#aws (2020-10)
 Discussion related to Amazon Web Services (AWS)
Discussion related to Amazon Web Services (AWS)
Discussion related to Amazon Web Services (AWS)
Archive: https://archive.sweetops.com/aws/
2020-10-01
How do people get all instances using amzn linux 1? I can get a list using ssm from command line but id prefer seeing it as a tag. Any recommends for tagging all ssm instances with their platform version?
thats what i do, runs on a schedule in a pipe
beautiful
thank you very much
can you make that a github gist so i can give you credit
sure
one addition that could speed this up since we have 1000+ instances, we could
- dump the ssm instances
- dump all the ec2 instances that don’t have the ssm tags
- find the ec2 instances that are in ssm and don’t have the ssm tags
- apply the tagging to those ec2 instances instead of all of them
dang im also getting RequestLimitExceeded for the tags…
it looks like --resources can be up to 1000 instance ids
yea ive thought about doing a check but not really a big priority as it works for my needs and a lot of our instances are ephemeral
this would probably work a lot better with a lambda and a cloudwatch schedule
then you could paginate and catch exceptions
@pjaudiomv https://gist.github.com/nitrocode/401fb59fd7318fc91db045164d6f09da
finishes in less than a minute!
awesome much better
You can use aws systems manager inventory I believe as well. Then you can query lots of the details in ssm or Athena.
3 free dev courses for aws cloud native development, they look quite nice on the surface: https://www.edx.org/course/building-modern-nodejs-applications-on-aws https://www.edx.org/course/building-modern-python-applications-on-aws https://www.edx.org/course/building-modern-java-applications-on-aws
In this course, we will be covering how to build a modern, greenfield serverless backend on AWS.
In this course, we will be covering how to build a modern, greenfield serverless backend on AWS.
In this course, we will be covering how to build a modern, greenfield serverless backend on AWS.
Our very own @Adam Blackwell works there :-)
Guys, how do you organize lambdas code? Do you prefer single git repo for all/multiple functions, or you like to keep it separate? We have 50+ functions. I like to separate everything, but developers like to keep everything in once place
assuming you’re using serverless framework, one way is to have a single repo with a serverless.yml for each function in subdirectories. You can use includes for common things.
Generally there are no common things between functions ., and we do not use serverless framework.
Good luck! :)
why good luck? There are good alternatives to serverless
I think separation into multiple repos has advantages but if you want a standard way to configure, test and deploy (i.e. CI/CD) I have found you need automation to set it up and keep them maintained.
So, personally, I would prefer a single repo unless you have a good reason not to. Of course, you then need a CI system that can handle building and deploying only functions that have changed.
As you said, for managing deployment you could use many different tools.
Same, we’ve started with repo per service but actively looking moving into monorepo to minimize the overhead of managing them from infra perspective
are they related?
I could see a single repo if they were all part of an API or workflow
2020-10-02
No, all functions are independent. Thing is that for developers obviously cloning and maintaining 50+ repos wouldn’t be OK. On the other side there is no clean way to maintain CI/CD from my side if we have single repo for all functions.
What are you using for CI/CD?
why “obviously”? i’m easily in and out of well over 50 repos. it’s not particularly hard
that usually points to devs not willing to, or not knowing how to, setup their shell/ide/whatever in a smoother fashion
While I’m a huge fan of targeted repos, I’ve found that while it makes devops work easier… the contributions from others becomes harder if they aren’t comfortable with it.
In the case of 50 functions, I’d propose that unless a specific issue blocks that this might be a good fit for a single repo.
Most of the CICD tools are very flexible with paths on triggers. You could have different workflows for different folders based on path and it could be easier to manage in one place possibly.
Something worth thinking about. I’m actually in the midst of moving a lot of my projects into a more “mono repo of systems management” stuff because the spread out nature of the content has made it very confusing for less experienced team members. While I won’t go full mono repo, I do think grouped content makes sense on the contributors.
If an application and contributors are completely unrelated to each other I’d say separate repos for sure, but otherwise consider less.
I was just discussing that with some terraform stuff yesterday. We only have 3 people contributing to our ‘module monorepo’ but the rate of changes is frequent enough that I think we’re going to split to smaller-module-monorepos where we can. We’re small enough that it doesn’t make sense for us to have 1 repo per module (and our module design is probably bad and would be a hassle if we tried)
Big difference with terraform modules. It forces you to do that to benefit. I’m talking about lambda functions etc. You’ll definitely want individual repos for modules to benefit from versioning and all.
If you are worried about managing the git repos, you can create a git repo terraform repo that will manage your repos
If you are worried about managing the git repos, you can create a git repo terraform repo that will manage your repos
not sure how to grok this
I’ve done this with a client. We used the Bitbucket provider but had to resort to some local-exec too.
oh - build the terraform repos in github, using terraform? is that what you mean?
I think the OP was talking about serverless function repos, but yes same thing.
Create the repo, add required CI variables, configure it, etc.
@Joe Niland Jenkins and bitbucket pipelines. With Jenkins its pretty easy to handle one repo with multiple functions, but I would like to go away from Jenkins to be honest. And I moved bunch of things to bb pipelines already . BB pipelines are not so mature of course and have some limitations. This kinda replies to @sheldonh statement as well about CICD tools flexibility.
@Milosb it looks like Bitbucket kind of supports this now: https://bitbucket.org/blog/conditional-steps-and-improvements-to-logs-in-bitbucket-pipelines

We recently shipped a number of improvements to Bitbucket Pipelines, helping you interact with pipeline logs and giving you greater flexibility…
Thanks a lot @Joe Niland. Somehow I missed release of this feature. It could be quite useful.
Is using pager duty for non actionable alerts and antipattern? Let’s say iam policy changes. Mostly is information and should just be acknowledged unless in rare case it is a problem. Would using pager duty vs just sending a notification to slack/teams be good to you and then open incident IF warranted, or would you have it flag in pagerduty regardless?
Personally I lean towards only actionable priority issues going in pagerduty, but wondering how others handle that. I’ve been playing with marbot and it made me think about the difference between something simple and notifying and something like pager duty that tends to be a lot more complicated to get right.
I’d prefer to keep only important things in pagerduty. Only things requiring me waking up in the middle of the night for doing something. The rest get dumped in slack.
 2
2That’s what I figured to. Sanity check that I’m not crazy. I brought this up in a management meeting. I noticed almost every 15 minutes and alert on a metric that self resolves itself. That type of information I feel dilutes the effectiveness of an incident response system but not sure how much traction will get on that cleanup. I think some are approaching this in that every alert Goes into pagerduty, but it just has different levels of severity.
Look at pagerduty as a message router. You can send the alerts there as a standard, but then select what happens to them (wake people up, slack, email, etc) Only have actionable for anything that goes directly to individuals.
That’s what I think they are doing. So would you have the “message router” even have an incident if no response required? Discard? Incident but disable anybody on service? It’s a very confusing architecture so I’m trying my best to evaluate best practices and not my bias on this.
You could certainly use it to send notices to a channel like that
although you could just as easily do that with SNS and lambda
counter argument - requirement of acknowledgement IS an action and makes perfect sense for this to be managed by pagerduty
Is cloud custodian better for custom rules notifications and config rule creation over doing with RDK or manually?
whats rdk
That figures. It’s the Amazon AWS Config Rule Development Kit.
Prefer to use Cloud Custodian if creating custom rules are straight forward. The less plumbing to set this stuff up the better.
lol ya cloud custodian is what i use. never used rdk
ive had great luck with custodian. it has some limitations. it covers a lot tho
2020-10-03
2020-10-05
Hey! Is anyone using AWS CodeDeploy? I’m trying to understand how to clarify which alarm was triggered while the version was deploying.
I want to do per-user rate limiting. AWS WAF does per-IP rate limiting (which is important as well) but users authenticate with Cognito JWTs and it would be great to have a user-aware limit. Any ideas?
We recommend that you add web ACLs with rate-based rules as part of your AWS Shield Advanced protections. These rules can alert you to sudden spikes in traffic that might indicate a potential DDoS event. A rate-based rule counts the requests that arrive from any individual address in any five-minute period. If the number of requests exceeds the limit that you define, the rule can trigger an action such as sending you a notification. For more information about rate-base rules, see
2020-10-06
We have several golden AMIs that teams have built AMIs off of (children), some AMIs are built off of those (grand children), and now we’d like to figure out how to track the decendant to its parent
Hey folks, what AWS service(s) should I be looking to utilize for ensuring notifications / alerting around AWS account changes surrounding the following:
- CloudTrail configuration changes
- Security Group Changes
- AccessKey Creations Some background: A client of mine is currently PCI compliant and they have CloudWatch Alarms / SNS Email Topics for alerting around the above changes, but they’re not in Terraform and we’re migrating all their ClickOps, poorly named resources over to Terraform. Now I could have one of my junior engineers create these same alerts through terraform, but I feel like there is a better way. Control Tower? AWS Config?
Control Tower is an industrial tunnel borer to crack a nut, so I would discount it here. Unless you are going to use it anyway and have already invested into customising it.
A small Terraform configuration to create these alarms (which takes a variable for the SNS topic to send notifications so) sounds ideal really. KISS.
Importing the existing resources into your Terraform configuration and setting lifecycle { ignore_changes = [name]} is a pattern I commonly reach for when I am importing unmanaged resources. Especially when re-creating the resource is troublesome and they don’t support renames (might apply to your SNS topic, if you manage it).
