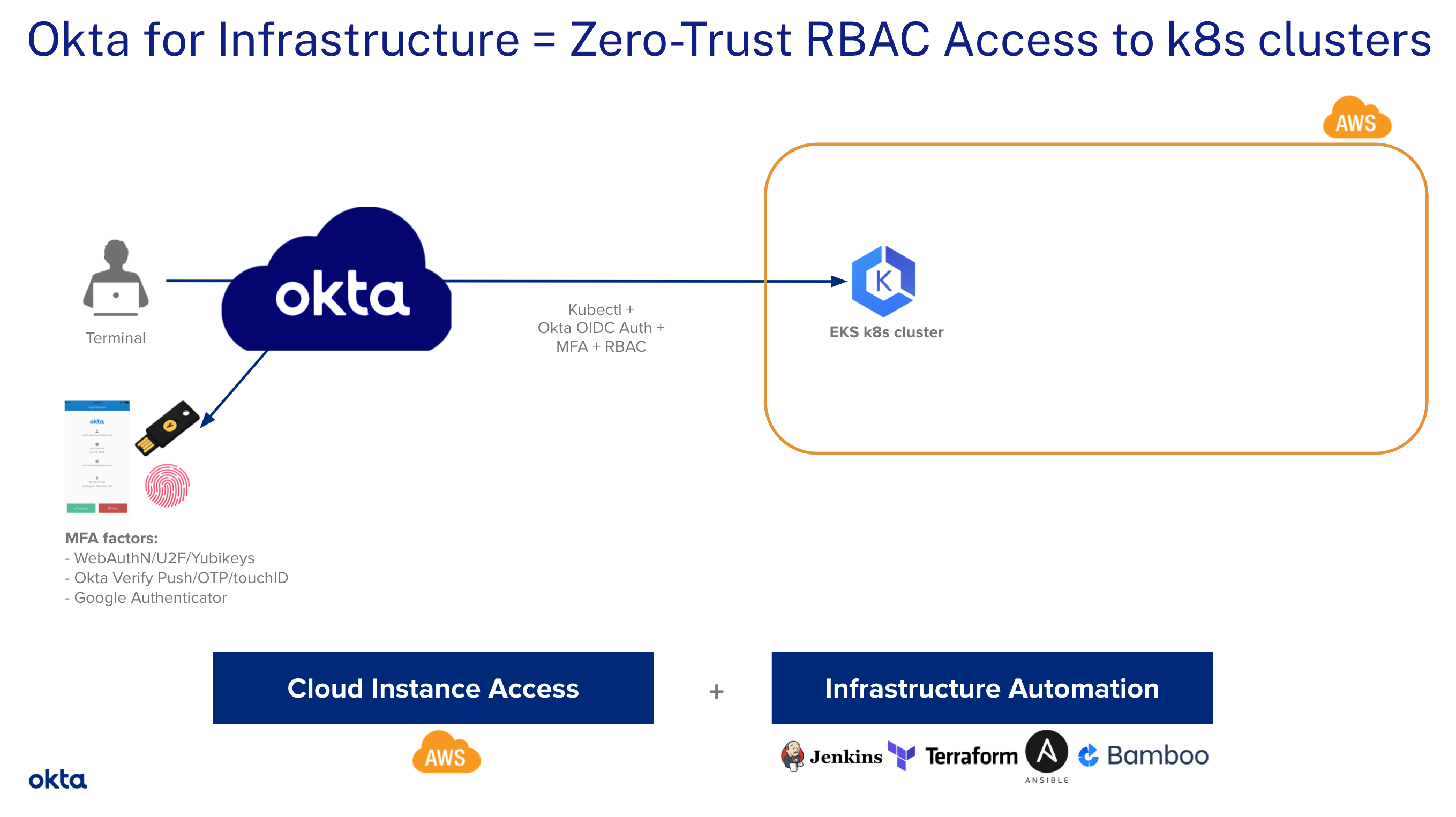
This tutorial is a step-by-step guide for admins on how to implement secure access to AWS EKS Clusters with Okta.
Although this is based on okta, so it’s not a small change for a team … something in AWS would be so much better.
Actually this seems like the same as IRSA, except that it ties in to SSO if that is used by the org
What is the CI/CD system?
For GitHub Actions, this is why we deploy self-hosted runners
It is bitbucket pipelines (not my choice!)
hah, first thing to “Fix”!
Haha, probably will not happen, but I think bb supports local runners
(although I will bring up the possibliity, as it would be nice)
The CI runners can connect into a machine you do control, eg via SSH. This can be a bastion server to the same VPC as the EKS cluster
Thanks @Alex Jurkiewicz, I have actually used that in another project. But unless the ssh key is temporary (like obtained at the time the pipeline is run, via OIDC from AWS EC2 Instance Connect), having a permanent key in a CI/CD secret does not seem like added security since kubectl comms is over https. Also best practice is to not leave sensitive data on bastion (such as .kube file), only use it as tunnel, in case bastion is hacked.
Or maybe if you use a bastion 100% dedicated to the CI/CD (so have separate bastion(s) if other tasks are needed, like for other devops tasks for team), such that bastion can only do what the CI/CD needs and nothing more… then yeah that might be better, as I could see that temp SSH key via OIDC in pipeline + .kube on bastion would be better than having the .kube in a CI/CD secret.
It’s added security because only your projects can authenticate with the bation. IP-based whitelisting allows anyone’s pipelines to access your EKS endpoints directly. Right?
If you mean that anyone using same cicd deployment engine as us could access the EKS endpoint, yes. In that sense, ssh does provided added security.
In the end I found a way to setup ssh socks5 proxy bastion that is used by the cicd alone (ie non-public EKS endpoint), and let devs still use kubectl via IP-filtered public endpoint. This way using kubectl from laptop can continue as before. It will be trivial to switch everyone over to using ssh tunnel if a security concern warrants that later.