So AWS Config for security group monitoring
and AWS Macie or AWS Detective for CloudTrail, which would also probably catch the access key creations
@loren is the SME on this topic
i’d second @Alex Jurkiewicz, keep it simple. importing any existing setup of events, alarms, and alerts is the easiest place to start. i haven’t yet seen an “easy button” for managing a “secure” infrastructure. everything needs to be customized for this customer, everyone needs to invest in managing their implementation(s). over time, setup securityhub, config, guardduty, cloudtrail, iam access analyzer, and whatever else comes out. you will, in the end, still need to manage those events, alarms, and alerts, you really just are adding more sources and event types
Good stuff — Thanks folks. I’ll keep it simple for now then and dig further into this in the coming weeks.
2020-10-07
What do you guys think the exploit is exactly?

Palo Alto Networks discovered two critical AWS cloud misconfigurations that could have led to a mulit-million-dollar data breach.
Maybe related to the fact that AWS account is not always required in ARNs in IAM? And it can give access to the same resource but in another AWS account somehow.
Palo Alto Networks discovered two critical AWS cloud misconfigurations that could have led to a mulit-million-dollar data breach.
of that MFA is not enforced for API calls so widely as it should be?
I was thinking something like that too, i.e. sometimes * is used in place of account id as well.
Or could lack of external id be related or using PassRole without a resource filter?
yes, external id always makes me think like an extra security feature which is 100% optional I don’t know how to explain it better really
Haha, yes, well said
I was recently discussing if there is room for a (OSS) tool for developers which builds the infrastructure up, multi account etc, configs, guardduty, transitgw. The argument against a tool like this was control tower which I haven’t checked myself yet. I’m curious to know other’s opinion regarding Control Tower & Landing zone.
when i last investigated control tower, it was a mess of cloudformation templates and nested stacks. seemed super hard to extend and update/verify over time
maybe it’s gotten better, but i’d rather invest expertise in terraform than cloudformation
very much what i wanted to hear
also, every customer we’ve spoken to that got started using control tower because it was provided by aws and marketed as an “easy button” is now frustrated with it
Control Tower works because customers who sign up to use it go “all in” on the solution. It requires a large amount of trust that AWS will continue to maintain and do the right thing for you.
I think you will run into a problem where the customers of your alternative will have very precise, fiddly, exacting requirements, and you won’t have the reputation to convince people to change their workflows to suit your standard.
This means your tool will have to be customisable in essentially every way. And at that point, your tool won’t be so different from putting the building blocks together from scratch.
3This is a general class of solutions we call “reference architectures”
And while we started out with a very rigid reference architecture, we found customers wanted a lot of changes. So what we’ve ended up doing is investing in a reference architecture as a project plan, comprised with hundreds of design decisions that we execute together with customers.
We are able to leverage the corpus of cloudposse modules as the foundational building blocks and some (currently) closed source root modules.
If you break it down, you have a reference architecture which is consisting of different modules, root modules and let’s say their linking. I’m sure there are projects who with configurations which will not be able to be re-used anywhere and that’s also not the aim. There is a large set of projects which evolve around EKS/ECS/Serverless multi-stack etc. , quite the common denominator..
Now if you have a tool which does the terraform execution and uses preconfigured sets of reference architectures of which one can then be applied to the customer stack in their respected accounts. Subsets of the stack are easy to be modified through UI etc. 4 eyes principle where needed, then is that something helpful or a waste of time to build ? A bit like env0 mixed with pre build or curated reference architectures.
I guess I disagree with:
There is a large set of projects which evolve around EKS/ECS/Serverless multi-stack etc. , quite the common denominator
Every company considers themselves a special snowflake. (Whether it’s true or not is besides the point.) Any reference architecture will have at least one “must change” blocker for every company.
anyone here do any integrity checking on binaries on golden amis ?
2020-10-08
Amazon Timestream is now Generally Available Anyone was using it during beta? Any insight?
Maximum 200y retention for metrics on magnetic storage sounds amazing
better get an RI for that to optimize costs
But timestream is serverless service so I’m not sure what RI (reserved instance?) are you referring to?
I was trying to make a joke
200 years of EBS storage
If it’s as easy to use as InfluxDB and I can plug in Grafana OSS I’d love to try it
Telegraf is failing with it right now. Telegraf build issue. Super excited. Needed something in aws for this as don’t have InfluxDB. Grafana supports it in OSS edition now! Woot!
Got it built and it’s working! Freaking love that I can write SQL. No learning curve to get value compared to FluxQL for example.
Gonna be leveraging for sure!
It’s working great so far. I have a dedicated access key just for it and no complicated security groups or setup required. Plug this into my telegraph config and I have separate accounts all pushing to one time stream database now.
I freaking love that they stuck with SQL syntax (as my expertise) … Grafana connected just fine. Surprisingly smooth once I got telegraf compiled.
I’m really looking forward to pushing some custom metrics into this. I’ve been blocked on some custom metric visualization with grafana because of not having influx DB anymore. Cloudwatch query API just sucks. This could easily seem to solve cross account aggregation dashboards. Gonna blog on this as soon as I can.
Yeah Sheldon! I migrated away from influxdb (used for my private IoT) today and I’m pretty happy about it. Grafana dashboard with timestream plugin works like a charm. Had no problems whatsoever as it’s pretty simple AWS service.
no tf support so far though
Telegraf? Look at my forked copy of the telegraf repo, grab the timestream branch which I’ve updated and try that. I have it running on monitor box in prod pushing metrics now :-)
It needs some refinement there are some measure name length errors but nothing stopping it from working that I see.
Also found out telegraf should work in lambda . They added run-once option so cron, SSH, etc should work. I think I’m going to give that a shot sometime as cloudwatch log forwarder. That or maybe just run in fargate though I think that would be much more expensive in comparison.
The biggest reason I’m excited about this… Cross account metrics from cloud watch is such a pain. the single biggest reason I preferred influx was to be able to aggregate all of my time series metrics into one place and use tags. I’m pretty sure now that time stream will solve that entire problem and allow me to build a dashboard that is purely tag driven. As far as basic metrics go I honestly don’t see a tremendous value from a tool like data dog just for metrics with with a solution like this possible. My next step is to spin up a grafana instance in fargate with github auth.
Haha, we are on the same page. I just spinned grafana in fargate yesterday and thinking about moving it away from K8S. One thing to know is that timestream seems pretty inexpensive for your usecase. $0.01 per 1gb of data scanned
I do agree CW is pain, it’s a really old product and because of that it can’t be upgraded making it backward incompatible (legacy component that too many companies rely on). I wonder how it will evolve tho
What module did you use for grafana. I’ve not yet set it up as didn’t have all the certs, github oath setup etc.
Official timestream plugin
Managed timeseries database from amazon
I’m asking about setting up grafana self-hosted. I already am using that data plugin. I just want to get it hosted and not have to manage (so fargate etc)
Ah, you asking about module as terraform module? Or something else?
Module for grafana deploy and build. I’m nearly there but lots of pieces to get in place
Yeah, I’m writing my own module for that which is tailored for my needs.
Has anyone had aws-vault be tagged as a virus by Microsoft Defender?
(I know running it in Windows is a bit weird)
We have a centralised auth AWS account which has IAM users. These users get allocated permissions to sts:AssumeRole into our other AWS accounts where real infrastructure is kept. We have a 1:1 mapping of roles to an IAM group. So to allow a user to assume a particular role, we add them to the corresponding group. The problem with this design is users can only be part of 10 groups. Anyone have a similar central auth AWS account? How to do you manage who can assume what in a scalable way?
per-user roles, with common managed policies, deployed through terraform
create the user in the central account, and at the same time create the role and attach policies in whatever accounts they need access to
So each user gets an individual role in each target account? And then you build up a single large inline user policy for them
@loren How do you communicate to users what the roles they can assume are, if every user’s role is unique?
Role is named for the user. And not necessarily an inline policy… The groups you use would map to a managed policy in the target account. Attach that policy to the user role in that account
Each user has a single role in each account they need to access in this model
One of the options would be to Create Customer managed policies (One per account / Role combination) and tag them AssumableRoleLink. The policies would then be assigned to the user (Not the best option as groups are preferred). You can then write a script to compose a page for the user by iterating through the tags and scanning for the tag and building a web page with links, or JSON with the relevant data.

Developers no longer have to make their Lambda functions Vault-aware.
This is a nice use of Layers
Developers no longer have to make their Lambda functions Vault-aware.
And the new extension feature!
oh wow - I thought it was a synonym for layers
Nope, just released! https://aws.amazon.com/blogs/compute/building-extensions-for-aws-lambda-in-preview/

AWS Lambda is announcing a preview of Lambda Extensions, a new way to easily integrate Lambda with your favorite monitoring, observability, security, and governance tools. Extensions enable tools to integrate deeply into the Lambda execution environment to control and participate in Lambda’s lifecycle. This simplified experience makes it easier for you to use your preferred […]
Very interesting. Thinking about how the External extensions can be used.
Hi, I have a question regarding AWS Loadbalancers (ELB, classic): It is normal, that the connection/response rate for a newly spanned LB is very slow? After creating an EKS cluster and attaching an ELB to it I was only able to query a website (HTTP connection to a container) at about 1 request every 5 seconds Now after some hours I have a normal response time of about 0.08s per request
Used this simple script: while true; do time curl [app.eks.example.com](http://app.eks.example.com); done
No. Maybe I would expect poor performance for the first 15mins. Are you sure it’s the ALB and not your backend resource?
Wait, why ELB not ALB?
Because ist the example I took. The ALB needs more config because the LB is created by the cluster
2020-10-09
anyone do integrity checks on their packed amis ?
such as running an agent that gets hashes of all installed binaries and save to a file or db before the ami is created ?
for sharing amis across accounts, do people simply set the ami_users argument in packer or is there a better way to share AMIs across accounts ?
that appears to be how we’re doing it
ah ok yep thats what i figured. ive heard of some people who have more than 100 aws accounts and i thought, they can’t be simply appending a comma separate string in ami_users, or can then !?
but we only manage like 10 accounts so it’s easy enough for us to update with a long string.
@Zach how do you tag your amis in shared accounts ?
Right now I have azure pipelines run the build. After successfully passing pester tests I use a go CLI app that triggers the terraform plan. This plan updates SSM parameter store by looking for the latest version of the Ami. Everyone points to SSM parameter store not to amis directly
My SSM parameters I believe use the cloud posse label module so all of my tagging and naming is consistent
yah we only run in a couple accounts so its a very short list. Tags don’t share cross-account (damn you aws) so we encode the info we need into the AMI name
our pipeline is awful though, we’re about to start some changes to that. Was kicking around sort of the same thing sheldonh was saying - using either paramstore or just s3 to write AMI metadata that could be indexed out and used in terraform data too
azure pipelines, interesting. i guess by moving the tag information from aws amis and into a separate system like SSM or other, then the tag does not need to be put on the AMIs themselves. novel!
so it sounds like Zach, you have the same issue as me
if the value is in paramstore, wouldn’t it be in a single region on a single account ?
does that mean that when retrieving the information, we’d have to retrieve it from a specific account and region or would the ssm param have to be copied to other accounts/regions ?
I think you can share params, but I’m not. I just setup my terraform cloud workspace for each (or you could do a single workspace with an explicit aliased provider).
If you need in multiple regions then you can benefit from the new foreach with modules so that shouldn’t stop you. The main benefit is no more scripting the ssm parameter creation, now I just use terraform to simplify and ensure it’s right
so it sounds like Zach, you have the same issue as me
yup. its a pain. We found out when I thought we could do some clever stuff to use tags in a pipeline and turned out to not work once we crossed accounts.
there must be an easy way to do it by using a lambda that can assume roles in all child accounts
Probably, though that was more work than we were willing to do at the time
I use terraform for ami_launch_permissions in a for_each based on a list with aws account ids. cross region replication can be done the same way.
Interesting. What’s the difference between doing that and setting the ami_users in packer?
You can create launch permissions for each image individually. Now we no longer have to maintain a list of aws owners id’s for each Packer image. Instead it can be managed from one space.
you add permissions to an existing AMI that you created earlier. so no need to run packer again for all AMI’s that you want shared.
can share some tf code if you are comfortable with that, but you will have to modify it to suit your own needs.
2020-10-10
is there any option to change metricsListen in eks without using kubectl edit cm?
For kube proxy? We ended up pulling all the objects as yaml and now deploy with Spinnaker, including changing metrics listen address… It’s a pain that the raw yaml isn’t available from AWS. Just watch as the configmap has masters address in it which will differ per cluster.
I want to avoid to patch the configmap everytime that I create a new cluster
Yeah that sucks. Maybe add comment to issue in AWS container road map. Maybe with terraform can get the config map details out and hydrate yaml etc. You’ll need to update kube proxy from time to time so might as well bring it into CD tooling along with other apps going into cluster.
2020-10-11
2020-10-12
Useful for practicing queries, developing response plans? https://summitroute.com/blog/2020/10/09/public_dataset_of_cloudtrail_logs_from_flaws_cloud/
AWS Security Consulting
Hello team, I am pleased to announce the official release of CLENCLI. A command-line interface that enables you to quickly and predictably create, change, and improve your cloud projects. It is an open source tool that simplifies common tasks that many Cloud engineers have to perform on a daily basis by creating and maintaining the code structure and its documentation always up-to-date. For more details please check the project on Github//github.com/awslabs/clencli>. I would love to hear your feedback and which features would you like to see implemented in order to make your life in the cloud easier.
CLENCLI enables you to quickly and predictably create, change, and improve your cloud projects. It is an open source tool that simplifies common tasks that many Cloud engineers have to perform on a…
 1
1CloudPosse’s build-harness project inspired me to develop something similar, that could be shared among teams as a binary, that could be simply executed and generate project and render templates easily.
CLENCLI enables you to quickly and predictably create, change, and improve your cloud projects. It is an open source tool that simplifies common tasks that many Cloud engineers have to perform on a…
So this is my humble way of saying thank you CloudPosse team and all of you that makes this community (the open-source) amazing and incredible, and the CLENCLI is my attempt to give back. Thank you!
I was just looking at the docs and I realize that was doing so something similar
super cool!
2020-10-13
If you didn’t have full control of infrastructure as code for your environment and all the places a common security group might be used would you:
• Gitops workflow for the shared security groups so that submissions for changes go through pull request
• Runbook with approval step using Azure Pipeline, AWS SSM Automation doc or equivalent that runs the update against target security group with basic checks for duplicates etc. I want to move to more pull request driven workflow, but before I do it this way, I’m sanity checking to see if I’m going to set myself up for failure and be better off with a runbook approach if I can’t guarantee the gitops workflow is the single source of truth period.
Might not be a question you want to hear, but why do you have common or shared security groups? Why not have separate ones, simply instantiated from the same template?
I’m asking because if you are sharing SGs, you may be exposing some resources on ports and source traffic they shouldn’t be exposed to. Also, making any “corrections” there will be problematic as it may impact a resource you’re not aware of.
Not all our infra is managed through code yet.
There are some common lists for access to bastion boxes in a nonprod environment for example and it’s causing lots of toil for the operations team. I want to provide a self-service way to submit in a request and upon approval (either in pipeline or pull request) have it apply those updates. Otherwise it’s all done by logging into console and editing the security groups manually right now.
It’s not perfect but I’m trying to implement a small step forward to getting away from these manual edits to maintain stuff so critical.
The process you are trying to improve - is that simply a matter of adding more IPs so they’d have access to the bastion? Or is it something else?
Pretty much. Add some ips, remove previous ip if it’s changed, maintain the list basically. Right now it’s all tickets. I want to get towards having the dev’s just submit the pull request, the pull providing the plan diff and upon an operations team member approving (or latest automatically running in nonprod environments), it updates those changes.
Is your end goal utilizing a lot more IaC? (Terraform or something else?)
yes. I do that with all my projects, but am working on getting some small wins in improving the overall comfort level of folks not currently using this approach.
however, if warranted I’m open to creating something like an AWS SSM Automation doc with approval step that does something similar. Just trying to get some feedback to make sure my approach makes sense to others or if I’m missing something
I think it depends on your end goal. If your end goal is to get as much covered by IaC as possible, I’d use the gitops route. It gets them used to doing things in IaC, and allows you to “ease into it” and see where things break.
My experience is that it’s pretty easy to train someone on how to make changes to a text file, commit and push it. Where you may find some trouble is in conflicts (git conflicts), hopefully that doesn’t happen.
BTW - as some point you’ll want to include security review of your IaC. Depending on the language you use, you’ll have a range of tools. If it’s Terraform, you can use checkov, terrascan, tfsec or Cloudrail (the last one being developed by Indeni, the company I work for).
yep! I was planning on putting the tfsec esp in my github actions so you are right on the money. I’m familiar with the workflow myself, but trying to verify it makes sense.
Team with zero experience of kubernetes is told to implement a gitops workflow with EKS + Airflow. Most experience is some windows ECS cluster build through terraform for a few folks. Level of difficulty to correctly setup infra-as-code
Somewhere between 2/3 is what I would really say. Depends on the team and how quick they are to pick up new things.
Some minor burns and contusions possible :-)
I need this as a keyboard macro whenever interacting with AWS support is on the menu:
Hello, I’m Alex. How are you going? I’m going well
They don’t answer my questions until we exchange these messages. And I’m only half joking
Yes. I’ve noticed that they want to exchange pleasantries before they start working on the problem
I usually beat them to the punch now by jumping in and saying “hi Im RB and this problem is stressful. My day was going well until I saw this. I tried to write out the full issue in the description, does it make sense?” :D
I’ve created general support cases to give them feedback just like this, highly encourage others to do the same as it’s not going to change until enough customers speak up.
My recommendation was that they allow us to fill out a customer profile that includes: Skip Pleasantries: true
2020-10-14
Hi all, I’ve an ASG on eu-west-1 based on spot instances c5.xlarge and I’m experiencing a termination of 2 instances roughly every 30 mins(Status: instance-terminated-no-capacity). Now I added another instance type and seems a bit better. Are you aware of a way to check spot instances capacity for a given AZ and instance type?
Anybody use a Yubikey w/ AWS Vault? Is there a better prompt on MacOSX than osaprompt? It’s bugging me that my machine won’t let me paste into that text box.
ah so I have noticed this issue too. i use the force-paste applescript to do this.
Paste text even when not allowed (password dialogs etc) in macOS - EugeneDae/Force-Paste
Ah interesting and then you just have a menu bar app that you click to paste… That makes it better. Thanks for the suggestion!
np. unfortunately, a lot of things depend on the mac prompt which disallows pasting
Yeah, it’s a PITA. I already need to use the command line to request a AWS token code for MFA auth… makes this Yubikey thing better than having to pick up my phone, but not by as large of a margin as I was hoping.
Need windows + linux administration, inventory, configuration management etc. AWS SSM has lots of painpoints. Would I be best served looking at Opsworks Puppet enterprise in AWS for managing this mixed environment?
For instance, someone asked me the state of windows defender across all instances. With SSM it’s pretty clunky to build out a report on this, inventory data syncing, athena queries, maybe Insights or other product just to get to useful summary. Will puppet solve a lot of that? The tear down and up rate is not quick enough and the environment mixed enough that managing through SSM Compliance and other aws tools is painful.
Is there any easy button to getting Grafana + Influx up in AWS (single cluster) for fargate or something similar? I’ve found Gruntworks module but at first look it’s all Enterprise. I’m working through a Telia module but nothing quick, as I need to update the grafana base image and other steps. Kinda been blocked on making progress due to it being side project.
how do you all use exported creds in local development?
we use hologram internally so the creds just work for all local dev
but we’re switching to okta to aws sso saml
when we click on okta to go to aws, it offers aws console or awscli creds
just not sure if this is the best approach
There is an AWS + Okta CLI tool that is maintained for okta I think…
I’d search the SweetOps archive for okta + aws. I feel like it has been discussed before for folks who are using Okta (I’m not).
we use aws-vault and soon we will be using aws-keycloak so it will be interesting to see how that goes
the saml2aws looks like it might replace our hologram tool
but ya ill take a look at the aws + okta
ya ive definitely asked other questions about this before but derivations
aws-vault works but still requires some manual stuff. we have a number of people complaining about it
i like aws-vault tool. i think they just want somethign that does it all without any manual steps
They don’t want the aws-vault add step or what?
I just onboarded a client’s team of ~10 engineers to aws-vault. I know I’m going to be helping them deal with issues for the few weeks, but it’s a lot better than alternatives that I know of.
what manual step? installing it? setting up the cli?or you have picky customers?
for instance, if you look at saml2aws, you use the login component, and it dynamically retrieves creds for you
whereas with aws-vault, you need to go through the sso, get the creds, paste them into aws-vault
right ?
lol might be picky customers too
so if I use aws-vault, I need to input two factor every time after every hour
which is basically the same in SSO
that is just people being picky
2 factor is standard and SSO is very similar workflow
@jose.amengual This might help you with that 1 hour TTL — https://github.com/Gowiem/DotFiles/blob/master/aws/env.zsh#L2-L3
Though I will say, MFA is still a PITA as it is request in scenarios where I don’t expect it to be. That’s why I got a yubikey.
the problem with that approach pepe is that your creds are still static. the saml approach is more secure since the entire path is sso
if you are curious, this is the issue i hit https://github.com/Versent/saml2aws/issues/570
there is a relevant blog post on amazon on this too
ahhh no bu what I means is not what is more secure or not, I meant to express that the flow from the user interface perspective is similar
run this, copy that, paste it here
@Matt Gowie we figure our that the aws automation we had was setting the TTL to 1 hour instead of 4 or 12 hours etc
Ah yeah for new roles it defaults to 1 hour I think.
omgogmogmgg i figured it out
$ aws configure sso
SSO start URL [None]: <https://snip-sandbox-3.awsapps.com/start>
SSO Region [None]: us-west-2
Attempting to automatically open the SSO authorization page in your default browser.
If the browser does not open or you wish to use a different device to authorize this request, open the following URL:
<https://device.sso.us-west-2.amazonaws.com/>
Then enter the code:
snip
The only AWS account available to you is: snip
Using the account ID snip
There are 2 roles available to you.
Using the role name "AdministratorAccess"
CLI default client Region [us-west-2]:
CLI default output format [None]:
CLI profile name [AdministratorAccess-snip]:
To use this profile, specify the profile name using --profile, as shown:
aws s3 ls --profile AdministratorAccess-snip
so beautiful
That’s just the native aws CLI?
yeah
pretty epic
Ah sweet — did not know that. AWS SSO will be the future for sure. Things like this just need to ship — https://github.com/terraform-providers/terraform-provider-aws/issues/15108
Community Note Please vote on this issue by adding a reaction to the original issue to help the community and maintainers prioritize this request Please do not leave "+1" or other comme…
yep and aws sso is free
this is a good faq on it https://aws.amazon.com/single-sign-on/faqs/
View frequently asked questions (FAQs) about AWS Single Sign-On (SSO). AWS SSO helps you centrally manage SSO access to multiple AWS accounts and business applications.
2020-10-15
Hi, does anyone has experience in buying reserved instances/ saving plans? I find it confusing because there are so many different options!
broadly it looks like RI’s will likely go away and savings plans will become the way AWS will run this in future. If you look at the www.calculator.aws you can run a m5.large instance through the options and see what the benefits are. RI’s used to be ‘heavy, medium, light’ usage where saving plans is combining that with some other stuff.
If you look at AWS costs year-on-year, prices go down substantially, so be wary about committing to a 3 year all upfront on instances that you’ll not likely need.
also check pricing here: https://www.ec2instances.info/
Hey :wave: - I’m looking at getting EFS up and running cross account but need to avoid the hacking of /etc/hosts as we’re planning on using the EFS CSI Driver to make use of EFS in Kubernetes. The AWS documentation is pretty lacking in this area and mentions using private hosted zones, but doesn’t really go into any further detail. Does anyone have experience of cross account (or VPC) EFS and route 53 private hosted zones that could offer a bit of insightful wisdom?
Maybe there are other non-EFS examples that might help
I did a lot vpc peering lately , Privated hosted zones might work , costs about .50 per month , if all you need is dns resolution , I would create a privated hosted zone ( yourcompany.net ) , attach the vpc that needs to resolve the ip and add an A record for the efs ip let’s say fs01.yourcompany.net ) , then use fs01.yourcompany.net instead of the ip while mounting the efs and the resource in that vpc will resolve that to the ip of efs let’s say 10.x.x.x
Obviously route53 will resolve the dns name to ip but to actually connect to the efs , vpc peering is needed
We have VPC peering between the accounts (and transit gateway), annoyingly the EFS CSI Driver only accepts the EFS ID and passes it to efs-utils to mount, it doesn’t accept custom DNS names - I spoke to AWS support and they suggested the same thing (custom DNS domain). Luckily, we were able to create a private hosted zone with the same name as the EFS DNS name (fs-blah.efs.region.amazonaws.com) and set it’s APEX A record to the 3 EFS mount target IPs. We could then authorize association to the zone from the other VPCs.
The one thing you lose is the assurance that you’re connecting to the EFS mount target in the same AZ as the client as The route3 record set is just plain old dns-rr.
It’d be great if you could create AZ aware private hosted zones as AZ specific records aren’t an option with the CSI Driver AFAIK.
Yeah I never had success with efs-utils
An ansible playbook or simple terraform remote exec will do the job while provisioning new infra , even with existing ones , ansible or a manual mount command works like charm
Yea but since you’ve a different use case , you’ve to deal with annoying efs utils
does anyone have at their disposal a completely readonly IAM role?
i tend to lean on the aws-managed policy SecurityAudit
makes sense
there is also a ReadOnlyAccess policy aws-managed, but i think it is too broad. for example, it allows anyone to retrieve any object from any s3 bucket.
the audit policy is more restricted to metadata, no actual data
i am going to go with SecurityAudit like you recommended. thanks
but i use one of those as the base, depending on the role, then extend it with a custom policy if the users need a bit more or some service isn’t yet covered by the aws-managed policy
There is also the ViewOnlyUser job-function policy — https://docs.aws.amazon.com/IAM/latest/UserGuide/access_policies_job-functions.html#jf_view-only-user
Use the special category of AWS managed policies to support common job functions.
this is mainly to give engineers readonly access via the console by default
ahh, ViewOnlyAccess looks like a good one also
might do that
hi, is this the latest and greatest way to setup aws <-> g suite sso for console and cli or are people using something else? https://aws.amazon.com/blogs/security/how-to-use-g-suite-as-external-identity-provider-aws-sso/

August 3, 2020: This post has been updated to include some additional information about managing users and permissions. Do you want to control access to your Amazon Web Services (AWS) accounts with G Suite? In this post, we show you how to set up G Suite as an external identity provider in AWS Single Sign-On […]
Funny, I set this up this morning.
August 3, 2020: This post has been updated to include some additional information about managing users and permissions. Do you want to control access to your Amazon Web Services (AWS) accounts with G Suite? In this post, we show you how to set up G Suite as an external identity provider in AWS Single Sign-On […]
It works well.
cool, good to know:) did you do it manually or find a module to automate it?
Entirely manually
AWS SSO doesn’t have a TF module
ok, that’s too bad
you don’t need a module for that, it’s a few lines of TF
resource "aws_iam_saml_provider" "default" {
name = "....."
saml_metadata_document = file(....)
}
Terraform support for AWS SSO coming at some point soon hopefully — https://github.com/terraform-providers/terraform-provider-aws/issues/15108
Community Note Please vote on this issue by adding a reaction to the original issue to help the community and maintainers prioritize this request Please do not leave "+1" or other comme…
this is good
but not the same as SSO with GSuite + AWS SAML provider
the diff is where you store the users
with GSuite, the users are in GSuite (which is IdP in this model), and AWS SAML Provider is a service in that model
with AWS SSO, AWS is IdP and you store your users in AWS
You manage the permissions for the GSuite users in AWS SSO though
It maps the user via the email (email is the username in AWS SSO), and permissions are managed within AWS SSO.
Yeah, is the way I’ve set it up in the past personally.
But that being said I still get confused with the mess that is the SSO / SAML landscape. It’s a cluster. @Andriy Knysh (Cloud Posse) sounds like you’ve dealt with it plenty. Ya’ll at CP should write a blog post on that.
In AWS IAM
haha, maybe even a book
AWS SSO is a separate service and permissions are managed there. It’s funky.
Learn how to use AWS Single Sign-On to centrally manage SSO access for multiple AWS accounts and business applications.
the diff is b/w authentication and authorization
authorization is always in AWS IAM since you tell AWS what entities have what permissions to access the AWS resources
with Federated access, the authentication is outside AWS (GSuite, Okta, etc.) - the authentication service (IdP) gets called for user login, and it in return gives back the roles that the user is allowed to assume
AWS SSO tries to be the authentication service (IdP) as well (similar to GSuite, Okta) - if you want to store your users in AWS
nice demo about that https://www.exampleloadbalancer.com/auth_detail.html
also, to completely understand the stuff, watch this https://www.youtube.com/watch?v=0VWkQMr7r_c&list=PLZ4_Rj_Aw2YkXY5aXk8_sTOiq8HC54fOK&index=1
Cool, I’ll check those out — Thanks. Could always use more education in this area.
still POCing it and it’s not as good as hologram but it’s a work in progress
I’ve also gotten this to work manually, except for login via G Suite menu, which runs into an error. Going directly to the SSO “start” page works and cli access works well, so I’m pretty happy with it so far. Will continue testing for a few weeks
I couldn’t get the login via G Suite menu to work either, but similarly to you, it was good enough for me.
anyone use aws batch ?
just realized it’s a frontend for ecs tasks
… but with less configurability. We’ve tried it and abandoned it. Any specific questions?
well were hitting the 40 queue limit on one of our accounts and i was thinking, why even bother using this if it’s just a frontend for ecs
especially now that there are off-the-shelf terraform modules for creating scheduled tasks
Yeah I agree. I think it’s targeted towards people coming from a big HPC-cluster environment (think academic or gov’t labs) with a PBS-type scheduler. The interface is very similar to Sun Grid Engine (then Oracle, now Univa) or Moab or Torque, Slurm, etc: you submit array jobs composed of 1-to-many tasks per job. You can add optional cross-task dependencies to make a workflow.
If you’re using Terraform then you’re probably not the intended market, which IMHO is why it seems superfluous
2020-10-16
If anyone has some Cloud custodian custom rules for AWS SSM inventory I could use it. I want to deploy an AWS configurable that checks SSM inventory on all windows instances for a specific role. I found the cloud formation schema but we’ll have I’m guessing an hour to figure all that out.
I would also like to know if anybody uses AWS config to define desired state inside a server to be validated. Let’s say I want to have a service running inside server. To test compliance of this would AWS config be the incorrect approach and instead it would just be a cloud watch alarm/event/opscenter? The boundary for what is the appropriate solution is a bit muddy as usual with aws
the cloud custodian gitter.im might help you
i haven’t done anything with custodian’s ssm schema
their ssm schema seems pretty limited
Do either of you have a good resource for shared Cloud Custodian policies? I’m just starting to look into this tool and I’d love to find something that was focused on PCI, SOC2, or even just general “Best practices”.
cloudtamer.io wraps cloud custodian with policy baselines mapped to certifications… I know they do CIS, at least. Not sure if they offer anything like a free tier, or open source though
Any idea on their cost?
they have a number of tiers, but for the enterprise side of things i was looking at something like $5k per year, plus $5k per $100k in cloud spend
2020-10-18
Is anyone using aws opscenter regularly? I’ve been exploring and love the level of information you get on an issue and the list of associated automation runbooks. Turn off all the defaults and setup a few opscenter items on key operations issues to handle and it seems much promising.
Pager duty would require an ton of work to get there. Thinking of trying to trigger opscenter item for say a disk space issue would be so much more effective than a pagerduty alert for equivalent.
I want more runbook automation steps associated with issues and don’t see easy way to promote in pagerduty in comparison to opscenter. I know you can add custom actions to run but it’s not the same thing.
AWS Systems Manager Automation helps you quickly remediate issues with AWS resources identified in your OpsItems. Automation uses predefined SSM Automation documents (runbooks) to remediate commons issues with AWS resources. For example, Automation includes runbooks to perform the following actions:
2020-10-19
 We have a scenario where we have 3 services (elasticsearch. Kibana and APM server deployed on EKS cluster) and we want to expose it to public using AWS ALB.
Would you prefer 3 ALBs one for each service or one ALB handling all 3 services ? what would be your take on this ? We have tried both way it works and we see one ALB for all 3 services is less code + less cost but not sure of any downsides of this
We have a scenario where we have 3 services (elasticsearch. Kibana and APM server deployed on EKS cluster) and we want to expose it to public using AWS ALB.
Would you prefer 3 ALBs one for each service or one ALB handling all 3 services ? what would be your take on this ? We have tried both way it works and we see one ALB for all 3 services is less code + less cost but not sure of any downsides of this
Compared to the cost of your applications, the ALB cost will be negligible. So I would not co sider cost when making your decision
thanks for your help
AWS orgs….Not sure yet how to use properly though to run commands across all environments. I have need to run the New-SSMInventoryDataSync so all my regions and accounts in org sync to common bucket.
While I enabled ssm across all accounts it didnt give me anything in the orgs screen to setup sync. Am I going to have to run a loop through every region and account now and deploy via CF or cli the bucket datasync or is there an easy button with orgs for this? Seems wierd to have to do so much per region work while the org setup was a couple clicks
Are there any compelling reasons to use a NAT gateway over a NAT instance when outbound traffic is not significant enough to justify the increased cost for switching over to a NAT gateway?
In this case I suggest you’d quantify the cost of maintaining the instance (work hours / month) and it’ll easily eclipse the NAT gateway.
I personally prefer simplicity, support, and best practice, and as such if I’m not paying for it myself, would go for a NAT gateway. However I have met co-workers and clients who are more cost-sensitive.
Yeah since both are hands-free this discussion will always surround cost until multi-AZ redundancy enters the equation
always want to be careful with cost savings. i run into these issues too regarding costs. what’s a more political/nicer way to say
penny wise pound foolish
maybe simply “best not to penny-pinch”
A Nat instance will require maintenance, patches, access management etc
The penny pinching that really hurts is that which introduces differences between DEV, STAGE, PROD - unless the differences are properly abstracted by Terraform modules, for example. But even that adds additional complexity.
So when a client says “My Staging env has the following (list of significant differences) than Prod because I save $200 a month”… it’s rather concerning. Of course not every organization is large or VC funded, but usually these differences make it a headache to iterate on infrastructure changes across both environments.
interesting so your environments are setup into different VPCs. you have 1 for prod, 1 for staging, etc. so if you need a NAT, you’ll need one for each VPC which is for each environment
i’d still say it’s worth the cost. what would be an alternative ? and what would the cost of maintenance be to use the alternative ?
You could also deploy a transit gateway with one VPC hosting the IGW / NAT GW for multiple other VPCs.
While its possible then you have traffic for prod and dev going through the same „proxy”. Which rather should be avoided for clear env separation. Also cost calculation per env might be harder in that case
Wild. This design pattern is referenced by AWS.
Can you share a link to it?

In this post, we show you how to centralize outbound internet traffic from many VPCs without compromising VPC isolation. Using AWS Transit Gateway, you can configure a single VPC with multiple NAT gateways to consolidate outbound traffic for numerous VPCs. At the same time, you can use multiple route tables within the transit gateway to […]
That was a good read. Thanks man. I wonder if anyone is using it also for prod environwmnt and if its as smooth as in the paper
I switched a few projects over to this design earlier this year and have not experienced any issues. We’ve gone beyond the simple NAT / bastion model outlined here, but the architecture is fairly similar. Entirely managed using Terraform and GitLab CI.
Good stuff
Dockerizing nodejs Code in Production with or without PM2?
if you will deploy the docker image on platforms that already have process monitoring, then no need for PM2. For example, Kubernetes, ECS, Elastic Beanstalk, all have ways of process monitoring, auto-restarting and replacing bad nodes/pods
Thank you, That helps a lot.
while dockerizing the nodejs code for production is base image alpine or node is good?
FROM node:12.14.1-alpine3.11 as builder
WORKDIR /usr/src/app
COPY package.json ./
COPY package-lock.json ./
RUN npm install --only=production
COPY app/ ./app/
COPY app.js ./
FROM node:12.14.1-alpine3.11
WORKDIR /usr/src/app
COPY --from=builder /usr/src/app/ ./
EXPOSE 3000
CMD ["node", "app.js"]
this works ok
using https://docs.docker.com/develop/develop-images/multistage-build/ to minimize the final image
Keeping your images small with multi-stage images
Just a note from my own experience - once you find yourself installing a bunch of extra libraries on your alpine image it’s time to switch to something beefier.
100% if you need more things then just Node
for Node it’s usually the NPM packages, so the node-alpine image should be enough for almost all cases
And last but not least, npm ci --loglevel warn --only production --prefer-offline is usually better (for these cases) than npm install
2020-10-20
I added Cognito auth to some of our dev sites via an ALB listener rule.
How do I have e2e tests (using cypress) authenticate through the Cognito redirect?
Hey @Andriy Knysh (Cloud Posse) — did you folks at CP need to do anything special to use the terraform-aws-datadog-integration module with 0.13? I’m continuing to get the below error when trying to use the latest (0.5.0) even though I’m specifying what I believe to be the correct required_providers configuration (below as well).
required_providers {
datadog = {
source = "datadog/datadog"
version = "~> 2.13"
}
...
}
Error: Failed to install providers
Could not find required providers, but found possible alternatives:
hashicorp/datadog -> datadog/datadog
If these suggestions look correct, upgrade your configuration with the
following command:
The following remote modules must also be upgraded for Terraform 0.13
compatibility:
- module.datadog_integration at
git::<https://github.com/cloudposse/terraform-aws-datadog-integration.git?ref=tags/0.5.0>
Tried googling around this issue and wasn’t able to find anything of substance.
I’m wondering if that modules needs to adopt the 0.13 required_providers syntax to fix this because the datadog provider is recent and wasn’t originally apart of the hashicorp supported providers or if I’m potentially missing something small and stupid.
not sure, I have not seen that error. I though the new syntax for the providers was optional and not required, but maybe it’s already changed
we deployed the module with TF 0.12 w/o any issues
I think I had this problem and I had to explicitly add the provider , I think this is related to the deprecation of module provider inheritance thing?
Hm. Frustrating. What version of 0.13 did you test this with?
Oh have you only used this with 0.12? I might try to run this with a smaller 0.13 test project and see if it breaks. I think the fact that there never was a hashicorp/datadog provider is causing this breakage.
@jose.amengual what do you mean you had to explicitly add the provider?
no, I had this problem with another provider in 0.13
yes
yes, we need to update the module to use the new provider syntax to support 0.13
I had to added explicitly in my TF project
As in this block:
provider "datadog" {
api_key = local.secrets.datadog.api_key
app_key = local.secrets.datadog.app_key
}
no, on the required_providers too
no
1 sec
Terraform module to provision Opsgenie resources using the Opsgenie provider - cloudposse/terraform-opsgenie-incident-management
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
# version = "3.6.0"
}
local = {
source = "hashicorp/local"
}
tls = {
source = "hashicorp/tls"
# version = "2.2.0"
}
}
required_version = ">= 0.13"
}
exactly
But ya’ll do that… https://github.com/cloudposse/terraform-aws-datadog-integration/blob/master/versions.tf#L4
Terraform module to configure Datadog AWS integration - cloudposse/terraform-aws-datadog-integration
but you need to do it on the TF you are instantiated the module
And I’m saying I do that as well in my root module —
# NOTE: This file is generated from `bootstrap_infra/`. Do not edit this
# `terraform.tf` file directly -- Please edit the template file in bootstrap
# and reapply that project.
terraform {
required_version = "0.13.2"
backend "s3" {
# REDACTED
}
required_providers {
datadog = "~> 2.13"
sops = {
source = "carlpett/sops"
version = "~> 0.5"
}
postgresql = {
source = "terraform-providers/postgresql"
version = "~> 1.7.1"
}
helm = {
source = "hashicorp/helm"
version = "~> 1.2"
}
aws = {
source = "hashicorp/aws"
version = "~> 2.0"
}
local = {
source = "hashicorp/local"
version = "~> 1.2"
}
null = {
source = "hashicorp/null"
version = "~> 2.0"
}
http = {
source = "hashicorp/http"
version = "~> 1.2"
}
external = {
source = "hashicorp/external"
version = "~> 1.2"
}
archive = {
source = "hashicorp/archive"
version = "~> 1.3"
}
template = {
source = "hashicorp/template"
version = "~> 2.1.2"
}
}
}
Ooof that is with the testing I was trying out. I’ve used the proper syntax and had it not work.
As in:
datadog = {
source = "datadog/datadog"
version = "~> 2.13"
}
did you run init after changing it?
Yeah. I’ve been banging on this for an hour.
this
datadog = {
source = "datadog/datadog"
version = "~> 2.13"
}
That was a hunch but wanted to confirm.
I would copy the module into a local modules folder, ref it from the top level module, update the provider syntax and test
much faster testing
Good idea.
That did it.
I’ll put up a PR.
ohhhhhhhh the module did not have it…
cool
ohhh so the way I fixed my problem was basically the wrong way
This may be specific to the datadog provider because it’s so new. I’ll do a write up on my hunch in the PR.
Argh — Just realizing I created this thread in #aws instead of #terraform — apologies folks
How do I pass for_each region on this provider run the resource/module. I tried with module and it’s not workign
Basically I need an example of creating a resource for each region AND giving it an explicit provider (as this plan handles multiple accounts, each with it’s own file)
You can’t change provider mappings with for_each in Terraform. It’s a known limitation.
so you can do
resource x y {
for_each = my_set
provider = aws.secondary
name = each.key
}
but not
resource x y {
for_each = my_hash
provider = each.value == "secondary" ? aws.secondary : aws.primary
name = each.key
}
ok, so for multi region i still need to duplicate the block each time
yup. If you look at the state file representation of a for_each / count resource, you will understand why. The provider mapping is stored once per resource block
can i pass in a region and dynamically set the provider region in the module so it’s the same provider except region changes?
It’s complicated, but try to avoid using anything which isn’t static config or a var as provider values
You can use expressions in the values of these configuration arguments, but can only reference values that are known before the configuration is applied. This means you can safely reference input variables, but not attributes exported by resources (with an exception for resource arguments that are specified directly in the configuration).
https://www.terraform.io/docs/configuration/providers.html
So I have to copy and paste this for every single region I want to run * each account… Uggh.
provider "aws" {
alias = "account-qa-eu-west-1"
region = "eu-west-1"
access_key = datsourcelinked
secret_key = datsourcelinked
}
resource "aws_ssm_resource_data_sync" "account-qa-eu-west-1" {
provider = aws.account-qa-eu-west-1
name = join("-", [module.label.id, "resource-data-sync"])
s3_destination {
bucket_name = module.s3_bucket_org_resource_data_sync.bucket_id
region = module.s3_bucket_org_resource_data_sync.bucket_region
}
}
This isn’t for any reuse beyond the folder itself, just need to avoid as much redundancy as i can
pull the parameter values out into locals then, imo
Something like this was what I was hoping for
module "foo" {
provider = aws.account-qa-eu-west-1
provider_region = 'please'
name = join('-', [module.label.id, "resource-data-sync"])
bucket_name = module.s3_bucket_org_resource_data_sync.bucket_id
bucket_region = module.s3_bucket_org_resource_data_sync.bucket_region
}
this one plan generates all my data syncs across org. I was hoping to keep it in single plan
I’d generate/template the provider config outside of terraform. Core use case for terragrunt, for sure
Are there any metric collection agents out there that can send postgres metrics to CloudWatch as custom metrics? I’m trying to avoid having to write this myself…
look for a tool that sends postgres metrics to an open source metric format, like statsd, prometheus, collectd, etc. They all have CloudWatch metric output targets
Thanks, I guess you don’t have any specific recommendations off the top of your head?
telegraf i can almost guarantee you will cover you
check the plugins. It’s pretty awesome
Are you looking to do psql query and out its output to metric? What kind of metrics you want to have as custom?
2020-10-21
Anyone know of any open source datadog monitor configurations for AWS resources like ALBs, NLBs, WAF, etc?
Likely looking for something that doesn’t exist yet… but since terraform-datadog-monitor has an awesome set of open source kubernetes monitors (from DataDog) I figured I should ask before I Terraform a bunch of existing monitors created before my time that I’m not too fond of.
Terraform module to configure and provision Datadog monitors from a YAML configuration, complete with automated tests. - cloudposse/terraform-datadog-monitor
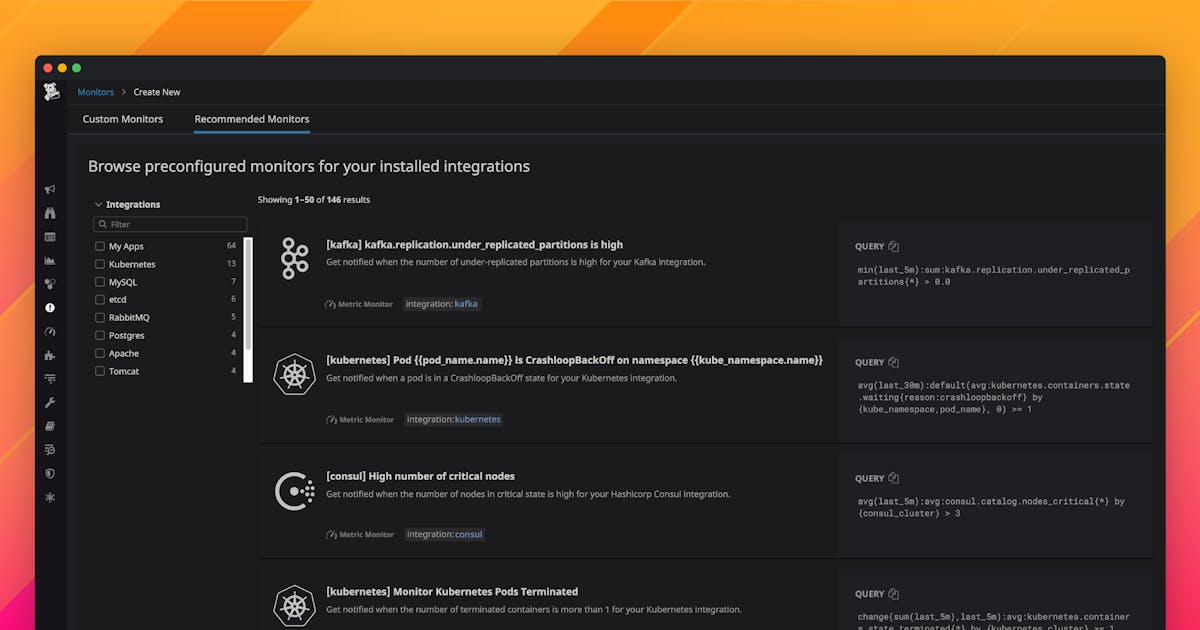
Recommended Monitors are a suite of curated, customizable alert queries and thresholds that enable Datadog customers to enact monitoring best practices for the technologies they rely on.
DD integration will pick up automatically resources on the account and exports those metrics and then you can create monitors and such
I was playing with this
autogenerate dashboards based on metric prefix. Contribute to borgified/terraform-datadog-dashboard development by creating an account on GitHub.
but I did not like the module much so I rewrote the script in go to pull the data
the same can be use to create monitors with a different api call
Yeah, I was just lazily looking to have predefined monitors like the recommended monitors that DataDog shared
We don’t have them yet, but would love more contributions to our our library of monitors
(…the library of monitors being the link you shared above)
I don’t know if its something that already exists, but a similar thing for dashboards would be cool
yep, dashboards need to be created manually
could possibly contribute what we have at least
I’d be :thumbsup: on a dashboard module. Just for the crowdsourced dashboard configuration honestly.
I’m starting to wonder if the monitor module should be updated for the monitors.yml file to be the default datadog_monitors variable. Then the module can move those monitors more front and center to the user and we’ll likely get more contributors to that base monitors configuration.
@Erik Osterman (Cloud Posse) do you folks deploy those monitors per account / environment that you’re deploying? The monitor.yml configuration that is in the repo would alert on any k8s cluster connected to DD so I’m wondering how you folks approach that.
You control escalations in opsgenie or whereever you do that
Aha that’s where you choose to section it up.
But you’ll definitely want to copy the monitor.yml into your repo and customize the thresholds and where it goes (e.g. OpsGenie or PagerDuty).
Yea, so treat alerts like a firehose of signals that should all get routed to opsgenie
then create policiies that control what is actionable and becomes an incident vs whats just noise
(see our opsgenie module too)
Yeah… client uses VictorOps and I don’t think it’s that sophisticated. It’s also not driven by IaC so I would be hesistant to put the control there unfortunately.
heh, ya, your mileage may vary then.
Yeah… not great.
if they are already an atlassian shop (e.g. using jira, confluence, et al), then I’d recommend they switch
They are and I will make that push, but of course that won’t be something that happens for a while.
Anyway, thanks for the info! I’m off to build something sadly more involved.
Sorry I missed this @Matt Gowie
If you want I can send you the terraform code we use, can DM me
But sounds like you need more than that
https://aws.amazon.com/blogs/aws/public-preview-aws-distro-open-telemetry/
https://aws-otel.github.io/
AWS Distro for OpenTelemetry is a secure, production-ready, AWS-supported distribution of the OpenTelemetry project. Part of the Cloud Native Computing Foundation (CNCF), OpenTelemetry provides open source APIs, libraries, and agents to collect distributed traces and metrics for application monitoring. With AWS Distro for OpenTelemetry, you can instrument your applications just once to send correlated metrics and traces to multiple monitoring solutions and use auto- instrumentation agents to collect traces without changing your code.

It took me a while to figure out what observability was all about. A year or two I asked around and my colleagues told me that I needed to follow Charity Majors and to read her blog (done, and done). Just this week, Charity tweeted: Kislay’s tweet led to his blog post, Observing is not […]
… yet another aws github org?
gotta HA those githubs
never know when one will go down
OMG this is stupid
https://docs.aws.amazon.com/cli/latest/reference/ecs/update-service.html
Warning
Updating the task placement strategies and constraints on an Amazon ECS service remains in preview and is a Beta Service as defined by and subject to the Beta Service Participation Service Terms located at <https://aws.amazon.com/service-terms> ("Beta Terms"). These Beta Terms apply to your participation in this preview.
every single tool for ecs deployment that I know uses update-service I guess now if something does not work I could say “ahhhhhh is a beta feature”
You can update other aspects of a service. It’s only dynamically changing the placement configuration which is flaky.
(It’s rare you do this to a production service, so it’s not too much of a problem.)
true
I’m so glad amazon does not build cars or hospital equipment
2020-10-22
Anyone know of any courses/tutorials that will walk you through building various different AWS architectures. Ideally with some kind of IaC (Cloudformation/CDK etc), and CI/CD to deploy/test this before it’s released?
I’m trying to build something at the moment, but I don’t know enough about AWS, IaC, CI/CD to do it, and could do with following some guides first I think as it’s taken me 1.5 days to create 4 resources in AWS
Learning IaC, Cloud, and CI/CD all in one tutorial is a high barrier to ask for. I would suggest trying to tackle understanding one at a time. For AWS, I recommend going through Stephane Maareks’s udemy course: https://www.udemy.com/course/aws-certified-solutions-architect-associate-saa-c02/

Pass the AWS Certified Solutions Architect Associate Certification SAA-C02. Complete Amazon Web Services Cloud training!
You’re right. I need to take a step back and tackle one at a time… Thanks for the course recommendation, I’ll give this a watch!
what are some of the must have polices in a initial AWS account
Aws config and trusted advisor can jump start you. Well architected framework is a good read. Also using root modules from cloudpossse I would be would help setup with some great practices
Has anyone requested a monthly SMS spending quota increase for Amazon SNS via Terraform?
aws service-quotas list-service-quotas –service-code sns
Tells me there is no service quotas I can request… and all the docs I’ve found haven’t mentioned an API / CLI option. I’m really hoping this isn’t one of AWS’ annoying manual steps.
Aha might have spoken too soon. I missed this – https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/sns_sms_preferences#monthly_spend_limit
Going to try that out — apologies for the noise.
Seems that AWS API only allows setting values for which you’ve already been approved. So they set the hardcap to $1 for all new AWS accounts. So you can use that monthly_spend_limit param to set any value between 0 and 1, but if you set $2 then AWS rejects it. Great stuff. Thank you AWS for adding another manual step into my environment creation process.
ah yah thats annoying, had that happen with Pinpoint SMS
Real fun when you need to update the limit and it can take 1-2 days
Yeah, they still haven’t gotten back to me…. if you’re going to introduce a manual step into my workflow at least make it super fast.
And once they raise the limit you still have to go set your service to something within the new limit. its a bit silly
Aha so I actually do need to use that sms_preferences / monthly_spend_limit parameter. Damn — that makes it even worst.
its a really bad process yah
I’m not sure there’s even a point to using terraform w/ it
If only you could query your limit and then use that as the input to the preference parameter…
Then it would just update it once you were approved.
2020-10-23
Hey there, thank you for this community
Regarding terraform-aws-ecs-alb-service-task I would like to know if I can create the NAT Gateway only on one subnet?
This would allow for a cheaper environment, as the normal is to create 2 NAT gateway
You might mean the subnets module? Either way, did you consider using NAT instances instead?
1Hi @Joe Niland yes the subnets module
(it’s a submodule of the first one I mentioned)
Can you elaborate on NAT Instance? Is there a good Terraform Module for it?
The subnets module has a variable for it:
You just need to set it to true and set NAT gateway to false
Terraform module which implements an ECS service which exposes a web service via ALB. - cloudposse/terraform-aws-ecs-alb-service-task
The gateway determines your level of HA. If you have only one gateway, no reason to operate in multiple zones. So we generally recommend using NAT instances in dev accounts to save money and NAT gateways in production accounts.
To reduce cost in dev accounts, reduce the number of AZs which reduces inter-AZ transfer costs and the costs of operating the NAT instances
Did anyone else start getting a flood of emails about AWS retiring some ECS-related infrastructure and asking for tasks to be restarted?
I got 21 emails this morning:
Subject: [Retirement Notification] Amazon ECS (Fargate) task scheduled for termination
We have detected degradation of the underlying infrastructure hosting your Fargate task ... in the us-east-1 region. Due to this degradation, your task could already be unreachable. After Mon, 23 Nov 2020 15:35:03 GMT, your task will be terminated.
...
How do you update AWS ECS Fargate?
this is option number two. thanks
boto3 and CloudFormation for us
Not sure ecs deploy is the same as bleu green codedeploy. To be fair the codepipeline is itself deployed with either cloudformation or terraform
How do we setup aws-vault with role and mfa to generate temporary credentials. with out generating any accesskeys and secret keys from user.
We do it via AWS SSO. Users are listed there, none of them have their own access keys. It generates them on the fly via federation.
For example, the profile looks like this:
[profile myaccount-yoni]
sso_start_url=<https://indeni.awsapps.com/start>
sso_region=us-east-1
sso_account_id=12345678
sso_role_name=cool_role
my goal is to enable sso. but I am noob with this. is active directory is provided by aws? or we have to use external identity provider.
AWS have their own directory service if you want, or use an external one. What does your org currently use?
Did anyone have issues with iam roles for service accounts in kubernetes? From some reason it fails over to instance profile instead. I suspect there is some bug in aws-sdk for javascript, but can’t confirm yet
Do you try to install awscli in your pod with serviceaccount associated, and try to login the shell type aws sts get-caller-identity ?
Yeah, sorry. Over cli it works perfectly fine and it assumes role correctly. And I didnt mention that it worked with aws-sdk for js before.
Oh, sorry, I never use aws-sdk for js.
I suspect there could be some bug with region. With sdk It worked in us-east-1 , but now in another region it doesn’t.
2020-10-24
2020-10-25
2020-10-26
Does anyone know of a robust solution for automatically mounting and formatting new EBS volumes when a new instance is first started?
SSM Command doc association can also run. This could allow windows + linux script for these commands to be run on demand, triggered, etc.
Cloudinit or userdata for running every single time might make sense though.
Lastly, an AWS Step Function/ AWS SSM Automation doc could provision an EBS volume wait for expasion being complete then run the ssm runcommand doc in instance to initiate the volume expansion. I’ve been looking into just that this last week to improve response on EBS volume space issues.
How to evaluate a right monitoring tool for your environment? I am working on Microservices Kubernetes environment. how do we evaluating a right Monitoring tool for prod environments. They are many sass companies, opensource tools out there providing same set of features. Any suggestions on how to select a sass product?
Prometheus is what I have used I think it is kind of a standard https://en.wikipedia.org/wiki/Prometheus_(software)
Prometheus is a free software application used for event monitoring and alerting. It records real-time metrics in a time series database (allowing for high dimensionality) built using a HTTP pull model, with flexible queries and real-time alerting. The project is written in Go and licensed under the Apache 2 License, with source code available on GitHub, and is a graduated project of the Cloud Native Computing Foundation, along with Kubernetes and Envoy.
Since you seem to want SASS google managed prometheus instead
I am looking at panopta
ymmv
adding to #office-hours agenda
2020-10-27
does anyone use any tools to rotate ecs ec2 instances ?
I found this today and wondering how other devs do this
Interactive Python/boto3 script for rotating/rebooting EC2 instances in an ECS cluster - chair6/ecsroll
We use terraform
Interactive Python/boto3 script for rotating/rebooting EC2 instances in an ECS cluster - chair6/ecsroll
| you use terraform to apply a new launch [configuration | template] version with an updated AMI and then what ? |
do you rotate the instances manually ? or do you let it rotate itself organically ?
afaik terraform will not rotate the instances for you and aws instance refresh doesn’t take into account ecs task health and proper draining
Well, we use terraform + terragrunt, we use different state file for each set of instances we are building, we launch new instances with packer builded ami and replace them with terraform + terragrunt
interesting. im not sure i follow exactly how they are replaced using terraform/terragrunt..
We have dedicated terraform structure using Partial Backend having only ec2 instances on it, everytime we create a new set of instance say v1.0 we name tfstate file as instances-v1.0
Backends are configured directly in Terraform files in the terraform section.
Not sure if this would work with ECS, but what I’m doing for for my EC2s
My use case allows me to decrease the running instances down to zero and then back up, so I know I’m gettin fresh instances. Won’t work for most people
EC2s have an Auto Scaling Group with a Launch Configuration that pulls the Image from an SSM Parameter. ASG User Data loads the init script from S3 and executes it.
ASG has a schedule to drop the desired count to 0 then back up to the desired count “later” – typically an hour later.
As new images are published, the SSM parameter is overwritten and the schedule takes care of the rest.
sounds like a recreation of aws instance refresh
unfortunately this doesnt work for ecs since this would cause down time
yeah, figured it wouldn’t work for you but wanted to share incase
in the ECS land we’re just taking the hit and using Fargate
very excited to start making use of FARGATE_SPOT now that’s available in CloudFormation
I’ve written simple python ecs rollout script which handles some corner cases. can share it if you’d like
From what I remember it drains single instance, detach it from ASG, wait for all tasks to be running and continue. after all done it asks for termination of detached instances
There’s whole terragrunt issue about ecs rollout with details and why such approach was best suited (at the time, maybe sth has changed) but this repo is private if you’re not grunt
I’ve nearly finished building an ECS cluster with the ASG in CloudFormation (which is deployed by TF) to use its rolling update policy to replace instances. There’s a launch lifecycle hook and Lambda function that waits for instances to become active in ECS, and a terminate hook and Lambda that drains instances before termination. It took quite a lot of work, hopefully I’ll be able to publish it.
A draining lifecycle hook might be enough to make instance refresh work without downtime.
Id love to see that published work. Nice job raymond!
It’s all brand new and maybe a bit too suited for use with my current customer project but here it is: https://github.com/claranet/terraform-aws-ecs-container-instances
Create an auto scaling group of ECS container instances - claranet/terraform-aws-ecs-container-instances
because of
Lifecycle hooks ensure that instances have been drained of tasks before they are terminated.
does that mean if someone was to manually terminate the ec2 instance, the lifecycle hook would run, lifecycle completes successfully, and then it terms the instance ?
the instance gets stuck in “terminating:wait” state until something completes the lifecycle action (the lambda function does this, or you could use the CLI to bypass it)
thats perfect. tyvm for sharing
you’re welcome. it’s not quite in production yet so beware of bugs and be sure to review and test carefully before you use it or anything from it
2020-10-28
2020-10-29
Reaching out to the group with a very edge case question - Has anyone deployed a hardened image, such as the CIS Amazon Linux 2 image, inside a Managed Node group for EKS? I ask the question because I want to use this image but I am not sure of how to install the required Kubernetes components (kubelet and kube-proxy) , which of course come preinstalled with the Amazon Linux 2 AMI. I also am not sure I can Terraform the cluster and node group using the CIS image. I would appreciate any help anyone has to offer!
@roth.andy hi Andrew, I’ve heard on our office hours you have to deal w/ PCI compliance at your company. do you have any opinion on this?
I’ve never had to deal with PCI compliance. My company works with FedGov/DoD so we have to deal with stuff like DFARS/FEDRAMP, and getting ATOs (Authority To Operate)
Have you ever deployed a custom AMI via Managed Nodes in EKS?
I haven’t had the opportunity to use managed nodes yet, so no
Thanks
I mostly use Rancher/RKE, which lets me use whichever EC2 AMI I want
So the cloudposse modules now support the custom AMIs and user data scripts for managed node groups. That said, it’s a more advanced operating model. Are you already using our modules? In the end, you have 2 options:
- Use packer to bundle your own AMIs based on the CIS Amazon Linux 2 image, and do that in each region you operate in
- Add the steps to
curlthe binaries into the image TL;DR: we don’t have an example for your exact use-case, but we are doing something similar to install gravitational teleport binaries in the base VM.
Terraform module to provision an EKS Node Group. Contribute to cloudposse/terraform-aws-eks-node-group development by creating an account on GitHub.
Combined with launch_template_name
Thanks Erik!
AWS VPC creation with IPv4 CIDR range with 10.0.0.0/16 vs creating VPC 172.31.0.0/16 which is recommended to use with aws ecs clusters.
It doesn’t matter unless you want to peer the vpc with another. I prefer 10/16 as I find it easier to remember
Learn which VPC peering connection configurations are not supported.
2020-10-30

Thanks to its efficiency and support for numerous programming languages, gRPC is a popular choice for microservice integrations and client-server communications. gRPC is a high performance remote procedure call (RPC) framework using HTTP/2 for transport and Protocol Buffers to describe the interface. To make it easier to use gRPC with your applications, Application Load Balancer (ALB) […]
That’s a great news! Thanks for your sharing.
Thanks to its efficiency and support for numerous programming languages, gRPC is a popular choice for microservice integrations and client-server communications. gRPC is a high performance remote procedure call (RPC) framework using HTTP/2 for transport and Protocol Buffers to describe the interface. To make it easier to use gRPC with your applications, Application Load Balancer (ALB) […]
I have a lambda that is running data collection. I want to run it 1 of the 20 combinations at a time on each server at time so that I minimize traffic. Aws, events, etc any tip on what would let me do this?
Step functions
+1 for step functions
We’ve had some interesting experience with AWS Step functions. Can you share more details, maybe there are other ways.
So a scheduled event for step functions that would execute each as desired keeping concurrency to my requirements?
I looked originally but didn’t seem any examples to jump start me on that approach. I’ll have to relook at
Step functions have loop + fan out. You need to implement concurrency control yourself, to ensure only one instance of your function runs at a time. But the rest is built in support
Yes, I just want to invoke the function and then have it issue all the combinations but not in full concurrency. Sounds like what I’d need.